一种引入三维环境场数据的雷达回波外推方法
1.本发明涉及气象学领域与机器学习领域,特别涉及一种利用三维环境场数据提升雷达组合反射率外推效果的方法。
背景技术:
2.临近预报指0-6小时(0-2小时为重点)时段内的高时空分辨率天气预报,是一种预防紧急局地灾害性天气的服务项目。由于灾害性天气具有发展迅速,变化复杂,破坏性强等特点,准确的临近预报可以有效保护灾害预发生地的经济财产与人员安全,在气象预报领域具有重大意义。
3.雷达回波外推是临近预报中较为常见的一种方法,其原理为根据过去时间段的雷达回波序列提供的信息,对未来固定时间段雷达回波的变化进行预测。与传统的nwp(数值天气预报模型)相比,雷达数据具有更高的时效性与分辨率,因此基于雷达的外推方法在0-2小时内的临近预报更具有优势。
1.4.近年来,随着人工智能与大数据技术的飞速发展,深度学习在气象学领域的应用受到了越来越多的关注,并且取得了巨大的进步。与传统的外推方法相比,深度学习可以从庞大的历史数据中学习到复杂的非线性气象过程,因此一系列机器学习预测模型应运而生,例如shi等人
2.提出了convlstm模型,通过cnn捕捉空间信息,再使用lstm学习雷达回波时间维度上的相关性,与光流法相比其性能显著提高。du等人
3.创造性地提出3d卷积模型,克服了使用rnn模型预测时空序列时存在的训练困难等问题。
5.发明人在实现本发明的过程中,发现现有技术中至少存在以下缺点和不足:
6.1.由于雷达回波寿命较短,基于深度学习的雷达回波预测模型的预测性能随着预测时间的增加而明显下降,超过雷达回波寿命时刻的预测效果较差。
7.2.现有的雷达回波外推模型大多通过历史样本信息来学习雷达回波的变化规律,忽略了实际存在的环境要素场的影响,忽略了复杂非线性气象过程,需要要素环境场提供必要的外推线索。
8.参考文献
9.[1]r.prudden,s.adams,d.kangin,n.robinson,s.ravuri,s.mohamed,a.aeeibas,”a review of radar-based nowcasting of precipitation and applicable machine learning techniques”,2020,arxiv:2005.04988.
[0010]
[2]x.shi,z.chen,h.wang,d.yeung,w.wong,and w.woo,“convolutional lstm network:a machine learning approach for precipitationnowcasting,”in proc.conf.neural inf.process.syst,2015,pp.802
–
810.
[0011]
[3]d.tran,l.bourdev,r.fergus,l.torresani,m.paluri,“learning spatiotemporal features with 3d convolutional networks”int.conf.comput.vis,2015,4489-4497.
技术实现要素:
[0012]
为了解决现有技术中的问题,本发明提供了一种引入三维环境场数据的雷达回波外推方法,解决现有技术中外推信息来源不充足,气象学角度解释性不强等问题。
[0013]
本发明的技术方案为:
[0014]
一种引入三维环境场数据的雷达回波外推方法,包括:
[0015]
(1)收集特定时刻雷达回波序列基数据以及与其在时间与空间上相匹配的多个三维环境场数据;
[0016]
(2)将雷达基数据从极坐标系转换成笛卡尔直角坐标系下的组合反射率,将环境场从等经纬度格点场插值成等距离格点场;
[0017]
(3)搭建基于3d卷积的雷达回波序列外推神经网络;
[0018]
(4)确定训练策略以及训练超参数。
[0019]
