基于虚拟飞行经验的着舰指挥员纵向强制指令建模方法与流程
本发明属于飞行器设计和飞行安全管理技术领域,主要用于舰机适配性设计和舰载机飞行安全仿真。
背景技术:
着舰过程中的指挥信息交互和飞行安全密切相关,美军就曾发生过因着舰指挥员(Landing Signal Officer,简称LSO)失误而产生的飞行安全事件。而开展LSO建模是开展多因素耦合着舰飞行安全仿真预测和多信息交互研究的基础。因此,开展LSO指挥行为建模研究有着重要意义。目前的LSO模型研究中,大多对LSO进行了简化。如参考文献[1](王立鹏.舰载机着舰指挥官指挥策略研究[M].哈尔滨工程大学硕士学位论文,哈尔滨,2012,3.)对LSO指令简化,建立了七标度的模糊建模。参考文献[2](屈香菊,崔海亮,王延刚.舰载机人工控制下LSO仿真模型[R].GF-A0085884G,北京:北京航空航天大学,2005,10)也对LSO建模方法进行了研究,但同样采用了模糊法对LSO指令建模。这些研究为LSO指令建模起到了极为重要的基础性作用,但这些研究没有详细区分信息类指令、建议类指令和强制类指令,也没有基于LSO决策机理对强制指令进行建模,因此在多人机交互闭环仿真中,无法完全反映LSO指挥决策过程。因此,有必要提供一种符合LSO决策机理,满足飞行安全仿真需要的LSO指令强制建模方法,解决上述问题。
技术实现要素:
本发明提供的基于虚拟飞行经验的LSO纵向强制指令建模方法,具体包括如下步骤:
第一步,建立带有飞行员观察阈值特性的人机闭环动力学模型。
第二步,确定LSO和飞行员约定操纵原则。
第三步,以飞行安全指标为目标函数,以约定操纵原则为前提条件,寻优求解并计算指令包线。
第四步,汇总强制指令包线,形成LSO指令产生式系统。
在上述步骤中,LSO和飞行员约定操纵原则,是指飞行员和LSO双方默认的操纵方式和幅值大小。飞行安全指标是指判定飞行风险发生的标准,可包括舰尾静高、着舰偏差等内容。指令包线是指以飞行安全为目标的,LSO指令下达范围,即一旦飞机偏差状态进入指令包线,那么LSO就下达相应强制推力指令。在本发明中指令包线是由高度偏差、下沉率偏差、飞机与母舰相对位置构成的一组曲线。
本发明的优点在于:
(1)提供了基于虚拟飞行经验的LSO强制指令建模方法,解决了LSO强制指令模型的有无问题。为多人机交互飞行安全仿真中的LSO指令生成提供了建模手段,为多因素耦合舰载机着舰飞行安全仿真模型建立奠定了基础。
(2)本发明根据人类知识经验生成机理,采用虚拟飞行经验方法建立模型,与真实LSO指令形成过程更为接近。
(3)本发明采用飞行员数学模型,通过飞行仿真,生成LSO强制指令包线,最终形成类似人脑的产生式指令系统,在仿真中通过二维插值即可实现,使用方便。
附图说明
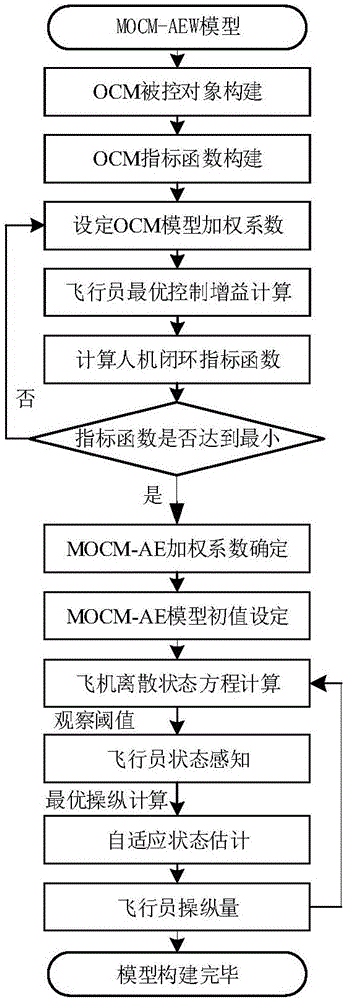
图1是带有飞行员观察阈值特性的人机闭环动力学模型计算流程示意图。
图2是“给点油门”指令包线示意图。
图3是“给点油门”指令允许区仿真对比算例图。
图4是“恢复推力”指令包线示意图。
图5是“加油门”指令包线示意图。
图6是“开加力”指令包线示意图。
图7实施例1下沉率Δhdot=2m/s指令包线汇总示意图。
图8是实施例2中LSO指挥下着舰轨迹末端放大图。
图9是实施例2中LSO指挥下飞行员仿真操纵量。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
本发明提供一种基于虚拟飞行经验的LSO纵向强制指令建模方法,所述方法包括如下步骤:
第一步:建立带有飞行员观察阈值特性的人机闭环动力学模型(Modified Optimal Control Pilot Model with Adaptive State Estimation and Optimal Weigtings,简称MOCM-AEW)。这一模型在后续步骤中将通过虚拟飞行形成LSO指令包线。如图1所示,所述的MOCM-AEW模型包括基于最优注意力分配的加权系数选择和MOCM-AE模型与最优加权系数结合应用两部分,具体步骤如下:
步骤一:构建形如下式的增广被控对象:
其中,xs是带有延迟的增广状态向量,为xs的一阶导数,As、Bs、Cs、Ds、Es是增广系数矩阵,up是飞行员操纵量,y是输出状态量,w是外界扰动向量。其中Cs=[C DCd],Ds=D,x为飞机小扰动方程状态向量。xd是带有延迟的增广状态向量,Ad、Bd、Cd分别为时间延迟系数矩阵。A、B、C、D、E是飞机小扰动方程系数矩阵。
飞行员实际感知向量yobs为:
yobs=Csxs+Dsup+vy (2)
其中vy是与近期观测历史有关的感知噪声,采用高斯白噪声建模,也称观测噪声。观测噪声强度Vy为其中ρy是感知噪声信噪比,典型单通道跟踪任务中感知噪声信噪比ρy通常为0.01,对应信噪比为-20dB,为观测噪声方差。
步骤二,根据飞行任务,构建驾驶员最优控制模型指标函数,设定初始加权系数值Qy和ru。采用二次指标函数构建驾驶员最优控制模型指标函数Jp如下:
其中,Qy是观察向量加权系数,ru是操纵向量加权系数,f是操纵速率加权系数,是up的一阶导数。它们反映了飞行员对信息观察、油门杆、驾驶杆、操纵速率等不同驾驶要素的重视程度。其中f的选择依赖于给定的神经动力延迟常数Tn。E∞是指标函数稳态期望值。本发明要解决的问题就是设法确定指标函数加权系数Qy和ru取值。
步骤三,计算飞行员最优控制增益。可以通过最优控制理论得到控制关系为:
其中,是飞行员最优操纵量,Gp是调节器增益向量,是状态向量X的估计值,K是由下列Riccati方程确定的唯一解:
0=(Ao)TK+KAo+Qo-KBof-1(Bo)TK (5)
其中,
将X=[xs up]T=[x xd up]T代入(4)式,则,
其中Gn是增益向量,为xs的估计值,Gn1是的增益向量。令,
则,
Ip即为飞行员最优控制增益。因此,(7)式可写为,
令引入操纵噪声vu,则
其中vu是强度为Vu的零均值高斯白噪声。ρu是操纵噪声信噪比系数,是操纵噪声方差。
步骤四:循环迭代求解观测噪声方差和操纵噪声方差,计算Kalman滤波增益。
联立(1)和(11)式得到:
其中,为带有操纵量的增广状态向量X的一阶导数,w为外界扰动向量,vu为操纵噪声,vy为观测噪声,C1=[C DCd D]。
状态向量X的估计值可以由Kalman滤波得到,其中滤波增益矩阵F为:
F=Σ1(C1)T(Vy)-1 (13)
其中,Vy为观测噪声强度,估计误差矩阵Σ1是由下列Riccati方程确定的唯一解:
0=A1Σ1+Σ1(A1)T+W1-Σ1(C1)T(Vy)-1(C1)Σ1 (14)
其中W1=diag(W,Vu),W为外界扰动强度,Vu为操纵噪声强度。带有状态估计的人机闭环状态方程为,
其中I1=[Ip,0],Cδ=[0 Cd 1],F为Kalman滤波增益矩阵,δ为飞机舵面偏转量。
协方差矩阵Xcov是下列Lyapunov方程的解:
其中,Qlyp=diag(W,Vy,Vu),Vy是观测噪声强度,Vu操纵噪声强度。
则,输出协方差矩阵:
其中,
由此得到观测噪声方差和操纵噪声方差分别为:
这样对于给定初始操纵噪声强度Vu和观测噪声强度Vy,可以分别得到一个和并可以分别计算得到信噪比系数ρy和ρu,由此可以形成循环迭代计算,直到信噪比满足ρy=0.01和ρu=0.003为止。同时,迭代结束后可以得到Kalman滤波增益。
步骤五:计算指标函数J。
其中,Je=Ycov(1,1),Ju=Ycov(2,2),row_u=row_X-row_x-row_xd,row_X是向量X的行数,row_x是向量x的行数,row_xd是向量xd的行数。
步骤六:根据最优注意力分配假设计算加权系数。
根据加权系数选择原则和指标函数计算原则,飞行员可以最优的对注意力分配,使指标函数最小。由此,设定不同Qy和ru,可以通过共轭梯度法寻优计算直到指标函数J取得最小值。由此确定了OCM模型最优加权系数Qy和ru。
步骤七:根据最优加权系数和飞行员模型指标函数设定驾驶员模型初值。
步骤八:离散飞机状态方程计算,得到飞机当前时刻动态响应。
将方程(1)、方程(11)离散化如下:
其中H、Bdis、Ddis是状态转移矩阵。Фu、Budis、Eudis是操纵向量离散方程状态向量。给定xs、y、w、up在k-1时刻初值,即可计算飞机当前时刻动态响应。
步骤九:飞行员根据外界感知进行自适应状态估计。时变噪声估值器如下,
其中(k)表示k时刻,(k-1)表示k-1时刻,为扰动均值估计,扰动方差矩阵估计,ε是新息向量,是观察噪声方差估计,是观察噪声均值估计,d是渐进遗忘系数,dk-1=(1-b)/(1-bk),0<b<1,b为遗忘因子。P是状态预测方程矩阵,I是单位阵,D(k)是递推算子,表达式如下:
自适应滤波器为:
P(k|k)=[In-KF(k)H(k)]P(k|k-1) (32)
是X的估计值,KF是滤波增益。
步骤十:由式(22)根据最优控制理论,得到飞行员最优操纵量。
步骤十一:带有飞行员观察阈值特性的人机闭环动力学模型构建完毕。
第二步:确定LSO和飞行员约定操纵原则。
LSO和飞行员约定的推力根据飞机油门特性和油门杆设置确定。假设舰载机正常下滑操纵时油门杆限位是配平位置的±10°。则假设LSO和飞行员约定的油门指令对应关系如下表1:
表1强制推力指令约定表
其中δT0是下滑配平状态油门杆位置。
第三步:以飞行安全指标为目标函数,以约定操纵原则为前提条件,寻优求解并计算指令包线。
为保证复飞安全,一般要求舰尾净空至少为3m,因此本发明飞行安全指标以舰尾静高3m为标准。在着舰指挥中,LSO对飞行状态进行预判,如果LSO预判飞机到达舰尾时静高小于3米则认为存在危险,则LSO下达相应的强制指令。此处,计算指令包线的方法是,以飞机与理想着舰点的相对位置X、位置X处的下沉率偏差Δhdot和高度偏差Δh0为自变量,以到底舰尾的静高3m为目标函数,采用第一步MOCM-AEW模型,以某一强制指令为输入,采用共轭梯度法寻优计算,则可以得到一组该强制指令对应的下沉率偏差和高度偏差曲线集,即指令包线。
第四步:汇总强制指令包线,形成LSO指令产生式系统。
将“给点油门、恢复推力、加油门、开加力”四条曲线进行汇总,即形成了LSO强制指令产生式系统。
实施例1:
下面以“给点油门”指令说明指令包线计算过程和本发明有益效果。
第一步:建立带有飞行员观察阈值特性的人机闭环动力学模型(MOCM-AEW)。其中模型参数如表2所示。
表2 MOCM-AEW模型参数
第二步:确定LSO和飞行员约定操纵原则如表1所示。
