一种基于自组织映射的机器人群体协同主动感知方法与流程
本发明属于人工智能领域,是机器学习算法和机器人环境目标探测技术相结合的应用,特别涉及一种基于自组织映射的机器人群体协同主动感知方法。
背景技术:
现阶段智能体在环境中的目标感知技术主要是被动地进行环境探测、目标识别与跟踪、实时定位与地图构建等,所涉及的智能体数目多为单个。另一方面,机器人群体的研究领域较多的集中在机器人群体编队、机器人之间的通信机制、多机器人之间的任务分配等方面,在多机器人协同完成任务的方面较少有成果发现。随着人工智能技术的飞速发展,以机器学习为代表的智能算法越来越多地应用于机器人领域。然而,机器学习及当下较为热门的深度学习主要关注于文本、图像、视频等数据的处理;强化学习更多的是训练机器人让其通过不断的试错来进行与环境信息地交互,但这一过程耗时长,运算复杂度较大。当场景较大,机器人需要与环境交互的信息量较多的时候,机器人不能很好地通过强化学习的方法来进行主动目标感知。
路径规划在很多领域有着广泛的应用,因此其技术方法也较为成熟。传统的路径规划算法有模拟退火算法、人工势场法等;基于智能仿生学的蚁群算法、遗传算法等。神经网络算法是人工智能领域中的一种应用及其广泛算法,它主要模拟动物神经网络行为,进行分布式并行信息处理。但它在路径规划中的应用却并不成功,因为路径规划中复杂多变的环境很难用数学公式进行描述,如果用神经网络去预测学习样本分布空间以外的点,其效果难以达到预期。
自组织映射网络是一种神经网络算法,能够通过其输入变量学会检测其规律性和输入变量相互之间的关系,并且根据这些输入变量的信息自适应调整网络,使网络以后的响应与输入变量相适应,不但能学习输入变量的分布情况,还可以学习输入变量的拓扑结构。现阶段主要应用于文本、视频等数据的分类。在路径规划中虽然也有使用,但是针对的是单目标的路径规划。
技术实现要素:
为了解决上述问题,本发明目的是提供一种运算复杂度低且能应用于大场景信息的多机器人协同主动感知方法。基于机器人群体在环境中主动探测,目的是最大限度地收集目标信息,观测点的选择影响最终的信息采集量,因此本发明将机器人群体协同主动感知的问题转化为多目标路径规划的数学模型,以实现机器人群体在最终生成的观测路径上获取到最多的环境信息量。
为了实现上述目的,本发明采用的技术方案是:
本发明提出的一种基于自组织映射的机器人群体协同主动感知方法,
所述机器人群体内各机器人的配置均相同,各机器人上分别搭载有激光雷达与深度相机,其特征在于,所述机器人群体协同主动感知方法包括以下步骤:
(1)参数设置,包括机器人群体的旅行预算时间阈值,自组织映射网络的迭代次数;根据待感知区域设置机器人群体的多个目标点;
(2)建立各机器人的运动学模型并利用该运动学模型进行相应机器人航迹上的所有路径点推算,各机器人的所有路径点构成相应机器人的路径点序列;
(3)在待感知环境中,为每个机器人随机选择一个初始位置,各机器人按照步骤(2)推算的航迹进行首轮探测,探测过程中通过多旅行商问题模型对各机器人的航迹进行修正,形成探测时间最短的航迹并得到对应的路径点序列,经过首轮探测后机器人回到各自的初始位置,分别形成一个闭环路径;在首轮探测过程中,将深度相机收集的图像数据较为丰富的位置作为各机器人的观测点序列,各观测点序列由多个观测点构成,一个目标点对应一个观测点序列,机器人通过各观测点采集相应目标点的特征信息;
(4)对机器人群体,首轮探测后通过深度相机与激光雷达随机确认一个未被感知的目标点作为当前目标点,机器人各自从与当前目标点对应的观测点序列中任意选择一个观测点作为目标观测点,选择到所述目标观测点的旅行预算时间与实际消耗时间比值最小的机器人作为获胜机器人;通过自组织映射网络算法,选择该获胜机器人所在的路径点序列中与所述目标观测点欧氏距离最短的路径点作为获胜路径点,通过自组织映射网络算法的迭代计算,获胜路径点向目标观测点不断靠近,同时保持各路径点之间的拓扑结构不变,直至获胜路径点与目标观测点之间的距离达到设定阈值或者旅行预算时间耗尽,迭代结束,得到包含有目标观测点的闭环路径,获胜机器人按照该闭环路径利用深度相机和激光雷达进行当前目标点探测;
(5)不断重复步骤(4),遍历所有目标点,探测结束。
本发明有如下优点:
(1)本发明把信息量较大的场景中机器人群体协同感知问题转化为多目标路径规划的多旅行商(multitravelingsalesmanproblem,mtsp)数学模型,极大地简化了问题的复杂度,可以放弃建立高纬度的马尔可夫决策表而转化为遍历多个目标点的闭环路径问题;
(2)本发明采用自组织映射神经网络(selforganizingmaps,som)算法进行机器人路径点的迭代处理,运算复杂度低,同时som的神经元竞争特性避免了机器人群体在探索目标时陷入局部最优解,使其能在感知过程中不满足于现有的目标点,从而不断探索新的区域;
(3)本发明克服了现阶段只有单机器人进行感知任务的缺陷,并扩大了多机器人的研究领域,为主动感知方案在机器人群体方面的应用提供了一种新的思路。
附图说明
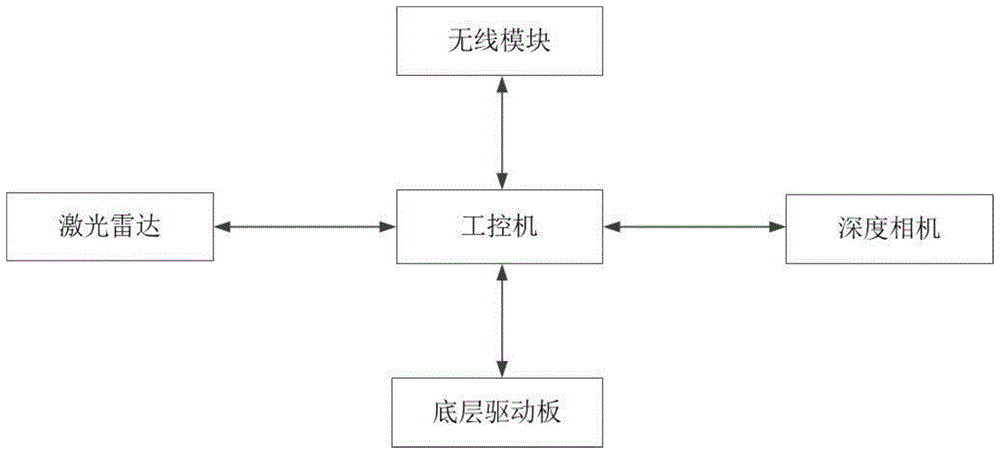
图1为本发明方法实施例所涉及的机器人的结构示意图。
具体实施方式
下面结合附图及实施例对本发明作进一步说明。
本发明提出的一种基于自组织映射的机器人群体协同主动感知方法,图1是本发明所涉及的机器人群体内各机器人的组成部分,各机器人配置均相同,其上均分别搭载有底层驱动板、工控机、无线模块、深度相机和激光雷达。其中,机器人通过深度相机来感知周围环境,激光雷达进行辅助探测,深度相机和激光雷达同步采集,工控机作为机器人的“大脑”,内装有ubuntu16.04操作系统,搭配ros-kinetic版本,进行数据处理和控制机器人,底层驱动板控制底层电机的工作,给机器人提供前进的动力。本实施例的机器人中,采用turtlebot3移动机器人作为主体,具有三个全向驱动轮,激光雷达采用思岚公司的rplidara2,深度相机采用interrealsense,工控机选择h61dvr型号主板,底层驱动板选用arduino扩展板,使用zigbee无线模块进行数据传输。
本发明提出的一种基于自组织映射的机器人群体协同主动感知方法,包括以下步骤:
(1)参数设置,包括机器人群体的旅行预算时间阈值,自组织映射网络的迭代次数;根据待感知区域设置机器人群体的多个目标点;
(2)建立各机器人的运动学模型并利用该运动学模型进行相应机器人航迹上的所有路径点推算,各机器人的所有路径点构成相应机器人的路径点序列;
具体地,本实施例采用的机器人的运动学模型为:
其中,v1、v2、v3是机器人三个驱动轮的速度,d是机器人底盘的半径;以机器人底盘圆心为原点,机器人底盘所在平面上任意互为垂直关系的两个方向作为x、y轴建立坐标系,旋转轴与x、y轴满足右手螺旋定则,vx、vy、vθ分别是机器人驱动轮速度在x轴、y轴和旋转轴方向的速度分量;除本实施例所示运动模型外,采用其他常规的运动模型本发明方法同样适用;
根据上述机器人运动模型,通过下式推算机器人航迹:
其中,x,y,θ为机器人底盘当前位姿,dx,dy,dθ分别为x方向位移增量、y方向位移增量、转向角增量,εx,εy,εθ分别为dx,dy,dθ的误差。
根据速度估计迭代最近点(velocityestimationiterativeclosestpoint,vicp)方法对推算出的机器人航迹的运动畸变进行去除,矫正后的机器人位姿为:
其中,si表示在深度相机或激光雷达第i帧时刻机器人的位姿;δt表示深度相机或激光雷达相邻两帧之间的时间间隔,深度相机和激光雷达同步采集且采集频率相同;dθ表示机器人的转向角增量;n表示深度相机或激光雷达第i帧时刻采集的图像信息内的像素点总数,j表示第i帧时刻采集的图像信息内的像素点编号;vi表示在深度相机或激光雷达第i帧时刻的机器人速度,计算公式如下:
其中,ti表示深度相机或激光雷达第i帧时刻的机器人位姿矩阵,表达式如下:
(3)在待感知环境中,为每个机器人随机选择一个初始位置,各机器人按照步骤(2)推算的航迹进行首轮探测,探测过程中通过多旅行商问题模型对各机器人的航迹进行修正,形成探测时间最短的航迹并得到对应的路径点序列,经过首轮探测后机器人回到各自的初始位置,分别形成一个闭环路径;在首轮探测过程中,将深度相机收集的图像数据较为丰富的位置作为各机器人的观测点序列,各观测点序列由多个观测点构成,一个目标点对应一个观测点序列,机器人通过各观测点采集相应目标点的特征信息(该特征信息即通过深度相机和激光雷达采集的图像信息);
