基于集成即时学习的污水处理过程自适应预测控制方法与流程
本发明涉及污水处理过程控制技术领域,特别是涉及一种基于集成即时学习的污水处理过程自适应预测控制方法。
背景技术:
水污染问题作为现今地球上最严峻的问题,给人类工业污水处理技术的发展带来了极大的挑战,污水处理过程具有如下特点:生化反应复杂,受季节天气影响水质波动较大,各状态变量耦合,是一个时滞非线性的过程。由于其非线性及生化反应复杂性,机理模型不能精确描述,从而很难进行稳定控制。在污水处理过程中有两个重要底层控制回路,一个是第五分区溶解氧浓度控制,其操作变量是第五分区氧气转换系数;一个是第二分区硝态氮浓度控制,其操作变量是污泥内回流量。污水处理过程中,对第五分区溶解氧浓度和第二分区硝态氮浓度控制直接影响出水水质,并且影响整个运行过程的能量消耗及经济成本。为了保证出水水质稳定达标,过程平稳运行,有必要对第五分区溶解氧浓度加以有效控制。
公开号为cn103771582a的专利“污水处理的曝气控制方法”,利用bp神经网络作为预测模型同时结合多种控制方法,提出一种污水处理的曝气控制方法,但是该方法不能针对异常数据进行实时调整,无法解决因数据异常等导致的模型失配问题。公开号为cn103197544a的专利“基于非线性模型预测的污水处理过程多目标控制方法”,利用rbf神经网络作为预测模型结合预测控制方法,但是该方法针对不同工况无法做出自适应调整预测模型,从而导致在工况改变时控制效果可能达不到理想效果。
预测控制被广泛应用于污水处理过程,由于污水处理过程是一个非线性过程,因此需要采用一些机器学习方法建立非线性模型进行预测控制。在实际污水处理过程中,会产生大量离线和在线测量数据,如何充分利用这些数据信息对控制器参数进行实时调整,也是整个污水处理过程中的关键问题。而且受检测仪表和变送器等装置的故障以及其他异常干扰对测量数据的影响,采集数据经常出现数据异常情况,如:数据值大于实际情况或者出现数据缺失现象。目前在污水处理控制过程中还没有较好的相关解决方案。
技术实现要素:
针对现有技术存在的问题,本发明提供一种基于集成即时学习的污水处理过程自适应预测控制方法,能够对污水处理过程进行自适应稳定控制,提高离线和在线输入输出测量数据的利用率,有效抑制输入输出干扰及异常数据对控制的影响,提高污水处理过程预测控制的精度和鲁棒性。
本发明的技术方案为:
一种基于集成即时学习的污水处理过程自适应预测控制方法,所述污水处理过程采用常规污水处理工艺,所述常规污水处理工艺的生化反应池部分包括厌氧区第一分区、厌氧区第二分区、厌氧区第三分区、好氧区第四分区、好氧区第五分区,所述好氧区第五分区安装有第五分区控制器、第五分区测量设备、第五分区氧气量调节阀,所述第五分区测量设备、第五分区氧气量调节阀均与plc系统电连接,所述plc系统通过通讯总线连接到上位机,其特征在于,包括下述步骤:
步骤1:数据采集、预处理及初始化:
步骤1.1:从污水处理过程中选取第五分区溶解氧浓度作为被控量,并选取第五分区氧气转换系数作为控制量,采集污水处理过程历史数据;所述污水处理过程历史数据包括第i时刻的被控量y(i)、控制量u(i),i∈{1,2,...,i};
步骤1.2:对污水处理过程历史数据进行预处理;
步骤1.3:确定局部预测模型为y(t)=f(x(t)),并利用污水处理过程历史数据构造历史数据库为d={(xi,yi),i=1,2,...,i};其中,f(·)为非线性映射,x(t)=[y(t-1),u(t),u(t-1)]t为局部预测模型的输入,y(t)为局部预测模型的输出,t为时刻;i为历史数据库容量,xi=x(i)=[y(i-1),u(i),u(i-1)]t为输入变量,yi=y(i)为输出变量;
