一种多智能体事件驱动编队控制系统及方法与流程
本发明属于多智能体控制技术领域,具体涉及一种多智能体事件驱动编队控制系统及方法。
背景技术:
智能体是人工智能领域中一个很重要的概念。任何独立的能够思想并可以同环境交互的实体都可以抽象为智能体。多智能体系统是多个智能体组成的集合,它的目标是将大而复杂的系统建设成小的、彼此互相通信和协调的,易于管理的系统。多智能体系统作为人工智能的一个重要分支,得到了人们的广泛关注。多智能体系统具有自主协调控制和分布式控制的性能,并具有自行组织的能力、学习能力和推理预测的能力。
多智能体系统的研究启发于自然界生物群集行为,如编队迁徙的鸟群、结队巡游的鱼群、协同工作的蚁群。这些生物通过个体协调,能够完成单一个体无法完成的任务。多智能系统通过个体间的合作能够以较小的代价完成更复杂的任务。编队控制通常是指多个智能体组成的团队在向特定目标或方向运动的过程中,通过智能体间的局部信息通信,相互之间保持预定的队形的控制问题。编队控制可以使多智能体系统能够更加有效地完成指定的任务,在航天航空、智能交通和智能机器人等领域有着广泛的应用背景。
目前,在编队控制方面,国内外已经开展了大量理论和实物研究,主要集中于队形生成、队形保持、队形切换、队形避障等方面。然而,现有的编队控制技术存在下列不足:第一,大部分编队控制研究局限于模型已知的多智能体系统,但是在实际应用中很难获取到智能体的精确模型,导致大部分研究成果难于应用到实际控制系统中。第二,针对动态未知的多智能体系统,提出的自适应编队控制局限于未知动态满足匹配条件的多智能体系统,即智能体的未知动态可以通过控制器进行前馈补偿。第三,现有编队控制研究属于基于时间驱动的控制方法,系统以固定的周期采样更新控制器,会导致系统已经实现期望的编队控制时,控制器仍然在更新,造成系统资源的浪费。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提供了一种多智能体事件驱动编队控制系统及方法。本发明要解决的技术问题通过以下技术方案实现:
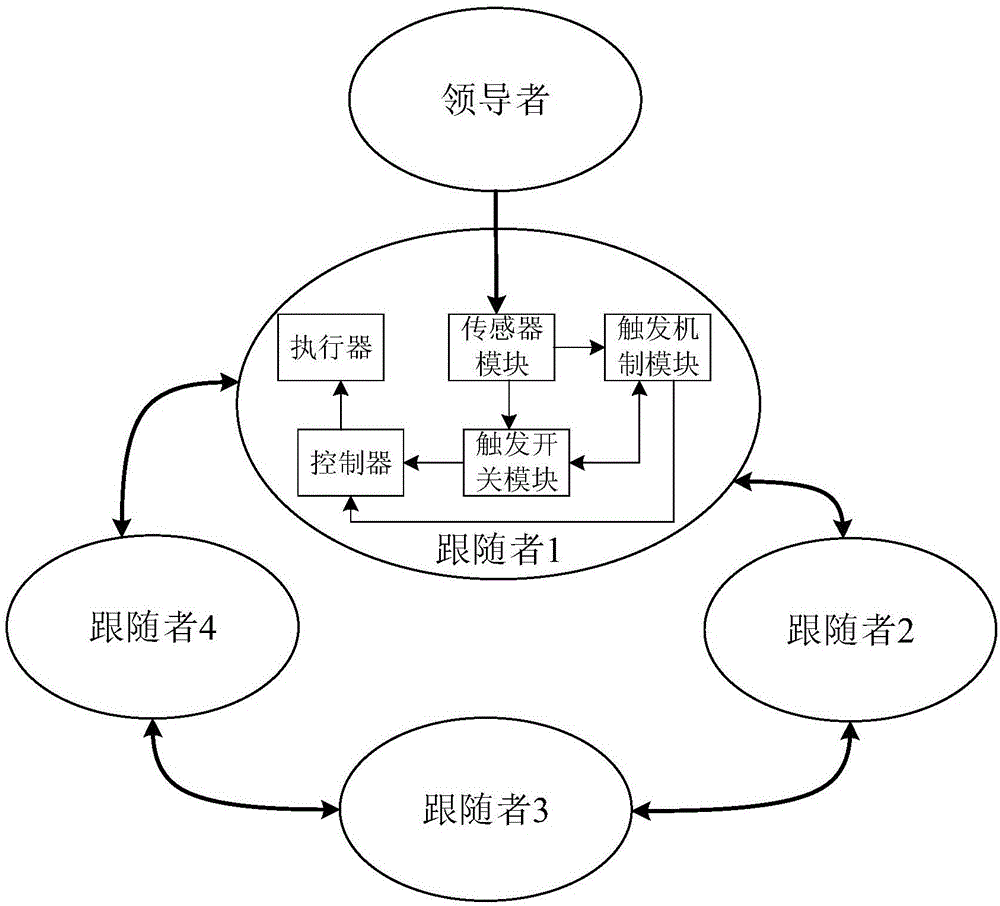
本发明实施例提供了一种多智能体事件驱动编队控制系统,包括:领导者、多个跟随者;其中,
所述领导者与至少一个所述跟随者之间通信,用于根据第一动作信息生成第一跟随指令;
多个所述跟随者之间相互通信,所述跟随者用于根据第二动作信息和所述第一跟随指令生成第二跟随指令,或根据第三跟随指令和所述第二动作信息生成所述第二跟随指令,并根据所述第二跟随指令实现预设队形。
在本发明的一个实施例中,所述第一动作信息包括所述领导者的位置信息和速度信息;
所述第二动作信息包括所述跟随者的位置信息和速度信息。
在本发明的一个实施例中,所述跟随者包括:传感器模块、触发机制模块、触发开关模块、控制器、执行器;其中,
所述传感器用于获取所述第二动作信息、所述第一跟随指令和第三跟随指令;
所述触发机制模块用于根据所述第一跟随指令或第三跟随指令生成所述第二跟随指令,并通过所述第二动作信息计算驱动偏差;
所述触发开关模块用于通过所述驱动偏差与设定阈值生成控制指令;