所述步骤(1)是指由于环境场的时间分辨率为1小时且时刻在整点附近,因此收集的雷达回波序列的中心时刻也应为整点,然后根据该中心时刻以及雷达站点的经纬度坐标提取相应的环境场。
[0020]
所述步骤(2)是指使用双线性插值法将雷达9个仰角下以极坐标格式存储的数据插值为512
×
512
×
31,分辨率为1km
×
1km
×
0.5km的三维格点等距离场;然后取相同水平位置上不同高度层的最大基本反射率作为该水平坐标上的组合反射率;而环境场数据为等经纬度格点场,转换为等距离场的具体方法为:根据格点场中心的雷达站的经纬度信息,计算出所求的等距离场每个格点的经纬度坐标,再使用双线性插值法插值得到每个格点上的数据值。
[0021]
所述步骤(3)是指融合环境场数据的3d卷积神经网络的搭建;该网络主要由雷达回波编码器,环境场编码器,推理器以及解码器四个模块构成;雷达回波编码器以及环境场编码器提取雷达回波序列以及环境场中时空维度上的重要信息,将高维数据转换到低维空间;推理器融合雷达与环境场编码器提供的信息以及进行外推预测;解码器将推理器提供的信息还原成与输入雷达回波序列时空分辨率相同的外推结果;
[0022]
每个模块均由若干个相同结构的卷积层构成,每进行一次卷积后都会进行一次批标准化处理以及一次激活函数处理,激活函数选择leakeyrelu函数;雷达回波编码器每经过两次卷积层会进行一次下采样,而解码器则会进行一次上采样,推理器与环境场编码器则不包含上采样与下采样;解码器的输出会经过一个1x1的卷积以合并通道得到最终输出。
[0023]
所述步骤(4)是指训练策略与细节:
[0024]
(1)对雷达数据与环境场数据进行归一化操作,然后打包为三维张量(tensor);
[0025]
(2)加载搭建好的神经网络并确定训练超参数;选择adam优化器更新参数,学习率设置为0.001,衰减系数为(0.9,0.999);训练轮数设置为70轮,batch_size为8;
[0026]
(3)使用dataloader加载预处理完成的雷达回波序列与环境场,将雷达回波序列分割成输入序列与标签序列两部分;
[0027]
(4)将训练集的雷达回波输入序列与对应的环境场输入网络进行前馈运算,得到网络预测的外推结果序列,然后计算该序列与标签序列之间的wsme损失;
[0028]
(5)根据计算得到的损失,使用bp算法对网络中的参数进行更新;
[0029]
(6)循环运行(3)、(4)、(5)三个步骤,直到训练轮数达到预设值;然后选取40dbz阈
值下后30min平均csi最高的一轮模型进行测试。
[0030]
本发明的有益效果是:本发明方法与单纯使用雷达回波序列作为输入的外推模型相比,提供了额外的约束信息,提升了外推准确性,延缓了外推效果随外推时间增加剧烈下降的趋势,增强了模型的可解释性。
附图说明
[0031]
图1为15个雷达气象站的位置示意图;
[0032]
图2为2016年8月1日13-14点烟台站雷达基数据转换后得到的组合反射率伪彩图样例(a图-j图:13:00至14:00每隔6min获得的组合反射率图片);
[0033]
图3为2016年8月1日14点烟台站提取的七个高度层的温度场灰度图(a图:高度为100hpa的温度场,b图:高度为200hpa的温度场,c图:高度为300hpa的温度场,d图:高度为500hpa的温度场,e图:高度为700hpa的温度场,f图:高度为850hpa的温度场,g图:高度为925hpa的温度场);
[0034]
图4为模型网络结构示意图;
[0035]
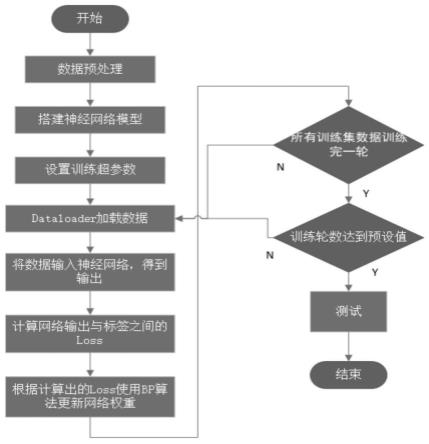
图5为模型训练流程图;
[0036]
图6为不同外推方法下的测试结果对比图(a图:阈值为20dbz下的不同方法在不同时刻时的外推csi值;b图:阈值为30dbz下的不同方法在不同时刻时的外推csi值;c图:阈值为40dbz下的不同方法在不同时刻时的外推csi值;d图:阈值为50dbz下的不同方法在不同时刻时的外推csi值;)。
