一种改进团队进步算法的近红外光谱波长筛选方法与流程
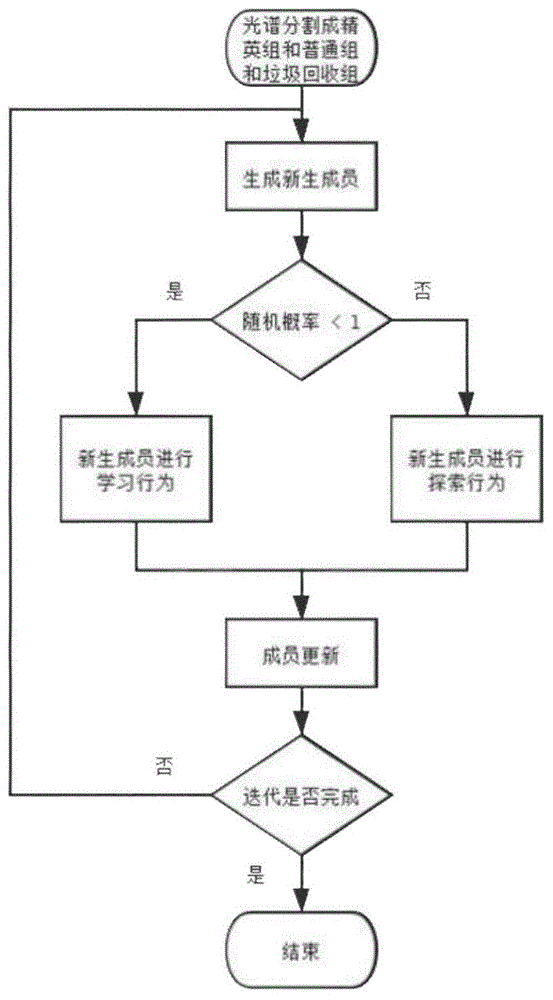
本发明涉及近红外光谱检测领域,具体涉及一种改进团队进步算法的近红外光谱波长筛选方法。
背景技术:
随着我国综合实力的大幅提升,人们对于产品品质的要求越来越高,其中包括水果、农作物、食品等。在工业过程检测领域中,需要检测油类,化学物品等成分质量,不仅要求检测技术快速无损,而且还追求检测精度。城市化的不断提升,对更加精确方便的检测技术的需求与目前比较落后的检测技术水平之间的矛盾愈发升级。在众多应用背景下,近红外光谱分析技术应声而出。
近红外光谱分析技术作为一种测试在线分析技术,具有分析速度快、效率高、成本低以及无损检测的优势,已经扩展到石油化工、制药、临床医学以及食品工业等众多领域。近红外光谱分析技术主要分为三大部分,光谱的预处理、波长筛选和模型建立。近红外光谱分析技术最重要的一个步骤便是筛选波长变量。近红外光谱分析技术一般情况都伴有大量的光谱数据,少则几百,多则上千,往往导致检测模型数据量过大预测效果不明显。对采集到的光谱数据进行波长筛选可以大大减小预测模型,有效防止预测模型出现过拟合现象,加快预测速度,增强模型的鲁棒性,同时也能提升预测准确率,对近红外光谱分析技术的发展有着举足轻重的作用。
现有的波长筛选算法主要有主成分分析(pca)、联合区间偏最小二乘法(sipls)、团队进步算法(tpa)、无信息变量消除法(uve)、遗传算法(ga)等。pca是一个降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量。将pca应用在光谱筛选中虽然能够筛选出极少量波长,有效较低模型体量,但同时也筛选掉了不少有效变量信息,导致预测准确度不够。ga算法是一种模拟自然进化过程搜索最优解的方法,将问题的求解转换成类似生物进化中的染色体基因的交叉、变异、复制等过程。在波长筛选过程中,将光谱数据看作染色体,将光谱数据分成若干个光谱段,每一个波段对应染色体上的一个基因,按照0-1形式进行编码,1表示选中该波段,0表示未选中,自定义原始种群的大小进行迭代进化,并选出最优个体。ga算法在求解较为复杂的组合优化问题时,如光谱波长筛选中,通常能够较快地获得较好的优化结果,但一般只能筛选出近乎一半的波长变量,对于一些计算模型级别低的场景并不适用。章海亮等(章海亮,罗微,刘雪梅,何勇.应用遗传算法结合连续投影算法近红外光谱检测土壤有机质研究[j].光谱学与光谱分析,2017,37(2):584-587.)提出遗传算法结合连续投影算法,用ga算法对光谱变量进行筛选之后,再用连续投影算法对光谱波长进行进一步筛选。最终筛选出18个变量进行建模。同时由于ga缺乏群体的多样性,在实际应用中容易产生早熟收敛,赵鑫等(xinzhao,qibingzhu,minhuang,haiyancen.aniga-plspmethodforft-nirwavelengthselectionformeasuringsolublesolidcontentofcitrusfruits[j].analyticalmethods,2013,5(18):4811-4817.)提出iga优选谱区结合偏最小二乘投影法(plsp),iga将生物免疫机制引入到标准遗传算法中,克服了ga的早熟缺陷,具有较快的收敛速度。同时在iga之后进行plsp对波长变量进一步筛选,克服了子区间变量冗余。双算法结合虽然筛选变量效果不错,但大大增大了工作量。薄亚明(多维函数全局寻优的团队进步算法[j].南京邮电大学学报(自然科学版),2008,28(5):7-14.)提出的tpa是一种双群体搜索算法,模仿一个团队的两个小组团队合作行为,将光谱变量分成若干个波段,波段跟对应的理化值建模的结果作为评价值指标,根据评价值将波段分为精英组跟普通组,再进行相应的学习和探索过程,并设计合理的波段更新规则更新波段,逐步提升其评价值以达到全局最优。tpa算法较ga算法简洁很多,同时筛选出来的波长数目极少,但预测精度稍有不及。