所述控制器用于根据所述控制指令和所述第二跟随指令控制所述执行器实现所述预设队形。
在本发明的一个实施例中,所述触发机制模块包括零阶保持器;
所述零阶保持器用于存储原始第二动作信息;
所述零阶保持器还用于根据所述控制指令更新所述原始第二动作信息。
本发明的另一个实施例提供了一种多智能体事件驱动编队控制方法,包括:
获取第一跟随指令、第三跟随指令和第二动作信息;
根据所述第一跟随指令、所述第三跟随指令和第二动作信息获取第二跟随指令;
根据所述第二动作信息计算驱动偏差;
通过所述第二跟随指令和所述驱动偏差实现当前跟随者的预设队形。
在本发明的一个实施例中,获取第一跟随指令、第三跟随指令和第二动作信息,包括:
通过领导者的第一动作信息获取所述第一跟随指令;
通过相邻跟随者的第二跟随指令获取所述第三跟随指令;
通过跟随者的当前位置信息、原始位置信息、当前速度信息和原始速度信息获取所述第二动作信息。
在本发明的一个实施例中,根据所述第二动作信息计算驱动偏差,包括:
通过所述当前速度信息与所述原始速度信息计算速度偏差;
通过所述当前位置信息与所述原始位置信息计算位置偏差;
根据所述速度偏差和位置偏差计算所述驱动偏差。
在本发明的一个实施例中,所述速度偏差与所述位置偏差的计算公式为:
其中,ei1(t)为所述位置偏差,pi(t)为所述当前位置信息,pi(tik)为所述原始位置信息,ei2(t)为所述速度偏差,vi(t)为所述当前速度信息,vi(tik)为所述原始速度信息。
在本发明的一个实施例中,通过所述第二跟随指令和所述驱动偏差实现当前跟随者的预设队形,包括:
通过第二跟随指令计算误差信号;
根据所述误差信号计算所述设定阈值;
根据所述设定阈值和所述驱动偏差实现当前跟随者的预设队形。
与现有技术相比,本发明的有益效果:
1)本发明提出的一种多智能体事件驱动编队控制系统为非线性多智能体编队控制系统,与现有的针对线性多智能体编队控制系统相比,拓展了应用范围,使得该系统更有利于实际应用。
2)本发明提出的一种多智能体事件驱动编队控制方法能够解决系统未知、动态不满足匹配条件的非线性多智能体系统的编队控制问题,放宽了编队控制对系统模型的限制,且控制算法对外界环境具有鲁棒性,对自身模型的不确定性具有自适应能力。
3)本发明提出的一种多智能体事件驱动编队控制方法,在满足期望控制性能的同时,有效的减少了调整编队的队形次数,降低了通信资源和计算资源。
附图说明
图1为本发明提供的一种多智能体事件驱动编队控制系统的结构示意图;
图2为本发明提供的一种多智能体事件驱动编队控制方法的原理示意图;
图3为本发明提供的编队控制轨迹示意图;
图4为本发明提供的编队驱动偏差示意图;
图5至图8分别为本发明提供的跟随者1至跟随者4的调整预设队形的频率示意图。
具体实施方式
下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。
实施例一
