一种基于虚拟现实和强化学习的熊蜂机器人摆腹控制方法与流程
本发明涉及昆虫机器人技术领域,具体涉及一种基于虚拟现实和强化学习的熊蜂机器人摆腹控制方法。
背景技术:
昆虫机器人是以昆虫为载体,结合控制模块形成的一种新型动物机器人系统。这类特殊机器人借助载体本身运动能力,不需要考虑复杂的机械及动力系统,在科学研究、国防安保、工业生产等领域有广泛的应用前景。
如何控制昆虫飞行是昆虫机器人研究中首要解决的问题。昆虫机器人一般包括行为刺激模块、昆虫行为采集与分析模块、控制指令决策三个部分。
目前,昆虫机器人的行为刺激方式以电刺激为主,并通过人手工来调节昆虫在不同运动状态下所对应的电刺激参数。电刺激方法是通过动物手术将硅或者微丝电极植入到昆虫的肌肉或者神经系统,采用微控制器生成方波脉冲输入到昆虫的刺激位点,达到控制昆虫左右偏转等行为的目的。虽然电刺激式的昆虫机器人取得了长足的进步,但是仍然存在若干问题:
第一,在植入刺激电极过程中会对昆虫的肌肉或者神经系统造成损伤,导致后续的控制性能下降;第二,长时间的电刺激会造成昆虫疲劳,对电刺激的响应灵敏度下降;第三,由于昆虫体型较小,大部分昆虫的肌肉和大脑的体积约为1立方毫米,那么一次电刺激可能涉及多个感觉-运动回路,甚至是整个肌肉或者大脑,从而引发不确定的行为反应;第四,若要进行人工调节刺激参数,需要事先进行大量的生物实验得到刺激-行为响应的关系,这样需要大量的生物实验,将消耗大量的时间,且不同昆虫个体对相同刺激参数的行为响应仍存在较大的偏差,因此人工调节刺激参数的方式存在效率低下,控制不精准等问题;
开发非植入式的控制方式可以避免上述对昆虫机体造成损伤的问题。大量研究表明,光流在昆虫的许多重要行为中起着关键作用,比如,飞行速度控制、高度控制、深度测量、飞行距离测量等,为实现光流控制式的昆虫机器人提供了理论基础。
昆虫视觉和电生理的研究中用于提供视觉刺激的方式有:打印有条纹的纸张、投影仪、显示器和LED点阵等。目前最常用的视觉刺激器是由LED点阵构成,如申请号为201410422437.4的中国专利申请文献提供了一种熊蜂飞行控制器,不仅要满足熊蜂的复眼特性,而且要能生成可定制的光流刺激。但是如何利用光流刺激,并且在强化学习算法框架下,对熊蜂飞行进行有效控制却未有报道。
技术实现要素:
本发明提供了一种基于虚拟现实和强化学习的熊蜂机器人摆腹控制方法,采用强化学习算法控制熊蜂的腹部摆动从一个初始状态达到一个目标状态,克服现有技术中由于人为调节刺激参数控制不精准,以及需要进行大量生物实验的问题。
一种基于虚拟现实和强化学习的熊蜂机器人摆腹控制方法,包括:
(1)根据设定的熊蜂腹部摆动的目标模式,采用强化学习算法建立Q表,所述Q表记录了每类摆腹模式下每个动作获得的累积折扣奖励值;
(2)监测熊蜂当前时刻的摆腹模式,对照Q表,依据奖励值最大原则,实时做出动作控制熊蜂摆腹;
所述动作为由环绕熊蜂流动的光束形成的不同参数的视觉刺激。
