一种基于NMF数据增强和CNN的滚动轴承故障诊断方法
一种基于nmf数据增强和cnn的滚动轴承故障诊断方法
技术领域
1.本发明属于机器工程领域,具体涉及一种基于nmf数据增强和cnn的滚动轴承故障诊断方法。
背景技术:
2.滚动轴承作为机器工程中的精密元件,在使用过程中可能因为过负载、过热等原因导致使用寿命缩短。因此,监测滚动轴承的状态,尽早发现轴承故障,有利于预防工业事故,节约生产成本。对滚动轴承故障诊断的已有研究中,传统的方法通过分析振动信号的时间、频率和时频域特征,用于确定轴承的状况,但这需要大量的故障检测和信号处理的先验信息,而实际中滚动轴承工作状态复杂多变,不易从振动信号中提取特征。基于机器学习的卷积神经网络对图像的空间特征提取能力强,可将一维振动信号转换为二维图像,提取其中空间特征,用于轴承故障诊断。滚动轴承通常处于稳定条件下运行,很少发生故障,检测其工作状态时,正常工作状态下产生的数据通常远多于故障状态下的数据,数据的分布并不平衡。机器学习模型需要足够的操作数据进行训练,收集的故障状态数据少,缺乏足够的训练样本,模型就容易出现过拟合的情况,导致模型准确度降低,诊断性能下降。因此,获取足够的数据,提高训练数据的质量和数量,有利于提高深度学习模型在实际应用中的分类准确性和可推广性,保障故障诊断的准确性。
技术实现要素:
3.为了对滚动轴承进行故障诊断和健康管理,本发明提出了一种基于nmf数据增强和cnn的滚动轴承故障诊断方法,给出了时域信号预处理的过程,提出了一种用于故障分类的轻量级cnn模型。时域信号通过stft转换为二维时频图,经过数据增强后,形成新的数据集,作为cnn模型的输入数据。针对滚动轴承故障状态下样本不足的问题,给出基于nmf和时域信号处理的数据增强方法,丰富了训练样本,提高了训练模型的准确性。
4.本发明采用的技术方案是:
5.振动信号预处理。为了减少后续cnn模型训练消耗的资源,将原始振动信号划分成更小的等尺寸信号样本。
6.生成二维时频图。传统的卷积神经网络不易从一维时域信号中提取特征,同时滚动轴承的振动信号具有非平稳性,很难根据时域或频域描述其中的相关性。通过stft从一维信号生成结构更加复杂的二维图像,利用卷积神经网络对图像特征提取的优势,便于获取轴承运行状态的重要特征。
7.数据增强算法扩充训练样本。对时域信号样本,通过窗函数和重复的方法进行信号处理,得到新的时域信号后,提高时频谱的时域或频域分辨率,再进行stft变换,得到新的时频图样本;对原始信号样本生成的时频图,采用nmf分解其中的特征。这种方法保留了原始样本的信号特征,从当前样本中合成新的标记样本,规避标记训练数据的不可用性,提高训练模型的鲁棒性。
8.数据集合成,生成诊断模型的训练样本和测试样本。对不同数据增强方法产生的时频图采用不同的标记区分,为了体现数据增强方法之间的差异性,设计参考组和不同的组合形成多个数据集,作为诊断模型的输入数据,
9.训练cnn诊断模型。设计轻量级cnn模型,包括特征学习阶段和分类阶段,模型通过卷积层、批归一化层、激活层和池化层从训练样本提取抽象空间特征。分类阶段是一个由全连接层组成的多层感知器,全连接层由隐藏层组成。经过多次迭代后,完成模型训练。同其他方法比较,评估该模型的故障分类性能以及跨域诊断的效果。
10.具体步骤如下:
11.步骤1:信号预处理。根据轴承转速选择合适的采样率,把原始振动信号划分为等尺寸的样本信号。
12.步骤2:数据增强。对样本信号采用高斯、凯泽、矩形窗函数,以及不同比例的重叠进行信号处理,产生新的信号样本。选择固定长度的窗函数,通过stft得到每个信号样本对应的二维时频谱,便于提取特征。
13.步骤3:对原始信号样本生成的时频图,将其转换成矩阵数据,使用nmf提取其中的故障特征,计算迭代后的闭式解,生成具有其特征的时频图,实现数据扩充。
14.步骤4:构建一个用于故障诊断的轻量级cnn模型,通过设置合适的超参数,实现尽量少的层数下提高卷积速度。模型通过卷积、批归一化、池化操作提取扩充后训练样本中的特征,对故障类型进行分类。
15.步骤5:设置多个数据集和参考组,参考评估诊断模型的分类效果,从准确度、精确度、召回率和f1值比较各个负载下故障诊断性能,测试该模型的跨域诊断性能,比较本方法于同类方法的优劣。
16.本发明的有益效果:将振动信号变换成二维时频图处理,保留原始信号中的数据相关性和非平稳数据特征。通过窗函数等方法改变时频图的时域或频域分辨率,实现数据扩充。基于nmf对原始时频图进行分解,实现数据增强,提高训练模型的泛化能力。轻量级cnn模型减少了卷积过程,降低训练时间。
