基于深度学习的葡萄糖度无损检测方法
1.本发明涉及水果品质检测领域,尤其涉及一种基于深度学习的葡萄糖度无损检测方法;具体地说是结合了深度学习方法,涉及了一种任意葡萄图像,检测出整串葡萄的糖度值,实现葡萄无损检测。
背景技术:
2.利用计算机视觉技术实现农产品内部品质无损检测是目前国际上正在研究的热点课题,为探索对葡萄内部、外部多个指标进行无损检测的提供了可行性,大量检索相关文献,目前已有相关研究基于可见光rgb图像,利用计算机视觉方法对各种农产品或食品的内外品质指标进行精确评估预测。
3.现阶段的无损检测技术主要是基于近红外高光谱技术和传统计算机视觉技术。传统方法检测指标单一,特征提取工作繁琐,对不同的任务需要进行针对性的特征提取。为进一步提高无损检测的精度和效率,满足生产生活需求,急需一种能够实现对整串葡萄进行无损检测的方法。
4.本发明利用手机采集图像,采集图像方式方便快捷。在数据预处理阶段,本发明提出了基于图像分割的数据预处理方法,可以减少图像噪声对模型训练的干扰,因此图像可在任意背景下通过手机拍摄得到。本发明采用迁移学习方法和深度自注意力网络方法。迁移学习方法是基于在大型可视化数据库上训练得到的模型来提取图像特征,具有很好的提取葡萄图像特征的效果,在糖度训练模型中能够得到更好的葡萄糖度预测效果。深度自注意力网络基于自注意力机制由多编码器组成的网络,在视觉领域能够取得很好的性能。
技术实现要素:
5.本发明的目的就在于克服现有技术存在缺点和不足,提供一种基于深度学习的葡萄糖度无损检测方法;将深度学习技术应用于葡萄糖度检测,实现精确的检测葡萄内部糖度信息。
6.本发明采用以下技术方案:
7.本发明提出了基于深度学习的葡萄糖度检测方法,结合标注的糖度信息,训练深度学习模型,以此来预测整串葡萄的糖度信息。本发明提出了图像分割的预处理方法,使得在构建葡萄数据时不限制于某个特定场景,实现了能够在任意场景采集的葡萄图片,同时提出了基于不同糖度区间步长的方法,以及模型集成的方法,有利于结合不同模型的优势,使得集成模型取得更好的效果,同时在训练模型时结合分类与回归的思想,采用了基于传统的回归模型损失函数的平方差损失,基于传统的分类模型的交叉熵损失作为辅助来共同构建一个新的损失函数。
8.1、研究对象
9.本发明以葡萄为研究对象,从本地超市或网购的方式购买不同类别的葡萄,以及直接去种植基地购买的葡萄。
10.2、深度学习方法
11.建立基于深度学习的回归模型,将构建的葡萄数据集输入深度学习模型进行训练。如图1,本方法工作流程如下:
12.①
构建葡萄数据集
13.a、使用手机拍摄葡萄
14.从超市购买的葡萄置于一采光良好且带有悬挂点的背景上用手机进行拍摄,或使用手机直接拍摄果园里的葡萄;
15.b、测量糖度
16.一面葡萄拍摄完毕后,选取该面4
‑
5颗葡萄逐颗测量得到糖度值,最终取平均值保留小数点后两位作为该串葡萄这一面的标签值;
17.②
划分糖度区间
18.根据糖度区间步长的不同,将糖度区间步长设置为0.4、0.6、0.8、1;
19.③
图像分割
20.将采集到的图片进行分割处理,只留下葡萄部分,图片其余部分红绿蓝向量均为0;
21.④
数据扩增
22.为了获得更多的数据,对现有数据集进行微小的改变,具体按以下方法:
23.a、缩放:将图像向外或向内缩放,向外缩放时最终图像尺寸将大于原始图像尺寸,向内缩放会缩小图像大小;
24.b、旋转:将图像旋转任意角度;
25.⑤
构建深度学习模型
26.将构建的数据集输入深度学习模型进行训练,葡萄糖度预测回归模型的模型架构如图2,其骨干网络为基于迁移学习的网络或深度自注意力网络;
27.⑥
分类回归汇聚
28.模型输出层采用一种多项逻辑斯特回归汇聚的方法,即利用多项逻辑斯特回归分类的中间结果与基于分类区间步长的所得的每一类的标签值相乘,得到具体糖度值,使用均方误差和交叉熵结合的方式作为模型的损失函数;
29.⑦
模型集成
30.如图3,根据网络框架的不同、糖度划分区间步长的不同,选出基于葡萄测试数据集效果最好的前5组模型来进行模型集成;
31.⑧
模型测试
32.集成好的模型以任意葡萄图像作为输入,模型输出即该串葡萄的糖度结果。
33.本发明具有下列优点和积极效果:
34.①
建立了一种全新的基于深度学习的葡萄糖度检测模型,深度学习算法相对于传统的算法,能够进行自我学习,模型的预测能力更强;
35.②
可保证水果样本的完整性,实现糖度无损检测。
附图说明
36.图1是本方法的工作流程图,图中:
37.11—构建葡萄数据集;
38.111—使用手机拍摄葡萄;
39.112—测量糖度;
40.12—划分糖度区间;
41.13—图像分割;
42.14—数据扩增;
43.141—缩放;
44.142—旋转;
45.15—构建深度学习模型;
46.16—分类回归汇聚;
47.17—模型集成;
48.18—模型测试。
49.图2是模型架构的方框图,图中:
50.21—葡萄数据集;
51.22—深度学习模型;
52.221—基于迁移学习的卷积神经网络;
53.222—深度自注意力网络;
54.23—葡萄糖度预测结果。
55.图3是模型集成原理图,图中:31—5个最优模型;
56.311—第1模型;
57.312—第2模型;
58.313—第3模型;
59.314—第4模型;
60.315—第5模型;
61.32—集成算法;
62.321—平均法;
63.322—随机森林;
64.323—堆叠法;
65.324—提升法。
66.33—基于集成的深度学习模型。
67.图4是构建葡萄数据集图片,图中:
68.4a—实验室采集图;
69.4b—果园中手机拍摄图;
70.4c—糖度检测仪;
71.4d—构建完整的葡萄数据示例。
72.图5是糖度划分图,图中:51—基于糖度区间步长为0.4的数据集划分结果;
73.52—基于糖度区间步长为0.6的数据集划分结果;
74.53—基于糖度区间步长为0.8的数据集划分结果;
75.54—基于糖度区间步长为1的数据集划分结果。
76.图6是图像分割示例图片,图中:
77.61—实验室采集图;
78.62—语义分割模型;
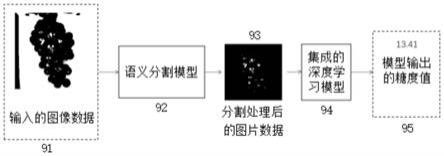
79.63—分割处理后的图片。
80.图7是图像扩增图片,图中:
81.7a—缩放;
82.7b—旋转。
83.图8是分类回归汇聚原理图,图中:
84.81—输入图像;
85.82—深度学习模型;
86.821—深度学习模型网络;
87.822—模型输出结果;
88.83—向量相乘;
89.84—图片分类标签值向量;
90.85—糖度结果。
91.图9是模型测试图,图中:
92.91—输入的图像数据;
93.92—语义分割模型;
94.93—分割处理后的图片数据;
95.94—集成的深度学习模型;
96.95—模型输出的糖度值。
具体实施方式
97.下面结合附图和实施例详细说明:1,本方法的工作流程
98.如图1,本方法的工作流程是:
99.①
构建葡萄数据集
‑
11,
100.a、使用手机拍摄葡萄
‑
111,
101.b、测量糖度
‑
112;
102.②
划分糖度区间
‑
12;
103.③
图像分割
‑
13;
104.④
数据扩增
‑
14,
105.a、缩放
‑
141,
106.b、旋转
‑
142;
107.⑤
构建深度学习模型
‑
15;
108.⑥
分类回归汇聚
‑
16;
109.⑦
模型集成
‑
17;
110.⑧
模型测试
‑
18。
111.2,深度学习的糖度预测模型
112.如图2,深度学习的糖度预测模型是:
[0113]ⅰ、葡萄数据集21;
[0114]ⅱ、深度学习模型22;
[0115]
ⅰ
、基于迁移学习的卷积神经网络221;
[0116]
ⅱ
、深度自注意力网络222;
[0117]ⅲ、葡萄糖度预测结果23。
[0118]
将构建的深度学习的糖度预测模型进行训练,深度学习的糖度预测模型其骨干网络为基于迁移学习的卷积神经网络221和深度自注意力网络222;
[0119]
基于迁移学习的卷积神经网络221是一种在大型可视化数据库上预训练完成的模型,具有较好的提取葡萄图像特征的能力。
[0120]
深度自注意力网络222是一种基于自注意力机制由多编码器组成的网络,在视觉领域能够取得很好的性能;还具有良好的全局特性,能够打破卷积神经网络卷积算子感受野的局限问题,能够扩大网络的关注区域;有更好的多模态融合能力和表征能力,使得在图像领域有较好的效果。
