机器学习装置、数值控制装置、数值控制系统以及机器学习方法与流程
本发明涉及机器学习装置、数值控制装置、数值控制系统以及机器学习方法。
背景技术:
螺纹孔加工之一是螺纹铣削加工。螺纹铣削加工是如下的加工:通过钻头在工件钻出底孔后,不使用丝锥而是使用称为螺纹铣刀的工具,通过螺旋插补进行底孔的侧面加工来切削出螺纹。
使用螺纹铣刀的加工与使用丝锥的加工相比具有以下的特征。
(1)使用螺纹铣刀的加工是使用直径小于内螺纹内径的工具进行的加工,因此难以咬住切屑,结果很少在加工中突然折断。
(2)使用螺纹铣刀的加工不需要像丝锥那样使旋转与刀片进给同步,能够自由地调整转速与刀片进给。
另一方面,在专利文献1以及2中公开了使机械加工的加工精度提高的技术。
专利文献1公开了一种技术,即为加工并测量第一个工件并进行评价,使用评价的结果来修正加工程序的路径,由此来提高第二个以及之后的工件的加工精度。另外,专利文献2公开了一种技术:即为根据电动机的负载、温度以及振动来学习是否在机械中发生了异常,调整进给速度、主轴的转速等加工条件,由此来提高加工精度。
在使用螺纹铣刀的加工中,在考虑了工具以及工件的基材的基础上,为了一边维持螺纹的精度一边实现最短的加工时间,需要针对工具的旋转以及工具或工件的移动调整合适的加工条件。因此,使用螺纹铣刀的加工存在需要花费时间进行调整的问题。
另外,并不限定于螺纹铣削加工,内径加工、外形加工、以及表面加工也同样地为了一边维持加工精度一边实现最快的加工时间,需要针对工具的旋转以及工具或工件的移动调整合适的加工条件。
专利文献1:日本特开平08-185211号公报
专利文献2:日本特许第6063016号说明书
技术实现要素:
本发明的目的在于提供一种机器学习装置、数值控制装置、数值控制系统、以及机器学习方法,其通过机器学习来求出合适的加工条件,由此能够一边维持加工精度一边缩短加工时间。
(1)本发明的机器学习装置是针对数值控制装置(例如,后述的数值控制装置200)进行机器学习的机器学习装置(例如,后述的机器学习装置300),所述数值控制装置根据加工程序使机床(例如,后述的机床100)进行动作,
所述机器学习装置具备:
状态信息取得部(例如,后述的状态信息取得部301),其取得包含设定值、对工件进行切削加工的周期时间以及该工件的加工精度的状态信息,所述设定值包含主轴转速、进给速度、切入次数以及每一次的切入量或工具校正量;
行为信息输出部(例如,后述的行为信息输出部303),其向所述数值控制装置输出包含在所述状态信息中包含的所述设定值的修正信息的行为信息;
回报输出部(例如,后述的回报输出部3021),其输出基于所述状态信息中包含的所述周期时间和所述加工精度的强化学习中的回报值;以及
价值函数更新部(例如,后述的价值函数更新部3022),其根据通过所述回报输出部输出的回报值、所述状态信息以及所述行为信息来更新行为价值函数,
在预定的加工程序中设定所述主轴转速、所述进给速度、所述切入次数以及所述每一次的切入量或所述工具校正量,
所述数值控制装置通过执行所述加工程序使所述机床进行切削加工,
通过由所述数值控制装置执行所述加工程序来取得所述周期时间以及所述加工精度。
(2)在上述(1)的机器学习装置中,可以不设置所述机器学习的最大试验次数而持续进行所述机器学习。
(3)在上述(1)或(2)的机器学习装置中,可以在所述机床的螺纹铣削加工、内径加工、外形加工、表面加工中的任意一个加工中进行所述机器学习。
(4)在上述(1)~(3)中的任意一项的机器学习装置中,所述机器学习装置还可以具备最优化行为信息输出部,该最优化行为信息输出部根据通过所述价值函数更新部更新后的价值函数,生成所述主轴转速、所述进给速度、所述切入次数以及所述每一次的切入量或所述工具校正量并进行输出。
(5)本发明的数值控制系统具备:上述(1)~(4)中的任意一项的机器学习装置;以及通过该机器学习装置对加工程序主轴转速、进给速度、切入次数以及每一次的切入量或工具校正量进行机器学习的数值控制装置。
(6)本发明所涉及的数值控制装置包含上述(1)~(4)中任一项的机器学习装置,并通过该机器学习装置,对加工程序主轴转速、进给速度、切入次数、以及每一次的切入量或工具校正量进行机器学习。
(7)本发明的机器学习方法是针对数值控制装置(例如,后述的数值控制装置200)进行机器学习的机器学习装置(例如,后述的机器学习装置300)的机器学习方法,所述数值控制装置根据加工程序使机床(例如,后述的机床100)进行动作,所述机器学习方法包含以下步骤:
取得包含设定值、对工件进行切削加工的周期时间以及该工件的加工精度的状态信息,所述设定值包含主轴转速、进给速度、切入次数以及每一次的切入量或工具校正量;
向所述数值控制装置输出包含在所述状态信息中包含的所述设定值的修正信息的行为信息;
计算基于所述状态信息中包含的所述周期时间和所述加工精度的强化学习中的回报值;以及
根据计算出的回报值、所述状态信息以及所述行为信息来更新行为价值函数,
在预定的加工程序中设定所述主轴转速、所述进给速度、所述切入次数以及所述每一次的切入量或所述工具校正量,
所述数值控制装置通过执行所述加工程序使所述机床进行切削加工,
通过由所述数值控制装置执行所述加工程序来取得所述周期时间以及所述加工精度。
根据本发明,通过机器学习求出合适的加工条件,由此能够一边维持加工精度一边缩短加工时间。
另外,根据状况求出合适的加工条件,由此即使对于长时间使用的工具也可维持加工精度,因此能够延长工具寿命。
附图说明
图1是螺纹铣削加工的说明图。
图2是表示本发明的第1实施方式的数值控制系统与机床的框图。
图3是表示本发明的第1实施方式的数值控制系统的数值控制装置以及机床的结构的框图。
图4是表示机器学习装置的结构的框图。
图5是表示本发明的第1实施方式中的q学习时的机器学习装置的动作的流程图。
图6是表示图5的步骤s15的基于周期时间来计算回报的计算方法的流程图。
图7是表示图5的步骤s15的基于加工精度来计算回报的计算方法的流程图。
