一种视觉伺服托盘姿态识别方法与流程
本发明涉及姿态识别,具体为一种视觉伺服托盘姿态识别方法。
背景技术:
1、随着物流行业的飞速发展,agv在行业中的应用越来越广泛,姿态识别系统对于agv来说至关重要,它可以识别任意摆放的载具,通过视觉识别技术精确定位到载具的位置,进而精确叉取。
2、但是当前已有的方案依赖于车子本身的定位系统、控制系统以及姿态识别系统。当车身的定位系统精度不够的情况下,会影响到控制精度以及姿态识别的精度,最终影响到取货精度,同时目前已有的方案都需要车子停下来拍照,效率低下。
技术实现思路
1、本发明的目的在于提供一种视觉伺服托盘姿态识别方法,以解决上述背景技术中提出现有的姿态识别由于定位导航系统误差过大导致载具取不正确以及停车拍照效率低的问题。
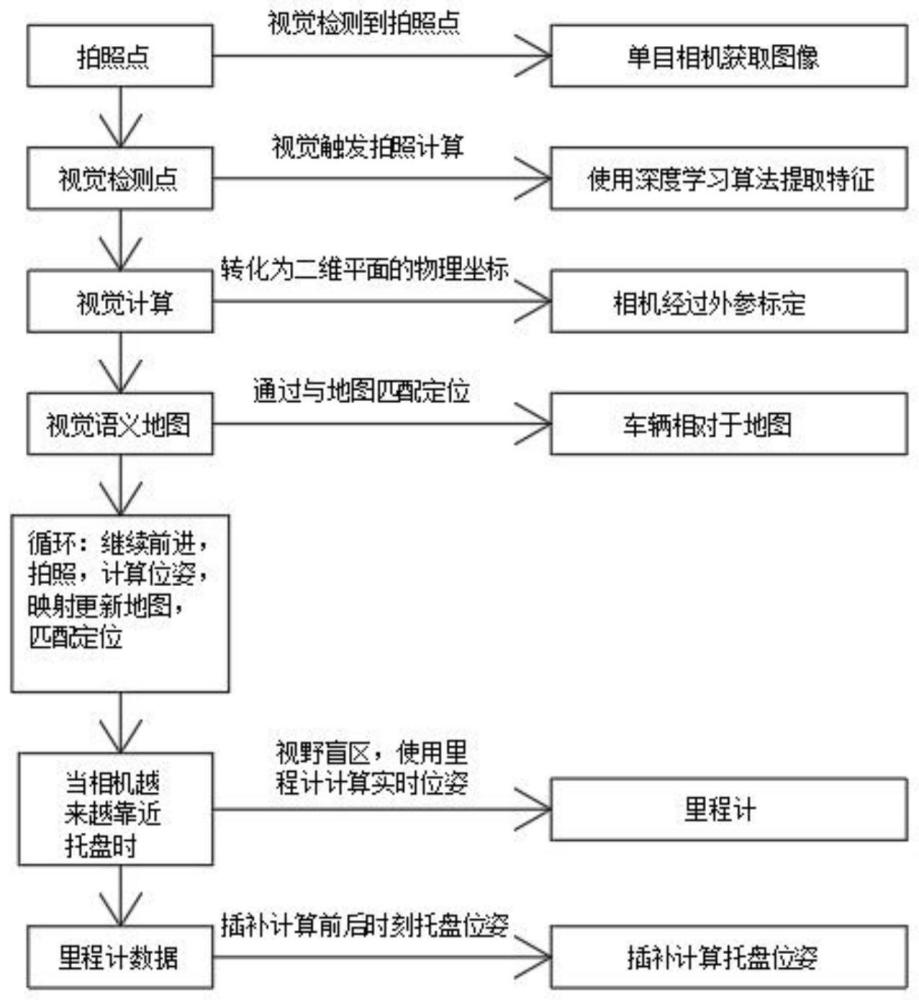
2、为实现上述目的,本发明提供如下技术方案:一种视觉伺服托盘姿态识别方法,包括标定模块、托盘姿态识别模块、实时计算位姿模块和卡尔曼滤波模块,本方法架构和提供的处理流程步骤如下:
3、步骤1、获取位姿(h1),车子运动过程中,视觉触发拍照并计算出拍照时刻载具相对于车体的位姿(h1);
4、步骤2、视觉拍照到视觉计算出托盘位姿的这段时间,可通过里程计得到车子自身运动的位姿(h2);
5、步骤3、计算当前时刻托盘的位姿(h3):h3=h2.inv()*h1,其中h2.inv()表示矩阵h2的逆;
6、步骤4、重复上述过程,连续求得托盘相对于车体的位姿;
7、步骤5、当相机越来越靠近托盘而无法拍摄到托盘表面时(视野盲区),使用车上的里程计来实时计算托盘相对于车体的位姿。
8、优选的,在步骤2和步骤3中,通过视觉拍照到视觉计算出托盘位姿这段时间车子自身运动的位姿(h2)和拍照时刻载具相对于车体的位姿(h1),计算得到当前时刻托盘的位姿(h3)。
9、优选的,在步骤4中,通过不断拍照、计算位姿和对里程计积分,实现持续托盘位姿估计。
10、优选的,在步骤5中,当相机视野无法拍摄到托盘表面时,由车上的里程计提供实时的托盘相对于车体的位姿,以保证控制的稳定性。
11、优选的,所述标定模块主要是求出相机变换到车体坐标系的位姿,本标定采用棋盘格标定法,首先确定棋盘格在车体坐标系下的位姿,再计算棋盘格相对于相机坐标系的位姿,从而计算出相机坐标系相对于车体坐标系的位姿。
12、优选的,所述托盘姿态识别模块中姿态识别传感器采用的是tof相机或激光雷达,当tof相机无法工作时,采用激光雷达也可以实现同样的功能,该部分主要由基于深度学习的目标检测+点云分割组成,根据目标检测模块得到托盘在图像上的大致区域,同时可获取该区域托盘的点云数据,采用点云滤波算法以及点云分割算法,求得托盘表面中心点的xyz以及角度的数据,乘以标定得到的相机外参矩阵最终获得托盘相对于车体的位姿。
13、优选的,所述实时计算位姿模块如方法流程步骤所述,视觉伺服系统实时获取车体里程计的结果,同时获取拍照时刻的托盘位姿,进而插补获得实时的托盘位姿。
14、优选的,所述卡尔曼滤波模块采用卡尔马滤波,卡尔马滤波即根据预测值和测量值得到的真实值的最优估计,这里的预测值即为根据里程计插补得到的托盘位姿,观察值为相机拍照计算得到的托盘位姿,而预测值与测量值都存在误差,利用卡尔曼滤波的思想可以计算出预测值与测量值之间的均方误差最小,进而求得更加准确的托盘位姿。
15、与现有技术相比,本发明的有益效果是:
16、1、引入里程计,使用视觉实时估计托盘位姿,不依赖车身的导航系统,不停车拍照也能够实时计算载具的位姿。
17、2、取货精度高,当前agv的最终取货误差包含:定位导航误差、控制误差、姿态识别误差,而本系统忽略了定位导航的误差,同时利用多次拍照求得最终的载具位姿。