本发明将该昆虫机器人控制问题以强化学习算法来进行建模。虚拟现实系统提供光流信息直接输入到熊蜂的复眼,诱发熊蜂的摆腹行为;高清摄像头实时捕捉熊蜂的腹部运动行为,并通过计算机图像算法获取熊蜂的腹部摆动模式,作为环境状态;算法会改变光流信息的参数,LED屏会改变它的运动参数,再输入给熊蜂,从而形成了一个闭环控制系统。
所述奖励值最大原则即贪心策略。
所述动作由若干个LED显示屏组成的虚拟现实系统产生,所述LED显示屏由基于CAN总线的LED控制系统控制。
具体地,一种基于CAN总线的LED显示屏,用于提供熊蜂的光流信息输入;所述LED显示屏为32×8结构,单片机的32个引脚控制列向LED显示,剩余8个引脚控制横向LED显示。由PC控制端、CAN总线上的主节点和若干包含LED驱动模块的从节点组成。所述PC控制端包括输入单元和第一串口通信服务单元,将包含了图像信息和控制命令的数据包发送给CAN总线的主节点,所述CAN总线上的主节点包括第二串口通信服务单元,接收客户端发送的数据;CAN总线通信服务单元,将接收到的数据编码后,上传到CAN总线;所述的从节点包括第二CAN总线通信服务单元,从CAN总线接收数据,并传输给相应的LED驱动模块。所述LED驱动模块所用单片机型号为MSP430F149,LED驱动模块驱动LED灯,从而到达了显示图像和控制图像运动的功能。
本发明采用记录熊蜂腹部摆动模式来反映熊蜂的飞行行为,大量研究发现,昆虫的腹部在昆虫飞行控制中起着关键的作用,因为腹部的位置决定了翅膀振翅产生的力的方向。
上述的熊蜂摆腹行为的采集和分析,由一个高清的摄像头、粒子滤波算法组成,可以得到熊蜂腹部的偏转角度时序序列。所述高清摄像头型号为ANC HD1080P,采集帧率为30帧/秒;摄像头通过USB线和电脑连接,将图像传输到电脑上,用于后续的行为分析。所述粒子滤波是一种应用广泛的,用于物体跟踪的经典算法,在实验之前,选中某一固定点作为跟踪点,选中图像中一块熊蜂腹部矩形区域作为跟踪目标,该区域的颜色直方图作为特征,用于计算下一帧目标所在位置,由此计算出熊蜂的腹部偏转角度。得到角度后,使用滑动窗口的方法计算熊蜂的摆腹模式。
作为优选,所述摆腹模式由单个滑动窗口内熊蜂腹部偏转角度的最大值、最小值、平均绝对值、波峰波谷数、大于均值点个数以及方差构成的6维向量表征。
作为优选,所述滑动窗口的宽度为200~400ms。更为优选,滑动窗口的宽度为200ms。
本发明采用强化学习算法建立起了熊蜂与视觉刺激器之间的交互机制,强化学习过程是一个不断地和环境交互的过程,通过交互,可以得到一种从环境到动作映射的最优策略。强化学习包括环境,动作和奖励函数三个主要部分。
所述环境部分为熊蜂的腹部摆腹模式,由上述的6维向量来表示;
所述动作是强化学习算法可采取的对外部视觉刺激的参数调控,作为优选,所述Q表包含5~20个动作。所述视觉刺激参数是图像旋转的角速度,具体地,有10个可选的角速度,分别为:[2.05,2.89,3.97,4.88,6.20,7.21,8.72,11.02,14.5,22.16,]rad/s;此外,视觉刺激参数也可以包括图像的亮度、运动方向、宽度等。