图8是表示由最优化行为信息输出部生成最优化行为信息时的动作的流程图。
图9是外形加工的说明图。
图10是表示本发明的第1实施方式中的q学习时的机器学习装置的动作中的基于表面精度来计算回报的计算方法的流程图。
图11是表面加工的说明图。
具体实施方式
以下,使用附图针对本发明的实施方式进行详细地说明。
(第1实施方式)
本实施方式的数值控制系统具备数值控制装置和机器学习装置,适用于通过机床进行螺纹铣削加工的情况。以螺纹铣削加工为例说明本实施方式,但是并不限于螺纹铣削加工。
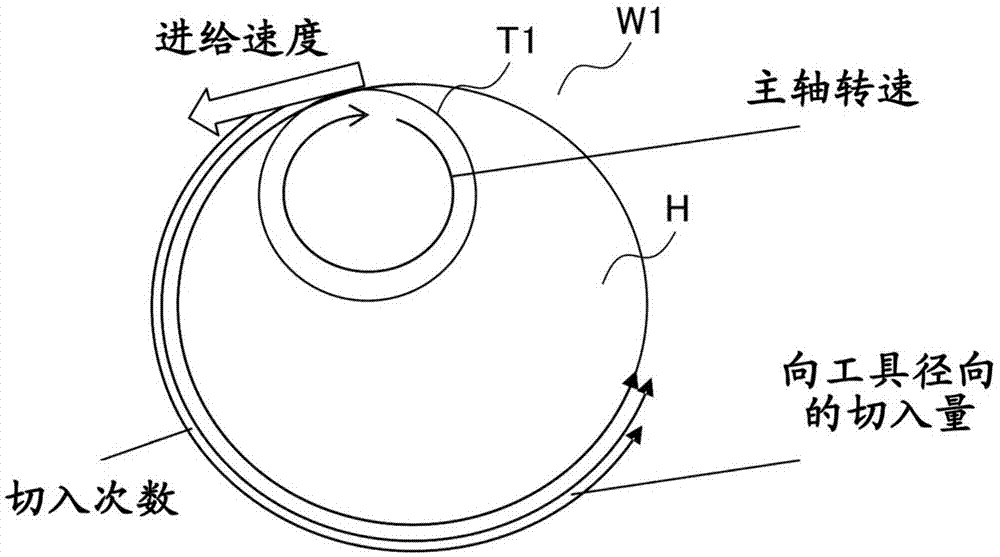
如图1所示,使用螺纹铣刀的加工是通过钻头在工件w1钻出底孔h后,使用螺纹铣刀t1,通过螺旋插补进行底孔h的侧面加工,来切削出螺纹的加工。在使用螺纹铣刀的加工中,在考虑了工具以及工件的基材的基础上,为了一边维持螺纹的精度一边得到更短的加工时间,如图1所示,需要调整用于使作为工具的螺纹铣刀t1旋转的主轴的主轴转速、进给速度、向工具径向的切入次数以及向工具径向的一次的切入量。主轴的主轴转速、进给速度、向工具径向的切入次数以及向工具径向的一次的切入量根据工件的加工形状、工件的材质、工具的外形(直径、刀片数量等)以及工具的材质等条件而变化。
图2是表示本发明的第1实施方式的数值控制系统与机床的框图。如图2所示,数值控制系统10具备n台数值控制装置200-1~200-n、网络400、经由网络400与数值控制装置200-1~200-n相连接的机器学习装置300-1~300-n。n台机床100-1~100-n与n台数值控制装置200-1~200-n连接。此外,n是任意的自然数。
将机床100-1与数值控制装置200-1设为1对1的组,并可通信地连接。对于机床100-2~100-n与数值控制装置200-2~200-n,也与机床100-1和数值控制装置200-1同样地进行连接。机床100-1~100-n与数值控制装置200-1~200-n的n个组可以经由连接接口直接连接,或经由lan(localareanetwork:局域网)等网络来连接。关于机床100-1~100-n与数值控制装置200-1~200-n的n个组,例如可以在相同的工厂中设置多组,也可以分别设置在不同的工厂中。
另外,将数值控制装置200-1与机器学习装置300-1设为1对1的组,并可通信地连接。对于数值控制装置200-2~200-n与机器学习装置300-2~300-n,也与数值控制装置200-1和机器学习装置300-1同样地进行连接。在图1中,数值控制装置200-1~200-n与机器学习装置300-1~300-n的n个组经由网络400连接,但是数值控制装置200-1~200-n与机器学习装置300-1~300-n的n个组可以经由连接接口将各个组的数值控制装置与机器学习装置直接连接。此外,网络400例如是在工厂内构建的lan(localareanetwork:局域网)、因特网、公共电话网络或它们的组合。对于网络400中的具体的通信方式、以及是有线连接还是无线连接等,并没有特别的限定。
接下来,针对机床100-1~100-n与数值控制系统10中包含的数值控制装置200-1~200-n以及机器学习装置300-1~300-n的结构进行说明。
图3是表示本发明的第1实施方式的数值控制系统10的数值控制装置200以及机床100的结构的框图。图4是表示机器学习装置300的结构的框图。图3的机床100、图3的数值控制装置200以及图4所示的机器学习装置300例如分别对应于图2所示的机床100-1、数值控制装置200-1以及机器学习装置300-1。机床100-2~100-n、数值控制装置200-2~200-n以及机器学习装置300-2~300-n也具有相同的结构。
首先针对机床100进行说明。
机床100按照根据在数值控制装置200中设定的加工程序而生成的指令来进行螺纹铣削加工。
机床具备主轴电动机101、进给轴伺服电动机102、周期计数器103。
主轴电动机101是用于使螺纹铣刀旋转的主轴电动机。在主轴电动机101的旋转轴安装螺纹铣刀。
进给轴伺服电动机102是使螺纹铣刀相对于工件的底孔螺旋状地移动的伺服电动机。图3所示的进给轴伺服电动机102由针对x轴方向、y轴方向以及z轴方向设置的3个进给轴伺服电动机组成。使x轴方向、y轴方向以及z轴方向的进给轴伺服电动机102的旋转轴旋转,由此通过与进给轴伺服电动机102相连接的滚珠丝杠等使螺纹铣刀螺旋状地移动。在此,进给轴伺服电动机102螺旋状地驱动螺纹铣刀,但是也可以设为针对x轴方向以及y轴方向设置的进给轴伺服电动机使放置了工件的工件台在x轴方向以及y轴方向移动,另一方面,针对z轴方向设置的进给轴伺服电动机可以使螺纹铣刀在z轴方向上移动,从而使螺纹铣刀对于工件相对螺旋状地进行移动。
周期计数器103是在机床100进行螺纹铣削加工时,用于测量该螺纹铣削加工所要的加工时间即周期时间的计数器。将周期计数器103测量出的周期时间输出给数值控制装置200。
数值控制装置200是通过控制机床100,使机床100进行螺纹铣削加工的装置。另外,数值控制装置200向机器学习装置300发送状态信息(也称为“状态”)。数值控制装置200还从机器学习装置300接收行为信息(也称为“动作”)。针对这些各信息的细节,在机器学习装置300的说明中进行详细描述。
数值控制装置200具备主轴电动机控制部201、进给轴伺服电动机控制部202、数值控制信息处理部203、存储部204以及程序修正部205。
主轴电动机控制部201根据来自数值控制信息处理部203的动作指令生成转矩指令,并将生成的转矩指令发送给机床100,由此来控制机床100的主轴电动机101的旋转。另外,进给轴伺服电动机控制部202根据来自数值控制信息处理部203的位置指令来生成转矩指令,并将生成的转矩指令发送给机床100,由此来控制机床100的x轴方向、y轴方向以及z轴方向的进给轴伺服电动机102的旋转。进给轴伺服电动机控制部202由3个进给轴伺服电动机控制部组成,其用于控制针对x轴方向、y轴方向以及z轴方向设置的3个进给轴伺服电动机。