步骤2:进行集成即时学习建模:
步骤2.1:构造查询回归向量:根据当前工作时刻t,采集上一时刻的被控量y(t-1)、控制量u(t-1),构造当前工作时刻t的查询回归向量xt=x(t)=[y(t-1),u(t),u(t-1)]t;
步骤2.2:选取最优相似学习子集:
步骤2.2.1:定义n种相似度指标,计算查询回归向量xt与历史数据库中数据向量xi之间的第n种相似度为sn(xt,xi);其中,n∈{1,...,n};
步骤2.2.2:在每种相似度下,均查询历史数据库中与xt最相似的k个xi,组成相似学习子集{(xi,yi),i=1,2,...,k},k∈[kmin,kmax],从而共有(kmax-kmin+1)个相似学习子集;
步骤2.2.3:在每种相似度下,均计算每个相似学习子集的留一法交叉验证均方误差为
其中,mseloo(k)为对应近邻数为k的留一法交叉验证均方误差;
步骤2.2.4:在每种相似度下,均从(kmax-kmin+1)个相似学习子集中选择留一法交叉验证均方误差最小的相似学习子集作为最优相似学习子集{(xi,yi),i=1,2,...,kbest},得到第n种相似度下的最优相似学习子集subn(x,y)={(xi,yi),i=1,2,...,kn,best},n=1,...,n;
步骤2.3:处理异常数据:在每种相似度下,根据最优相似学习子集,计算平均数据向量为
步骤2.4:进行局部arx建模:将第n种相似度下的最优相似学习子集subn(x,y)作为训练集,得到第n个预测模型
其中,
步骤3:对集成预测模型进行滚动优化控制:
步骤3.1:计算集成预测模型的np步预测输出并对预测输出进行在线校正,得到校正后的np步预测输出为
其中,
步骤3.2:根据被控量的设定期望值ysp建立参考轨迹方程,使输出y(t)能够平滑过渡到设定期望值ysp;所述参考轨迹方程为
其中,yr(t+j)为t+j时刻的被控量参考值,η为柔化系数,0<η<1;
步骤3.3:构架污水处理过程预测控制优化模型为
s.t.umin≤u(t+j-1)+δu(t+j)≤umax
其中,j为优化控制性能指标,np为预测步长,nc为控制步长,u(t+j)为t+j时刻的控制量,δu(t+j)为t+j时刻的控制量增量,ry和ru均为加权系数,umin、umax分别为控制量约束的下限、上限;
步骤3.4:采用序贯二次规划算法求解所述污水处理过程预测控制优化模型,得到使优化控制性能指标j最小的控制量增量δu*(t),进而得到最优控制量u*(t)=u(t-1)+δu*(t);
步骤4:上位机将最优控制量u*(t)发送给plc系统,plc系统调节第五分区氧气量调节阀,使第五分区氧气转换系数达到最优控制量,然后采集最新一组污水处理过程测量数据u(i),y(i),进行与步骤1中相同的预处理后,更新历史数据库。
所述步骤1.2中,所述预处理包括滤波处理和归一化处理;所述滤波处理包括采用噪声尖峰滤波算法剔除污水处理过程中的噪声尖峰跳变数据;所述归一化处理包括对滤波处理后的污水处理过程历史数据进行归一化处理。
所述步骤2.2.1中,n=2;
利用基于空间的夹角和距离的k-vnn方法,计算s1(xt,xi)=σ·exp(-dti)+(1-σ)cos(αti);dti、cos(αti)分别为xt与xi之间的距离相似性、角度相似性,σ为权重参数,dti=||xi-xt||,
利用基于互信息熵的欧式加权距离方法,计算s2(xt,xi)=exp(-d(xt,xi)2);
