一种智能家居控制系统的制作方法
本实用新型涉及智能网关技术领域。更具体地,涉及一种智能家居控制系统。
背景技术:
全息成像技术是利用制作完成的全息视频、显示器以及全息三角锥来达到空气中呈现三维立体影像的效果。但是目前用于家居控制的全息智能网关显示三维立体影像以及人机交互的方式没有实现智能化,即无法通过对用户的表情、身姿、语音情感等数据同时进行采集和分析并变换不同的内容,以满足用户人性化的需求。在人机交互技术上,传统的人机交互技术包括语音识别,手势识别,人脸识别等,可以对人体的不同输入动作给出不同的反馈。然而在给出反馈时,无法针对用户的行为特点进行分析,给出定制化的反馈。且当用户使用沉浸式头盔,沉浸在虚拟现实设备创造的虚拟沉浸式环境中,用户与真实世界的交互被阻断,存在一定的局限性。
技术实现要素:
本实用新型的目的在于提供一种智能家居控制系统,以根据用户的状态提供个性化的全息内容显示和智能家居控制;解决用户在使用虚拟显示设备时无法控制智能家居的问题。
为达到上述目的,本实用新型采用下述技术方案:
本实用新型一方面公开了一种智能家居控制系统,包括虚拟现实设备、全息智能网关及服务器;
所述全息智能网关与智能家居和所述服务器分别信号连接,用于采集用户的语音信息和深度图像传输至所述服务器,并基于服务器传输的显示信息显示全息影像、音频信号进行音频播放以及控制信息控制所述智能家居实现对应操作;
所述虚拟现实设备用于根据用户的运动状态形成智能家居控制请求,并将所述智能家居控制请求传输至所述服务器;
所述服务器用于接收所述全息智能网关传输的所述语音信息和深度图像以及所述虚拟现实设备传输的所述智能家居控制请求,对所述语音信息、深度图像和智能家居控制请求处理得到对应的所述音频信号、所述显示信息和所述控制信息并传输至所述全息智能网关。
优选地,所述全息智能网关包括第一通信模块、中央处理模块、全息投影模块、语音模块以及身份识别模块;
所述中央处理模块用于接收所述语音模块采集的用户语音信息,接收所述身份识别模块采集的用户深度图像信息,接收所述第一通信模块的所述智能家居的信息,并将所述显示信息传输至所述全息投影模块,将所述音频信号传输至所述语音模块以及将所述控制信息传输至所述第一通信模块;
所述第一通信模块用于与所述服务器和所述智能家居进行信号连接和传输,将用户的语音信息和深度图像传输至所述服务器,并接收所述服务器传输的音频信号、显示信息和控制信息并传输至所述中央处理模块,以及将所述中央处理模块传输的控制信息传输至所述智能家居以使所述智能家居实现对应操作;
所述语音模块用于采集用户的语音信息并传输至所述中央处理模块以及播放所述音频信号;
所述身份识别模块用于采集用户的深度图像并传输至所述中央处理模块;
所述全息投影模块用于根据所述显示信息进行全息投影,其中所述显示信息包括智能家居状态信息、所述身份识别模块识别结果的反馈信息、所属语音模块识别结果的反馈信息。
优选地,所述第一通信模块包括ZigBee模块、红外模块、蓝牙模块和/或WiFi模块。
优选地,中央处理模块为多线程CPU。
优选地,所述全息投影模块包括用于传输显示信息的多媒体接口、与所述多媒体接口连接的显示屏以及用于将显示屏的图像进行全息投影的光学投影组件。
优选地,所述语音模块包括扬声器以及多个麦克风。