数值控制信息处理部203根据在存储部204中存储的加工程序,向主轴电动机控制部201发送动作指令,向进给轴伺服电动机控制部202发送位置指令。另外,数值控制信息处理部203取得从机床100的周期计数器103输出的周期时间以及进行了螺纹铣削加工的工件的加工精度,并作为状态信息发送至机器学习装置300。使用3维测量器等来测量工件的加工精度,并输入至数值控制信息处理部203。机床100可以具有工件的加工精度的测量功能。
在工件作出的螺纹的加工精度包含加工精度是否在适当范围内的判断结果。能够使用3维测量器等来判断加工精度是否在适当范围内,但是例如也能够由观测者或机器人尝试判断螺纹规的通端是否穿过通过螺纹铣削加工而加工出的螺纹孔,止端是否未进入螺纹孔超过旋转2周。如果由于螺纹孔小而在适当范围外,则判断为切削不足,如果螺纹孔大而在适当范围外,则判断为切削过量。另外,当加工精度在适当范围内时,进一步关于在工件作出的螺纹的加工精度,例如内螺纹的公差带等级(tolerancerangeclass)包含jisb0209-1:2001(对应于“iso965-1:1998”)的表8中记载的根据公差品质(tolerancequality)“精细”、“中等”、“粗糙”进行评价而得到的评价结果。使用3维测量器等来测量公差品质。公差品质按照“精细”、“中等”、“粗糙”的顺序具有高加工精度。
另外,数值控制信息处理部203将在加工程序中设定的主轴转速、进给速度、切入次数以及一次的切入量作为状态信息发送至机器学习装置300。
程序修正部205直接修正加工程序。具体而言,程序修正部205根据从机器学习装置300输出的行为信息以及最优化行为信息,修正在加工程序中记录的主轴转速、进给速度、切入次数以及一次的切入量的程序代码。
以上,针对机床100以及数值控制装置200的结构进行了说明,上述结构是与本实施方式的动作特别相关的部分。机床100以及数值控制装置200的各结构的细节,例如用于向进给轴伺服电动机控制部进行位置速度反馈的位置速度检测器、对动作指令进行放大的电动机驱动放大器、以及用于接受用户的操作的操作面板等是本领域技术人员已知的,因此省略详细的说明以及图示。
<机器学习装置300>
机器学习装置300是针对由数值控制装置200执行加工程序来使机床100进行动作时的主轴转速、进给速度、切入次数以及一次的切入量进行强化学习的装置。
在说明机器学习装置300中包含的各功能块之前,首先针对强化学习的基本的机制进行说明。智能体(相当于本实施方式中的机器学习装置300)观察环境的状态,选择某个行为。于是,根据该行为使得环境变化。伴随着环境的变化,给予一些回报,智能体学习选择更好的行为(决策)。
相对于有监督学习表示完全正确的解,强化学习中的回报大多是基于环境的部分的变化的碎片化的值。因此,智能体学习选择行为,使得将来的回报的总和最大。
如此,在强化学习中,机器学习装置300通过学习行为,考虑行为带给环境的相互作用来学习合适的行为,即学习用于使将来得到的回报最大的行为。这在本实施方式中表现为获得影响未来的行为,例如选择一边维持加工精度一边缩短周期时间的行为信息。
在这里,作为强化学习能够使用任意的学习方法,但是在以下的说明中,以使用q学习(q-learning)的情况为例进行说明,q学习是在某个环境的状态s下,对于选择行为a的价值函数q(s,a)进行学习的方法。
q学习的目的在于,在某个状态s时,从可取得的行为a中选择价值函数q(s,a)最高的行为a来作为最佳的行为。
然而,在最初开始q学习的时间点,对于状态s与行为a的组合,完全不知道价值函数q(s,a)的正确值。因此,智能体在某个状态s下选择各种各样的行为a,根据针对此时的行为a赋予的回报来选择更好的行为,由此学习正确的价值函数q(s,a)。
另外,因为想要使将来得到的回报的总和最大,所以以最终成为q(s,a)=e[σ(γt)rt]为目标。在这里,e[]表示期待值,t是时刻,γ是后述的被称为折扣率的参数,rt是时刻t的回报、σ是时刻t的总和。该式子中的期待值是按照最佳的行为而使状态发生了变化时的期待值。但是,在q学习的过程中,不知道最佳的行为是什么,因此通过进行各种各样的行为,一边探索一边进行强化学习。关于这样的价值函数q(s,a)的更新式,例如能够通过以下的数学式1(以下表示为式1)表示。
【式1】
在上述的式1中,st表示时刻t的环境的状态,at表示时刻t的行为。通过行为at,状态变化为st+1。rt+1表示通过该状态的变化而得到的回报。另外,带有max的项是在状态st+1下,选择了当时所知道的q值最高的行为a时的q值乘以γ的项。在这里,γ是0<γ≤1的参数,被称为折扣率。另外,α是学习系数,设为0<α≤1的范围。
上述式1表示根据作为行为at的结果而返回的回报rt+1,来对状态st下的行为at的价值函数q(st,at)进行更新的方法。
该更新式表示如果基于行为at的下一个状态st+1下的最佳的行为的价值maxaq(st+1,a)大于状态st下的行为at的价值函数q(st,at),则增大q(st,at),反之,如果小于,则减小q(st,at)。也就是说,更新式表示使某个状态下的某个行为的价值接近基于该行为的下一个状态下的最佳的行为的价值。但是,行为的价值的差根据折扣率γ与回报rt+1的方式而变化,基本上,某个状态下的最佳的行为的价值传播至该状态的前一个状态下的行为的价值。
在此,在q学习中,具有生成与全部的状态行为对(s,a)有关的价值函数q(s,a)的表来进行学习的方法。但是,该方法存在为了求出全部的状态行为对的q(s,a)的值,状态数过多,q学习收敛需要较多时间的情况。
因此,在q学习中可以使用公知的被称为dqn(deepq-network)的技术。具体而言,dqn可以使用适当的神经网络来构成价值函数q,并调整神经网络的参数,由此通过适当的神经网络来近似价值函数q从而计算价值函数q(s,a)的值。通过使用dqn,q学习收敛所需要的时间变短。此外,关于dqn,例如在以下的非专利文献中有详细的记载。
