一种针对地下停车场环境的建图与车辆定位系统及方法与流程
1.本发明涉及车辆定位技术领域,具体涉及一种针对地下停车场环境的建图与车辆定位系统及方法。
背景技术:
2.自动泊车是自动驾驶领域的一项具体应用,在这项任务中,车辆经常需要在狭窄、拥挤、弱光且没有gps信号的停车场自主导航,因此,对车辆的准确定位至关重要。近十年出现了大量的定位方案,包括基于视觉的定位方案、基于视觉惯性导航的定位方案以及基于激光雷达的定位方案。为了节约成本,大量的研究都基于视觉定位展开。传统的视觉定位方案多是利用环境中的稀疏点、线段或平面等几何特征,其中,角点在视觉里程计算法中被广泛应用,这些方案的一般流程为通过特征点匹配,估计地图点位置,建立地图并基于此地图对相机位姿进行估计。
3.近些年,基于orb特征进行建图定位的方案在学术界和工业界的备受关注,如公开号为cn113808203a的发明专利申请中公开了一种基于lk光流法与orb-slam2的导航定位方法,该方法在orb-slam2前加入基于gpu的lk光流算法,根据光流追踪特征点的数量,作为当前帧是否为关键帧的判断条件,并且对于非关键帧,不会进入orbslam2的三个线程,阻止了非关键帧提取特征点和后续的计算,从而加快orbslam2对tracking线程处理,增强了算法的实时性,而且并不影响其鲁棒性,适用于汽车的自动驾驶和agv物流小车的定位与导航。然而,这种定位方法容易受到光照、视角及环境外观变化的影响,无法长时间地有效定位。尤其是地下停车场这种环境,向orb-slam等传统的视觉定位方案提出了巨大的挑战。一方面,地下室内停车场主要是墙体、地面及立柱组成,这种弱纹理结构使得特征点的检测和匹配变得很不稳定,定位也因此容易出现跟踪丢失的状况。另一方面是不同时间段不同车辆进进出出造成的停车场环境变化,长期的车辆重定位对于传统视觉定位方案来讲几乎不可能。
技术实现要素:
4.针对现有技术存在的上述不足,本发明要解决的技术问题是:如何提供一种能实现车辆在地下停车场环境下的长时间稳定定位,更加鲁棒地应对环境变化,同时成本较低的针对地下停车场环境的建图与车辆定位系统及方法。
5.为了解决上述技术问题,本发明采用如下技术方案:
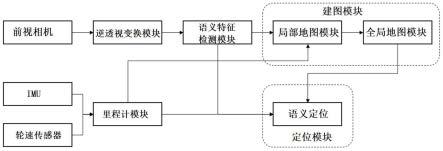
6.一种针对地下停车场环境的建图与车辆定位系统,包括前视相机、逆透视变换模块、语义特征检测模块、里程计模块、建图模块和定位模块;
7.所述前视相机用于获取车辆前方区域的原始图像并输入给所述逆透视变换模块;
8.所述逆透视变换模块用于将所述前视相机输入的原始图像进行逆透视变换后得到俯视图并输入给所述语义特征检测模块;
9.所述语义特征检测模块用于通过卷积神经网络得到俯视图语义分割后的图像,并
获取语义特征输入到所述建图模块和所述定位模块;
10.所述里程计模块用于获取车辆的位姿输入到所述建图模块和所述定位模块;
11.所述建图模块基于所述里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得全局语义地图;
12.所述定位模块用于获取车辆当前语义特征的全局坐标点,并将该全局坐标点与全局语义地图做匹配,以获得车辆当前的语义定位结果。
13.优选的,所述里程计模块包括一个惯性测量单元和两个轮速传感器;
14.所述建图模块包括局部地图模块和全局地图模块;
15.所述局部地图模块基于所述里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得局部地图并输入给所述全局地图模块;
16.所述全局地图模块用于对局部地图加回环检测和全局优化后生成全局语义地图。
17.一种针对地下停车场环境的建图与车辆定位方法,采用上述的针对地下停车场环境的建图与车辆定位系统,所述建图与车辆定位方法包括建图方法和车辆定位方法;
18.其中所述建图方法包括以下步骤:
19.步骤a1)所述前视相机获取车辆前方区域的原始图像并输入给所述逆透视变换模块;
20.步骤a2)所述逆透视变换模块将所述前视相机输入的原始图像进行逆透视变换后得到俯视图并输入给所述语义特征检测模块;
21.步骤a3)所述语义特征检测模块通过卷积神经网络得到俯视图语义分割后的图像,并获取语义特征输入到所述建图模块;
22.步骤a4)所述里程计模块获取车辆的位姿输入到所述建图模块;