请参见图1至图8,图1为本发明提供的一种多智能体事件驱动编队控制系统的结构示意图;图2为本发明提供的一种多智能体事件驱动编队控制方法的原理示意图;图3为本发明提供的编队控制轨迹示意图;图4为本发明提供的编队驱动偏差示意图;图5至图8分别为本发明提供的跟随者1至跟随者4的调整预设队形的频率示意图。本发明实施例提供了一种多智能体事件驱动编队控制系统,具体包括:领导者、多个跟随者;其中,
所述领导者与至少一个所述跟随者之间通信,用于根据第一动作信息生成第一跟随指令;
多个所述跟随者之间相互通信,所述跟随者用于根据第二动作信息和所述第一跟随指令生成第二跟随指令,或根据第三跟随指令和所述第二动作信息生成所述第二跟随指令,并根据所述第二跟随指令实现预设队形。
进一步地,所述第一动作信息包括当前所述领导者的位置信息和速度信息;
所述第二动作信息包括当前所述跟随者的位置信息和速度信息。
具体地,所述第二动作信息包括当前速度信息、当前位置信息、原始位置信息、原始速度信息。
具体地,本实施例提供的领导者和跟随者均选取动态未知的二阶线性模型,跟随者模型可通过下式表示:
其中,下标i表示第i个跟随者,i为大于等于1的整数;pi,vi为跟随者的位置信息和速度信息;
优选的,fi1(pi)=sin(pi),
领导者模型可通过下式表示:
其中,po,vo为领导者的位置信息和速度信息;
优选的,第一跟随指令包括领导者的位置信息,第二跟随指令包括各跟随者预定队形的预定位置信息和自身的第二动作信息。
优选的,第三跟随指令为当前跟随者的相邻跟随者生成的第二跟随指令。
具体地,多个跟随者之间可以互相通信,在多个跟随者中,至少有一个跟随者可以获取领导者发送的第一跟随指令,当跟随者获取第一跟随指令后,该跟随者通过自身的位置信息、速度信息以及第一跟随指令生产第二跟随指令,并通过第二跟随指令实现自身的预设队形。
具体地,当跟随者未获取领导者发送的第一跟随指令,则该跟随者通过获取第三跟随指令,并与自身的位置信息和速度信息生成第二跟随指令,并通过第二跟随指令实现自身的预设队形。
具体地,跟随者在通过第二跟随指令运行时会出现微小的偏差,这时,跟随者根据自身的位置信息和速度信息,与通过第二跟随指令的得到的预设队形进行比较,且跟随者可以通过比较结果获取跟随者的控制输入,并通过控制输入实现自身的预设队形。
具体地,两个相互通信的跟随者之间的通信网络可以用双向图
具体地,如图1所示,本发明以1个领导者和4个跟随者为例进行说明。其中,跟随者1可以直接获取领导者发送的第一跟随指令,同时可以获取跟随者2和跟随者4的第二跟随指令;跟随者2可以获取跟随者1和跟随者3生成的第二跟随指令,同时和跟随者2的位置信息和速度信息生成跟随者2的第二跟随指令;同理,跟随者3和跟随者4可以各自生成自身的第二跟随指令。
进一步地,所述跟随者包括:传感器模块、触发机制模块、触发开关模块、控制器、执行器;其中,
所述传感器用于获取所述第二动作信息、所述第一跟随指令和第三跟随指令;
所述触发机制模块用于根据所述第一跟随指令或第三跟随指令生成所述第二跟随指令,并通过所述第二动作信息计算驱动偏差;
所述触发开关模块用于通过所述驱动偏差与设定阈值生成控制指令;
所述控制器用于根据所述控制指令和所述第二跟随指令控制所述执行器实现所述预设队形。