<非专利文献>
“human-levelcontrolthroughdeepreinforcementlearning”、volodymyrmnih1著[online]、[平成29年1月17日检索]、因特网〈url:http://files.davidqiu.com/research/nature14236.pdf〉
机器学习装置300进行以上说明的q学习。具体而言,机器学习装置300将数值控制装置200的加工程序的主轴转速、进给速度、切入次数以及一次的切入量、周期时间以及工件的加工精度作为状态s,针对选择该状态s下的主轴转速、进给速度、切入次数以及一次的切入量的调整来作为行为a的价值函数q进行学习。
机器学习装置300观测状态信息s来决定行为a,该状态信息s包含:加工程序的主轴转速、进给速度、切入次数以及一次的切入量;以及通过执行加工程序而得到的周期时间和工件的加工精度。机器学习装置300在每一次进行行为a时给予回报。机器学习装置300例如反复试验地搜索最佳的行为a,使得将来的回报的总和为最大。由此,机器学习装置300能够针对包含通过执行加工程序而取得的周期时间以及工件的加工精度的状态s,选择最佳的行为a(即,最佳的主轴转速、进给速度、切入次数以及一次的切入量)。
即,机器学习装置300根据学习的价值函数q,选择涉及某个状态s的对于加工程序的主轴转速、进给速度、切入次数以及一次的切入量采用的行为a中的价值函数q的值为最大的行为a,由此来选择周期时间更短,工件的加工精度更高的行为a(即、加工程序的主轴转速、进给速度、切入次数以及一次的切入量)。
图4是表示本发明的第1实施方式的机器学习装置300的框图。
为了进行上述强化学习,如图4所示,机器学习装置300具备状态信息取得部301、学习部302、行为信息输出部303、价值函数存储部304、最优化行为信息输出部305以及控制部306。学习部302具备回报输出部3021、价值函数更新部3022以及行为信息生成部3023。控制部306控制状态信息取得部301、学习部302、行为信息输出部303以及最优化行为信息输出部305的动作。
状态信息取得部301从数值控制装置200取得状态s,该状态s包含:加工程序的主轴转速、进给速度、切入次数以及一次的切入量;以及通过执行加工程序而得到的周期时间和工件的加工精度。该状态信息s相当于q学习中的环境状态s。
状态信息取得部301向学习部302输出所取得的状态信息s。
此外,由用户预先设定在最初开始q学习的时间点的加工程序的主轴转速、进给速度、切入次数以及一次的切入量。主轴的主轴转速、进给速度、向工具径向的切入次数以及向工具径向的一次的切入量根据工件的加工形状、工件的材质、工具的外形(直径、刀片数量等)以及工具的材质等条件而变化,因此由用户根据这些条件来进行设定。在本实施方式中,机器学习装置300通过强化学习将用户设定的主轴转速、进给速度、切入次数以及一次的切入量调整为最佳。
学习部302是对于在某个状态信息(环境状态)s下选择某个行为a时的价值函数q(s,a)进行学习的部分。具体而言,学习部202具备回报输出部3021、价值函数更新部3022以及行为信息生成部3023。
回报输出部3021是计算在某个状态s下选择了行为a时的回报的部分。回报输出部3021可以根据多个评价项目来计算回报。另外,回报输出部3021可以通过对根据多个评价项目而计算出的回报进行加权来计算整体的回报。在本实施方式中,回报输出部3021根据周期时间以及加工精度来计算回报。
首先,对基于周期时间计算回报进行说明。
在由于行为a使得状态s迁移到状态s′的情况下,将根据状态s以及状态s′下的加工程序的主轴转速、进给速度、切入次数以及一次的切入量进行动作的机床100的周期时间的值设为值t(s)以及值t(s′)。
回报输出部3021如下那样基于周期时间来计算回报。
当值t(s′)>值t(s)时,使回报为负值。
当值t(s′)=值t(s)时,使回报为零。
当值t(s′)<值t(s)时,使回报为正值。
例如,能够使基于周期时间而得到的回报的值在周期时间值变长时为-5,在周期时间值不变时为+5,在周期时间值变短时为+10。
此外,回报输出部3021可以在值t(s′)=值t(s)时使回报为正值,在值t(s′)<值t(s)时,使此时的回报为比值t(s′)=值t(s)时的回报大的正值。
另外,关于执行行为a之后的状态s′的周期时间比前一个状态s下的周期时间长时(值t(s′)>值t(s))的负值,可以根据比例使负值变大。也就是说,可以根据周期时间变长的程度使负值变大。相反地,关于执行行为a之后的状态s′的周期时间比前一个状态s下的周期时间短时(值t(s′)<值t(s))的正值,可以根据比例使正值变大。也就是说,可以根据周期时间变短的程度使正值变大。
接下来,对基于加工精度计算回报进行说明。
在由于行为a从状态s迁移到状态s′时,回报输出部3021根据工件的加工精度来决定回报,该工件的加工精度是根据状态s′下的加工程序的主轴转速、进给速度、切入次数以及一次的切入量来进行动作的机床10所制造出的工件的加工精度。
回报输出部3021根据在工件的加工精度中包含的加工精度是否在适当范围内的判断结果,当加工精度在适当范围外时使回报为负值。适当范围外是切削不足或切削过量的情况。希望将工件中作出的螺纹的加工精度在适当范围外时的回报的负值的绝对值设为整体的回报成为数字较大的负值那样的值,从而不会选择加工精度在适当范围外的情况。这是因为关于加工精度在适当范围外的情况,当切削过量时无法再加工,当切削不足时需要再次进行切削,因此作为切削加工并不是优选的状态。当切削过量时无法再加工,因此能够使切削过量时的回报成为比切削不足时的回报更大数字的负值那样的值。例如,能够设为切削过量时的回报为-50,切削不足的回报为-10。
当加工精度在适当范围内时,回报输出部3021根据工件的加工精度的内螺纹的公差带等级的公差品质相当于“精细”、“中等”、“粗糙”中的哪一个这样的评价结果,例如能够如下那样计算回报。