具体实施方式
[0037]
1.雷达回波数据集制作
[0038]
(1)下载2015-2016年中国华北与华东地区15个雷达气象站的雷达基数据,雷达站点位置如图1所示。每个雷达站点的记录范围为512km
×
512km,含有9个仰角的数据,平均每6min扫描一次。
[0039]
(2)使用双线性插值法,将极坐标系下的雷达基数据插值为笛卡尔直角坐标系下的512
×
512
×
31三维格点数据,分辨率为1km
×
1km
×
0.5km。然后在同一水平位置的不同高度层取最大的基本反射率作为该点的组合反射率,如图2所示。
[0040]
(3)统计记录所有的整点时刻数据,若某个整点时刻数据和与它相邻的两个整点数据之间记录时刻完整,即共包含21个时刻的数据,则该记录周期完整,将这21个数据打包作为一个样本。将中间的整点时刻与站点名组合作为样本名,例如:2015年10月1日20点的青岛站样本记录为2015_10_01_20_qingdao。
[0041]
(4)筛选组合反射率较高的样本:若样本中超过10个时刻大于40dbz的点多于600个或大于25dbz的点多于40000个,则该样本保留,否则舍弃。经筛选共得到8979个样本。
[0042]
(5)按照训练集:验证集:测试集=4:1:1的比例随机划分,最终得到训练集数据5987个,验证集与测试集数据各1496个。
[0043]
2.环境场数据集制作。
[0044]
(1)下载2015-2016年全中国范围内的全时刻era5全球分析数据。该数据的时间分辨率为1小时,空间分辨率为0.25
°×
0.25
°
,包含7个高度层。环境要素主要有十类:散度、重
力势能、潜在涡度、相对湿度、比湿度、温度、风的u分量、风的v分量、垂直速度、相对涡度。
[0045]
(2)根据雷达回波样本名称提取对应的环境场,提取范围为以雷达站点为中心的1024km
×
1024km方形区域。由于era5提供的是等经纬度的格点场,无法与雷达提供的等距离格点场对齐,因此首先需要将环境场转换成等距离格点场,具体方法为:根据等经纬度格点场中心的雷达站点的经纬度,计算出相应的等距离场中每个格点位置的经纬度值,然后通过双线性插值法插值得到等距离场每个格点上的具体数值。最终将0.25
°×
0.25
°
的等经纬度格点场转换为32km
×
32km的等距离格点场,大小为32
×
32。提取后的七个高度层的环境场灰度图如图3所示。
[0046]
3.模型网络搭建
[0047]
考虑到训练难度与计算资源等因素,本方法选择3d卷积作为外推模型。传统的cnn模型多采用2d卷积,其卷积核的深度等于输入图像的通道数,因此无论输入多少张图片,2d卷积最终都只会输出一张特征图。模型只能学习到空间特征信息,而时间维度上的信息则会被覆盖掉。与传统的2d卷积相比,3d卷积的卷积核增加了时间维度,使得卷积核不仅可以在空间维度上卷积,还可以沿着时间维度方向进行卷积,从而学习到不同时刻的雷达回波之间的时间相关性。
[0048]
整个网络可分为雷达回波场编码器、环境场编码器、推理器以及解码器四个子网络,每个子网络均由相同结构的卷积块堆叠而成。每个卷积块包括进行一次三维卷积,然后进行一次批标准化,最后通过一个激活函数输出。批标准化的作用主要是将一组分布差距较大的特征值重新拉回到标准正态分布,这样,特征值将会落在激活函数对输入较为敏感的区间,避免了梯度消失,同时加快了收敛速度。激活函数选用leakeyrelu函数,该函数与sigmod函数和tanh函数相比无饱和区间,解决了梯度消失的问题,与relu函数相比在输入小于0时仍具有较小梯度,避免输入小于0时失活。
[0049]
雷达回波场编码器的主要作用是捕捉输入回波序列在空间与时间上的相关信息,它能够将高维的时空数据编码至低维空间。在编码过程中,每经过两层卷积块后特征图层数增加,然后进行一次空间维度上的平均值池化,使得特征图的空间分辨率减半。每两个卷积块与一层平均值池化构成一个编码块。整个编码器网络由若干个编码块堆叠而成,其中最后一个编码块的池化还承担着降低时间分辨率的作用。