进一步地,所述触发机制模块包括零阶保持器;其中,所述零阶保持器用于存储原始第二动作信息;所述零阶保持器还用于根据所述控制指令更新所述原始第二动作信息。
具体地,原始第二动作信息包括原始位置信息和原始速度信息。根据所述控制指令更新所述原始第二动作信息,即将原始第二动作信息更新为第二动作信息。
具体地,传感器模块可以获取所在跟随者的第二动作信息(位置信息和速度信息)、第一跟随指令和第三跟随指令。优选的,传感器模块包括位置传感器、速度传感器和接收单元,位置传感器用于获取当前跟随者的位置信息,速度传感器用于获取当前跟随者的速度信息,接收单元用于获取第一跟随指令和第三跟随指令。
触发机制模块根据所述第一跟随指令或第三跟随指令生成所述第二跟随指令,并通过所述第二动作信息计算驱动偏差;
具体地,触发机制模块首先通过当前速度信息与原始速度信息计算速度偏差;然后通过当前位置信息与原始位置信息计算位置偏差;最后再根据速度偏差和位置偏差计算驱动偏差。
具体地,所述速度偏差与所述位置偏差的计算公式为:
其中,t包含于单调递增的时间序列{ti0,ti1,ti2…},且ti0=0。ei1(t)为所述位置偏差,pi(t)为所述当前位置信息,pi(tik)为所述原始位置信息,ei2(t)为所述速度偏差,vi(t)为所述当前速度信息,vi(tik)为所述原始速度信息。
具体地,驱动偏差的计算公式为:
其中,
具体地,控制器采用神经网络控制,可以表示为:
其中,γ1,γ2为待设计的控制增益;
具体地,参数向量θi1,θi2的自适应律设计为
其中,βi1,βi2为待设计的自适应学习律,ρi1,ρi2为设计参数,σi1,σi2为一个设计参数。
进一步地,触发开关模块还用于计算设定阈值;其中,
触发开关模块通过第二跟随指令计算误差信号;最后根据所述误差信号计算所述设定阈值。
具体地,触发开关模块连接传感器模块,可以获取第二动作信息和第一跟随指令,并通过第二动作信息和第一跟随指令可以获取该跟随者和领导者之间的绝对偏差以及当前位置信息和速度信息。
具体地,所述误差信号包括:位置误差和速度误差,其计算公式分别为:
其中,si1(t)为位置误差,si2(t)为速度误差,σi为第i个跟随者和领导者之间的绝对偏差、αi虚拟控制律。
具体地,根据位置误差和速度误差计算设定阈值的计算公式为:
ω1=ρ1(3γ1/4-1)/(γ1λmax(l+al)+μ1||θi1||)
ω2=ρ2(γ2-1/2)/(γ2+μ2||θi2||)
具体地,
进一步地,当计算出设定阈值
当
当
本发明在上述多智能体事件驱动编队控制系统的基础上,还提供了一种多智能体事件驱动编队控制方法,包括:
获取第一跟随指令、第三跟随指令和第二动作信息;
根据所述第一跟随指令、所述第三跟随指令和第二动作信息获取第二跟随指令;
根据所述第二动作信息计算驱动偏差;
通过所述第二跟随指令和所述驱动偏差实现当前跟随者的预设队形。
进一步地,获取第一跟随指令、第三跟随指令和第二动作信息,包括:
通过领导者的第一动作信息获取所述第一跟随指令;
通过相邻跟随者的第二跟随指令获取所述第三跟随指令;
通过跟随者的当前位置信息、原始位置信息、当前速度信息和原始速度信息获取所述第二动作信息。