技术实现要素:
[技术问题]
现有的近红外光谱波长筛选检测模型筛选的波长数量过大且预测精度低。
[技术方案]
本发明提供一种改进团队进步算法的近红外光谱波长筛选方法,包括:
步骤一:将需筛选的近红外光谱波段均分为p个波段,每个波段包括多个波长点,所述p个波段都为itpa算法模型中的成员,并确定p个波段中每个波段的评价值;
步骤二:按照评价值的从高到低,将p个波段值分为n个精英组、m个普通组和l个垃圾回收组,n、m和l分别为整数;
步骤三:选择在精英组或普通组中产生新生波段,所述新生波段的波长点从选择组中的随机一条波段中选择波长点,新生波段的波长点继承该被选择的波长点;
步骤四:继承下来的新生波段通过设定概率选择一次学习行为或者探索行为以更新自身的波长点,生成候选波段,所述选择学习行为和探索行为概率之和为100%;
步骤五:进行候选波段的更新;包括:将候选波段的评价值分别与精英组、普通组、垃圾回收组中的波段值进行比较来确定候选波段进入精英组或普通组或垃圾回收组;
步骤六:自定义迭代更新次数,迭代结束之后,选取精英组中评价值最高的波段作为所要筛选的波段。
在本发明的一种实施方式中,所述itpa算法模型为:
式中,向量x代表一个成员,即为包含多个波长的波段;x1-xn表示该波段的所有波长点,xi表示该波段中的第i个波长点,bi和ai分别表示该波长点的上、下边界值,函数f(x)代表该条波段的评价值。
在本发明的一种实施方式中,所述评价值f(x)即以该波段x与测得的含量理化值进行pls建模得到的校正均方根误差(rmsec)和相关系数(r)为变量的函数值,所述评价值为
通过更新波段x以逐步提升或降低评价值来寻求最优波段。
在本发明的一种实施方式中,所述学习行为包括:新生波段xr向参照目标方向调节,所述新生波段xr产生于普通组或精英组,产生于普通组或精英组的新生波段的参照方向分别产生于精英组和垃圾回收组的样板值,所述样板值包括:精英组样板ee和垃圾回收组样板el;所述样板值取所在组波段波长的平均值;普通组或精英组中生成的新生波段xr在选择学习行为时分别为:
xc=(1-γ)xr+γee(3)
xc=(1+γ)xr-γel(4)
式中,γ为区间[0,1]内随机数,xc为候选波段。
在本发明的一种实施方式中,所述新生波段经过探索行为生成候选波段为:
式中,t为矩阵转置符号,xri为新生波段对应的波长,即该波段的第i个波长,i=1,2,...,n;k为算法最大迭代次数,k表示当前累计的迭代次数;收缩指数ae,p表示当新生波段继承自精英组时选取ae,当新生波段继承自普通组时选取ap;γi是区间(0,1)的随机数,mi随机在0,1二值间取值。
在本发明的一种实施方式中,在步骤一之前,对近红外光谱数据样本进行异常点剔除及样本集划分,包括:用马氏距离剔除光谱中异常数据,剔除光谱中异常数据后,采用k-s法将剩余的样本点分成校正集和预测集。
在本发明的一种实施方式中,所述进行候选波段的更新包括:
1、若候选波段xc的评价值高于精英组末位xewst的评价值,所述xewst为精英组中评价值最低的波段;则xc进入精英组,精英组末位xewst不进入普通组直接淘汰;
2、若候选波段xc的评价值劣于xewst但优于普通组末位xpwst,还需检查xc是否由探索得到,若是,则xc进入普通组,淘汰xpwst。若不是,直接丢弃xc;