当公差品质为“粗糙”时,使回报为正的第1值。
当公差品质为“中等”时,使回报为比正的第1值大的正的第2值。
当公差品质为“精细”时,使回报为比正的第2值大的正的第3值。
此外,回报的值的给予方式并不限于此,可以与“精细”、“中等”、“粗糙”无关而设为相同的正值。例如,能够将“精细”、“中等”、“粗糙”时的回报设为相同的+10。另外,可以将“粗糙”时的回报设为零,将“中等”以及“精细”时的回报设为相同的正值。
回报输出部3021根据如上所述计算出的基于周期时间的回报以及基于加工精度的回报来计算整体的回报。回报输出部3021在计算整体的回报时,并不限于相加,例如可以进行加权。另外,可以计算基于周期时间的回报与基于加工精度的回报的平均值。能够根据周期时间与加工精度的优先度来适当设定计算整体的回报的方法。例如,在重视周期时间时,回报输出部3021能够针对基于周期时间的回报乘以超过1的权重系数来与基于加工精度的回报进行相加从而进行加权加法运算。
价值函数更新部3022根据状态s、行为a、将行为a应用于状态s时的状态s′以及如上所述计算出的整体的回报的值来进行q学习,由此来更新价值函数存储部304所存储的价值函数q。
价值函数q的更新可以通过在线学习来进行,也可以通过批量学习来进行,还可以通过小批量学习来进行。
在线学习是通过将某个行为a用于当前的状态s,从而在每次状态s迁移至新的状态s′时,立即进行价值函数q的更新的学习方法。另外,批量学习是通过重复进行将某个行为a用于当前的状态s,从而使状态s迁移至新的状态s′的处理,来收集学习用数据,使用收集到的全部的学习用数据来进行价值函数q的更新的学习方法。并且,小批量学习是在线学习与批量学习之间的在每次积累了某种程度的学习用数据时进行价值函数q的更新的学习方法。
行为信息生成部3023针对当前的状态s选择q学习的过程中的行为a。行为信息生成部3023在q学习的过程中,为了进行用于对数值控制装置200的加工程序的主轴转速、进给速度、切入次数以及一次的切入量进行修正的动作(相当于q学习中的行为a),生成行为信息a,并将生成的行为信息a输出给行为信息输出部303。
更具体而言,行为信息生成部3023例如针对在状态s中包含的加工程序的主轴转速、进给速度、切入次数以及一次的切入量,通过行为a对加工程序的主轴转速、进给速度、切入次数以及一次的切入量进行调整从而使其增加或减小。
行为信息生成部3023通过行为a来调整加工程序的主轴转速、进给速度、切入次数以及一次的切入量,在迁移到状态s′时,可以根据周期时间的状态(增减或维持)以及加工精度的状态(是否在适当范围内以及公差品质为“精细”、“中等”、“粗糙”中的哪一个)来选择下一个行为a′的加工条件(主轴转速、进给速度、切入次数以及一次的切入量)。
例如,在由于周期时间的减少而给予了正的回报(正值的回报),并且由于加工精度在适当范围内且公差品质为“精细”而给予了正的回报(正值的回报)的情况下,作为下一个行为a′,行为信息生成部3023例如可以采取以下措施:选择逐渐增加进给速度,或者逐渐增加切入量并且减少切入次数等,使周期时间变得更短的行为a′。
另外,在迁移到状态s′,由于周期时间的减少而给予正的回报(正值的回报),并且加工精度在适当范围内,公差品质为“粗糙”的情况下,作为下一行为a′,行为信息生成部3023可以采取以下措施:选择逐渐减少切入量并且增加切入次数等提高加工精度的行为a′。
另外,行为信息生成部3023可以采取以下措施:通过在当前推定的行为a的价值中,选择价值函数q(s,a)最高的行为a′的贪婪法、或者以某个小的概率ε来随机选择行为a′,在此之外选择价值函数q(s,a)最高的行为a′的ε贪婪法这样的公知的方法,来选择行为a′。
行为信息输出部303是将从学习部302输出的行为信息a发送给数值控制装置200的部分。行为信息输出部303例如可以生成将主轴转速、进给速度、切入次数以及一次的切入量的值应用于特定的宏变量的宏变量文件来作为作为行为信息,并将生成的宏变量文件经由网络400输出给数值控制装置200的程序修正部205。程序修正部205使用接收到的宏变量文件,将行为信息(主轴转速、进给速度、切入次数以及一次的切入量)反映到在存储部204中存储的加工程序的特定的宏变量的值中。数值控制信息处理部203执行包含了特定的宏变量的加工程序。此外,生成宏变量文件,使用该宏变量文件将行为信息反映到加工程序的特定的宏变量的值中的方法是用于将行为信息反映到加工程序中的方法的一个例子,并不限于此。
价值函数存储部304是存储价值函数q的存储装置。价值函数q例如可以针对每个状态s、每个行为a保存为表(以下,称为行为价值表)。通过价值函数更新部3022来更新在价值函数存储部304中存储的价值函数q。另外,可以与其他的机器学习装置300共享在价值函数存储部304中存储的价值函数q。如果由多个机器学习装置300共享价值函数q,则可以通过各机器学习装置300分散地进行强化学习,因此能够提高强化学习的效率。
最优化行为信息输出部305根据通过价值函数更新部3022进行q学习而更新后的价值函数q,生成用于使机床100进行使价值函数q(s,a)成为最大的动作的行为信息a(以下,称为“最优化行为信息”)。
更具体而言,最优化行为信息输出部305取得价值函数存储部304所存储的价值函数q。如上所述,该价值函数q是通过价值函数更新部3022进行q学习而更新后的函数。然后,最优化行为信息输出部305根据价值函数q,生成行为信息,并将生成的行为信息输出给程序修正部205。该最优化行为信息与行为信息输出部303在q学习的过程中输出的行为信息同样地,包含对加工程序的主轴转速、进给速度、切入次数以及一次的切入量进行修正的信息。
程序修正部205根据该最优化行为信息来修正当前设定的加工程序,并生成动作指令。通过该动作指令,机床100能够以一边提高加工精度一边使加工周期时间更短的方式来进行动作。
以上,针对在数值控制装置200以及机器学习装置300中包含的功能块进行了说明。