所述奖励函数主要由当前熊蜂的摆腹模式和目标摆腹模式之间的欧式距离决定,记目标状态为向量xg,对应离散状态为kg,当前时刻t的熊蜂摆腹模式为xt,对应离散状态为kt,上一时刻熊蜂的摆腹模式记为xt-1,dist1为xt与xg间的距离,dist2为xt-1与xg间的距离,那么奖励函数可以记为:
R=0.2,if(dist1>dist2and kt≠kg);
R=+1,if(dist1>dist2and kt=kg);
R=-1,otherwise。
奖励函数是对强化学习产生某个动作的好坏作一种评价,强化学习的目的是使得累积的奖励最大化。
作为优选,所述Q表的建立方法为:
(1)初始化Q表,学习速率α,折扣因子γ,摆腹模式聚类中心;
(2)获得时刻t熊蜂的摆腹模式xt;
(3)利用序列K-means离散化,调整摆腹模式类中心;
(4)依据epsilon-greedy选取动作at;
(5)执行动作at,获得奖励值rt+1和下一时刻熊蜂的摆腹模式xt+1;
(6)重复步骤(3)和(4),选取动作at+1;
(7)根据如下公式更新Q表;
Q(xt,at)←Q(xt,at)+α[rt+1+γQ(xt+1,at+1)-Q(xt,at)];
(8)再从步骤(2)开始循环执行,直到Q表收敛。
通过强化学习算法与环境的交互,得到一个从可以环境到动作映射的最优策略,即可以根据当前熊蜂的摆腹模式来确定下一次视觉刺激的参数,形成一个闭环的控制系统。在实际的控制过程中,摆腹模式将在强化学习算法控制下快速、精确的趋近于目标状态。
本发明具备的有益效果:
(1)本发明针对熊蜂的视觉通路,采用光流刺激,排除了因为采用植入式方式导致的对熊蜂本身的伤害。
(2)采用强化学习算法建立起了熊蜂摆腹行为与视觉刺激器之间的交互机制,不需要进行大量的生物实验来得到刺激-行为响应之间的关系。
(3)本发明视觉刺激诱导熊蜂的运动行为,并以强化学习算法作为控制算法,有效地形成了一个闭环的控制系统,能够精确的控制熊蜂的腹部摆动行为。
附图说明
图1为发明的基于虚拟现实和强化学习的熊蜂机器人闭环控制系统控制流程图。
图2为发明的基于虚拟现实和强化学习的熊蜂机器人闭环控制系统部分结构示意图。
图3为基于CAN总线的LED显示屏模块示意图。
图4为熊蜂的行为采集和分析过程及结果示意图。
图5为强化学习算法交互过程示意图。
图6为基于滑动窗口来提取熊蜂腹部摆动特征的过程。
图7为强化学习算法的学习过程。
图8为一只熊蜂分别在强化学习算法和随机策略控制下维度SSC的控制曲线。
图9为一只熊蜂分别在强化学习算法和随机策略控制下维度SSC和目标维度SSC的偏差曲线。
图10为算法学习到的Q表分布图。
具体实施方式
下面结合实施例对本发明作进一步说明。
实施例1