3、若候选波段xc的评价值低于垃圾回收组首位xlbst的评价值,所述xlbst为垃圾回收组中评价值最高的波段,则xc进入垃圾回收组,同时垃圾回收组中的xlbst波段遭到淘汰,促使垃圾回收组评价值一直保持低的状态,为继承于精英组的新生波段进行学习行为时提供一个正确的更新方向,每次波段更新完毕,对三组进行评价值排序。
在本发明的一种实施方式中,新生波段继承自普通组的收缩指数为继承自精英组的一半。
在本发明的一种实施方式中,新生成员选择学习行为的概率为0.35,选择探索行为的概率为0.65。
本发明的一种改进团队进步算法的近红外光谱波长筛选方法应用于农作物的无损检测。
[有益效果]
1、本发明提供的一种itpa算法的波长筛选算法,将近红外光谱波段值按照评价值的从高到低分为精英组、普通组和垃圾回收组;本发明中的新生波段产生于精英组,本发明不同于传统的tpa算法向普通组样板的反方向调节,而是向垃圾回收组样板的反方向调节,因为普通组样板在迭代过程中评价值有所上升,后期并不能提供一个良好调节方向,而垃圾回收组样板评价值在整个过程中都是处于低的状态,能有效的为产生于普通组的新生波段提供一个良好的调节方向。从而在保证了模型预测准确度的情况下,大大减少了波长变量数,同时降低了算法的复杂程度,并且提高了农作物(如玉米)中的无损检测的检测精度。
附图说明
图1是本发明所述itpa算法筛选波长流程示意图;
图2是各个数据样本点到数据中心点的马氏距离分布图;
图3是剔除异常样本之后的原始光谱图;
图4是itpa算法在迭代的过程中,精英组最优波段的评价值示意图;
图5是ga,tpa,itpa算法分别对光谱数据进行波长筛选,测试50次的预测均方根误差值示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步详细说明。
实施例1
如图1所示,本实施例提出一种改进团队进步算法的近红外光谱波长筛选方法,并将其应用于一组标准玉米近红外光谱数据集。该光谱数据集引用自eigenvector网站上开源的玉米样本光谱数据集,地址https://eigenvector.com/resources/data-sets/。该数据集包括80个玉米样品,分别用三台光谱仪器测得(m5,mp5,mp6)。波长范围为1100-2498nm,间隔为2nm(700变量),包括每个样品的水分、油、蛋白质和淀粉值。这些数据最初是在cargill公司采集的。本次实验数据采用该数据集中用设备mp5所采集到的样本数据以及对应的蛋白质含量值。
所述方法包括:
步骤一:异常点剔除及样本集划分。考虑到仪器测量光谱数据时产生误差而得到异常光谱,会影响模型性能,故先用马氏距离剔除光谱中异常数据。图2为各个数据样本点到数据中心点的马氏距离分布图。图3为剔除异常样本之后的原始光谱图。采用k-s法将剩余的78个样本点分成校正集和预测集。划分结果为校正集样本50个,预测集样本为28个。校正集和预测集蛋白质含量值统计如表1。
表1校正集和预测集蛋白质含量值(单位g,每100g玉米中的含量)
步骤二:设定itpa算法相关参数。itpa是一种双群体搜索算法,模仿一个团队的三个小组,精英组、普通组和垃圾回收组的学习和探索过程,并设计合理的成员更新规则,逐步提升其评价值以达到全局最优。算法模型可表示为
式中,向量x代表一个成员,相当于包含多个波长的波段。x1-xn表示该波段的所有波长点,xi表示该波段中的第i个波长点,bi和ai分别表示该波长点的上、下边界值,函数f(x)代表该条波段的评价值,评价值即以该波段与测得的含量理化值进行pls建模得到的校正均方根误差(rmsec)和相关系数(r)为变量的函数值,设定评价值为