技术特征:
1.一种视觉伺服托盘姿态识别方法,其特征在于,包括标定模块、托盘姿态识别模块、实时计算位姿模块和卡尔曼滤波模块,本方法架构和提供的处理流程步骤如下:
2.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:在步骤2和步骤3中,通过视觉拍照到视觉计算出托盘位姿这段时间车子自身运动的位姿(h2)和拍照时刻载具相对于车体的位姿(h1),计算得到当前时刻托盘的位姿(h3)。
3.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:在步骤4中,通过不断拍照、计算位姿和对里程计积分,实现持续托盘位姿估计。
4.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:在步骤5中,当相机视野无法拍摄到托盘表面时,由车上的里程计提供实时的托盘相对于车体的位姿,以保证控制的稳定性。
5.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:所述标定模块主要是求出相机变换到车体坐标系的位姿,本标定采用棋盘格标定法,首先确定棋盘格在车体坐标系下的位姿,再计算棋盘格相对于相机坐标系的位姿,从而计算出相机坐标系相对于车体坐标系的位姿。
6.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:所述托盘姿态识别模块中姿态识别传感器采用的是tof相机或激光雷达,当tof相机无法工作时,采用激光雷达也可以实现同样的功能,该部分主要由基于深度学习的目标检测+点云分割组成,根据目标检测模块得到托盘在图像上的大致区域,同时可获取该区域托盘的点云数据,采用点云滤波算法以及点云分割算法,求得托盘表面中心点的xyz以及角度的数据,乘以标定得到的相机外参矩阵最终获得托盘相对于车体的位姿。
7.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:所述实时计算位姿模块如方法流程步骤所述,视觉伺服系统实时获取车体里程计的结果,同时获取拍照时刻的托盘位姿,进而插补获得实时的托盘位姿。
8.根据权利要求1所述的一种视觉伺服托盘姿态识别方法,其特征在于:所述卡尔曼滤波模块采用卡尔马滤波,卡尔马滤波即根据预测值和测量值得到的真实值的最优估计,这里的预测值即为根据里程计插补得到的托盘位姿,观察值为相机拍照计算得到的托盘位姿,而预测值与测量值都存在误差,利用卡尔曼滤波的思想可以计算出预测值与测量值之间的均方误差最小,进而求得更加准确的托盘位姿。
技术总结
本发明涉及姿态识别技术领域,具体为一种视觉伺服托盘姿态识别方法,包括标定模块、托盘姿态识别模块、实时计算位姿模块和卡尔曼滤波模块,本方法架构和提供的处理流程步骤:获取位姿(H1),车子运动过程中,视觉触发拍照并计算出拍照时刻载具相对于车体的位姿(H1),视觉拍照到视觉计算出托盘位姿的这段时间,可通过里程计得到车子自身运动的位姿(H2),根据H1和H2可计算当前时刻托盘相对于车体的位姿(H3),使用里程计对视觉拍照到计算出托盘位姿这段时间插值,可输出托盘相对于车体更精细的位姿。本发明引入车载里程计,使用视觉实时估计托盘位姿,不依赖车身的定位系统,可以提高载具的取放效率和取货精度。
技术研发人员:陈文成,吕朝顺,黄金勇,董邓炜
受保护的技术使用者:劢微机器人科技(深圳)有限公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!