如图1所示,其中图1(A)是本发明的基于虚拟现实和强化学习算法的熊蜂机器人闭环控制系统的控制回路,控制回路是,首先熊蜂的复眼接收到了外部的光流刺激,然后产生了腹部摆动相应;为了捕捉熊蜂的腹部摆动行为,本发明使用粒子滤波算法跟踪熊蜂的腹部尖端,并计算了其摆动角度,然后根据滑动窗口来进行特征提取;提取到的熊蜂腹部摆动特征,作为强化学习算法的环境状态,算法则会选取下一个时刻的刺激参数,由此形成了闭环的学习过程。图1(B)则是本发明的基于虚拟现实和强化学习算法的熊蜂机器人闭环控制系统的物理组成,对应图1(A),系统包括一个基于CAN总线的LED显示屏,用来提供光流刺激;一个用于采集熊蜂摆腹行为的高清摄像头和一台用于对图像进行分析和处理,并且运行着强化学习算法的电脑。
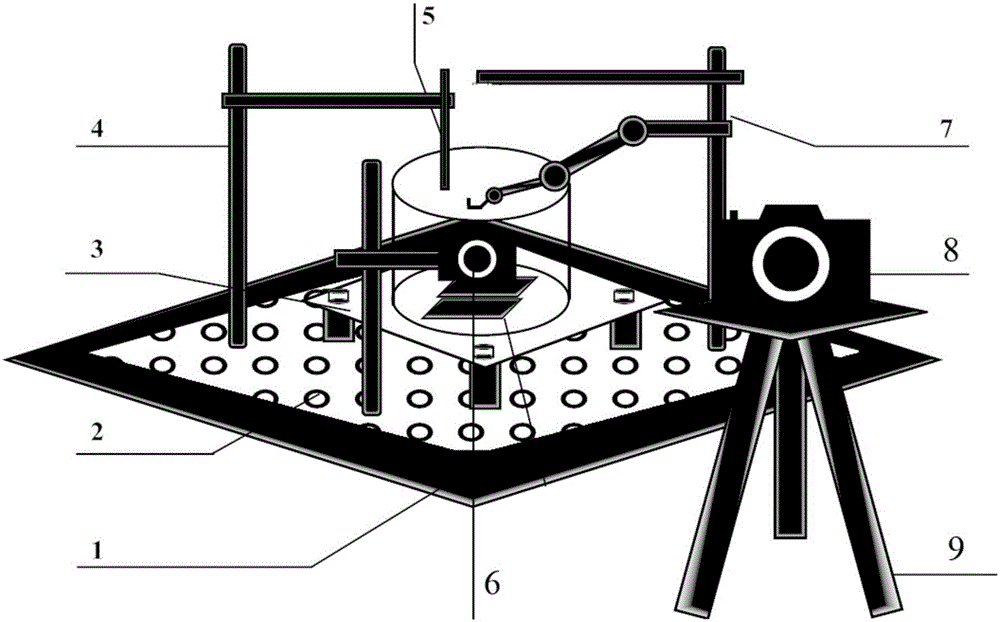
如图2所示,一种基于光流刺激和强化学习的熊蜂机器人控制方法实验平台,包括了防震台1、2,放置在防震台上的LED显示屏3,LED屏用来产生特定的视觉刺激,用于固定微操固定支架的支柱4,用于调整熊蜂固定位置的微操固定支架5,用于拍摄熊蜂腹部摆动行为的高清摄像头6,万向支架7,用于后续系统的扩展,此外,设计中还包括了高速摄像头8以及用于固定高速摄像头的支架9。整个系统除了PC以外均放在防震台上,防止桌面抖动带了的对实验的影响。
如图3所示,一种基于CAN总线的LED显示屏,用于提供熊蜂的光流信息输入;所述LED显示屏为32×8结构,单片机的32个引脚控制列向LED显示,剩余8个引脚控制横向LED显示。由PC控制端、CAN总线上的主节点和若干包含LED驱动模块的从节点组成。所述PC控制端包括输入单元和第一串口通信服务单元,将包含了图像信息和控制命令的数据包发送给CAN总线的主节点,所述CAN总线上的主节点包括第二串口通信服务单元,接收客户端发送的数据;CAN总线通信服务单元,将接收到的数据编码后,上传到CAN总线;所述的从节点包括第二CAN总线通信服务单元,从CAN总线接收数据,并传输给相应的LED驱动模块。所述LED驱动模块所用单片机型号为MSP430F149,LED驱动模块驱动LED灯,从而到达了显示图像和控制图像运动的功能。
本发明中使用单一的亮条纹作为熊蜂机器人的视觉信息输入,由此来诱导熊蜂运动行为。
如图4所示,为本发明中熊蜂飞行行为的采集和数据分析示意图,熊蜂的腹部摆动行为通过背面的高清摄像头捕获,摄像头的型号是ANC HD1080P,熊蜂的摆腹频率最高位7Hz左右,因此设置摄像头的帧率为30帧/秒。图中(x0,y0)是熊蜂被固定的点,熊蜂被固定在一根弯曲细铁棒上,铁棒的弯曲角度为45度,直径为1mm,固定点为熊蜂背部。由操作人员选取需要跟踪的腹部位置区域,记区域的中心为(x,y),根据公式可以得到熊蜂摆腹角度β=arctan[(x-x0)/(y-y0)]。
如图5所示,为本发明中的强化学习算法的交互过程,通常,强化学习维护了一个从环境到动作映射的动作值函数Q(xt,at),表示在状态xt下,采取动作at能够获得的累积奖励,每一次,在得到这个值函数后,通常选择对应状态xt下,能够获得最大值的动作at。这个值函数的更新是通过强化学习不断地和环境交互得到的。