其中,操作人员可随机选择每个机器人的初始位置,其选择不受目标点位置距离远近等因素的限制,但是结束点的位置必须和起始点重合,使各机器人的路径分别成为一个闭环;通过深度相机和激光雷达为目标点附近设置一系列观测区域,观测点位于观测区域的内部,机器人的路径点只要在任意一个观测区域内部即可认为观测到目标;路径点序列之间的路径生成原则遵从dubins曲线,以此保障路径点之间的最短距离。在通过多旅行商问题模型解决多机器人协同主动感知时,其原理是:将多个机器人看作不同的旅行商,将待感知的目标看作旅行商待访问的城市,最终目标是让多个旅行商遍历所有的城市,从而将多机器人协同主动感知问题转化为了多旅行商问题来进行路径规划。
(4)对机器人群体,首轮探测后通过深度相机与激光雷达随机确认一个未被感知的目标点作为当前目标点,机器人各自从与当前目标点对应的观测点序列中任意选择一个观测点作为目标观测点,选择到所述目标观测点的旅行预算时间与实际消耗时间比值最小的机器人作为获胜机器人,表达式如下:
其中,rr表示最终获胜的机器人,角标r表示该获胜机器人的编号;cq表示编号为q的机器人的旅行预算时间,bq表示编号为q的机器人的旅行实际消耗时间,q=1,2,…,n,n为机器人的总个数;
通过自组织映射网络算法,选择该获胜机器人所在的路径点序列中与所述目标观测点欧氏距离最短的路径点作为获胜路径点,通过自组织映射网络算法的迭代计算,获胜路径点向目标观测点不断靠近,同时保持各路径点之间的拓扑结构不变,直至获胜路径点与目标观测点之间的距离达到设定阈值或者旅行预算时间耗尽,迭代结束,得到包含有目标观测点的闭环路径,获胜机器人按照该闭环路径利用深度相机和激光雷达进行当前目标点探测,其中,深度相机采集机器人周围的环境,生成深度点云数据,激光雷达进行机器人与目标点的距离测量,同时辅助地进行环境测量工作;
本步骤中,利用自组织映射网络算法得到包含有目标观测点的闭环路径的迭代计算,具体实现过程如下:
(4.1)设定变量
将步骤(3)得到的获胜机器人路径点序列作为自组织映射网络的输入变量x=[x1,x2,…,xm],每个输入变量均为m维向量;设定自组织映射网络的学习率η;
设定各输入变量与相应输出变量(对应于一个神经元)之间的权值向量为ωl(k)[ωl1(k),ωl2(k),…,ωlp(k)],其中l为当前输入变量的元素编号,l=1,2,…,m;p表示输出变量的维度,k为当前与l对应的输出变量的元素,
(4.2)对权值向量使用[1,10]中的随机值进行初始化,并对输入变量和权值向量均进行归一化处理:
其中,||x||、||ωl(k)||分别为输入变量和权值向量的欧几里得范数。
(4.3)将随机抽取的多个输入变量输入自组织映射网络,将输入变量与权值向量的内积值最大的神经元作为输出变量。由于输入变量与权值向量均已归一化,因此求内积最大相当于求欧氏距离最小:
d=||x-ωl(k)||
将欧氏距离d最小的神经元,记为获胜神经元。
(4.4)对获胜神经元拓扑邻域内的其他神经元,使用konhonen规则对权值向量进行更新:
ωl(k+1)=ωl(k)+η(x-ωl(k))
(4.5)更新自组织映射网络的学习率η及拓扑邻域,并对更新后的权值向量再次进行归一化。其中,学习率和拓扑邻域大小的调整按排序阶段和调整阶段两步来进行:在排序阶段,随着迭代的进行,学习率从0.9下降至0.02,拓扑邻域大小逐渐减少,权值向量根据输入变量进行调整,使权值向量的拓扑结构与更新后输入变量的拓扑结构相适应;在调整阶段,学习率从0.02以更为缓慢的速率下降,拓扑邻域大小保持不变,权值向量在排序阶段确定的拓扑结构上做调整,保证学习的稳定性。
(4.6)判断迭代次数是否达到步骤(1)中预设的最大值,若没有达到最大迭代次数,则转到步骤(4.3),否则迭代结束,输出获胜机器人更新后的路径点序列。
本步骤所采用的自组织映射网络属于无监督学习中聚类算法的一种,无需教师信号,在训练的过程中进行多轮迭代即可;该网络的训练不需要大量的样本集和测试数据,实时性较好;网络迭代的性能可根据实际需要调整学习率。
(5)不断重复步骤(4),遍历所有目标点,探测结束。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!