一种基于神经网络的钻井液含砂量的测量方法和设备
1.本发明涉及神经网络技术领域,具体涉及一种基于神经网络的钻井液含砂量的测量方法和设备。
背景技术:
2.钻井液的主要功用是悬排钻渣、保护井壁、冷却钻头和润滑钻具,钻井液性能的变化会直接影响机械钻速、钻头寿命、孔壁稳定、孔内净化等,钻井液中的无用固相含量过高会使钻井液的流变特性变坏,流态变差,引起上下钻阻卡,压力激动等事故的发生。此外,对管材、钻头、水泵缸套、活塞拉杆的磨损也会变大,缩短使用寿命。因此实现现场钻井液含砂量的在线检测,按需实时优化钻井液性能至关重要。
3.现阶段钻井液密度、粘度等参数的检测都已经有了成熟的在线检测设备,国外现有的钻井液流变性能的在线检测装置主要分为两类,一种是由saasen a等人对原有的六速粘度计进行改造设计的在线六速粘度计,另一种是由vajargah a k等人设计的可以测量钻井液流变指数的管道流变仪。但对于钻井液中的含砂量的自动检测依旧停留在手动检测的阶段,耗时长,实时性差且精度不高。
技术实现要素:
4.本发明解决的一个主要问题是现有的钻井液含砂量的检测方法不够智能,耗时长,实时性差且精度不高。提出一种基于人工神经网络(artificial neural network,ann)的在线数据驱动传感器来预估钻井液的含砂量。
5.根据本发明的一个方面,本发明提供一种基于神经网络的钻井液含砂量的测量方法,包括:
6.采集泥浆的性能参数;
7.筛选分析所述泥浆的性能参数,根据所述性能参数计算获得赫谢尔-巴尔克莱三参数,将所述筛选分析后的性能参数和赫谢尔-巴尔克莱三参数作为输入参数;
8.对所述输入参数进行数据扩展和划分,得到训练集、验证集和测试集;
9.构建ann神经网络模型,利用训练集和验证集迭代训练并验证所述ann神经网络模型;
10.利用测试集评估训练后的所述ann神经网络模型的预测效果,利用满足预设预测效果的所述ann神经网络模型测量钻井液的含砂量。
11.进一步地,筛选分析所述泥浆的性能参数,获得输入参数包括:
12.采集多组不同含砂量的泥浆的密度、马氏漏斗粘度、旋转粘度和含砂量;
13.剔除所述密度、马氏漏斗粘度、旋转粘度、和含砂量中的异常数据;
14.利用剔除异常数据后的旋转粘度计算赫谢尔-巴尔克莱三参数、表观粘度和塑性粘度;
15.将剔除异常数据后的密度、马氏漏斗粘度、旋转粘度、赫谢尔-巴尔克莱三参数、表
观粘度和塑性粘度作为输入参数,将剔除异常数据后的含砂量作为输出参数。
16.进一步地,对所述输入参数进行数据扩展和划分,得到训练集、验证集和测试集包括:
17.对剔除异常数据后的所述密度、马氏漏斗粘度、旋转粘度、含砂量和赫谢尔-巴尔克莱三参数分别利用三次样条法进行插值扩展,获得对应的扩展数据;
18.将对应的所述扩展数据分别划分为训练集、验证集和测试集。
19.进一步地,利用剔除异常数据后的旋转粘度计算赫谢尔-巴尔克莱三参数包括步骤:
20.基于剔除异常数据后的旋转粘度,利用公式一计算赫谢尔-巴尔克莱三参数流变模型的动切力τy,公式一为:
21.τy=0.511θ322.其中,θ3为旋转粘度计3r/min时测得的刻度盘读数;
23.基于剔除异常数据后的旋转粘度,利用公式二计算赫谢尔-巴尔克莱三参数流变模型的流体行为指数n,公式二为:
24.n=3.322lg[(θ
600-θ3)/(θ
300-θ3)]
[0025]
其中,θ
600
和θ
300
分别为旋转粘度计测得的600r/min和300r/min时的读数;
[0026]
基于剔除异常数据后的旋转粘度,利用公式三计算赫谢尔-巴尔克莱三参数流变模型的流体稠度k,公式三为:
[0027]
k=0.511(θ
300-θ3)/511n。
[0028]
进一步地,构建ann神经网络模型,利用训练集和验证集迭代训练所述ann神经网络模型包括:
[0029]
构建基于钻井液粘度的ann神经网络模型和基于赫谢尔-巴尔克莱三参数流变模式的ann神经网络模型;
[0030]
将基于剔除异常数据后的所述密度、所述马氏漏斗粘度和所述旋转粘度,以及基于所述表观粘度和所述塑性粘度划分的所述训练集和所述验证集,输入所述基于钻井液粘度的ann神经网络模型进行迭代训练并验证训练效果;
[0031]
将基于剔除异常数据后的所述密度、所述马氏漏斗粘度和所述旋转粘度,以及基于所述赫谢尔-巴尔克莱三参数划分的所述训练集和所述验证集,输入所述基于赫谢尔-巴尔克莱三参数流变模式的ann神经网络模型进行迭代训练并验证训练效果。
[0032]
进一步地,利用训练集和验证集迭代训练所述ann神经网络模型包括:
[0033]
在模型训练时,还利用编程方法生成训练噪音,模拟钻进过程中的环境因素对采集数据的干扰。
[0034]
进一步地,利用测试集评估训练后的所述神经网络模型的预测效果,包括:
[0035]
输入所述测试集,以预设的预估误差和相关系数为标准评价训练完成后的所述ann神经网络模型的预测性能。
[0036]
进一步地,利用测试集评估训练后的所述神经网络模型的预测效果,利用满足预设预测效果的所述神经网络模型测量钻井液的含砂量,还包括:
[0037]
当训练完成后的所述ann神经网络模型的预估误差满足阈值范围,且相关系数满足预设阈值时,利用满足条件的所述神经网络模型测量钻井液的含砂量。
[0038]
根据本发明的另一个方面,还公开一种基于神经网络的钻井液含砂量的测量设备,所述测量设备包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于神经网络的钻井液含砂量的测量方法,所述基于神经网络的钻井液含砂量的测量程序被所述处理器执行时实现如前任一项所述的基于神经网络的钻井液含砂量的测量方法的步骤。
[0039]
本发明运用交叉学科的思想,将自动化的方法融入到钻井液的含砂量检测过程中,提高检测效率,从而最大程度避免井塌等钻井事故的发生。通过对待测泥浆搅拌并水化相同的时间,剔除错误数据等,达到提高模型精度的目的。利用三次样条法插值,对有限的少量已有数据进行扩展,以满足人工神经网络训练模型学习的需求。针对两种泥浆粘度的在线检测装置,设计了两种神经网络模型,模型的输入分别对应的是两种装置的输出参数,增加了模型的实用性。在钻进过程中实时采集的数据会受到周围环境的干扰,数据会携带噪声,在训练神经网络时,用编程的方法模拟生成训练噪声,增加了神经网络的鲁棒性。
附图说明
[0040]
本发明构成说明书的一部分附图描述了本发明的实施例,并且连同说明书一起用于解释本发明的原理。
[0041]
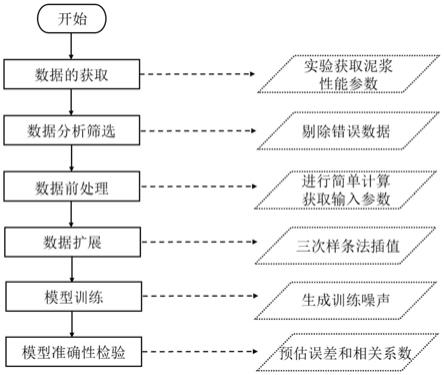
图1为本发明实施例的流程图。
[0042]
图2为本发明实施例的神经网络预测模型1的结构图。
[0043]
图3为本发明实施例的神经网络预测模型2的结构图。
[0044]
图4为本发明实施例的神经网络预测模型1的含砂量的预估误差结果图。
[0045]
图5为本发明实施例的神经网络预测模型1的相关系数结果图。
[0046]
图6为本发明实施例的神经网络预测模型2的含砂量的预估误差结果图。
[0047]
图7为本发明实施例的神经网络预测模型2的相关系数结果图。
具体实施方式
[0048]
下面将结合附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。
[0049]
同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
[0050]
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。
[0051]
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
[0052]
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。
[0053]
在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
[0054]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一
个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
[0055]
实施例一,公开一种基于人工神经网络的钻井液中含砂量的软测量技术,包括以下步骤:泥浆性能参数的获取、数据的分析筛选、数据前处理、数据扩展和划分、模型训练和模型准确性评价,具体流程参见附图1。
[0056]
获取泥浆性能参数。在泥浆性能参数的获取时,首先定好泥浆配方,本技术实施例选取的泥浆配方为:5%膨润土+0.5%纯碱+0.4%黄原胶,配置1l的泥浆待用。
[0057]
在配制泥浆时,要注意加药品的时候先打开搅拌机,边搅拌便加入药品,以防药品结块,影响泥浆的水化效果。待测泥浆在配制完成后,高速搅拌一小时,再静置水化24小时后,方可加砂并测量性能参数。
[0058]
拿出事先准备好的不同粒径的砂粒,用200目的筛网筛出300克74μm以上的砂粒备用。
[0059]
在加砂时应控制变量,保持泥浆除含砂量以外的其他配方不变,只改变加砂的量,每次加入5-10克的砂,加砂后使用搅拌机低速搅拌5分钟,将砂粒搅拌均匀。这一步注意不可高速搅拌,因为高速搅拌会产生气泡,影响测量结果。
[0060]
搅拌均匀后,用比重计测量泥浆的密度,用马氏漏斗测量泥浆的漏斗粘度,用六速旋转粘度计测量3r/min、6r/min、100r/min、200r/min、300r/min、600r/min这六个转速的读数,即旋转粘度,用含砂量的测量装置手动测量含砂量。
[0061]
记录每组泥浆配方对应的泥浆性能参数,并对数据进行分析筛选,根据经验以及对整组数据的分析,剔除实验中的明显错误数据,得到多组不同含砂量的泥浆的密度、马氏漏斗粘度、旋转粘度和含砂量;
[0062]
对前述步骤测得的基础数据进行简单计算,获取表观粘度、塑性粘度和赫谢尔-巴尔克莱三参数:
[0063]
其中,表观粘度为av=θ
300
