一种基于深度学习的InSAR相位解缠优化方法
本发明涉及到遥感算法开发领域,具体为一种基于深度学习的insar相位解缠优化方法。
背景技术:
0、技术背景
1、随着遥感技术的高速发展与更新,合成孔径雷达干涉测量(interferometricsynthetic aperture radar,insar)等高新遥感技术蓬勃发展,insar技术凭借着全天候、全天时、大范围、低成本、高分辨率,探测地表形变精度可达厘米级甚至毫米级等优势,在地壳形变、地震研究、城市沉降、山体滑坡、火山活动以及煤火监测等领域已被广泛应用。在insar数据处理过程中,相位解缠是影响数据反演质量的关键步骤,加之在地质灾害预警等特种环境下所需的高时效性,探索高效精准的解缠方法对insar高精度监测地表形变显得至关重要。
2、传统的相位解缠技术主要分为两大类:1)通过受限路径积分(称为路径跟踪方法)来估计相位;2)通过最小化包裹相位与近似真实相位之间的函数(称为最小范数法)来估计相位。这些传统方法存在误差累积和计算时间长等关键问题,并且大梯度地形、高噪声环境或涉及复杂地理过程的条件下,往往表现出低效率、大误差甚至失效。因此,探索和开发一种新型的insar相位解缠方法,具有重要的实际意义。这将有可能突破现有技术的限制,提升在复杂环境下的解缠效率和精度,从而更好地服务于地壳形变、地震研究、城市沉降、山体滑坡、火山活动以及煤火监测等重要领域,实现高精度的地表形变监测。
3、另一方面,深度学习作为人工智能领域的重要分支,在许多问题的解决中展示出强大的性能,尤其是图像处理、序列预测等复杂任务中。然而,尽管深度学习在地球物理学的一些子领域(如地震信号处理、地质建模等)得到了一定的应用,但其在insar相位解缠问题上的应用并不普遍。原因在于,其一,深度学习所需数据集庞大,并且训练数据集的客观性和准确性是影响模型应用于实际任务的一大重要因素。其二,insar相位解缠涉及到噪声估计、复杂和非线性地形建模、空间连续性约束、大梯度变化等多个层面,这些都增加了深度学习模型的设计、搭建和训练的难度。
技术实现思路
1、针对上述技术问题,本发明提出一种基于深度学习的insar相位解缠优化方法,该算法包括一个多效应干涉相位仿真(multi-effect interferometric phase simulation,me-ips)和一个扩张多路径相位解缠网络(dilated multi-path phase unwrappingnetwork,dmp-punet)。相较于传统的peaks模拟算法及其他单一效应的模拟方法而言,me-ips提供了更为真实的模拟结果,me-ips旨在通过综合考虑地形效应与数字高程模型(digital elevation model,dem)误差、大气湍流、植被效应、基线几何效应、多次散射效应以及噪声效应的方式仿真干涉相位,一方面解决深度学习训练数据集匮乏问题,另一方面以得到更接近真实场景的结果,从而提高后续相位解缠算法的准确性和适用性。dmp-punet的模型架构启发于u-net++网络,充分利用u-net++强大的特征捕获能力,同时为了防止过拟合现象,并考虑网络模型的用途,对u-net++进行了跳跃连接路径的优化以及扩张卷积感受野的增强,由此构建的dmp-punet可以克服传统解缠方法的限制,同时充分利用深度学习强大的数据驱动和非线性建模能力,能够显著提高insar测量的精度和鲁棒性,以满足日益增长的地貌和地壳运动监测需求。
2、为实现上述技术目的,本发明的一种基于深度学习的insar相位解缠优化方法;
3、综合考虑待测地表的地形效应与dem误差、大气湍流、植被效应、基线几何效应、多次散射效应以及噪声效应,综合考虑了真实世界的主要影响因素,构建多效应干涉相位仿真me-ips,利用me-ips构建模拟干涉相位训练集,获取丰富的训练数据集;
4、基于srtm 30米分辨高程模型dem数据,采用dem反演算法生成真实干涉相位训练数据集;
5、基于u-net++网络,设计对地表地形insar干涉相位解缠的扩张多路径相位解缠网络dmp-punet;