第三步:以飞行安全指标为目标函数,以约定操纵原则为前提条件,寻优求解并计算指令包线。根据LSO以往飞行经验,“给点油门”是根据飞机的偏差状态和偏差出现时机给出的。为此采用MOCM-AEW驾驶员模型对LSO飞行经验进行仿真模拟。计算结果如图2所示,根据初始下沉率偏差Δhdot、距离理想着舰点距离X、高度偏差Δh0,给出了“给点油门”LSO指令允许区。如图2所示,每条曲线下阴影部分即为指令允许区。同时,由于计算采用的目标函数是舰尾处静高,因此指令允许区的位置边界是x=-80m,即舰尾点相对理想着舰点坐标。由仿真可见,随着下沉率的增加,指令允许区逐渐减小。随着飞机接近舰尾,LSO指令允许的高度偏差逐渐减小。这与实际情况是相符的。为说明指令允许区的合理性,分别比较指令包线内外各一点,如图2中A点和B点,算例下沉率增量为4m/s,偏差出现位置为X=-300m,高度偏差分别为ΔhA=-15m和ΔhB=10m。进行着舰仿真,A点、B点以及理想着舰着舰轨迹如图3所示,A点和B点在舰尾处的静高分别是-4.7423m和14.8617m(向下为正)。显然对于B点飞行状态,即便LSO给出了“给点油门”指令,飞机仍将撞舰。因此通过这一指令的计算可以说明,本发明所述LSO指令包线计算是准确和合理的。
步骤四:汇总强制指令包线,形成LSO指令产生式系统。同样计算“恢复推力”、“加油门”、“开加力”的指令包线如图4~6所示。以Δhdot=2m/s为例比较相同下沉率不同指令的指令包线,如图7所示。参见图7其中区域1、2、3、4即为下沉率Δhdot=2m/s时“给点油门”、“恢复推力”、“加油门”和“开加力”的LSO指令区。而飞机偏差状态一旦进入区域5,即使飞行员开加力,飞机到达舰尾静高仍将小于3m,产生较大着舰风险。
汇总后的LSO强制推力指令的使用方法如下:
第一步:进入复飞决策点后,对每一时刻(位置X)进行状态判断。根据位置和当前下沉率(X,Δhdot),进行二维插值,计算当前状态对应的“给点油门、恢复推力、加油门、加力”包线高度偏差边界值。
第二步:根据当前飞行状态(X、Δh、Δhdot),按照指令包线,选择LSO指令。
第三步:根据LSO指令,飞行员加以操纵或根据指令进行多人机交互闭环仿真。
由此实现了LSO强制推力指令建模和仿真。
实施例2
下面采用着舰仿真对LSO指令模型进行验证。如果在LSO指挥下,飞机的着舰精度和安全性得到提高,那么就说明本发明中提供的LSO建模是合理的。仿真验证算例参数如表2所示。为清楚比较LSO指令下的偏差修正能力,避免随机性产生的影响,在着舰仿真中去掉了大气扰动影响。在LSO强制类推力指令仿真中,设定偏差位置X=-1429m,初始偏差Δhdot=4.5m/s、Δh=20m。比较LSO强制推力指令下的飞行仿真结果如图8所示,为直观显示,仅给出了末端轨迹放大图。图9为LSO指挥下的飞行员操纵比较图。由图8可见,没有LSO指挥时,飞机在舰尾处的静高h=-1.0543m(倒三角轨迹),当仅有LSO信息类和建议类指令时(圆点轨迹),静高h=-1.7147,而LSO下达强制推力指令后,飞机静高为h=-3.9491m(正三角轨迹)。通过这一比较说明了LSO强制指令在确保飞行安全中的合理性。同时图9示出了LSO指挥下的飞行员操纵行为,可见在距着舰480m左右时,LSO下达了开加力指令,由此确保了飞机飞行安全。
本发明针对传统LSO无法与LSO真实指令建立关联的现状。对LSO强制推力指令采用虚拟飞行经验获,建立了LSO强制指令包线,形成了LSO指令产生式系统。实施例表明LSO指挥在提高着舰精度,确保飞行安全方面具有重要作用,这说明了本发明LSO指令模型建模方法的合理性和模型准确性。
- 还没有人留言评论。精彩留言会获得点赞!