基于改进多尺度幅值感知排列熵的滚动轴承故障诊断方法与流程
本发明涉及数字信号处理领域,具体为一种基于改进多尺度幅值感知排列熵的轴承特征提取方法。
背景技术:
滚动轴承是旋转机械中最常见的部件之一,但由于磨损、疲劳、腐蚀、过载等因素的影响,滚动轴承在工作过程中极易发生故障,影响机械设备整体性能。因此,滚动轴承的故障诊断及严重程度分析对保证机械设备运行的可靠性及制定相应维修策略具有重要意义。
滚动轴承故障的位置和严重程度将导致振动信号的冲击特性存在明显差异,因此基于振动信号的故障诊断技术成为了当前滚动轴承异常状态监测的重要研究方向之一。滚动轴承故障诊断的本质是一个模式识别过程,主要包括特征提取和故障分类。但是,由于滚动轴承振动信号具有非线性和非平稳性的特点,同时运行过程中容易受到多种外界因素的干扰,信噪比较低,导致轴承故障特征难以得到有效提取,影响故障诊断结果的准确率。
鉴于此,相关学者针对滚动轴承故障诊断开展了大量的研究工作,并取得了一定的研究成果。现有文献中记载了利用集合经验模态分解(eemd)实现对滚动轴承振动信号的自适应分解,并采用峭度值结合相关系数的方法确定包含主要轴承状态信息的本征模态函数,再利用其奇异值作为特征向量,通过超球多类支持向量机实现对滚动轴承的多故障分类。然而,eemd不能够完全解决emd的模态混叠问题,峭度值结合相关系数的本征模态函数选择法会损失部分轴承故障信息,而超球多类支持向量机的核参数选取和优化过于复杂,增加了实际应用的困难。另一篇文献中记载了利用局部均值分解(lmd)算法对滚动轴承振动信号进行预处理,再利用多尺度熵(mse)提取故障特征向量,最后构建bp神经网络分类器实现故障类型识别。但是,mse在时间序列的粗粒化过程中,粗粒化后的序列长度会随着尺度因子的增加而缩短。当尺度因子较大时,多尺度熵值具有不稳定性,进而影响特征提取的有效性。还有一篇文献中记载了利用多尺度排列熵提取滚动轴承振动信号中的故障特征,并采用laplacianscore算法进行特征选择,随后通过支持向量机(svm)实现故障类型识别。然而,基于排列熵的特征提取忽略了时间序列中元素幅值对熵值的影响,会使得提取的特征具有较大的随机性,影响故障识别准确率。因此,现有基于滚动轴承振动信号的故障诊断方法尚存在特征提取可分性不强、故障识别准确率低及故障严重程度分析不充分等问题。
技术实现要素:
本发明的目的是:针对现有滚动轴承振动信号的故障诊断方法尚存在特征提取可分性不强、故障识别准确率低及故障严重程度分析不充分等问题,提出一种基于改进多尺度幅值感知排列熵的滚动轴承故障诊断方法。
本发明采用如下技术方案实现:基于改进多尺度幅值感知排列熵的滚动轴承故障诊断方法,包括以下步骤:
步骤一:获取已知的不同故障种类、不同故障程度下的滚动轴承振动信号,并组成不同故障种类、不同故障程度下的滚动轴承振动信号样本集;
步骤二;针对样本集中的每一个振动信号,进行固有时间尺度分解,获取一系列固有旋转pr分量,并从中选取最优pr分量进行后续特征提取;
步骤三;利用改进多尺度幅值感知排列熵提取最优pr分量不同时间尺度下包含的滚动轴承振动信号的特征,组成不同故障种类、不同故障程度下的故障特征向量,所述改进多尺度幅值感知排列熵的获取步骤为:
步骤三一:假设待分析时间序列为{x1,x2,...,xn},利用改进的粗粒化过程产生一组新的粗粒化时间序列
步骤三二:对于每一个时间尺度因子τ和嵌入维数d,分别计算
其中,aape为幅值感知排列熵;