通过更新波段以逐步提升或降低评价值来寻求最优波段。
步骤三:将整条光谱波段(样本集划分之后的校正集)均分为p个波段并同时确定其评价值,每一个波段就相当于步骤二中的向量x。将p个波段按评价值从大到小排列分成n+m+l个波段,n、m和l分别为整数,前n个评价值最高的波段组成为精英组,xe表示精英组中的波段,其中标号1,2,...n表示第几个波段,一共n个;后m个评价值适中的波段组成为普通组,xp表示普通组中的波段,其中1,2,...m表示第几个波段,一共m个;最后l个评价值最低的波段组成垃圾回收组,xl表示垃圾回收组中的波段,其中1,2,...l表示第几个波段,一共l个;垃圾回收组该改进算法新增的小组,保持该小组在整个迭代过程中评价值处于极低的状态。所述n、m和l一般按照经验取值,n、m和l的数值之间不能相差过大。
本实施例设定总成员个数为35个,即p=35;对每个波段与蛋白质理化值进行pls建模会得到该波段对应的评价值,其中精英组个数为10个,普通组个数为10个,垃圾回收组个数15个。
步骤四:产生一条新生波段xr。所述产生方法为:新生波段从精英组和普通组两组任意一组产生,所述新生波段的波长点从当前组随机波段同一波长点中继承;即新生波段如果出身自精英组,且该新生波段的第n个波长点如果是在精英组第m个波段中产生,那么该波长点需继承精英组第m个波段中第n个波长点。
步骤五:继承下来的新生波段xr需通过设定概率l选择一次学习行为或者探索行为以更新自身的波长点,才能成为候选波段xc,所述选择学习行为和探索行为概率的和为100%。本实施例设定新生成员(新生波段xr)选择学习行为的概率l为0.35,即选择探索行为的概率为0.65。
学习行为:
新生波段xr如果进行学习行为,则需要向参照目标方向调节。参照方向分别产生于精英组和垃圾回收组的样板值,称为精英组样板ee和垃圾回收组样板el;所述样板值取所在组波段波长的平均值。若新生波段产生于普通组,则其需向精英组样板调节。若新生波段产生于精英组,该算法不同于tpa算法向普通组样板的反方向调节,而是向垃圾回收组样板的反方向调节,因为普通组样板在迭代过程中评价值有所上升,后期并不能提供一个良好调节方向,而垃圾回收组样板评价值在整个过程中都是处于低的状态,能有效的为产生于普通组的新生波段xr提供一个良好的调节方向,普通组或精英组中生成的新生波段xr在选择学习行为时分别为:
xc=(1-γ)xr+γee(3)
xc=(1+γ)xr-γel(4)
式中,γ为区间[0,1]内随机数。若xc某个波长点越界,则改用其边界值。本实施例设定的近红外光谱波长范围是1100-2498nm,边界值即为1100nm和2498nm。
探索行为:
新生波段xr如果进行探索行为,则其各波长点xi(i=1,2,...,n)将做随机改变,并且探索强度逐步减小。两组新生波段xr经过探索行为生成xc的表达式可写为:
式中,xri为新生波段对应的波长,即该波段的第i个波长;k为算法最大迭代次数,k表示当前累计的迭代次数;收缩指数ae,p表示当新生波段继承自精英组时选取ae,当新生波段继承自普通组时选取ap。γi是区间(0,1)的随机数,mi为0,1二值随机整数。本实施例设置精英组收缩指数为20,普通组收缩指数一般为精英组的一半,取10。
步骤六:进行成员(候选)波段的更新。包括:
6.1若候选波段xc的评价值高于精英组末位xewst的评价值,所述xewst为精英组中评价值最低的波段;则xc进入精英组,同时精英组再次进行评价值排序,精英组末位xewst不进入普通组直接淘汰。这是因为tpa设置了学习行为,加强了算法的定向搜索和局部搜索能力,遭到淘汰的精英组末位xewst如果进入普通组的话容易导致算法陷入局部最优。