为了实现这些功能块,数值控制装置200以及机器学习装置300分别具备cpu(centralprocessingunit:中央处理单元)等运算处理装置。另外,数值控制装置200以及机器学习装置300分别还具备存储了应用程序软件、os(operatingsystem:操作系统)等各种控制用程序的hdd(harddiskdrive:硬盘驱动器)等辅助存储装置、以及在运算处理装置执行程序时用于暂时存储所需要的数据的ram(randomaccessmemory:随机存取存储器)这样的主存储装置。
然后,在各个数值控制装置200以及机器学习装置300中,运算处理装置从辅助存储装置读入应用程序软件或os,并将读入的应用程序软件或os在主存储装置中展开,同时基于这些应用程序软件或os进行运算处理。另外,各个数值控制装置200以及机器学习装置300根据该运算结果,来控制各装置所具备的各种硬件。由此,实现本实施方式的功能块。也就是说,本实施方式的功能块能够通过硬件与软件的协作来实现。
在机器学习装置300中与机器学习相伴的运算量较多,因此优选例如在个人计算机中搭载gpu(graphicsprocessingunits:图形处理单元),通过被称为gpgpu(general-purposecomputingongraphicsprocessingunits:通用图形处理单元)的技术,将gpu用于与机器学习相伴的运算处理。机器学习装置300通过使用gpu能够进行高速处理。并且,为了进行更高速的处理,机器学习装置300使用多台搭载了这样的gpu的计算机来构筑计算机集群,通过在该计算机集群中包含的多个计算机来进行并行处理。
接下来,参照图5、图6以及图7的流程图来对本实施方式的q学习时的机器学习装置300的动作进行说明。图5是表示本实施方式中的q学习时的机器学习装置300的动作的流程图,图6是表示图5的步骤s15的基于周期时间的回报的计算方法的流程图,图7是表示图5的步骤s15的基于加工精度的回报的计算方法的一部分的流程图。
首先,在步骤s11中,控制部306将试验次数设为1来向状态信息取得部301指示取得状态信息。
在步骤s12中,状态信息取得部301从数值控制装置200取得最初的状态信息。将取得的状态信息输出给价值函数更新部3022以及行为信息生成部3023。如上所述,该状态信息是相当于q学习中的状态s的信息,包含在步骤s12时间点的加工程序的主轴转速、进给速度、切入次数以及一次的切入量的值、以及根据被设定为这些值的加工程序进行了加工处理时的周期时间和工件的加工精度。此外,预先由用户生成在最初开始q学习的时间点的加工程序的主轴转速、进给速度、切入次数以及一次的切入量的设定值。在本实施方式中,机器学习装置300将用户生成的加工程序的主轴转速、进给速度、切入次数以及一次的切入量的值通过强化学习调整为最佳的值。
在步骤s13中,行为信息生成部3023生成新的行为信息a,并将生成的新的行为信息a经由行为信息输出部303输出给数值控制装置200的程序修正部205。接收到行为信息的程序修正部205根据接收到的行为信息,对当前的状态s所涉及的加工程序的主轴转速、进给速度、切入次数以及一次的切入量进行修正从而设为状态s′。数值控制信息处理部203根据修正后的状态s′,驱动机床100来进行切削加工。
在步骤s14中,状态信息取得部301取得相当于从数值控制装置200取得的新的状态s′的状态信息。在这里,新的状态信息包含:状态s′所涉及的加工程序的主轴转速、进给速度、切入次数以及一次的切入量的值;用于进行状态s′所涉及的加工处理所需的周期时间;以及通过状态s′所涉及的加工处理制作出的工件的加工精度。用于进行状态s′所涉及的加工处理所需的周期时间以及通过状态s′所涉及的加工处理制作出的工件的加工精度成为判定信息。状态信息取得部301向学习部302输出所取得的状态信息。
在步骤s15中,回报输出部3021根据输入的判定信息,即周期时间以及加工精度来计算回报。步骤s15包含根据周期时间来计算回报的步骤、根据加工精度来计算回报的步骤、根据基于周期时间的回报以及基于加工精度的回报来计算整体的回报的步骤。
图6的步骤s15-1表示根据周期时间来计算回报的步骤。如步骤s15-1所示,回报输出部3021首先在步骤s151中判断用于进行状态s′所涉及的加工处理所需要的周期时间值t(s′)比用于进行状态s所涉及的加工处理所需要的周期时间值t(s)长还是短还是不变。
当周期时间值t(s′)>周期时间值t(s)时,回报输出部3021在步骤s152中使回报为负值。当周期时间值t(s′)=周期时间值t(s)时,回报输出部3021在步骤s153中使回报为零。当周期时间值t(s′)<周期时间值t(s)时,回报输出部3021在步骤s154中使回报为正值。
图7的步骤s15-2表示根据加工精度来计算回报的步骤。回报输出部3021首先在步骤s155中判断在工件中作出的螺纹的加工精度是否在适当范围内。当加工精度在适当范围外时,回报输出部3021使回报为负值。适当范围外包括切削过量与切削不足。在此,在为切削过量导致的适当范围外的情况时,回报输出部3021在步骤s156中使回报为负的第1值,在为切削不足的情况时,在步骤s157中使回报为数字小于负的第1值的负的第2值。将切削过量时的回报设为数字比切削不足时的回报更大的负值的原因在于,切削过量无法再加工,因此比切削不足更加不好。
当加工精度在适当范围内时,回报输出部3021在步骤s158中,判断工件的加工精度的内螺纹的公差带等级的公差品质相当于“精细”、“中等”、“粗糙”中的哪个。如果公差品质是“粗糙”,则回报输出部3021在步骤s159中使回报为正的第1值。如果公差品质是“中等”,则回报输出部3021在步骤s160中使回报为大于正的第1值的正的第2值。如果公差品质是“精细”,则回报输出部3021在步骤s161中使回报为大于正的第2值的正的第3值。如已说明的那样,给出回报的值的方式并不限于此。
图7的步骤s15-3表示根据基于周期时间的回报以及基于加工精度的回报来计算整体的回报的步骤。步骤s15-3是对于基于周期时间的回报以及基于加工精度的回报,例如通过相加、加权相加、求出平均值,来计算整体的回报的步骤。
