一种基于强化学习的喷涂机器人轨迹优化方法与流程
本发明属于智能算法控制领域,特别涉及一种基于强化学习的喷涂机器人轨迹优化方法。
背景技术:
大部分喷涂机器人采用示教喷涂,根据技术员工预先设定好的轨迹进行喷涂,这种喷涂方法根据前人喷涂的经验进行有效的喷涂,但是前期编程工作较大,而且轨迹优化不明显,效率较低,涂料浪费相对较大。
基于强化学习的轨迹优化利用强化学习通过机器人对环境进行建模,在机器内部模拟出与环境相同或类似的状况,进行喷涂轨迹优化。在已有的轨迹优化算法中,通常都是概率路图法、快速搜索树法及人工势场法等。此类方法在将对环境建模或者模拟空间时,需要对机械臂的多种姿态进行采样,并通过运动学方程判断当前动作是否合理,计算量大;当环境中的障碍物和目标位置发生改变时,需要对新的环境重新计算构型空间的映射,难以达到动态实时规划的目的。另外,此类方法需要事先对机械臂构建精确的物理模型,建模的偏差会直接影响机械臂控制的效果。
针对目前强化学习的方法,强化学习方法以马尔科夫决策过程来描述问题,通过智能体与环境的互动积累经验,并且不断更新智能体的策略,使它做出的决策能够获得更高的奖励。相比于传统方法,该方法不需要对机械臂构建物理模型,在训练完成后,策略能够直接根据当前环境状态输出下一步的决策,由于网络进行一次前向计算的计算量很少,因此能够实现喷枪的在线规划与实时控制。
技术实现要素:
本发明要解决的技术问题是提供一种基于强化学习的喷涂机器人轨迹优化方法,解决了喷枪在喷涂过程中,能够实现有效的在线规划与实时控制。
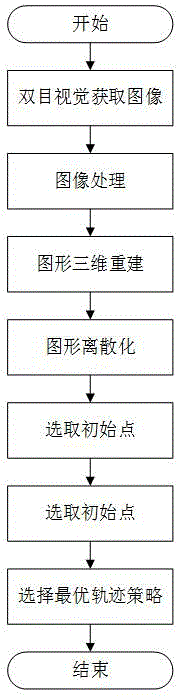
为解决上述技术问题,本发明的技术方案为:一种基于强化学习的喷涂机器人轨迹优化方法,其创新点在于:所述轨迹优化方法通过图像获取、图像处理、图形三维重建、图形离散化、选取初始点和选择最优轨迹策略,从而确定出最优喷涂轨迹,其中,所述图像处理包括摄像机标定、图像校正和立体匹配;具体步骤如下:
步骤1:图像获取:采用双目视觉系统中的两台相同的相机同时获取同一个场景中的目标物体图像,然后,对获取的图像进行预处理;
步骤2:摄像机标定:对于获取的畸变向量,消除它的径向和切线方向上的镜头畸变,获得无畸变图像,同时建立摄像机的成像模型,确定目标点与像素点之间的对应关系;
步骤3:图像校正:通过线性变换使处理后的无畸变图像中的共轭极线位于同一水平线上,把二维空间的匹配问题化简为一维空间的求解问题;
步骤4:立体匹配:采用立体匹配算法得到校准后的图像与原图像的视差值,然后利用这个视差值得到每两幅图像之间的稀疏匹配,再通过优化算法,获得稠密匹配;
步骤5:三维重建:采用三角测量原理计算获取的立体匹配图像的深度值,得到稠密的三维空间点云,再对获取的三维空间点云进行网格化和差值计算,得到物体的三维结构模型;
步骤6:图形离散化:通过双目视觉系统对目标物体进行目标获取,对空间进行离散化,即将目标转化为点的集合;
步骤7:选取初始点;
步骤8:选择最优轨迹策略:将决策策略π定义为一个函数,它将一个状态映射到一个动作s→a,即当前状态s执行动作a;强化学习的目标函数为:
qπ(s,a)=e(r(s0)+γr(s1)+γ2r(s2)+...|s0=s,a0=a,π)(1)
qπ(s,a)表示当前初始状态s下,采取动作a之后依照策略π的决策运动所能获得期望收益,即找到最优策略π*,使得
π*=argmaxqπ(s,a)。
进一步地,所述步骤2中的摄像机标定,假设目标点p的三维坐标为(xw,yw,zw),左摄像机的坐标系为o1-x1y1z1,图像坐标系为o1-x1y1;右摄像机的坐标系为o2-x2y2z2,图像坐标系为o2-x2y2;原点o1,o2分别为左右摄像机的光心;左右摄像机的焦距分别设为f1,f2。
进一步地,所述步骤5中得到物体的三维结构模型
其中,r1,r2……r9为旋转分量;tx,ty,tz为平移分量,式中xw、yw和zw为三维结构模型中三维坐标的解。
进一步地,所述步骤8中,在q学习的基础上,深度q学习,以神经网络来拟合q函数(s,a),其输入状态s可以是连续变量;学习算法如下:
(1)初始化经验回放存储区d;
(2)初始化q网络、目标q网络(q′),其网络权值为随机值;
(3)开始新的一轮,随机生成环境、喷涂目标,目标点随机出现在空间一定范围内的任意位置,喷枪重置为初试姿态;
(4)以ε的概率选择随机动作at,1-ε的概率选择最优动作at=max(st,a),其中st为当前状态;
(5)执行动作at,得到当前奖励rt,下一时刻状态st+1,将(st,at,rt,st+1)存入d;
(6)从d中随机采样一批数据,即一批(sj,aj,rj,sj+1)四元组,令
(7)若st+1不是最终状态st则返回步骤(4),若st+1是最终状态,st则更新目标网络q′,令q′的网络参数等于q的网络参数,并返回步骤(3)。
进一步地,奖励函数rt分为三个部分,第一部分对重复喷涂进行惩罚,即静止不动,第二部分对喷枪到达目标位置进行奖励,第三部分,对喷枪与目标距离进行奖励或者惩罚,奖励函数为:
式中,xd为当前点坐标,xe为目标点坐标。