6.2若候选波段xc的评价值劣于xewst但优于普通组末位xpwst,还需检查xc是否由探索得到,若是,则xc进入普通组,淘汰xpwst;若不是,直接丢弃xc。这是因为学习行为产生高评价值候选成员的可能性比较大,且趋同性强,容易导致普通组波段同化,降低全局寻优能力。
6.3若候选波段xc的评价值低于垃圾回收组首位xlbst的评价值,所述xlbst为垃圾回收组中评价值最高的波段,则xc进入垃圾回收组,同时垃圾回收组中的xlbst波段遭到淘汰,促使垃圾回收组评价值一直保持低的状态,为继承于精英组的新生波段进行学习行为时提供一个较为正确的更新方向。
步骤七:自定义迭代更新次数。本实施例设定迭代次数为1000次,迭代结束之后,选取精英组中评价值最高的波段作为我们所要筛选的波段对象。
实施例2
为考察实施例1提出的变量筛选算法对建模预测的效果,设定总成员个数为35个,其中精英组个数为10个,普通组个数为10个,垃圾回收组个数15个。设定新生成员选择学习的概率l为0.35,即选择探索行为的概率为0.65。精英组收缩指数为20,普通组收缩指数一般为精英组的一半为10。设定迭代次数为1000次。图4显示的是算法在迭代的过程中,精英组最优波段的评价值。
用经典的近红外光谱波长筛选算法遗传算法(ga)、主成分分析(pca)、团队进步算法(tpa)与本文提出的改进团队进步算法(itpa)做筛选变量建模效果比较。进行ga算法时,将原光谱均分若干个子区间,进化迭代获取最大适应度值所对应的优选子区间组合。根据基因选出的波段建立pls模型,计算出模型的r和rmsec值,适应度函数f与公式(2)的评价值函数f(x)保持一致为
将原光谱共700个波长点数划分35个等距区间,即遗传编码长度为35,每一个基因包含20个波长点数。设定群体个数为50个,交叉概率为0.85,变异概率为0.1,最大迭代数为200代。在种群进化过程中寻找最大迭代次数内进化过程中最优适应度个体。由于ga算法、tpa算法和itpa算法具有随机性,因此将以上三种算法分别运行50次求平均。
图5为ga、tpa、itpa算法分别对光谱数据进行波长筛选,测试50次的预测均方根误差值。由图可得,itpa算法较原tpa算法预测精度有所提升,稍逊于ga算法,但是经itpa算法筛选过后的变量数目远远小于ga算法。
将原光谱进行pca降维筛选波长变量,筛选贡献率为前20的变量。计算得前20变量的累积贡献率已达0.999997。将此20个变量与蛋白质含量进行pls建模并求出相关预测值。
分析数据。从表2可得,itpa算法预测均方根误差rmsep为0.1177,预测相关系数rp为0.9704,校正均方根误差rmsec为0.1019,校正相关系数rc为0.9759,预测效果比全谱pls和tpa算法都有提升,全谱pls的预测均方根误差rmsep为0.1789,tpa算法的预测均方根误差rmsep为0.1193。ga算法总体预测效果最佳,但其筛选出来的平均波长点数高达346个,远远大于itpa,为19.60个。通过对原光谱进行主成分分析(pca),筛选出20个波长点(贡献率已达0.999997),以此跟筛选出近乎相同波长数的itpa算法作比较。经pca算法筛选波长之后得到的模型预测均方根误差rmsep为0.2306,远远大于itpa算法。因此,itpa算法能在保持预测能力的前提下能大幅度削减波长点数,有效的减小建模的计算量。
表2算法比较
本发明的保护范围并不仅局限于上述实施例,凡是在本发明构思的精神和原则之内,本领域的专业人员能够做出的任何修改、等同替换和改进等均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!