,塑性粘度为pv=θ
600-θ
300
,θ
600
和θ
300
为六速旋转粘度计测量的600r/min和300r/min的读数;
[0064]
赫谢尔-巴尔克莱(herschel-bulkely)三参数流变模式的数学表达式为:
[0065]
τ=τy+kγnꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0066]
式中,τy表示动切力,n表示流体行为指数,k表示流体稠度,γ表示剪切速率,τ表示剪切应力。
[0067]
通常,由旋转粘度计3r/min时测得的刻度盘读数θ3可以近似的确定τy的值。因此可由以下三式分别求得τy、n和k的值:
[0068]
τy=0.511θ3ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0069]
n=3.322lg[(θ
600-θ3)/(θ
300-θ3)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0070]
k=0.511(θ
300-θ3)/511nꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0071]
式中,τy的单位为pa,n为无因次量,k的单位为pa
·
sn,θ3为旋转粘度计3r/min时测得的值,根据公式(2)-(4),计算出本实施例中用到的泥浆配方对应流体的赫谢尔-巴尔克莱三参数。
[0072]
得到所有输入参数后,对输入参数分别进行数据扩展,具体使用三次样条法进行插值,分别扩充得到1000组以上的数据。
[0073]
在训练模型时,从前述扩充的样本中随机抽取70%的数据作为训练集用来训练模
型,15%的数据作为验证集用来验证模型,15%的数据作为测试集用来测试模型。
[0074]
构建两个ann神经网络。本实施例中构建的两个人工神经网络模型均为三层神经网络,如图2和图3所示,包括输入层、隐藏层和输出层;
[0075]
其中,模型1的输入层为前述剔除异常数据后的泥浆的密度、马氏漏斗粘度、旋转粘度计测得的旋转粘度等以及计算得到的表观粘度和塑性粘度,输出层为剔除异常数据后泥浆的含砂量;
[0076]
模型2的输入层为前述剔除异常数据后的泥浆的密度、马氏漏斗粘度等,以及由旋转粘度计算得到的τy、n和k,输出层为泥浆的含砂量。
[0077]
在模型训练时,用编程的方法模拟生成训练噪声,以模拟钻进过程中周围环境对于实时采集数据的干扰。
[0078]
具体的模型训练过程为:
[0079]
1、首先训练普通参数。在训练集(给定超参数)上利用学习算法,训练普通参数,使得模型在训练集上的误差降低到可接受的程度(一般接近人类的水平)。即将基于剔除异常数据后的密度、马氏漏斗粘度和旋转粘度,以及基于表观粘度和塑性粘度划分的训练集和验证集,输入基于钻井液粘度的ann神经网络模型1进行迭代训练;并将基于剔除异常数据后的密度、马氏漏斗粘度和旋转粘度,以及赫谢尔-巴尔克莱三参数输入基于赫谢尔-巴尔克莱三参数流变模式的ann神经网络模型进行迭代训练。
[0080]
2、训练超参数。在验证集上验证上述两个网络模型的generalization error(泛化能力),并根据模型性能对超参数进行调整;
[0081]
3、重复1和2两个步骤,直至ann神经网络模型在验证集上取得较低的泛化能力,此时完整的训练过程结束。
[0082]
在完成参数和超参数的训练后,在测试集上测试ann网络模型的性能。模型训练完毕后,从预估误差、相关系数等方面评价训练后的模型,具体的测试效果图见附图4-7。
[0083]
如图4所示,为本方法中模型一的预估误差图,图中可以看出,模型1的预估误差小于
±
0.03%。如图5所示,为本方法中模型一的相关系数图,图中可以看出,四组试验中,模型一测量结果的相关系数均在0.9997以上。如图6所示,为本方法中模型二的预估误差图,图中可以看出,模型2的预估误差小于
±
0.08%。如图7所示,为本方法中模型二的相关系数图,图中可以看出,四组试验中,模型二的相关系数也均在0.9997以上。
[0084]
根据上述结果图可知,由于人工测量时,检测仪器是筛网,用清水冲洗筛网时,少量砂会残留在筛网上,致使含砂量测量结果偏低。而本实施例的基于人工神经网络的测量方法得到的预估误差远小于人工测量的误差。因此本技术的两种模型用作钻井液中含砂量检测的虚拟传感器具有很大的潜力。
[0085]
以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则范围之内所作的任何修改、等同替换以及改进等,均应包含在本发明的保护范围之内。
[0086]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括要素的
过程、方法、商品或者设备中还存在另外的相同要素。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1