优选地,所述身份识别模块为与所述中央处理模块连接的深度摄像头。
优选地,所述虚拟现实设备包括头戴显示器、激光定位器、运动传感器以及第二通信模块;
所述激光定位器用于感测用户的位置状态并传输至所述头戴显示器;
所述运动传感器用于感测用户的运动状态,并将所述运动状态传输至所述头戴显示器;
所述头戴显示器用于向用户展示虚拟场景,根据用户的所述位置状态和所述运动状态形成智能家居控制请求并传输至所述第二通信模块;
所述第二通信模块可与所述服务器信号连接,用于将所述智能家居控制请求传输至所述服务器。
优选地,所述服务器包括操作系统、Web服务器、应用服务器、数据库、分布式缓存服务、消息队列和服务器后台。
优选地,所述服务器用于接收所述全息智能网关传输的所述语音信息和深度图像以及所述虚拟现实设备传输的所述智能家居控制请求,通过基于卷积神经网络的图像分析模型处理所述深度图像得到人脸表情和用户年龄,根据所述人脸表情、用户年龄以及语音信息,通过基于机器学习的语音模型得到对应的音频信号、显示信息和控制信息。
本实用新型的有益效果如下:
本实用新型的智能家居控制系统中,虚拟现实设备可根据用户的运动状态形成智能家居控制请求,并将所述智能家居控制请求传输至所述服务器以对智能家居进行控制,本实用新型可解决虚拟现实设备阻断用户与真实世界的交互而导致用户在使用虚拟现实设备时无法控制智能家居的问题。同时,本实用新型基于用户的语音信息和深度图像等用户的状态进行全息图像显示,结合全息技术和人机交互技术针对用户的不同状态进行个性化定制。
附图说明
下面结合附图对本实用新型的具体实施方式作进一步详细的说明。
图1示出本实用新型一种智能家居控制系统一个具体实施例的示意图。
图2示出本实用新型一种智能家居控制系统一个具体实施例的工作流程图。
具体实施方式
为了更清楚地说明本实用新型,下面结合优选实施例和附图对本实用新型做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本实用新型的保护范围。
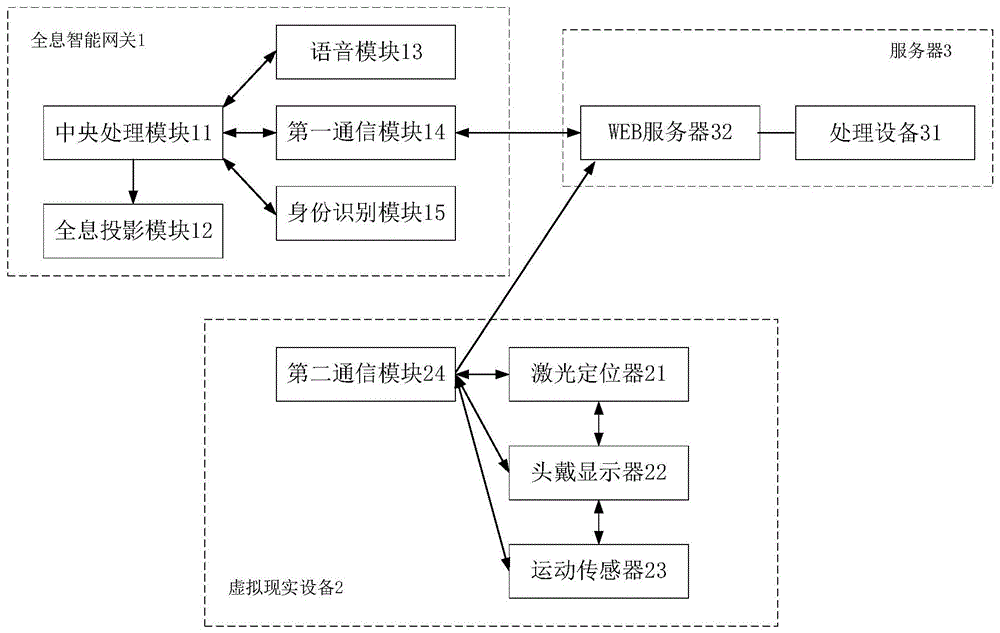
图1所出本实用新型一种智能家居控制系统一个具体实施例的示意图,本实施例中,家居控制系统包括虚拟现实设备2、全息智能网关1及服务器3。其中,所述全息智能网关1与智能家居和所述服务器3分别信号连接,全息智能网关1可采集用户的语音信息和深度图像传输至所述服务器3,并基于服务器3传输的显示信息显示全息影像、音频信号进行音频播放以及控制信息控制所述智能家居实现对应操作。所述虚拟现实设备2可根据用户的运动状态形成智能家居控制请求,并将所述智能家居控制请求传输至所述服务器3。所述服务器3可接收所述全息智能网关1传输的所述语音信息和深度图像以及所述虚拟现实设备2传输的所述智能家居控制请求,对所述语音信息、深度图像和智能家居控制请求处理得到对应的所述音频信号、所述显示信息和所述控制信息并传输至所述全息智能网关1。
本实用新型中的家居控制系统可结合全息技术和人机交互技术针对用户的不同状态进行个性化定制,家居控制器通过采集用户的语音信息和深度图像,并将语音信息和深度图像传输至服务器3,以使服务器3对用户的状态进行分析,可得到用户发出的家居控制指令、用户身份、用户表情以及用户动作等信息,生成或查找对应的音频信号、显示信息和家居控制信息并传输回全息智能网关1,全息智能网关1可根据显示信息向用户显示对应的全息图像,向用户传递家居控制的反馈信息。