其中,sn(xt,xi)∈[0,1],sn(xt,xi)越接近1表示xt与xi越相似。
所述步骤2.2.1中,通过互信息熵来确定权重向量,包括:
基于k近邻熵估计,计算历史数据库中输入变量xi=[xi1,...,xid,...,xim]t中子变量xid与输出变量yi之间的互信息为
计算xi,yi的互信息总和为
计算权重
所述步骤2.4中,采用信息熵法确定ωn,包括下述步骤:
步骤2.4.1:计算第n个预测模型在第k时刻的相对误差为
其中,yk为第k时刻的实际输出;
步骤2.4.2:计算第n个预测模型在第k时刻的相对误差的比重为
步骤2.4.3:计算第n个预测模型的熵值为
步骤2.4.4:计算第n个预测模型的相对误差序列的变异程度为dn=1-en;
步骤2.4.5:计算第n个预测模型的权重为
本发明的有益效果为:
(1)本发明在两种不同的相似度指标下,通过即时学习方法,实时查询历史数据库中的相似数据样本,选取最优相似学习子集作为训练集得到两组预测模型并通过加权集成得到集成预测模型,将即时学习与预测控制相结合,能够自适应地根据污水运行过程时变的工况为系统在线建立当前工作点的局部预测模型,避免了离线全局建模方法的局限性,有效解决了预测控制中预测模型的在线更新问题。
(2)本发明通过加权集成得到的集成预测模型能够更真实地反映系统的非线性关系,预测精度更高,根据得到的最优控制量对污水处理过程进行控制,能够提高污水处理底层回路控制的稳定性,给污水处理厂操作人员提供良好的控制参考依据,从而保证污水处理出水水质稳定达标。
(3)本发明根据采集的污水处理过程历史数据构造历史数据库,基于历史数据库进行建模及优化控制,能够重复利用有用数据样本,大大提高了离线和在线输入输出测量数据的利用率。
(4)本发明基于即时学习能够有效查询污水处理过程产生的大量数据信息,不断根据最新的工况数据即时选取最优相似学习子集并对异常数据进行处理,更新预测模型参数,在每一个控制时刻建立新的局部预测模型,不保留旧模型参数,从而过去时刻出现的干扰不会影响当前时刻局部预测模型的预测准确性,能够有效抑制输入和输出干扰及异常数据对控制器的不良影响,提高控制器的鲁棒性、自适应能力和稳定性。
附图说明
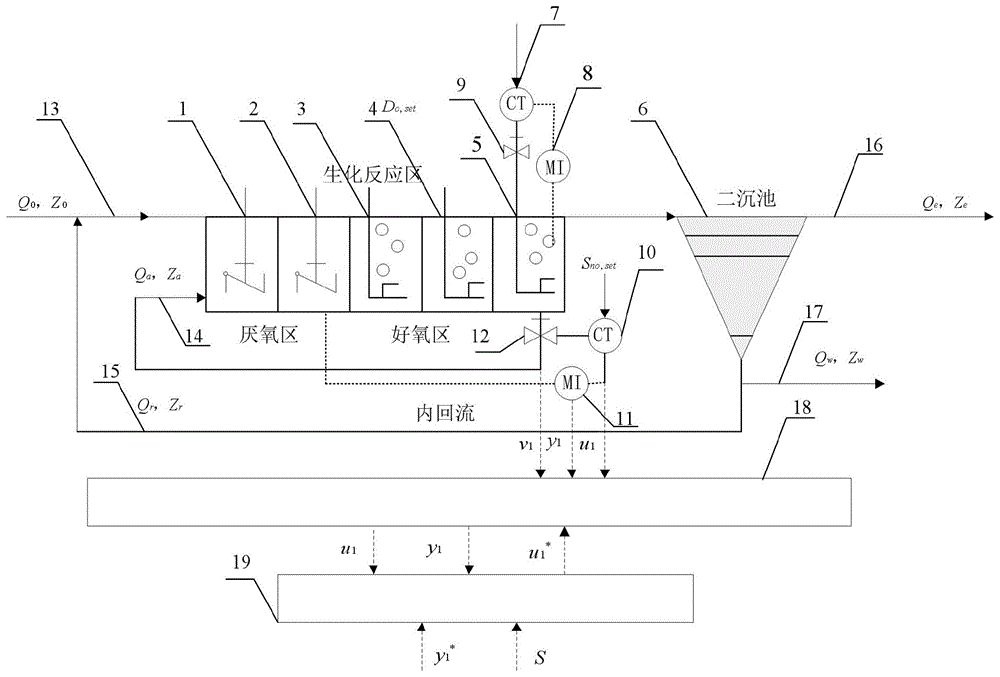
图1为本发明具体实施方式中污水处理过程的工艺图;
图2为本发明基于集成即时学习的污水处理过程自适应预测控制方法的流程图;
图3为本发明具体实施方式中集成即时学习建模的流程图;
图4为本发明具体实施方式中不同时刻更改不同设定期望值时被控量的控制效果图;
图5为本发明具体实施方式中不同时刻更改不同设定期望值时控制量的变化曲线图;
图6为本发明具体实施方式中不同时刻加入输入干扰时被控量的控制效果图;
图7为本发明具体实施方式中不同时刻加入输入干扰时控制量的变化曲线图;
图8为本发明具体实施方式中不同时刻加入输出干扰时被控量的控制效果图;
图9为本发明具体实施方式中不同时刻加入输出干扰时控制量的变化曲线图;
图10为本发明具体实施方式中不同时刻既加入输入干扰又加入输出干扰时被控量的控制效果图;
图11为本发明具体实施方式中不同时刻既加入输入干扰又加入输出干扰时控制量的变化曲线图;
图中,1-厌氧区第一分区,2-厌氧区第二分区,3-厌氧区第三分区,4-好氧区第四分区,5-好氧区第五分区,6-二沉池,7-第五分区控制器,8-第五分区测量设备,9-第五分区氧气量调节阀,10-第二分区控制器,11-第二分区测量设备,12-第二分区回流量调节阀,13-入水组分及入水流量,14-内回流及内回流组分,15-外回流及外回流组分,16-出水流量及出水组分,17-污泥流量及污泥组分,18-plc系统,19-上位机。