6、将模拟干涉相位训练集和真实干涉相位训练数据集合并成一个数据集后输入dmp-punet网络模型完成训练;
7、利用训练好的dmp-punet模型对将待解缠的insar干涉相位进行解缠,有效降低解缠的耗时。
8、进一步,在考虑地形效应与dem误差时,使用二维正弦函数来模拟地形效应,并加入随机噪声以模拟dem误差,具体公式为:
9、terrain(x,y)=magnitude-1×sin(x)×sin(y)+dem_error×randomnoise(x,y)
10、其中,terrain(x,y)为位置(x,y)的地形效应与dem误差,magnitude_1为地形效应的强度,dem_error为dem的误差;
11、所述的大气湍流效应,使用高斯随机数生成器,模拟大气中随机的扰动,具体公式为:
12、turbulence(x,y)=magnitude_2×randomnoise(x,y)
13、其中:turbulence(x,y)为位置(x,y)的大气湍流值,magnitude_2为湍流的强度,randomnoise(x,y)为位置(x,y)的随机噪声值;
14、所述的植被效应,是使用随机数生成技术模拟特定密度的植被覆盖,具体公式为:
15、vegetation(x,y)=desity×threshold(0.95,randomvalue(x,y))
16、其中,vegetation(x,y)为位置(x,y)的植被效应值,density为植被的密度或覆盖度,randomvalue(x,y)为位置(x,y)的随机值,threshold为一个阈值函数,仅当随机值大于0.95时才返回植被效应值;
17、所述的基线几何效应,利用正弦函数和网格生成技术,具体公式为:
18、baselinegeometry(x,y)=magnitude_3×sin(x)×sin(y)
19、其中,baselinegeometry(x,y)为位置(x,y)的基线几何效应值,magnitude_3为基线几何效应的强度,x,y代表图像中的空间变量;
20、所述的多次散射效应,通过生成随机相位和随机振幅来模拟,其具体公式为:
21、multiplescattering,y)=angle(magnitude_4×ej×randomphase(x,y))
22、其中,multiescattering(x,y)为位置(x,y)的多次散射效应值,magnitude_4为多次散射的强度,randomphase(x,y)为位置(x,y)的随机相位值;
23、所述的噪声,通过设定高斯随机噪声的最大标准偏差noise_max来模拟不同级别的噪声。
24、进一步,me-ips算法构建模拟干涉相位训练集的步骤如下:
25、生成随机矩阵:设置一个初始矩阵的最小尺寸size_min和最大尺寸size_max;在size_min和size_max这两个边界值之间随机选择一个整数,得到初始矩阵的大小size_xy;根据初始矩阵的大小size_xy创建一个随机矩阵initial_matrix,随机矩阵中的值介于0和1之间;
26、调整随机矩阵的值:设置固定的高度值height,将initial_matrix中的每个值乘以height,得到新的矩阵initial_matrix_height;
27、进行插值处理:为initial_matrix_height设置原始网格,原始网格大小与矩阵大小相同,并将原始网格规模化到0至128之间;使用双线性插值和立方插值方法,将initial_matrix_height插值到新的精细网格上,得到initial_matrix_interp;
28、设置参数并处理相位:定义最小高度值height_min和最大高度值height_max;从height_min和height_max高度范围中随机选择一个值作为最大绝对相位值h;
29、标准化initial_matrix_interp到0至h的范围,得到纯净的绝对相位