附图说明
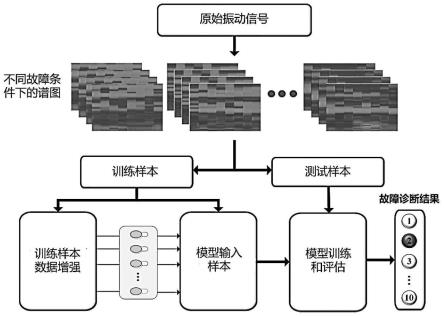
17.图1为本发明的总体结构框图。
18.图2为采样的振动信号分割示意图。
19.图3为采用不同数据增强方法下产生的训练样本,(a)为原始数据,(b)为高斯窗函数,(c)为凯撒窗函数,(d)为矩形窗函数,(e)为25%重叠,(f)为75%重叠,(g)为nmf。
20.图4为搭建的轻量级cnn诊断模型结构框图。
21.图5为构建的数据集组合示意图。
22.图6为不同负载情况下数据集的准确度评估情况。
23.图7为数据集的训练时间和准确度比较结果。
24.图8为试验测试集损失值的箱线图。
具体实施方式
25.本发明的原理流程图如图1所示,将振动信号转换成具有空间特征的时频图,经过
多种数据增强的方法后,形成数据集,在cnn模型中完成训练过程,实现自动分类。下面通过具体实施例,结合附图对本发明的故障诊断方法作进一步介绍。
26.使用的振动信号数据来自凯斯西储大学(cwru)的滚动轴承数据集,试验轴承为skf 6205-2rs jem型深沟球轴承,以12khz的采样率收集数据。每种状态下有0hp、1hp、2hp、3hp共计4种负载,其中hp为英制马力,1hp=0.75kw。根据负载的不同,轴承转速范围从1797rpm到1730rpm。数据集包括类型:正常状态(n)、内圈故障(of)、外圈故障(if)和滚动体故障(bf)。故障点蚀直径分别为0.18、0.36和0.54mm,每种负载下包括十种轴承健康状况。
27.进一步的,步骤1的详细过程为:
28.信号预处理,划分样本数据。从振动信号中获取多个相同点数的样本,需要对振动信号进行划分。正常状态下,0hp负载时的振动信号的长度为240000,其他3种负载下长度为480000。所有的故障状态下,振动信号的总长度为120000。采样频率fs为12khz,工作转速s为1797rpm,则每转的采样点数ns可估计为:
[0029][0030]
样本大小取为400点进行划分,样本划分示意图如图2。在所有故障状态下,每种情况有300个样本。正常状态下,0hp负载时为600个样品,其他负载时为1200个样品。表1为原始数据和生成数据的长度分布,l
0-3
分别对应了负载为0-3hp。原始数据中80%用作训练样本,20%平均分为验证集和测试集。
[0031]
表1不同负载下采样数据长度
[0032][0033]
进一步的,步骤2的详细过程为:
[0034]
步骤2.1生成二维时频图。采用短时傅里叶变换(stft)将每个样本转换成一个时频图,作为cnn模型的训练样本。
[0035]
短时傅里叶变换使用固定长度的滑动窗,对每个窗口内的时域信号做傅里叶变换,形成不同时间窗口的频域信号,将一维时域信号变换为二维时频图。时域信号的stft可以表示为:
[0036][0037]
其中w(t-τ)为滑动窗。计算二维时频图的参数会显著影响分类器的性能,为取得不同故障类型的明显特征,选择stft参数为一个长度88点的汉明窗,重叠比例50%,dft点数为256。
[0038]
步骤2.2本发明采用了多种方法对原始数据样本进行数据增强,对样本信号采用的数据增强方法包括窗函数和重叠;对原始信号样本产生的时频图采用了nmf方法。窗函数包括矩形窗、高斯窗和凯泽窗函数,重叠选择25%和75%的重叠比例。
[0039]
进一步的,步骤3的详细过程为:
[0040]
对原始样本产生的时频图提出了一种基于非负矩阵分解(nmf)的数据增强。对于给定一个非负数据矩阵通过nmf将x近似为一个基矩阵和一个编码矩阵
[0041]
x≈wh
ꢀꢀꢀ
(3)
[0042]
其中矩阵w和h是两个低阶非负矩阵,因子分解参数r远小于n和m。对每个样本采用nmf获得矩阵w和h。然后将优化问题表示为:
[0043][0044]
对于上式中的优化问题,可以用乘法更新规则(mu)、交替最小二乘法(als)或其他梯度下降方法,在给定的迭代次数内获得闭式解,直至收敛。局部最小值在实践中也可能具有故障特征,因此,在迭代中并不是必须使用全局最小值。算法1说明该算法的代码实现过程。图3展示了这些数据增强方法生成的训练样本。其中原始数据为数据集a,经过25%重叠、75%重叠、高斯、凯泽、矩形窗函数和nmf生成的数据依次对应数据集b至g。
[0045][0046][0047]
进一步的,步骤4的详细过程为:
[0048]