当步骤s15结束时,在步骤s16中,价值函数更新部3022根据整体的回报的值,更新价值函数存储部304所存储的价值函数q。接下来,在步骤s17中,控制部306判断是否达到最大试验次数。预先设定最大试验次数。如果没有到达最大试验次数,则控制部306在步骤s18中对试验次数进行相加,并返回至步骤s13。重复进行步骤s13到步骤s18的处理,直至达到最大试验次数为止。此外,在这里,当试验次数达到了最大试验次数时处理结束,但是也可以将重复了预定时间进行步骤s13到步骤s18的处理作为条件来使处理结束。
此外,步骤s16例示了在线更新,但是也可以替换为批量更新或小批量更新来取代在线更新。
以上,通过参照图5、图6以及图7进行了说明的动作,本实施方式实现以下效果:能够生成价值函数q,该价值函数q用于生成一边提高工件的加工精度一边缩短周期时间的行为信息。
接下来,参照图8的流程图,针对最优化行为信息输出部305生成最优化行为信息时的动作进行说明。
首先,在步骤s21中,最优化行为信息输出部305取得在价值函数存储部304中存储的价值函数q。如上所述,价值函数q是通过由价值函数更新部3022进行q学习而更新的函数。
在步骤s22中,最优化行为信息输出部305根据该价值函数q,生成最优化行为信息,并向数值控制装置200的程序修正部205输出所生成的最优化行为信息。
如上所述,数值控制装置200根据该最优化行为信息来修正当前设定的加工程序,并生成动作指令。通过该动作指令,可以实现以下效果:机床100能够以一边提高工件的加工精度,一边进一步缩短该加工周期时间的方式进行动作。
以下,根据实施例对本实施方式的效果进行说明。
(实施例1)
实施例1是设置最大试验次数,在机器学习装置300例如采取措施,即主要选择使主轴速度以及/或进给速度加速的行为a来进行机器学习后,主轴速度s、进给速度f变快,周期时间变短的情况的实施例。
使用图2~图4示出的机床100、数值控制装置200以及机器学习装置300,基于图5示出的机器学习动作来进行机器学习。使机器学习中的回报的值如下那样。
关于基于周期时间的回报的值,在周期时间值变长时设为-5,在周期时间值不变时设为+5,在周期时间值变短时设为+10。关于基于加工精度的回报的值,在加工精度在适当范围内时设为+10。即,与公差品质是“精细”、“中等”、“粗糙”无关,将基于加工精度的回报的值设为相同的+10。
机器学习前的输出数据为主轴速度s:758[rev/min],进给速度f:455[rev/min]。作为机器学习的结果,机器学习后的输出数据为主轴速度s:909[rev/min],进给速度f:682[rev/min]。
(实施例2)
实施例2是设置最大试验次数,例如在采取措施,即主要选择使切入量j增加以及/或者使切入次数减少的行为a来进行机器学习后,切入量j增加,切入次数l减少,加工路径变短,结果周期时间变短时的实施例。
在实施例2中,与实施例1同样地,使用图2~图4示出的机床100、数值控制装置200以及机器学习装置300,根据图5示出的机器学习动作来进行机器学习。基于周期时间的回报的值以及基于加工精度的回报的值也与实施例1相同。
在径向的总切入量是1.2[mm]时,机器学习前的输出数据为一次的切入量j:0.3[mm],切入次数l:4[次]。作为机器学习的结果,机器学习后的输出数据为一次的切入量j:0.4[mm],切入次数l:3[次]。
<变形例>
此外,在以上说明的实施方式中,机器学习装置300决定最大试验次数来进行机器学习,但是也可以不决定最大试验次数地持续进行机器学习。如果不决定最大试验次数,则根据情况调整加工条件以使加工精度提高,因此即使工具变旧锋利程度变差,也可以通过在该时间点的最优化的加工条件来进行加工。因此,对延长工具寿命有效。
以下,根据实施例针对机器学习装置300不决定最大试验次数地持续进行机器学习时的效果进行说明。
本实施例是机器学习装置300不决定最大试验次数地进行机器学习,即使切入量j减少,对主轴速度s,进给速度f进行了调整的实施例。
在本实施例中,与实施例1同样,使用图2~图4示出的机床100、数值控制装置200以及机器学习装置300,根据图5示出的机器学习动作来进行机器学习。基于周期时间的回报的值以及基于加工精度的回报的值也与实施例1相同。在实施例3中不设置最大试验次数,因此不设置图5的步骤s17以及s18,机器学习装置300重复进行步骤s12~步骤s16。
作为机器学习的结果,在某时间点的输出数据为主轴速度s:758[rev/min],进给速度f:455[rev/min],一次的切入量j:0.4[mm],切入次数l:3[次]。在持续进行机器学习之后的时间点的输出数据为主轴速度s:909[rev/min],进给速度f:682[rev/min],一次的切入量j:0.3[mm],切入次数l:4[次]。
<其他的变形例>
在以上说明的实施方式中,通过包含工具半径的坐标来生成加工程序,在使用不同的工具时必须修正全部的坐标。还存在由于工具侧的磨损等需要修正路径的情况。因此,在加工程序中设置称为工具直径修正的功能。在上述实施方式中,可以调整工具直径校正量来取代每一次的切入量,或者可以除了每一次的切入量以外还调整工具直径校正量。工具直径校正量对应于工具校正量。
在上述实施方式中,作为机床100,列举了进行螺纹铣削加工的机床,但是并不限于此,机床100可以是进行内径加工、外形加工、表面加工等加工的机床。以下,作为第2以及第3实施方式来说明外形加工以及表面加工的例子。
(第2实施方式)
本发明的第2实施方式涉及通过机床进行外形加工时的数值控制系统。由于在本实施方式中使用的数值控制装置以及机器学习装置是与第1实施方式中说明的数值控制装置以及机器学习装置相同的结构,因此省略说明。