步骤四;通过对滚动轴承振动信号样本集进行特征提取,组成滚动轴承振动信号故障特征集,将该特征向量输入到随机森林分类器中。
步骤五:将测试集输入随机森林分类器中,得到测试集的滚动轴承故障类型和故障严重程度。
本发明具有如下有益效果:本发明中的改进多尺度幅值感知排列熵故障特征提取方法具有良好的故障严重程度描述能力,提取的特征向量具有良好的可分性;
改进多尺度幅值感知排列熵改善了多尺度分析中的粗粒化过程,并利用幅值感知排列熵对信号幅值和频率变化敏感的特性,计算不同时间尺度下的aape值并组成特征向量,具有较强的故障描述能力;
改进多尺度幅值感知排列熵与rf的滚动轴承故障诊断方法能够在准确识别故障类型的基础上,进一步对故障严重程度进行分析,在故障严重程度较为复杂的情况下,平均识别准确率达到99.25%。
附图说明
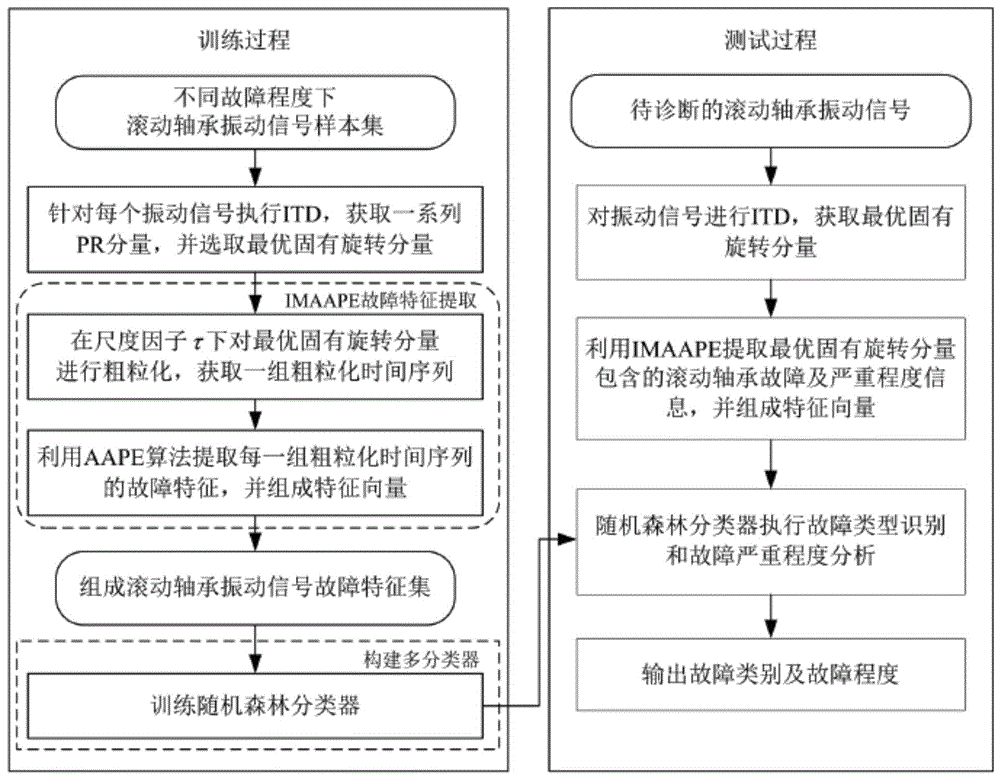
图1为故障识别及故障严重程度分析流程图。
图2为0负载下不同故障严重程度的滚动轴承振动信号图。
图3为0负载下不同故障严重程度的滚动轴承振动信号图。
图4为0负载下不同故障严重程度的滚动轴承振动信号图。
图5为0负载下不同故障类型的改进多尺度幅值感知排列熵特征聚类图。
图6为0负载下不同故障严重程度的改进多尺度幅值感知排列熵特征聚类图。
具体实施方式
具体实施方式一:下面结合图1具体说明本实施方式。本实施方式基于改进多尺度幅值感知排列熵的滚动轴承故障诊断方法,包括以下步骤:
步骤一:获取已知的不同故障种类、不同故障程度下的滚动轴承振动信号,并组成不同故障种类、不同故障程度下的滚动轴承振动信号样本集;
步骤二;针对样本集中的每一个振动信号,进行固有时间尺度分解,获取一系列固有旋转pr分量,并从中选取最优pr分量进行后续特征提取;
步骤三;利用改进多尺度幅值感知排列熵提取最优pr分量不同时间尺度下包含的滚动轴承振动信号的特征,组成不同故障种类、不同故障程度下的故障特征向量,所述改进多尺度幅值感知排列熵的获取步骤为:
步骤三一:假设待分析时间序列为{x1,x2,...,xn},利用改进的粗粒化过程产生一组新的粗粒化时间序列
步骤三二:对于每一个时间尺度因子τ和嵌入维数d,分别计算
其中,aape为幅值感知排列熵;
步骤四;通过对滚动轴承振动信号样本集进行特征提取,组成滚动轴承振动信号故障特征集,将该特征向量输入到随机森林分类器中。
步骤五:将测试集输入随机森林分类器中,得到测试集的滚动轴承故障类型和故障严重程度。
首先,本发明通过固有时间尺度分解(itd)法提取滚动轴承振动信号的最佳固有旋转分量,突显不同种故障信号的特征;然后,利用改进多尺度幅值感知排列熵(imaape)对故障信号幅值和频率变化敏感的特性,计算不同时间尺度下的幅值感知排列熵作为特征向量,同时改善了多尺度分析中的粗粒化过程,提升了故障特征提取的稳定性;最后,利用故障特征集构建随机森林多分类器,通过简单的参数选择就能实现对滚动轴承不同故障类型的识别及严重程度分析,具有较强的泛化能力。
本发明提出的故障诊断方法能够实现滚动轴承内环、外环及滚珠故障识别及故障严重程度分析,该方法的故障识别及故障严重程度分析流程如图1所示。
文中所述的改进的粗粒化过程为现有技术,出处为azamih,escuderoj.improvedmultiscalepermutationentropyforbiomedicalsignalanalysis:interpretationandapplicationtoelectroencephalogramrecordings[j].biomedicalsignalprocessingandcontrol,2016,23:28-41。