30、使用欧拉公式将纯净的绝对相位转换为复数形式,具体公式为:
31、
32、其中,i为虚数单位;
33、从绝对相位的复数形式计算对应的纯净的缠绕相位wrapped_phase,使用公式:
34、
35、其中,im表示复数的虚部,re表示复数的实部;
36、在得到的纯净的缠绕相位依次加入上述模拟的地形效应与dem误差、大气湍流、植被效应、基线几何效应、多次散射效应以及噪声六种效应,得到多效应的缠绕相位mul_wrapped_phase;
37、重新调整尺寸:定义目标尺寸new_size,将绝对相位和多效应的缠绕相位mul_wrapped_phase按立方插值方法调整为目标尺寸new_size大小的纯净的绝对相位ap_resized和多效应的缠绕相位wp_resized;得到模拟干涉相位训练集的一个样本;
38、重复上述步骤即可得到更多的模拟干涉相位训练集的样本。
39、进一步,dem反演算法生成真实干涉相位训练数据集的步骤如下:
40、获取dem 30米分辨率的数据:从网站https://earthexplorer.usgs.gov/上随机获取中国范围内的n幅dem数据。
41、dem数据提取:在n幅dem数据中随机裁切出n幅目标尺寸new_size×new_size大小的dem;
42、设置参数并处理相位:定义最小高度值h_min和最大高度值h_max;从h_min和h_max高度范围中随机选择一个值作为最大真实相位hreal;
43、标准化dem到0至hreal的范围,得到真实的绝对相位
44、使用欧拉公式将真实的绝对相位转换为复数形式,具体公式为:
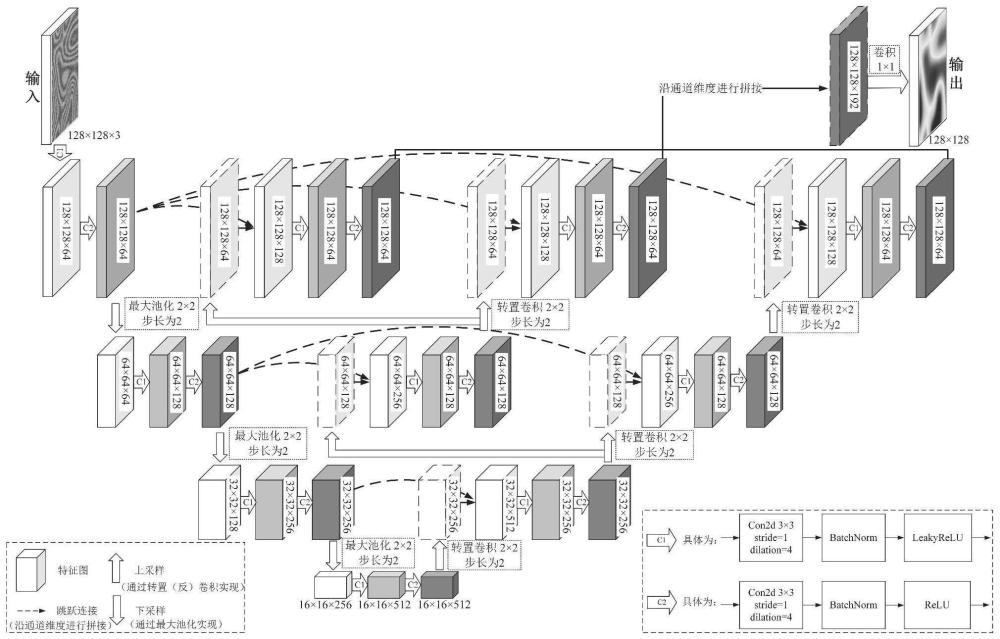
45、
46、其中,i为虚数单位;
47、使用下列公式从绝对相位的复数形式计算对应的真实缠绕相位wrapped_phase_real:
48、
49、其中,im表示复数的虚部,re表示复数的实部;
50、最终获得真实干涉相位训练数据集的一个样本;
51、重复上述即可得到真实干涉相位训练数据集中更多的样本。
52、进一步,所述的dmp-punet网络模型包括依次设置的下采样和上采样,下采样和上采样之间通过跳跃连接;
53、所述的下采样包括顺序连接的输入卷积、第一层下采样、第二层下采样和第三层下采样;其中三层下采样结构相同,均包括顺序设置的最大池化、扩张卷积、批量归一化、leakyrelu激活函数、扩张卷积、批量归一化、relu激活函数、输出;
54、所述的上采样包括顺序连接的第一层下采样、第二层下采样、第三层下采样和输出卷积;其中三层下采样结构相同,均包括顺序设置的转置卷积、串联、扩张卷积、批量归一化、leakyrelu激活函数、扩张卷积、批量归一化,relu激活函数、输出。
55、进一步,下采样具体为:
56、输入卷积块:输入尺寸为a×a的缠绕相位,首先通过一个卷积核大小为m×m的扩张卷积,其扩张率为dilation_rate,输入通道为n_channels,输出通道为m_channels的特征图;接着,经过批量归一化、leakyrelu激活函数处理,保持m_channels通道;之后,数据再次经过一个m×m的扩张卷积,扩张率为dilation_rate,输入和输出通道数均为m_channels;再进行一次批量归一化、relu激活函数处理,输出大小a×a,通道数m_channels特征图1;
57、第一层下采样:输入特征图1首先经过p×p的最大池化,尺寸减少一半a/2×a/2;接着,通过m×m的扩张卷积,扩张率为dilation_rate,输入通道为m_channels,输出通道为2×m_channels;进行批量归一化、leakyrelu激活函数处理;数据再次经过m×m的扩张卷积,扩张率为dilation_rate,输入和输出通道数均为2×m_channels;再次进行批量归一化、relu激活函数处理,输出大小a/2×a/2,通道数2×m_channels的特征图2;