[0050]
环境场编码器的作用于雷达回波编码器类似,区别在于环境场的时间分辨率更大。所以环境场编码器需要先在时间维度上进行线性插值,使得环境场与雷达回波在时间维度上对齐。其次,由于环境场表示的空间范围比雷达更广,采用池化的方法无法将雷达探测范围以外的环境信息有效融合进外推空间范围,因此采用大卷积核替代池化层进行空间维度降维。
[0051]
雷达回波序列与环境场序列通过各自的编码器后会产生一系列空间维度上相等的特征图,将他们在通道维度进行堆叠后输入进推理网络。推理网络的作用主要是学习雷达回波与环境场之间的相关性,并且将二者的特征融合起来。推理网络由一系列卷积块构成,不包含池化操作,并且特征图层数保持不变。
[0052]
解码器的任务是将从推理器接收到的的若干特征图还原成与输入序列相同空间分辨率的外推序列。解码器结构与编码器基本相同,区别在于解码器将编码器中的平均值池化操作更换为上采样,并且每经过一个解码块特征图层数减少。整个解码器网络由若干
个解码块堆叠而成,其中第一个解码块的池化还承担着恢复时间分辨率的作用。
[0053]
模型网络示意图如图4所示,整个网络由雷达回波编码器、环境场编码器、推理器以及解码器四部分构成。雷达回波序列与环境场分别输入雷达回波编码器与环境场编码器,然后输出若干层特征图。将雷达回波特征图与环境场特征图在通道维度上堆叠后输入推理器,推理器会将从雷达回波序列以及环境场中提取出的信息进行融合。经推理器融合转化后的特征图会被输送进解码器,解码器最终会将特征图还原成与输入雷达回波相同分辨率的外推结果。
[0054]
雷达回波编码器由四个编码块构成,每个编码块包含两次卷积以及一次平均值池化。每执行一次卷积操作后,都会使用一次批处理归一化和一次激活函数。激活函数统一使用leakeyrelu,斜率设为0.1。每经过一个编码块,特征层层数增加。环境场编码器则先进行一次时间维度上的上采样,然后进行三次卷积操作,其中第二次卷积使用大卷积核融合外围信息。
[0055]
推理器与编码器相比舍弃了池化操作,同时特征层层数保持不变,主要目的是为了融合雷达回波信息与环境场信息。推理器输出结果被送入解码器,解码器与雷达回波编码器结构类似,区别在于解码器将平均池化操作改为上采样操作。具体网络参数如表1所示:
[0056]
表1神经网络各层参数
[0057]
模块卷积核尺寸填充步长输出尺寸radar_encoder14x3x31132x10x128x128radar_encoder23x3x31164x10x64x64radar_encoder33x3x311128x10x32x32radar_encoder43x3x311256x5x16x16env_encoder13x3x31132x5x32x32env_encoder21x17x170164x5x16x16env_encoder33x3x311128x5x16x165*inference3x3x311256x5x16x16decoder13x3x311128x10x32x32decoder23x3x31164x10x64x64decoder33x3x31132x10x128x128decoder43x3x31132x10x256x256to_img3x3x3111x10x256x256
[0058]
4.模型训练
[0059]
模型训练主要包括数据的预处理,损失函数与优化器的选择,学习率与训练轮数的确定等:
[0060]
(1)数据预处理:主要采取的预处理方法为归一化。由于记录的绝大多数雷达回波强度都小于70dbz,因此将雷达回波序列中的数据都除以70,使得数据放缩至0到1之间。而不同环境场数据分布差异较大,因此采用z-score归一化,使得不同类型的环境场数据都归一化至n(0,1)的高斯分布。
[0061]
(2)损失函数:在雷达外推结果中,高反射率区域往往意味着该区域产生灾害性天