实施例:
本发明选用美国西储大学轴承数据中心提供的滚动轴承故障数据集对所提出的故障诊断方法进行实验验证。实验以skf轴承作为研究对象,数据集通过加速度传感器采集正常(nm)、内环故障(ir)、外环故障(or)及滚珠故障(b)四种状态下的轴承振动信号,采样频率为12khz;对于三种故障类型,分别选取故障直径为7mils、14mils和21mils三种不同的故障严重程度进行数据获取。0负载下不同故障严重程度的滚动轴承振动信号的时域波形如图2和图3所示,可见故障类型和故障严重程度的变化与其振动信号的幅值和频率的变化相关。表1所示为实验样本中故障类型及严重程度组成,实验样本一共包括10种不同的滚动轴承健康状态。将每种轴承数据不重叠地分割成多个数据样本,每个样本中含有n=1024个采样点,组成每种健康状态下50个样本构成的实验数据集。其中,采用每种健康状态下10个样本作为训练集,40个样本作为测试集。
滚动轴承故障特征提取实验:
在执行滚动轴承故障特征提取前,需采用固有时间尺度分解(itd)对振动信号进行预处理,进一步突出信号固有瞬时幅值、频率等形态特征。如图4所示为故障直径7mils下滚珠故障itd分解结果,itd将故障振动信号分解为5个pr分量和1个单调趋势分量。由分解结果可见,峰度值最高的最优pr分量包含描述滚珠故障的主要幅值和频率特征。
表1实验样本的故障类型及严重程度组成
tab.1compositionoffaulttypesandseverityinexperimentalsamples
滚动轴承振动信号经itd分解后,采用改进多尺度幅值感知排列熵(imaape)进行特征提取。对最优pr分量进行imaape特征提取,设置嵌入维数为d=4,时间延迟为l=1,时间尺度为τ=20,调整系数a=0.5。对测试集的振动信号样本进行imaape特征提取,得到20维的滚动轴承振动信号故障特征向量。如图5所示为0负载下不同故障类型的imaape特征聚类图,从特征向量的前3个维度可以看出,本发明提出的特征提取方法能够较好地对正常、内环故障、外环故障及滚珠故障进行描述,特征向量具有较强的聚类性。如图6所示为0负载下不同故障严重程度的imaape特征聚类图,选取特征向量中前2个维度可以看出,本发明提出的特征提取方法对不同故障严重程度的特征提取结果也具有较好的聚类性。
表2滚动轴承故障特征提取算法的性能比较
tab.2performancecomparisonofrollingbearingfaultfeatureextractionalgorithm
为了说明imaape滚动轴承振动信号特征提取方法的性能,本发明将imaape与现有滚动轴承故障特征提取方法的效果进行对比。实验采用0负载下内环故障、外环故障和滚珠故障各40个样本进行分析,实验结果如表2所示。
不同故障类型情况下,特征向量的类间距离平均值越大,表示特征提取方法提取的不同故障类型的特征差异性越大;不同故障类型情况下特征向量的类内距离平均值越小,表示特征提取方法提取的相同故障类型的特征差异性越小。由表2可见,imaape的平均类间距离大于改进多尺度排列熵(impe)和精细复合多尺度排列熵(rcmpe),但小于改进多尺度样本熵(imse)、改进多尺度模糊熵(imfe)和精细复合多尺度样本熵(rcmse),而imaape的平均类内距离在所有特征提取方法中最小。该实验结果说明imaape提取的滚动轴承故障特征具有较好的聚类性质。此外,由表2可知,在计算相同的采样点数时,imaape的平均耗时为所有特征提取方法中最小的,具有较好的实时性。