23.步骤a5)所述建图模块基于所述里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得全局语义地图;
24.步骤a6)完成建图;
25.所述车辆定位方法包括以下步骤:
26.步骤s1)所述前视相机获取车辆当前位置前方区域的原始图像并输入给所述逆透视变换模块;
27.步骤s2)所述逆透视变换模块将所述前视相机输入的原始图像进行逆透视变换后得到俯视图并输入给所述语义特征检测模块;
28.步骤s3)所述语义特征检测模块通过卷积神经网络得到俯视图语义分割后的图像,并获取语义特征输入到所述定位模块;
29.步骤s4)所述里程计模块获取车辆当前的位姿输入到所述定位模块;
30.步骤s5)所述定位模块基于所述里程计模块提供的车辆当前的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得车辆当前语义特征的全局坐标点;
31.步骤s6)将步骤s5)中得到的全局坐标点与所述建图方法中得到的全局语义地图做匹配,以获得车辆当前的语义定位结果,完成车辆定位。
32.优选的,逆透视变换的公式为:
[0033][0034]
式中:πc(
·
)为前视相机投影模型,[rctc]为从前视相机坐标系向车体坐标系转化的外参矩阵,[u v]为语义特征的像素坐标,[x
v yv]为语义特征在车体坐标系下的坐标,λ为尺度因子。
[0035]
优选的,所述语义特征检测模块的卷积神经网络使用所述前视相机采集的停车场图片集进行训练分类,且卷积神经网络的分类类别包括车道线、停车线、引导线、减速带、可通行区域、障碍物和墙体,且所述语义特征检测模块通过卷积神经网络获取的语义特征包括车道线、停车线、引导线和减速带。
[0036]
优选的,将语义特征从车体坐标系投影至全局坐标系的公式为:
[0037][0038]
式中:[x
w,yw zw]为语义特征在全局坐标系下的坐标,ro为从车体坐标系向全局坐标系转化的旋转矩阵,to为从车体坐标系向全局坐标系转化的平移向量。
[0039]
优选的,所述里程计模块包括一个惯性测量单元和两个轮速传感器;
[0040]
所述建图模块包括局部地图模块和全局地图模块;
[0041]
所述局部地图模块基于所述里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得局部地图并输入给所述全局地图模块;
[0042]
所述全局地图模块用于对局部地图加回环检测和全局优化后生成全局语义地图;
[0043]
步骤a5)中,所述局部地图模块基于所述里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得局部地图并输入给所述全局地图模块;所述全局地图模块再对局部地图加回环检测和全局优化后生成全局语义地图。
[0044]
优选的,步骤a5)中,所述全局地图模块对局部地图加回环检测的方法为:使用基于数据配准法将当前的局部地图与之前生成的局部地图做匹配,若匹配结果满足设定值,则证明出现回环,用计算得到的相对位姿进行位姿图优化来消除累积误差。
[0045]
优选的,步骤a5)中,所述全局地图模块对局部地图进行全局优化的方法包括约束两帧连续局部地图的所述里程计模块的测量值、以及回环检测时基于数据配准法得到的相对位姿做回环帧间的约束。
[0046]
优选的,步骤a5)中,所述全局地图模块对局部地图进行全局优化的方法为高斯牛顿法,目标函数为:
[0047][0048]
式中:χ为位姿集合,t
t,t+1
为t帧和t+1帧前视相机的相对位姿估计值,为从里程计模块获取的相对位姿测量值,l为回环帧对的集合,为基于数据配准法得到的第i帧和第j帧之间的相对位姿,做测量值使用,t
i,j
为第i帧和第j帧带有累计误差的相对位姿估计值。
[0049]
与现有技术相比,本发明具有以下优点:
[0050]
1、本发明不同于传统视觉定位方案用到的环境中的几何特征,本发明利用环境中的语义特征,对于停车场环境,主要包括车道线、引导线、停车线和减速带等,语义特征相比于几何特征能够长期稳定存在,并在光照、视角和环境变化时依旧健壮,这些语义特征由卷积神经网络检测,并利用该语义特征建立全局语义地图,再利用全局语义地图对车辆进行定位。因此该方案比传统的定位方案能更加鲁棒地应对环境变化,并能保持长时间稳定准确的使用状态。
[0051]