图9是外形加工的说明图。如图9所示,机床使工具t2一边旋转一边进行移动,从而进行工件w2的外周的外形加工。外形加工在考虑工具t2以及工件w2的基材的基础上,为了一边维持成为工件w2的外周的加工精度的表面精度一边实现更短的加工时间,如图9所示,需要调整使工具t2进行旋转的主轴的主轴转速、进给速度、向工具径向的切入次数以及向工具径向的切入量。第2实施方式中的机器学习中的状态信息除了工件的加工精度是表面精度这一点以外与第1实施方式相同。使用3维测量器等测量表面精度。表面精度是用于表示加工后的面相对于作为目标的表面偏离怎样的程度的值。
第2实施方式中的q学习时的机器学习装置300的动作与第1实施方式的动作的不同之处在于,使用图10所示的步骤s15-4来代替图7所示的根据加工精度来计算回报的步骤s15-2。
如步骤s15-4所示,图4所示的回报输出部3021首先在步骤s162中,判断通过状态s′所涉及的加工处理制造出的工件的表面精度比通过状态s所涉及的加工处理制造出的工件的表面精度低还是不变还是高。然后,当表面精度降低时,回报输出部3021在步骤s163中使回报为负值。当表面精度不变时,回报输出部3021在步骤s164中使回报为零。当表面精度提高时,回报输出部3021在步骤s165中使回报为正值。
此外,回报输出部3021可以在表面精度不变时使回报为正值,在表面精度提高时使回报为比表面精度不变时的回报更大的正值。
另外,可以根据比例来增大在通过执行行为a之后的状态s′所涉及的加工处理制造出的工件的表面精度低于通过前一个状态s所涉及的加工处理制造出的工件的表面精度时的负值。也就是说,可以根据表面精度降低的程度来使负值增大。相反,可以根据比例增大在通过执行行为a之后的状态s′所涉及的加工处理制造出的工件的表面精度高于通过前一个状态s所涉及的加工处理制造出的工件的表面精度时的正值。也就是说,可以根据表面精度提高的程度来使正值增大。
(第3实施方式)
本发明的第3实施方式涉及通过机床进行表面加工时的数值控制系统。在本实施方式中使用的数值控制装置以及机器学习装置是与第1实施方式中说明的数值控制装置以及机器学习装置相同的结构,因此省略说明。
图11是表面加工的说明图。机床使工具t3一边旋转一边进行直线移动,从而进行工件w3的加工面的表面加工。表面加工在考虑工具t3以及工件w3的基材的基础上,为了一边维持成为工件w3的加工表面的加工精度的表面精度一边实现更短的加工时间,如图11所示,需要调整使工具t3进行旋转的主轴的主轴转速、进给速度、向工具轴向的切入次数以及向工具轴向的切入量。
第3实施方式的机器学习的状态信息中的工件的加工精度是表面精度,除了切入次数与切入量不是工具径向而是工具轴向以外,第3实施方式与第1实施方式相同。使用3维测量器等测量表面精度。表面精度是用于表示加工后的面相对于作为目标的表面偏离怎样的程度的值。第1实施方式中的工具直径校正量在第3实施方式中成为工具长度校正量。工具长度校正量对应于工具校正量。
根据加工精度来计算回报的步骤与第2实施方式的步骤s15-4相同。
以上,针对本发明的实施方式进行了说明,但是上述数值控制装置以及机器学习装置分别能够通过硬件、软件或它们的组合来实现。另外,通过各个上述数值控制装置以及机器学习装置的协作而进行的机器学习方法也能够通过硬件、软件或它们的组合来实现。在这里,通过软件来实现是指通过由计算机读入并执行程序来实现。
能够使用各种各样的类型的非暂时性的计算机可读记录介质(non-transitorycomputerreadablemedium)来保存程序,并提供给计算机。非暂时性的计算机可读记录介质包含各种各样的类型的有形的记录介质(tangiblestoragemedium)。作为非暂时性的计算机可读记录介质的例子,包含磁记录介质(例如,软盘、硬盘驱动器)、磁光记录介质(例如,磁光盘)、cd-rom(readonlymemory:只读存储器)、cd-r、cd-r/w、半导体存储器(例如,掩膜rom、prom(programmablerom:可编程rom)、eprom(erasableprom:可擦除prom)、闪存rom、ram(randomaccessmemory:随机存取存储器))。
另外,上述实施方式是本发明的优选的实施方式,但是本发明的范围不仅限于上述实施方式,在不脱离本发明的主旨的范围内可以通过实施了各种各样的变更后的方式来实施。
<变形例>
在上述第1~第3实施方式中,机器学习装置300是通过与机床100以及数值控制装置200不同的装置来实现的,但是机器学习装置300的部分功能或全部功能也可以通过机床100或数值控制装置200来实现。另外,机器学习装置300的最优化行为信息输出部305可以作为与机器学习装置300不同的最优化行为信息输出装置。这种情况下,可以针对多个机器学习装置300设置1个或多个最优化行为信息输出装置来进行共享。
<系统结构的自由度>
在上述实施方式中,将机器学习装置300与数值控制装置200可通信地连接为1对1的组合,但是也可以设为例如1台机器学习装置300经由网络400与多个数值控制装置200可通信地连接,来执行各数值控制装置200的机器学习。
此时,可以设为将机器学习装置300的各功能适当分散到多个服务器的分散处理系统。另外,也可以在云端利用虚拟服务器功能等来实现机器学习装置300的各功能。
另外,当存在分别与相同的型号名称、相同规格或相同系列的多个数值控制装置200-1~200-n相对应的多个机器学习装置300-1~300-n时,数值控制系统10可以构成为共享各机器学习装置300-1~300-n中的学习结果。由此,可以构建更为最优化的模型。
符号说明
10数值控制系统
100、100-1~100-n机床
101主轴电动机
102进给轴伺服电动机
103周期计数器
200、200-1~200-n数值控制装置
201主轴电动机控制部
202进给轴伺服电动机控制部
203数值控制信息处理部
204存储部
300、300-1~300-n机器学习装置
301状态信息取得部
302学习部
303行为信息输出部
304价值函数存储部
305最优化行为信息输出部
400网络。
- 还没有人留言评论。精彩留言会获得点赞!