在用户使用虚拟现实设备时,虚拟现实设备可实时感测用户的运动状态,形成与用户的运动状态对应的智能家居控制请求,传输至服务器3,服务器3处理接收的智能家居控制请求并处理得到智能家居的控制信息传输至全息智能网关1,全息智能网关1进一步可根据所述控制信息实现对智能家居的控制,由此,本实用新型可在用户使用虚拟现实设备的同时实现对智能家居的控制,解决虚拟现实设备阻断用户与真实世界的交互而导致用户在使用虚拟现实设备时无法控制智能家居的问题。
在优选地实施方式中,所述全息智能网关1可包括第一通信模块、中央处理模块、全息投影模块12、语音模块13以及身份识别模块。
所述中央处理模块可将所述显示信息传输至所述全息投影模块12,将所述音频信号传输至所述语音模块13以及将所述控制信息传输至所述第一通信模块。其中,中央处理模块可包括64位四核中央处理器等多线程CPU、存储器以及双核多媒体协处理器等处理设备31。中央处理模块主要用于处理后台云端服务器3发送的指令,同时,将指令传递给其他功能模块。其中,64位四核中央处理器主要用于处理后台云端服务器3的消息指令,并将指令进行多线程处理。存储器主要用于指令的缓存,提高指令的调度处理速度。
所述第一通信模块用于与所述服务器3和所述智能家居进行信号连接和传输,可将用户的语音信息和深度图像传输至所述服务器3,并接收所述服务器3传输的音频信号、显示信息和控制信息并传输至所述中央处理模块,以及将所述中央处理模块传输的控制信息传输至所述智能家居以使所述智能家居实现对应操作。其中,第一通信模块可包括ZigBee模块、红外模块、蓝牙模块和/或WiFi模块等。通过第一通信模块形成全息智能网关1与服务器3以及智能家居信息传输的通信网络。其中,ZigBee模块主要用于与智能家居进行通信,将全息智能网关1作为智能家居ZigBee网络中的汇聚节点,将中央处理模块的指令发送给终端的智能家居设备。WiFi模块主要用于与后台云端服务器3进行通信,用来获取云端服务器3发送的指令。红外模块主要用于将红外码转换为特定频率的红外信号,发送给红外终端智能家居设备,进行终端智能家居设备的控制。
所述全息投影模块12包括用于传输显示信息的多媒体接口、与所述多媒体接口连接的显示屏以及用于将显示屏的图像进行全息投影的光学投影组件,可采用现有的全息投影技术。其中,高清多媒体接口用于全息视频的输出,高清显示屏用于全息视频的播放,全息光学投影设备用于空气中的全息三维成像。
所述语音模块13可采集用户的语音信息并传输至所述中央处理模块以及播放所述音频信号。例如可通过扬声器播放音频信号向用户反馈智能家居的控制结果等信息。优选地,所述语音模块13可包括呈六脉环形阵列排布的多个扬声器,用于播放音频。进一步地,音频模块还可包括呈六脉环形阵列排布的多个麦克风,用于采集用户的音频信号。
所述身份识别模块可采集用户的深度图像并传输至所述中央处理模块。所述全息投影模块12可根据所述显示信息进行全息投影,其中所述显示信息包括智能家居状态信息、所述身份识别模块识别结果的反馈信息、所属语音模块13识别结果的反馈信息。优选地,所述身份识别模块可为与所述中央处理模块连接的深度摄像头。