气的可能性较大。而由于雷达检测到较高反射率的概率非常低,若单纯使用mse损失函数进行训练,模型可能会忽略高反射率区域的外推结果。因此采用加权的mse损失函数即wmse来训练模型,更高的反射率区域会被赋予更高的权重,使得模型能更关注于这些区域。
[0062]
(3)优化器:由于adam优化器可以自适应改变学习率,并且是基于动量的算法,易于跳出局部极小值,因此使用adam优化器训练模型。
[0063]
(4)训练过程:将预处理好的雷达回波序列与环境场输入网络进行前向运算,最终网络输出外推结果,使用wmse函数计算外推结果与真实结果之间的损失值。然后使用bp算法更新网络权重。
[0064]
模型训练的流程图如图5所示。训练轮数设置为70轮,由于我们更希望能突出模型在预测灾害性天气方面的优势,组合反射率较大的区域需要赋予更多的关注,因此损失函数采用加权mse函数,权值设置为:
[0065][0066]
因为adam优化器可以自适应改变学习率,并且是基于动量的算法,易于跳出局部极小值,因此使用adam优化器训练模型。学习率设为0.001,衰减系数设置为(0.9,0.999)。为了保证训练效率,加快收敛,batch_size设置为8。
[0067]
训练过程:将预处理好的一个批量的雷达回波序列与环境场分别输入网络进行前向运算,最终网络输出外推结果,使用wmse函数计算外推结果与真实结果之间的损失值。然后使用bp算法更新网络权重。然后输入进下一个批量的雷达回波序列与环境场,循环上述步骤,直到达到预设的训练轮数。
[0068]
5.模型评估
[0069]
为了验证加入环境场后的外推效果优于不加环境场的情况,需要对模型预测效果进行合理评估。我们引入的气象学预报指标主要包括:击中率(pod)、虚警率(far)、临界成功指数(csi)、公平技巧评分(ets)以及heidke技巧评分(hss)。在计算评分之前需要设置一个阈值,将大于阈值的点记为正样本,小于阈值的点记为负样本。各评分计算公式如下所示:
[0070]
表2分类结果混淆矩阵
[0071] 预测为正样本预测为负样本真实为正样本tpfn真实为负样本fptn
[0072][0073][0074]
[0075][0076][0077][0078]
我们选取在验证集上阈值为40dbz时后30min的平均csi最高的模型作为测试模型。光流法、无环境场的3d卷积模型以及加入最优环境场的3d卷积模型在每个外推时段中的测试结果如图六所示,不同阈值下全时段的平均结果如下表所示。由图可知,阈值为20,30,40dbz时,某些特定的环境场的加入在一定程度上提升了模型的外推性能,并且阈值越大,提升效果越明显,在一定程度上延长了外推的有效时间。而阈值为50dbz时则无明显效果,推测原因可能是大于50dbz的格点占比太少,而wmse赋予大于50dbz格点的权重又太小,模型很难学习到大于50dbz格点的变化规律。
[0079]
表3加入不同的环境场在不同阈值下的平均csi(验证集)
[0080][0081]
(注:字体加粗表示为该指标最优值,字体加下划线表示该指标次优值)
[0082]
表4阈值为20dbz时不同方法在全时刻下的平均指标(测试集)
[0083][0084]
(注:字体加粗表示为该指标最优值,字体加下划线表示该指标次优值)
[0085]
表5阈值为30dbz时不同方法在全时刻下的平均指标(测试集)
[0086][0087]
(注:字体加粗表示为该指标最优值,字体加下划线表示该指标次优值)
[0088]
表6阈值为40dbz时不同方法在全时刻下的平均指标(测试集)
[0089][0090][0091]
(注:字体加粗表示为该指标最优值,字体加下划线表示该指标次优值)
[0092]
本领域技术人员可以理解附图只是一个优选实施例的示意图。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1