交互强化学习方法在水下机器人中的应用与流程
本发明属于机器人控制技术领域,涉及交互强化学习方法在水下机器人中的应用。
背景技术:
自主式水下航行器(autonomousunderwatervehicle,auv)要在复杂且不可预知水下环境中自主完成预定任务,精确可靠的控制是必不可少的。传统的控制方法需要精确的数学模型或解决系统耦合性能力较差,虽然对于系统内部特性的变化和外部扰动的影响都具有一定的抑制能力,但是由于控制器参数是固定的,所以当系统内部特性变化或者当外部扰动的变化幅度很大时,系统的性能常常会大幅度下降甚至是不稳定,往往需要线下重新调整控制参数,不能实时地对不可预测的环境变化作出反应和调整。
与此相比,强化学习可以实现在线参数调整,在没有精确地数学模型或耦合性较高的系统中,可以获得良好的控制效果。但是,目前在传统强化学习方法中,定义一个有效的奖赏函数并不是简单的事,这需要控制器的设计人员凭领域知识定义,还需要经过多次调试才能完成。采用一个低效的奖赏函数会在很大程度上影响到最终的最优策略,并意味着控制器需要大量的学习样本和时间去试错和探索,尤其是在学习的初始阶段,这很可能为auv在线学习造成不必要的错误和损失。
技术实现要素:
本发明提供交互强化学习方法在水下机器人中的应用,利用训练者的经验知识来提高auv自主学习速度的技术,避免传统强化学习方法繁琐的调试和不必要的试错;将离线获得的策略作为auv在实际环境中运行的初始控制策略,通过在线自主学习改进控制策略,提高稳定性。
为了实现上述目标,本发明所采用的技术方案如下:
首先,对auv进行仿真建模,在仿真环境中auv利用训练者的经验知识通过交互强化学习方法提取所有有用的信息,并初步学习控制策略,一旦训练者认定auv获得足够的知识并建立了一个安全的控制策略,就将仿真学习得到的初始控制策略转移到auv,在真实环境中在线学习,采用auv在线自主学习控制技术,继续改进控制策略,作为auv在真实环境中运行的控制策略。
进一步,交互强化学习方法首先探测auv在仿真环境中所处的状态,根据当前的控制策略选择并执行一个动作,训练者观察控制器在当前状态下所选择的动作,并根据自己的经验知识评估其质量,控制器以此评估信号作为奖赏信号更新控制策略,直到训练者认定控制器的策略足够安全为止,最后将学习到的控制策略移植到auv,作为auv在真实环境中在线学习的初始控制策略。
进一步,离线仿真训练所得的初始控制策略移植到auv以后,控制器需要继续在线自主学习,auv探测数据并判断当前所处的状态,控制器依据离线获得的初始控制策略选择并执行动作,auv依据预先定义的奖赏函数的环境奖赏信号更新控制策略,并判断是否最优控制策略,若是最优控制策略,结束当前学习并执行相应动作;若不是,则重新进行此学习过程,直到达到最优控制策略为止,通过在线自主学习控制技术达到最优的控制效果。
附图说明
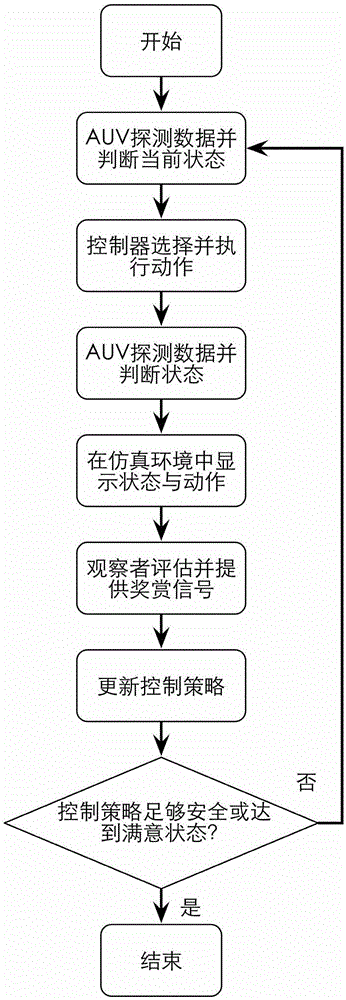
图1是交互强化学习方法加速auv自主学习技术路线示意图;
图2是auv在线自主学习控制技术路线示意图。
具体实施方式
下面结合具体实施方式对本发明进行详细说明。
本发明的实施过程分为离线仿真训练获得初始控制策略和在线自主学习改进控制策略两部分:
首先,对auv进行仿真建模,在仿真环境中auv探测数据并判断当前所处的状态,控制器依据自己的初始策略选择并执行一个动作,训练者通过观察控制器的动作,并依据自己的经验对当前环境下控制器所选择的动作进行评估,训练者对他所认为的控制器执行的正确动作给予一个积极的反馈作为鼓励信号,当控制器选择执行一个不合适的动作时训练者给它一个负的反馈信号,告诉控制器它当前状态下采取的动作是错误的,控制器通过训练者给出的反馈及时调整控制策略,一直到训练者认定auv获得足够的知识并建立了一个安全的控制策略,就将学习的控制策略移植到真正的auv上,作为auv在真实环境中运行的初始控制策略,从而大大减少auv在真实环境中的在线学习时间,避免不必要的试错造成的损失。图1为交互强化学习方法加速auv自主学习技术路线示意图。