2、本发明所用传感器仅为一个前视相机、一个imu(惯性测量单元)和两个轮速传感器,其中imu和轮速传感器组成里程计模块,在建图和定位时提供车辆的相对位姿,因此本发明的使用成本很低,量产车也能轻松配置。
[0052]
3、本发明的框架主要包含两部分,建图和定位。顾名思义,建图即建立停车场环境的全局语义地图;由前视相机获取车辆前方区域的原始图像,经过逆透视变换后得到俯视图,然后输入卷积神经网络得到语义分割后的图像,并获得车道线、停车线、引导线和减速带等语义特征;然后基于里程计模块提供的位姿,将语义特征投影到全局坐标系下,鉴于里程计模块的数据漂移,本发明还利用回环检测和全局优化来消除这些累积误差,最后通过保存这些特征点,建立停车场的全局语义地图。全局语义地图生成之后,进入停车场的车辆通过前视相机获取图像、逆透视变换、语义特征检测及里程计模块提供的位姿获得语义特征的全局坐标点,再通过icp算法(基于数据配准法)与建好的全局语义地图做匹配修正车辆位姿,最终获得准确的车辆定位结果。
附图说明
[0053]
图1为本发明针对地下停车场环境的建图与车辆定位系统的系统框图。
具体实施方式
[0054]
下面将结合附图及实施例对本发明作进一步说明。
[0055]
如附图1所示,一种针对地下停车场环境的建图与车辆定位系统,包括前视相机、逆透视变换模块、语义特征检测模块、里程计模块、建图模块和定位模块;
[0056]
前视相机用于获取车辆前方区域的原始图像并输入给逆透视变换模块;
[0057]
逆透视变换模块用于将前视相机输入的原始图像进行逆透视变换后得到俯视图并输入给语义特征检测模块;
[0058]
语义特征检测模块用于通过卷积神经网络得到俯视图语义分割后的图像,并获取语义特征输入到建图模块和定位模块;
[0059]
里程计模块用于获取车辆的位姿输入到建图模块和定位模块;
[0060]
建图模块基于里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得全局语义地图;
[0061]
定位模块用于获取车辆当前语义特征的全局坐标点,并将该全局坐标点与全局语义地图做匹配,以获得车辆当前的语义定位结果。
[0062]
在本实施例中,里程计模块包括一个惯性测量单元和两个轮速传感器;
[0063]
建图模块包括局部地图模块和全局地图模块;
[0064]
局部地图模块基于里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得局部地图并输入给全局地图模块;
[0065]
全局地图模块用于对局部地图加回环检测和全局优化后生成全局语义地图。
[0066]
一种针对地下停车场环境的建图与车辆定位方法,采用上述的针对地下停车场环境的建图与车辆定位系统,建图与车辆定位方法包括建图方法和车辆定位方法;
[0067]
其中建图方法包括以下步骤:
[0068]
步骤a1)前视相机获取车辆前方区域的原始图像并输入给逆透视变换模块;
[0069]
步骤a2)逆透视变换模块将前视相机输入的原始图像进行逆透视变换后得到俯视图并输入给语义特征检测模块;
[0070]
步骤a3)语义特征检测模块通过卷积神经网络得到俯视图语义分割后的图像,并获取语义特征输入到建图模块;
[0071]
步骤a4)里程计模块获取车辆的位姿输入到建图模块;
[0072]
步骤a5)建图模块基于里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得全局语义地图;
[0073]
步骤a6)完成建图;
[0074]
车辆定位方法包括以下步骤:
[0075]
步骤s1)前视相机获取车辆当前位置前方区域的原始图像并输入给逆透视变换模块;
[0076]
步骤s2)逆透视变换模块将前视相机输入的原始图像进行逆透视变换后得到俯视图并输入给语义特征检测模块;
[0077]
步骤s3)语义特征检测模块通过卷积神经网络得到俯视图语义分割后的图像,并获取语义特征输入到定位模块;
[0078]
步骤s4)里程计模块获取车辆当前的位姿输入到定位模块;
[0079]
步骤s5)定位模块基于里程计模块提供的车辆当前的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得车辆当前语义特征的全局坐标点;
[0080]
步骤s6)将步骤s5)中得到的全局坐标点与建图方法中得到的全局语义地图做匹配,以获得车辆当前的语义定位结果,完成车辆定位。