表3滚动轴承故障特征提取算法性能比较
tab.3performancecomparisonofrollingbearingfaultfeatureextractionalgorithm
为了进一步说明本发明提出的imaape故障特征提取方法的可分性,本发明分别利用表2中描述的特征提取方法与随机森林分类器相结合,设置cart决策树数量为50,对滚动轴承10种不同健康状态下的每种类别40个测试样本进行分析,实验结果如表3所示。可见,与当前不同滚动轴承故障特征提取方法相比较,本发明提出的imaape故障特征提取方法具有更好的故障严重程度描述能力,提取的特征向量具有更高的可分性。
滚动轴承故障类型识别实验
为了验证本发明提出的基于改进幅值感知排列熵(imaape)与随机森林(rf)相结合的轴承故障诊断方法的性能,对滚动轴承10种不同健康状态下的每种类别40个测试样本进行实验验证,结果如表4所示。可见,提出的滚动轴承故障诊断方法能够有效地识别正常、内环故障、外环故障、滚珠故障,并且能够较为有效地分析故障严重程度,误报率较低,平均识别准确率高达99.25%。
表4提出的滚动轴承故障诊断方法的识别率
tab.4identificationrateoftheproposedrollingbearingfaultdiagnosismethod
为了进一步说明本发明提出方法在滚动轴承故障诊断中的性能,将本发明提出的滚动轴承故障诊断方法与现有方法进行比较,实验结果如表5所示。可以看出,本发明提出的方法能够实现滚动轴承故障类型识别,并能够进一步分析轴承故障严重程度。在故障严重程度单一的情况下,能够准确识别故障类型;在故障严重程度较为复杂的情况下,依然具有相对较高的平均故障识别率。
表5不同滚动轴承故障诊断方法识别率比较
tab.5comparisonofidentificationratesofdifferentfaultdiagnosismethodsforrollingbearings
结论
1)itd能够稳定地将滚动轴承故障信号分解为一组pr分量,其中最优pr分量能够突出滚动轴承故障信号的主要时-频特性,便于后续故障特征提取;
2)imaape改善了多尺度分析中的粗粒化过程,并利用幅值感知排列熵对信号幅值和频率变化敏感的特性,计算不同时间尺度下的aape值并组成特征向量,具有较强的故障描述能力;
3)基于imaape与rf的滚动轴承故障诊断方法能够在准确识别故障类型的基础上,进一步对故障严重程度进行分析,在故障严重程度较为复杂的情况下,平均识别准确率达到99.25%。
本发明研究的方法目前仅适用于滚动轴承固定负载下的故障类型识别及故障严重程度分析。为了进一步提升该滚动轴承故障诊断方法的泛化能力,后续的研究重点为变负载情况下滚动轴承的故障类型与故障严重程度分析。
具体实施方式二:本实施方式是对具体实施方式一的进一步说明,本实施方式与具体实施方式一的区别是在在所述步骤二中,设xt为已知的待分析的信号,定义
固有时间尺度分解算法的主要步骤如下:
步骤二一:假设{τk,k=1,2,...}表示信号xt的局部极值,默认τ0=0;
步骤二二:在区间[0,τk]中定义lt和ht,且xt在区间t∈[0,τk+2],在连续极值间隔(τk,τk+1]中的提取的基线信号lt表示为:
其中,