[0121]
3,模型集成
[0122]
如图3,模型集成包括依次交互的五个最优模型31、集成算法32和基于集成的深度学习模型33;
[0123]
五个最优模型31包括第1模型311、第2模型312、第3模型313、第4模型314、第5模型315;
[0124]
集成算法32包括平均法321、随机森林322、堆叠法323和提升法324。
[0125]
根据网络框架的不同和糖度划分区间步长的不同,选出基于葡萄测试数据集效果最好的五个最优模型31来进行模型集成,基于每一个模型的优势,进行模型集成能够集合每一个模型的优势,从而使模型获得更高的准确率;集成算法32包括平均法321、随机森林322、堆叠法323和提升法324。
[0126]
4,构建葡萄数据集
[0127]
如图4,从左到右,依次排列有实验室采集图4a、果园中手机拍摄图4b、糖度检测仪4c、构建完成的葡萄数据示例4d。
[0128]
图4a为在超市购买于实验室拍摄的图,是将葡萄悬挂在带有悬挂点的背景上用手机进行拍摄所得;图4b是在果园拍摄的葡萄图像,一面葡萄拍摄完毕后,选取该面4
‑
5颗葡萄;使用图4c的糖度检测仪逐颗测量得到糖度值,最终取平均值保留小数点后两位作为该串葡萄这一面的标签值。如图4d,构建的完整的葡萄图像包括图像和标签两部分组成,标签中以空格为分界符,第一个空格前的数据为测量所得的糖度值,其余部分为标识符以标记不同图像数据。
[0129]
5,将图片数据按照糖度区间分类
[0130]
如图5,由于葡萄数据集呈长尾分布,即糖度值偏大和偏小的葡萄数据少,糖度值处于中间值的葡萄数据多。处理的标准数据通常都有一个基本假设,即该数据集各类别对应的样本数量是近似服从均匀分布的,即类别平衡,我们根据葡萄糖度值分布范围,将两端数据各自归为一类,使数据更加平衡。如图5按照步长为0.4、0.6、0.8、1.0的跨度区间来划分葡葡萄数据集。
[0131]
6,图像分割
[0132]
如图6,将采集到的图片进行分割处理,只留下葡萄部分,图片其余部分红绿蓝分量均为0,这里采用语义分割网络模型,分割后的结果如图6所示:
[0133]
实验室采集图61、语义分割模型62和分割处理后的图片63。
[0134]
7,图像扩增
[0135]
如图7,为了获得更多的数据,对现有数据集进行微小的改变,具体按以下方法:
[0136]
a、缩放比例:将图像向外或向内缩放,向外缩放时最终图像尺寸将大于原始图像尺寸,向内缩放会缩小图像大小,处理后的图如图7a所示。
[0137]
b、旋转:将图像旋转任意角度,处理后的图如图7b所示。
[0138]
8,分类回归汇聚
[0139]
如图8,分类回归汇聚包括依次交互的输入图像81、深度学习模型82、深度学习模型网络821、模型输出结果822、向量相乘83、图片分类标签值向量84和糖度结果85。
[0140]
模型输出层采用一种分类回归汇聚,即一种多项逻辑斯特回归汇聚的方法,即利用多项逻辑斯特回归方法的中间结果与糖度分类得到的标签值相乘,得到具体糖度。本方法是基于分类网络得到每一类的概率值再与每一类的标签值相乘得到最终结果的,损失函数同时采用了平方差损失和交叉熵损失,使得在训练网络模型时,使损失更快的向下收敛,使网络模型训练时间缩短。
[0141]
图8采用了基于糖度划分区间步长为1的数据分类划分方法,由于基于糖度划分区间步长为1的方式划分数据,可将数据分为六类,即葡萄图像输入深度学习模型后可得到一行六列的向量,将其当前的分类标签值组成六行一列的向量,两向量相乘的结果即为糖度结果。
[0142]
9,模型测试
[0143]
如图9,模型测试的流程包括依次交互的输入的图像数据91、语义分割模型92、分割处理后的图片数据93、集成的深度学习模型94和模型输出的糖度值95。
[0144]
训练好的模型以任意葡萄的图像数据91作为输入,将图像数据91输入语义分割模型92,得到去除背景后的葡萄图像即分割处理后的图片数据93,再将其作为集成的深度学习模型94的输入数据,最后即可得到模型输出的糖度值95。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1