t时刻时,熊蜂的摆腹模式为xt,并根据序列K-means算法进行状态离散化,随后选择一个动作at,即调整了当前的光流刺激参数,同时,熊蜂的复眼接受到光流刺激以后,会产生对应的腹部摆动行为,熊蜂的摆腹行为参数为由粒子滤波算法得到的偏转角度,且如图6所示,这里我们设置了一个大小为200ms的滑动窗口,取其中所有的偏转角度数据,计算了包括最大值、最小值、平均绝对值、波峰波谷数,大于均值点个数以及方差这6个特征作为熊蜂的摆腹模式,这个6维特征即图中所示的状态xt+1,同时,通过计算奖励函数,可以得到当前得到的即时奖rt+1,强化学习算法的更新公式为:
Q(xt,at)←Q(xt,at)+α[rt+1+γQ(xt+1,at+1)-Q(xt,at)]。
其中为α是算法的学习速率,γ为折扣因子。具体算法流程如图7所示。
所述奖励函数主要由当前熊蜂的摆腹模式和目标摆腹模式之间的欧式距离决定,记目标状态为向量xg,对应离散状态为kg,当前时刻t的熊蜂摆腹模式为xt,对应离散状态为kt,上一时刻熊蜂的摆腹模式记为xt-1,dist1为xt与xg间的距离,dist2为xt-1与xg间的距离,那么奖励函数可以记为:
R=0.2,if(dist1>dist2and kt≠kg);
R=+1,if(dist1>dist2and kt=kg);
R=-1,otherwise。
应用强化学习算法,无需事先知道光流刺激参数与熊蜂摆腹模式之间的对应关系,通过不断的交互学习,强化学习算法可以学习到这种从环境状态(熊蜂摆腹模式)到动作(光流刺激参数)的映射关系,并作为后续的闭环实时控制策略,避免了人为地大量实验并进行数据分析的过程。
为了验证基于强化学习算法的控制机制的有效性,我们还和普通的随机算法进行了比较,图8-10是我们采集到的熊蜂的数据以及其算法控制实验结果,图8和9是熊蜂的控制曲线图,体现的是当前状态的维度SSC向目标状态xg的维度SSC趋近的情况(SSC是指滑动窗口内波峰波谷的个数,反应了腹部运动的频率信息,是描述熊蜂腹部摆动最主要的特征)。
其中带三角形的线是目标的SSC值,带圆形的线是在强化学习算法控制下的变化曲线,带×的线则是随机算法控制的变化曲线,可以看出:
1、强化学习算法的控制结果使得SSC每一步都越来越趋近于目标状态,每一步状态和目标状态的偏差(对应的是图10的欧氏距离)是单调递减的,最终偏差趋于0。但是随机算法的控制曲线在控制过程中是随机的,偏差也是随机的,并没有明确的控制趋势。
2、在强化学习算法的控制下,熊蜂在最多8步以内,均已趋于目标值,且最终保持了稳定,然而随机算法并没有使得控制的过程趋于目标值,靠近目标值的状态没有规律性。
3.强化学习算法控制下的曲线较光滑,随机算法控制的曲线抖动非常大。
从以上的结果和分析来看,基于强化学习算法,我们可以很好的用光流刺激来控制熊蜂的腹部摆动,为后续的光流式熊蜂机器人打下了良好的基础。
- 还没有人留言评论。精彩留言会获得点赞!