式中,α是线性缩放因子,用来调节提取固有旋转分量幅度,0<α<1;
步骤二三:根据式(2)和式(3),固有旋转分量ht可以表示为:
其中,
步骤二四:将基线信号lt作为下一次分解的输入信号重复步骤二一至二三,获取一系列pr分量,分解的终止条件为基线信号lt变得单调或者小于某个预设值;
经过固有时间尺度分解分解后,时间序列xt被分解为一系列pr分量和一个单调趋势分量,信号的峰度值能有效描述信号的脉冲特性,峰度值越高,信号所包含的脉冲特征越丰富,获取峰度值最大的pr分量为最佳固有旋转分量,其计算过程如下所述:
其中,ki表示第i个pr分量的峰度值,n表示时间序列长度,ui为第i个pr分量的归一化峰度值,m是pr分量的个数,最佳固有旋转分量选取ui为最大值时所对应的pr分量,
具体实施方式三:本实施方式是对具体实施方式一的进一步说明,本实施方式与具体实施方式一的区别是所述步骤三一中改进的粗粒化过程的获取步骤为:
步骤三一一:假设一个长度为n的时间序列{xi}={x1,x2,...,xn},利用尺度因子τ=1,2,...,n,对序列进行粗粒化,粗粒化过程如下式所示,
其中,
步骤三一二:计算每个粗粒化的新时间序列的样本熵值,获得不同时间尺度下的n个多尺度熵值来描述原始时间序列的信号特征;
步骤三一三:对多尺度熵的粗粒化过程进行改进,改进后的粗粒化时间序列表示为
其中,
具体实施方式四:本实施方式是对具体实施方式一的进一步说明,本实施方式与具体实施方式一的区别是所述步骤三二中时间序列的幅值感知排列熵的获取步骤为;
步骤三二一:假设给定的长度为n的时间序列x={x1,x2,...,xn},对于每个时间点t,将信号x嵌入到d维空间获得重构向量,
步骤三二二:按每个向量
其中,f(πi)表示统计排列顺序πi出现次数的函数,每当
步骤三二三:假设
调节信号振幅均值及振幅之间偏差的权重,一般取0.5;
步骤三二四:对于整个时间序列中
时间序列的幅值感知排列熵表示为:
具体实施方式五:本实施方式是对具体实施方式一的进一步说明,本实施方式与具体实施方式一的区别是所述步骤四中的随机森林分类器具体步骤为:假设随机森林分类器由多个决策树{hj(x,θk),k=1,2,...,n}组成,{θk,k=1,2,...,n}表示相互独立且同分布的随机向量;随机森林分类器的训练样本集表示
d={(x1,y1),(x2,y2),...,(xn,yn)},xi=(xi,1,...,xi,p)t表示第i个训练样本xi具有p个特征值,yi表示训练样本xi对应的标签;对训练样本集d进行n次bootstrap采样,获得n个bootstrap子样本dj(j=1,2,…,n);针对每个子样本dj,构建决策树模型hj(x)(一般选用cart决策树),最终获得由一组决策树{h1(x),h2(x),…,hk(x)}组成的决策树分类器;对于一个新的测试样本,通过n个决策树投票,得到最多票数的类别作为测试样本的最终类别,分类决策如下:
其中,hj(x)代表第j棵决策树,i(·)为示性函数,即当集合内有此数时值为1,否则值为0;y表示类别标签yi构成的目标变量。
具体实施方式六:本实施方式是对具体实施方式二的进一步说明,本实施方式与具体实施方式二的区别是所述步骤二二中α=0.5。
需要注意的是,具体实施方式仅仅是对本发明技术方案的解释和说明,不能以此限定权利保护范围。凡根据本发明权利要求书和说明书所做的仅仅是局部改变的,仍应落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!