步骤4.1构建cnn模型训练。本发明提出的cnn模型结构框架如图4,包括特征提取和分类阶段。特征提取阶段依次由卷积层、批归一化层和池化层构成,该模型经过卷积操作生成特征映射,池化层提取其中重要的局部特征。分类阶段则由全连接层实现对特征的分
类,输出诊断结果。
[0049]
步骤4.2数据输入。将二维时频图重塑为32x32的相同尺寸,分小批量送入模型的输入层。
[0050]
步骤4.3模型训练。对数据样本进行卷积操作。卷积层中卷积核大小为3
×
3,卷积步长为1,该层生成的特征映射经过修正线性单元(relu)后,进入批量归一化(bn)层,减少协方差偏移,改善模型整体性能。随后,池化层窗口大小为2x2,对特征映射进行子采样,经过最大池化产生最大值。重复上述结构,进一步提取数据特征。之后数据经过压平为一维后,进入全连接层。全连接层包括两个隐藏层,每个隐藏层64个单元。最后进入大小为10的输出层。
[0051]
该模型通过多次非线性变换,获取鉴别特征,提高整体性能。使用反向传播(bp)算法更新模型中的参数,并用adam优化器将样本数减少到32。试验在配备i7 cpu和8gb nvidia geforce rtx 2070 gpu的windows计算机上进行,使用keras和python完成。模型的学习率为0.001,通常在10个迭代周期后收敛。
[0052]
进一步的,步骤5的详细过程为:
[0053]
步骤5.1数据集组合。使用原始数据集和六个合成数据集,对应数据集a~g,形成新的数据集组合,评估本发明的诊断方法。产生数据集组合共22种,对应编号为数据集0~21,每个数据集的组合方式如图5所示,依次评估各个数据集在不同负载条件下的性能。
[0054]
步骤5.2诊断性能评估。使用准确度(accuracy)、精确度(precision)、召回率(recall)和f1值(f1-score)作为故障分类模型的性能评估指标,对测试样本进行多次测试,取平均值评估该模型的性能:
[0055][0056]
其中nc是组数,tp和fp分别是真假阳性的数量。tn和fn分别是真假阴性的数量。试验测试结果如表2所示,其中acc、pre、rec和f1分别为准确度、精确度、召回率和f1值的平均百分比值。
[0057]
表2各个数据集测试结果
[0058][0059][0060]
在不同负载下,该故障诊断模型在区分各种故障状态方面表现良好,准确性高。0-3hp负载情况下各个数据集的平均准确度如图6所示。经过数据增强后,计算时间随训练数据集大小成正比增加。各个数据集计算时间的平均值如图7所示,通过比较计算时间和准确度曲线,数据集6说明了使用nmf进行数据增强的优点,训练时间增加少,准确度高。通过比较不同负载条件下的测试集损失,所有经过数据增强的数据集,在测试集损失上都低于作为参考的数据集0,说明了该方法的有效性,如图8所示。
[0061]
步骤5.3测试该方法的在跨域问题上的性能。使用给定负载条件下的标记数据训练模型,然后使用其他负载上的数据进行测试。随着工作负载值远离其训练对应物,测试精度降低。用0hp训练模型并用1hp测试其平均精度为95.85%,在用2hp和3hp测试时分别降低了7.94%和15.17%。如表3所示,可以在所有列车和测试交叉域中观察到精度值的降低。
[0062]
表3本方法的跨域精确度对比
[0063]
[0064][0065]
步骤5.4与使用了相同数据集的其他故障诊断方法比较,可见本方法的有效性和优越性,如表4所示。其中方法1至方法5分别对应基于集成深度自动编码,基于频域特征的dcnn(deep convolutional neural networks,深度卷积神经网络),基于频谱峰值的elm(extreme learning machine,极限学习机),基于svm(support vector machines,支持向量机)算法的多尺度局部特征学习和基于dbn(deep belief networks,深信度网络)的分层诊断网络的滚动轴承故障诊断方法。
[0066]
应当理解本文所述的例子和实施方式仅为了说明,并不用于限制本发明,本领域技术人员可根据它做出各种修改或变化,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
[0067]
表4不同故障诊断方法的平均测试精确度对比
[0068]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1