进一步地,根据所述第二动作信息计算驱动偏差,包括:
通过所述当前速度信息与所述原始速度信息计算速度偏差;
通过所述当前位置信息与所述原始位置信息计算位置偏差;
根据所述速度偏差和位置偏差计算所述驱动偏差。
进一步地,所述速度偏差与所述位置偏差的计算公式为:
其中,ei1(t)为所述位置偏差,pi(t)为所述当前位置信息,pi(tik)为所述原始位置信息,ei2(t)为所述速度偏差,vi(t)为所述当前速度信息,vi(tik)为所述位置位置信息。
进一步地,通过所述第二跟随指令和所述驱动偏差实现当前跟随者的预设队形,包括:
通过第二跟随指令计算误差信号;
根据所述误差信号计算所述设定阈值;
根据所述设定阈值和所述驱动偏差实现当前跟随者的预设队形。
为了更好的说明本发明的效果,下面以图1为例,进行进一步描述。
具体地,如图1所示,在上述实施例的基础上,设定多智能体事件驱动编队控制系统的具体参数如下:
γ1=3,γ2=5,β11=0.1,ρ11=1,σ11=0.01,β21=0.1,ρ21=1,σ21=0.01,
β31=0.1,ρ31=1,σ31=0.01,β41=0.1,ρ41=1,σ41=0.01,
β12=0.5,ρ12=1,σ12=0.01,β22=0.5,ρ22=1,σ22=0.01,
β32=0.5,ρ32=1,σ32=0.01,β42=0.5,ρ42=1,σ42=0.01,μ1=1,μ2=1
对其进行电路仿真,获取其仿真结果,其结果如图3至图8所示。图3为领导者和跟随者编队控制轨迹示意图;其中,p0、p1、p2、p3、p4、分别为领导者、跟随者1、跟随者2、跟随者3、跟随者4的轨迹,从图中可以看出4个跟随者以领导者为中心,形成了对称的编队队形。图4中,横坐标为时间坐标轴(单位:秒),纵坐标为驱动偏差(单位:r弧度/秒)。图4为本发明提供的编队驱动偏差示意图,s11、s21、s31、s41分别为跟随者1至跟随者4的驱动轨迹,从图中可以看出,各跟随者的驱动偏差均收敛到零的极小邻域内。图5至图8中,threshold表示设定阈值,eventerror表示驱动偏差,横坐标为时间坐标轴(单位:秒),纵坐标为距离,图5至图8分别为本发明提供的跟随者1至跟随者4的调整预设队形的频率示意图,可以看出本发明提供的多智能体事件驱动编队控制系统方法在模型具有未知动态的情况下能够实现设定的编队效果;不采用固定周期更新,可以有效减小数据传输,减少控制能量。
本发明提出的一种多智能体事件驱动编队控制系统为非线性多智能体编队控制系统,与现有的针对线性多智能体编队控制系统相比,拓展了应用范围,使得该系统更有利于实际应用。本发明提出的一种多智能体事件驱动编队控制方法能够解决系统未知、动态不满足匹配条件的非线性多智能体系统的编队控制问题,放宽了编队控制对系统模型的限制,且控制算法对外界环境具有鲁棒性,对自身模型的不确定性具有自适应能力,且在满足期望控制性能的同时,有效的减少了调整编队的队形次数,降低了通信资源和计算资源。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!