[0081]
在本实施例中,前视相机的内外参已离线标定,通过逆透视变换将前视相机获取的原始图像投影到地面上,逆透视变换的公式为:
[0082][0083]
式中:πc(
·
)为前视相机投影模型,[rctc]为从前视相机坐标系向车体坐标系转化的外参矩阵,[u v]为语义特征的像素坐标,[x
v yv]为语义特征在车体坐标系下的坐标,λ为尺度因子。
[0084]
在本实施例中,语义特征检测模块使用卷积神经网络u-net做语义分割,且卷积神经网络使用前视相机采集的停车场图片集进行训练分类,且卷积神经网络的分类类别包括车道线、停车线、引导线、减速带、可通行区域、障碍物和墙体,且语义特征检测模块通过卷
积神经网络获取的语义特征包括车道线、停车线、引导线和减速带,这是由于车道线、停车线、引导线和减速带语义特征可辨识度高且稳定,适用于本发明的建图和定位。
[0085]
在本实施例中,利用里程计模块提供的位姿,将语义特征通过如下公式从车体坐标系投影至全局坐标系,保存语义特征的全局坐标点生成局部地图,局部地图范围为30m;其中,将语义特征从车体坐标系投影至全局坐标系的公式为:
[0086][0087]
式中:[x
w,yw zw]为语义特征在全局坐标系下的坐标,ro为从车体坐标系向全局坐标系转化的旋转矩阵,to为从车体坐标系向全局坐标系转化的平移向量。
[0088]
在本实施例中,步骤a5)中,局部地图模块基于里程计模块提供的车辆的位姿,将语义特征从车体坐标系投影到全局坐标系下,以获得局部地图并输入给全局地图模块;全局地图模块再对局部地图加回环检测和全局优化后生成全局语义地图。
[0089]
在本实施例中,步骤a5)中,全局地图模块对局部地图加回环检测的方法为:使用基于数据配准法将当前的局部地图与之前生成的局部地图做匹配,若匹配结果满足设定值,则证明出现回环,用计算得到的相对位姿进行位姿图优化来消除累积误差。
[0090]
在本实施例中,步骤a5)中,全局地图模块对局部地图进行全局优化的方法包括约束两帧连续局部地图的里程计模块的测量值、以及回环检测时基于数据配准法得到的相对位姿做回环帧间的约束。
[0091]
在本实施例中,步骤a5)中,全局地图模块对局部地图进行全局优化的方法为高斯牛顿法,目标函数为:
[0092][0093]
式中:χ为位姿集合,t
t,t+1
为t帧和t+1帧前视相机的相对位姿估计值,为从里程计模块获取的相对位姿测量值,l为回环帧对的集合,为基于数据配准法得到的第i帧和第j帧之间的相对位姿,做测量值使用,t
i,j
为第i帧和第j帧带有累计误差的相对位姿估计值。
[0094]
与现有技术相比,本发明不同于传统视觉定位方案用到的环境中的几何特征,本发明利用环境中的语义特征,对于停车场环境,主要包括车道线、引导线、停车线和减速带等,语义特征相比于几何特征能够长期稳定存在,并在光照、视角和环境变化时依旧健壮,这些语义特征由卷积神经网络检测,并利用该语义特征建立全局语义地图,再利用全局语义地图对车辆进行定位。因此该方案比传统的定位方案能更加鲁棒地应对环境变化,并能保持长时间稳定准确的使用状态。本发明所用传感器仅为一个前视相机、一个imu(惯性测量单元)和两个轮速传感器,其中imu和轮速传感器组成里程计模块,在建图和定位时提供车辆的相对位姿,因此本发明的使用成本很低,量产车也能轻松配置。本发明的框架主要包含两部分,建图和定位。顾名思义,建图即建立停车场环境的全局语义地图;由前视相机获取车辆前方区域的原始图像,经过逆透视变换后得到俯视图,然后输入卷积神经网络得到语义分割后的图像,并获得车道线、停车线、引导线和减速带等语义特征;然后基于里程计
模块提供的位姿,将语义特征投影到全局坐标系下,鉴于里程计模块的数据漂移,本发明还利用回环检测和全局优化来消除这些累积误差,最后通过保存这些特征点,建立停车场的全局语义地图。全局语义地图生成之后,进入停车场的车辆通过前视相机获取图像、逆透视变换、语义特征检测及里程计模块提供的位姿获得语义特征的全局坐标点,再通过icp算法(基于数据配准法)与建好的全局语义地图做匹配修正车辆位姿,最终获得准确的车辆定位结果。
[0095]
最后需要说明的是,以上实施例仅用以说明本发明的技术方案而非限制技术方案,本领域的普通技术人员应当理解,那些对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1