58、第二层下采样:特征图2首先经过pp×pp的最大池化操作,使得特征图的尺寸减少到原来的一半,为a/4×a/4;接着,通过m×m的扩张卷积,这次卷积的扩张率为dilation_rate,输入通道数为2×m_channels,输出通道数为4×m_channels;特征图经过批量归一化处理、leakyrelu激活函数,通道数保持为4×m_channels;再次通过一个m×m的扩张卷积,其扩张率为dilation_rate,输入通道和输出通道都是4×m_channels;经过第二次批量归一化、relu激活函数处理,输出大小a/4×a/4,通道数4×m_channels的特征图3;
59、第三层下采样:特征图3首先进入p×p的最大池化操作,尺寸再次减半,为a/8×a/8;接下来,特征图经过m×m的扩张卷积,扩张率为dilation_rate,输入通道为4×m_channels,输出通道为8×m_channels;通过批量归一化、leakyrelu激活函数处理,通道数保持为8×m_channels;再次通过m×m的扩张卷积,扩张率为dilation_rate,输入和输出通道均为8×m_channels;最后,经过批量归一化、relu激活函数处理,输出大小a/8×a/8,通道数8×m_channels的特征图4;
60、进一步,上采样和跳跃连接具体为:
61、第一层上采样:上采样开始于特征图4,使用卷积核大小q×q转置卷积(也称为反卷积)进行上采样,使得特征图尺寸增大到原来的两倍,为a/4×a/4;此时的输出的特征图通道数为4×m_channels;然后,该特征图与先前下采样过程中4×m_channels通道的特征图3进行串联,形成一个有8×m_channels(即4×m_channels+4×m_channels)通道的特征图;特征图经过m×m的扩张卷积,扩张率为dilation_rate,输入通道为4×m_channels,输出通道为4×m_channels;批量归一化被应用于特征图,此时通道数仍然为4×m_channels;特征图通过leakyrelu激活函数,通道数继续保持为4×m_channels;再次,特征图通过m×m的扩张卷积,扩张率为dilation_rate4,输入和输出通道均为4×m_channels;紧接着是另一个批量归一化步骤,通道数仍为4×m_channels;最后,特征图经过relu激活函数处理,输出大小a/4×a/4,通道数4×m_channels的特征图5;
62、第二层上采样:首先,特征图5经过两轮q×q转置卷积,上采样得到尺寸为a/2×a/2,通道数为2×m_channels的特征图up2_1和特征图up2_2;由于后续对特征图up2_1和特征图up2_2的操作相同,这里仅以特征图up2_1为例进行详细说明;紧接着,特征图up2_1与先前下采样中的特征图2进行串联,分别形成4×m_channels(即2×channels+2×channels)通道的特征图;经过m×m的扩张卷积,扩张率为dilation_rate,输入通道为4×m_channels,输出通道为2×m_channels;批量归一化被应用于特征图,此时通道数仍然为2×m_channels;特征图通过leakyrelu激活函数,通道数继续保持为2×m_channels;再次,特征图通过m×m的扩张卷积,扩张率为dilation_rate,输入和输出通道均为2×m_channels;紧接着是另一个批量归一化步骤,通道数仍为2×m_channels;最后,特征图经过relu激活函数处理,输出大小a/2×a/2,通道数2×m_channels的特征图6;同理,特征图up2_2经过上述操作最终得到大小a/2×a/2,通道数2×m_channels的特征图7;