其次,由于auv运行的实际环境复杂多变,往往不同于仿真环境。离线仿真训练所得的初始控制策略移植到auv后,控制器需要继续在线学习,通过自动调整适应真实运行环境,改进初始控制策略,提高稳定性。仿真阶段训练者提供的人的奖赏信号虽然可以提高学习速度,但由于人的奖赏信号是主观的,且一般有不可避免的缺陷,控制策略很难达到最优的学习效果。相比之下,预定义奖赏函数提供的环境奖赏信号虽然学习速度慢,但是客观且无缺陷,最终可以达到最优学习效果。另一方面,由于离线学习已经获得有效的初始控制策略,auv在实际环境中的奖赏信号可以通过简单预定义的奖赏函数提供,不需要对奖赏函数做反复的调试。因此,本发明通过离线和在线的方式结合人的奖赏信号和环境奖赏信号,以期达到既可以减少学习时间,又可以最终获得比其中任何一种奖赏信号都要好的最优学习效果。本发明采取的auv在线自主学习控制技术路线如图2所示。
本发明中采用动作-评价者(actor-critic)方法作为auv在线自主学习的算法。在强化学习中,值函数方法最为常用,值函数方法适用于具有离散动作空间的系统,控制器通过与环境的交互学习优化值函数,控制策略直接从值函数中获取,但这种方法学习的控制策略泛化能力差,并且容易在最优和次优策略间震荡,对具有连续动作空间的系统而言计算量大;而策略梯度(policygradient)方法能够收敛到最优策略,通过对控制策略采用函数逼近方法(functionapproximation)解决了泛化问题,适用于具有连续动作空间的系统,但学习速度比较慢。动作-评价者(actor-critic)算法有效地结合了强化学习值函数方法和策略梯度法的优点,能够有效地减少收敛所需时间,计算量小,适合线上学习,并且避免获得一个局部最优策略。该算法通过评价者模块(critic)维持一个值函数,同时通过动作模块(actor)维持一个分离的参数化的控制策略。由于控制策略与值函数分离,在值函数出现较大的变化时,可以有效的避免控制策略产生大幅度变动,从而提高系统稳定性。除此以外,为了完全覆盖状态和动作空间,使用函数逼近器来维持值函数和控制策略,鉴于极限学习机elm良好的在线学习能力和泛化特性,auv的状态和动作空间都是连续的,而控制策略和值函数多为非线性函数,我们将其作为控制策略和值函数的函数逼近器。
本发明的优点还在于:
(1)本发明将研究利用人的经验知识加速auv自主学习能力。不同于国内外多数研究采用传统的强化学习方法设计auv控制系统,本发明提出了采用新提出的交互强化学习方法加速学习过程,不需要预定义奖赏函数,而是通过训练者对auv行为动作进行评估来提供奖赏进行学习,在以一种自然的方式充分利用训练者的经验知识更好地指导学习的同时,避免了传统强化学习方法繁琐的调试和不必要的试错,利用线下训练获得的策略作为auv在实际环境中运行的初始控制策略,避免auv在线自主学习时不必要的错误和损失。
(2)本发明将研究auv在线自主学习能力。不同于传统的auv控制系统需要精确的数学模型或是解决系统耦合性的能力较差,一旦环境有所变化,需要重新线下调整参数,本发明提出了采用强化学习、极限学习机等在线学习方法,在离线训练获得的初始控制策略的基础上继续学习,改进控制策略,以期通过在线参数调整实时地对不可预测的环境变化作出反应,即使在没有精确的数学模型或耦合性较高的系统中,也可以获得良好的控制效果。
(3)不同于传统的强化学习方法只从预定义的环境奖赏信号中进行学习,本发明提出将人的奖赏与预定义的环境奖赏通过离线与在线的方式结合,充分利用训练者的经验知识,达到既能加速auv自主学习,又可以使auv最终获得优于从任何一种奖赏信号单独学习的目的。
以上所述仅是对本发明的较佳实施方式而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施方式所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!