具体的,如图2所示,在实现智能家居终端的控制上,全息智能网关1首先采集用户的语音命令,再将用户的语音命令反馈到后台云端服务器3,通过后台云端服务器3语料库的识别和筛选,接收云端服务器3发送的语音数据,通过扬声器设备将反馈的语音信息进行呈现,同时,全息智能网关1的中央处理模块在主线程外创建线程一,利用线程一将云端服务器3反馈的信息通过ZigBee通信模块发送给智能家居终端设备,以实现通过用户语音控制智能家居终端的功能。此外,全息智能网关1还负责用户的身份识别(包括人脸识别,面部表情识别,人物体态识别),全息内容的定制化呈现两个功能。在这两个功能中,全息智能网关1的中央处理模块利用多线程的方法解决线程冲突的问题。中央处理模块的主线程负责接收用户的语音指令,在接收到用户的语音指令后,中央处理模块利用WiFi传输模块将用户的语音指令发送给后台云端服务器3,云端服务器3进行语音指令的识别。基于交互技术的全息智能网关1服务系统的分级式多线程服务机制,如图2所示。采用这种优先级处理机制的优势是有效防止程序冲突与资源相互占用,不影响主程序的执行。全息智能网关1的语音交互功能优先级为最高,其次是智能家居控制功能,最后是基于图像识别的交互。这种按需求分配的多线程服务机制能够高效率的运用资源,保证全息智能网关1的运行。
在优选地实施方式中,云端服务器3还可采用基于深度学习的语音模型实现语音识别的功能。首先对目标语音输入进行预处理,利用语音模型对处理后的语音信号进行特征提取,通过语音的解码和搜索算法匹配相对应的文本数据,实现语音识别的功能。识别结束后,云端服务器3的处理设备31进行语料的筛选,并将匹配的语料暂存在云端服务器3的的缓存中。之后,云端服务器3对全息智能网关1发出打开深度摄像头的指令,全息智能网关1的中央处理模块接收到该指令后,主线程继续运行,并创建线程二,线程二主要用于打开深度摄像头,将深度摄像头记录的用户信息保存在全息智能网关1的内存中,并将该信息发送给云端服务器3。云端服务器3接收到该信息后,对用户的身份信息进行分析筛选,并在音轨库中筛选合适的音轨。
在优选地实施方式中,所述虚拟现实设备2可包括头戴显示器22、激光定位器21、运动传感器23以及第二通信模块24,第二通信模块24可以包括WIFI或蓝牙等类型的通信组件。其中,头戴显示器22可采用HMD高清头戴显示器22,HMD高清头戴显示器22主要用于虚拟沉浸式场景的显示。激光定位器21用于获取头戴式显示器以及运动传感器23在空间中的位置。运动传感器23可采用6Dof运动传感器23。运动传感器23主要用于进行用户与沉浸式虚拟场景中物体的交互,在本系统中主要用来进行在虚拟场景中进行真实世界家居的控制。
其中,所述激光定位器21可感测用户的位置状态并传输至所述头戴显示器22。所述运动传感器23可感测用户的运动状态,并将所述运动状态传输至所述头戴显示器22。所述头戴显示器22可向用户展示虚拟场景,根据用户的所述位置状态和所述运动状态形成智能家居控制请求并传输至所述第二通信模块24。所述第二通信模块24可与所述服务器3信号连接,用于将所述智能家居控制请求传输至所述服务器3。