63、第三层上采样:首先,特征图6经过两轮q×q转置卷积,上采样得到尺寸为a×a,通道数为m_channels的特征图up1_1和特征图up1_2,特征图7经过q×q转置卷积得到尺寸为a×a,通道数为m_channels的特征图up1_3;后续对up1_1、up1_2以及up1_3的操作相同,故以up1_3为例具体介绍;紧接着,特征图up1_3与先前下采样中的特征图1进行串联,分别形成2×m_channels(即channels+channels)通道的特征图;特征图经过m×m的扩张卷积,扩张率为dilation_rate,输入通道为2×m_channels,输出通道为m_channels;批量归一化被应用于特征图,此时通道数仍然为m_channels;特征图通过leakyrelu激活函数,通道数继续保持为m_channels;再次,特征图通过m×m的扩张卷积,扩张率为dilation_rate,输入和输出通道均为m_channels;紧接着是另一个批量归一化步骤,通道数仍为m_channels;最后,特征图经过relu激活函数处理,输出大小a×a,通道数m_channels的特征图8;同理,特征图up1_2经过上述操作最终得到大小a×a,通道数m_channels的特征图9;特征图up1_3经过上述操作最终得到大小a×a,通道数m_channels的特征图10;
64、跳跃连接起到了在网络中保持信息流通的作用,使得深层特征可以直接与浅层特征相结合,增强了特征的表达能力;在上述的上采样过程中,可以观察到先前下采样得到的特征图被与上采样后的特征图进行串联;这些连接的过程,就是实现了跳跃连接;
65、输出卷积:在完成所有的上采样步骤之后,模型的输出部分包含了从三个m_channels通道的特征图up1_1、up1_2和up1_3进行串联的操作,产生了一个具有192通道的特征图11;此特征图11进入一个输出卷积层;在这里,一个1×1的卷积核被应用于减少通道数,从192通道减少到目标通道n_classes,最终输出得到大小a×a,通道数为n_classes的特征图12;
66、进一步,利用构建好的dmp-punet模型对训练数据进行训练;
67、将me-ips算法得到的多效应缠绕相位mul_wrapped_phase和dem反演算法得到的真实缠绕相位wrapped_phase_real作为dmp-punet模型的输入数据,将me-ips算法得到对应的纯净绝对相位和dem反演算法得到对应的真实绝对相位作为dmp-punet模型对的输出数据,即标签数据,进行训练网络;其中模型训练采用的是l1损失函数,其计算公式如下:
68、
69、其中,是损失项,n为参与模型训练的样本总数,为第i个训练样本的预测值,为第i个样本的真实值。
70、有益效果
71、本发明提供了一种基于深度学习的insar相位解缠优化方法,该方法实现方便,效果显著,主要体现在以下三点:
72、第一,通过me-ips以及dem反演的干涉相位,能够更为全面和准确地模拟真实环境中的干涉相位效应。相较于简单的基于随机矩阵法、peaks函数法等,me-ips能够更加准确地模拟真实环境中复杂的干涉相位效应,包括地形、大气和其他随机效应。这种模拟技术以及dem反演技术确保了在深度学习阶段为模型提供了高质量的训练数据。
73、第二,dmp-punet与传统的相位解缠技术相比较,具有结构上的显著优势。dmp-punet利用特定的空洞卷积技术来捕捉更广泛的上下文信息,并利用leakyrelu激活函数来增强网络的非线性建模能力,dmp-punet不仅具备高效的处理速度,还能实现更高的解缠准确性。此外,与u-net++相比,dmp-punet的解码机制更加专业化,其特有的解码结构为模型提供了更丰富的特征融合和上采样策略,能够实现更为精细化的相位解缠效果。
74、第三,当me-ips、dem反演技术与dmp-punet三者结合,形成一个高效、精确且鲁棒的相位解缠框架。在数据生成层面,me-ips与dem反演为模型训练提供了丰富且精确的数据源;在模型层面,dmp-punet确保了相位的准确解缠。与传统的相位解缠方法(如:路径跟踪法、最小范数法)对比,此框架不仅能提供更高的解缠准确度,而且在处理各种复杂场景时展现出卓越的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!