本发明的优点在于:
(1)本发明基于强化学习的喷涂机器人轨迹优化方法,采用双目视觉获取目标的位置空间信息,精确度较高,对于一些喷涂工件的大曲率或者凹点凸点能够很好的识别,效率较高;
(2)本发明基于强化学习的喷涂机器人轨迹优化方法,该方法能够在不同的环境中根据不同的状态规划出可行路径,并且决策时间短、成功率高,能够满足在线规划的实时性要求,从而克服了传统机械臂路径规划方法实时性差、计算量大的缺点;
(3)本发明基于强化学习的喷涂机器人轨迹优化方法,强化学习不需要大量的训练数据,且能够生成决定性策略,抗干扰能力强,能够有效地进行轨迹优化。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是本发明基于强化学习的喷涂机器人轨迹优化方法的流程图。
图2是双目视觉系统图。
图3是汇聚式双目视觉理论模型图。
图4是双目视觉三维重建系统组成图。
图5是强化学习模型示意图。
具体实施方式
下面的实施例可以使本专业的技术人员更全面地理解本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例
本实施例中基于强化学习的喷涂机器人轨迹优化方法中的双目视觉系统,如图2所示,左右相机能够平行放置,并且要保证基线不能太长,将平行式光轴双目视觉系统中的左右相机分别绕光心顺时针和逆时针旋转一定角度,从而形成汇聚式双目视觉系统;此系统的优点是能够获得更大的视场,大视场的好处就是能够提高计算视差的精度,从而可以提高三维重建的精度。
本实施例中基于强化学习的喷涂机器人轨迹优化方法,如图1所示,通过图像获取、图像处理、图形三维重建、图形离散化、选取初始点和选择最优轨迹策略,从而确定出最优喷涂轨迹,其中,所述图像处理,如图4所示,包括摄像机标定、图像校正和立体匹配;具体步骤如下:
步骤1:图像获取:采用双目视觉系统中的两台相同的相机同时获取同一个场景中的目标物体图像,然后,对获取的图像进行预处理;
步骤2:摄像机标定:对于获取的畸变向量,消除它的径向和切线方向上的镜头畸变,获得无畸变图像,同时建立摄像机的成像模型,确定目标点与像素点之间的对应关系;如图3所示,假设目标点p的三维坐标为(xw,yw,zw),左摄像机的坐标系为o1-x1y1z1,图像坐标系为o1-x1y1;右摄像机的坐标系为o2-x2y2z2,图像坐标系为o2-x2y2;原点o1,o2分别为左右摄像机的光心;左右摄像机的焦距分别设为f1,f2;
步骤3:图像校正:通过线性变换使处理后的无畸变图像中的共轭极线位于同一水平线上,把二维空间的匹配问题化简为一维空间的求解问题;
步骤4:立体匹配:采用立体匹配算法得到校准后的图像与原图像的视差值,然后利用这个视差值得到每两幅图像之间的稀疏匹配,再通过优化算法,获得稠密匹配;
步骤5:三维重建:采用三角测量原理计算获取的立体匹配图像的深度值,得到稠密的三维空间点云,再对获取的三维空间点云进行网格化和差值计算,得到物体的三维结构模型;得到物体的三维结构模型为
其中,r1,r2……r9为旋转分量;tx,ty,tz为平移分量,式中xw、yw和zw为三维结构模型中三维坐标的解;
步骤6:图形离散化:通过双目视觉系统对目标物体进行目标获取,对空间进行离散化,即将目标转化为点的集合;
步骤7:选取初始点;
步骤8:选择最优轨迹策略:将决策策略π定义为一个函数,它将一个状态映射到一个动作s→a,即当前状态s执行动作a;强化学习的目标函数为:
qπ(s,a)=e(r(s0)+γr(s1)+γ2r(s2)+...|s0=s,a0=a,π)(1)
qπ(s,a)表示当前初始状态s下,采取动作a之后依照策略π的决策运动所能获得期望收益,即找到最优策略π*,使得
π*=argmaxqπ(s,a);在q学习的基础上,深度q学习,以神经网络来拟合q函数(s,a),其输入状态s可以是连续变量;学习算法如下:
(1)初始化经验回放存储区d;
(2)初始化q网络、目标q网络(q′),其网络权值为随机值;
(3)开始新的一轮,随机生成环境、喷涂目标,目标点随机出现在空间一定范围内的任意位置,喷枪重置为初试姿态;
(4)以ε的概率选择随机动作at,1-ε的概率选择最优动作at=max(st,a),其中st为当前状态;
(5)执行动作at,得到当前奖励rt,下一时刻状态st+1,将(st,at,rt,st+1)存入d;
(6)从d中随机采样一批数据,即一批(sj,aj,rj,sj+1)四元组,令
(7)若st+1不是最终状态st则返回步骤(4),若st+1是最终状态,st则更新目标网络q′,令q′的网络参数等于q的网络参数,并返回步骤(3)。
其中,(5)中的奖励函数rt分为三个部分,第一部分对重复喷涂进行惩罚,即静止不动,第二部分对喷枪到达目标位置进行奖励,第三部分,对喷枪与目标距离进行奖励或者惩罚,奖励函数为:
式中,xd为当前点坐标,xe为目标点坐标。
以上显示和描述了本发明的基本原理和主要特征以及本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!