优选地,所述服务器3可包括WEB服务器23和处理设备31,其中处理设备31可包括但不限于操作系统、应用服务器、数据库、分布式缓存服务、消息队列和服务器后台等,以对智能家居控制器和虚拟现实设备2传输的信息进行处理。服务器3主要用于储存全息视频内容素材以及身份识别(包括人脸识别,面部表情识别,人物体态识别)的算法处理。
所述服务器3可接收所述全息智能网关1传输的所述语音信息和深度图像以及所述虚拟现实设备2传输的所述智能家居控制请求,通过基于卷积神经网络的图像分析模型处理所述深度图像得到人脸表情和用户年龄,根据所述人脸表情、用户年龄以及语音信息,通过基于机器学习的语音模型得到对应的音频信号、显示信息和控制信息。
具体的,云端服务器3将音轨信息与语料信息相结合,将得到的反馈信息发送给全息智能网关1,全息智能网关1利用扬声器给出用户定制化的音频反馈。在用户身份信息的分析和筛选中,云端服务器3采用基于卷积神经网络的图像分析模型实现人脸表情识别、年龄识别的功能。首先基于目标检测网络模型进行人脸部位的检测,检测到人脸部位后对人脸部位进行特征点提取,分别输入到人脸表情识别模型和人脸年龄神经网络识模型进行目标人物的表情与年龄的识别。利用深度摄像头的深度信息建立人体行为识别模型,通过人工神经网络对人体骨骼点的模态与相对位置等信息进行特征提取进行模型的训练。在定制化的全息内容呈现上,在全息智能网关1接收到用户的语音命令之后,通过主线程利用WiFi传输模块将用户的语音指令发送给后台云端服务器3,云端服务器3进行语音指令的识别。识别结束后,云端服务器3的中央处理器进行语料的筛选,并将匹配的语料暂存在云端服务器3的的缓存中。之后,云端服务器3对全息智能网关1发出打开深度摄像头的指令,全息智能网关1的中央处理模块接收到该指令后,主线程继续运行,并创建线程二,线程,打开深度摄像头,将深度摄像头记录的用户信息保存在全息智能网关1的内存中,并将该信息发送给云端服务器3。云端服务器3接收到该信息后,对用户的身份信息进行分析筛选,在音轨库中筛选合适的音轨,在全息视频素材库中筛选对应的全息视频素材。最后,云端服务器3将音轨信息与语料信息相结合,将得到的音频反馈信息与全息视频素材发送给全息智能网关1,全息智能网关1利用扬声器给出用户定制化的音频与全息视频反馈。
沉浸式虚拟现实系统主要在于解决虚拟现实系统用户与真实世界中的物体隔离的问题。可虚拟场景中设置相应的触发器,利用用户的运动传感器23与触发器的碰撞检测触发器的触发状态,当相应触发器被触发时,虚拟现实系统头戴式显示器的中央处理器利用头戴式显示器中的WiFi模块,给云端服务器3发送请求,云端服务器3接收到请求后,将请求转发给全息智能网关1,全息智能网关1通过通信模块采用相应的通信协议对相应智能家居终端发送命令,实现在虚拟现实系统中控制真实世界智能家居终端的功能。
显然,本实用新型的上述实施例仅仅是为清楚地说明本实用新型所作的举例,而并非是对本实用新型的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本实用新型的技术方案所引伸出的显而易见的变化或变动仍处于本实用新型的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!