具体实施方式
下面将结合附图和具体实施方式,对本发明作进一步描述。
本发明基于集成即时学习对污水处理过程进行自适应预测控制。所述污水处理过程采用如图1所示的常规污水处理工艺。所述常规污水处理工艺涉及污水处理厂的初沉池及二沉池,污水处理对象安装了常规测量变送系统。所述常规污水处理工艺的生化反应池部分包括厌氧区第一分区1、厌氧区第二分区2、厌氧区第三分区3、好氧区第四分区4、好氧区第五分区5,所述好氧区第五分区5安装有第五分区控制器7、第五分区测量设备8、第五分区氧气量调节阀9,所述第五分区测量设备8、第五分区氧气量调节阀9均与plc系统18电连接,所述plc系统18通过通讯总线连接到上位机19。此外,常规污水处理工艺还涉及二沉池6、第二分区控制器10、第二分区测量设备11、第二分区回流量调节阀12、入水组分及入水流量13、内回流及内回流组分14、外回流及外回流组分15、出水流量及出水组分16、污泥流量及污泥组分17。其中,流量计、温度计等常规测量仪表和流量调节阀等执行机构安装于各个反应池中,底层plc系统连接常规测量仪表和执行机构,并通过通讯总线连接上位机。图1中,
本实施例中,采用c#高级语言实现本发明方法在软件系统中的编写,该软件系统可实现数据显示、软测量结果显示以及设定被控量期望输出值等功能,可以方便地让操作人员对污水处理系统进行实时优化控制。另外,计算机系统上装有opc通讯软件负责与下位机以及数据采集装置进行数据双向通讯。
本发明利用实际污水处理厂现有常规测量设备采集的污水处理过程数据作为优化控制需要的数据,将采集后的数据经过预处理之后,利用本发明所提供的方法对污水处理过程进行优化控制,为污水处理过程的优化操作和稳定顺行运行提供参考。
本发明的基于集成即时学习的污水处理过程自适应预测控制方法,如图2所示,包括下述步骤:
步骤1:数据采集、预处理及初始化:
步骤1.1:从污水处理过程中选取第五分区溶解氧浓度作为被控量,并选取第五分区氧气转换系数作为控制量,采集污水处理过程历史数据;所述污水处理过程历史数据包括第i时刻的被控量y(i)、控制量u(i),i∈{1,2,...,i};
步骤1.2:对污水处理过程历史数据进行预处理;
步骤1.3:确定局部预测模型为y(t)=f(x(t)),并利用污水处理过程历史数据构造历史数据库为d={(xi,yi),i=1,2,...,i};其中,f(·)为非线性映射,x(t)=[y(t-1),u(t),u(t-1)]t为局部预测模型的输入,y(t)为局部预测模型的输出,t为时刻;i为历史数据库容量,xi=x(i)=[y(i-1),u(i),u(i-1)]t为输入变量,yi=y(i)为输出变量。
本实施例中,所述预处理包括滤波处理和归一化处理;所述滤波处理包括采用噪声尖峰滤波算法剔除污水处理过程中的噪声尖峰跳变数据;所述归一化处理包括对滤波处理后的污水处理过程历史数据进行归一化处理。
步骤2:进行如图3所示的集成即时学习建模:
步骤2.1:构造查询回归向量:根据当前工作时刻t,采集上一时刻的被控量y(t-1)、控制量u(t-1),构造当前工作时刻t的查询回归向量xt=x(t)=[y(t-1),u(t),u(t-1)]t。
其中,u(t)是需要求解的当前时刻控制量,所以在计算相似度时不考虑该项,同时也不考虑xt中的异常数据项。
步骤2.2:选取最优相似学习子集:
步骤2.2.1:定义n种相似度指标,计算查询回归向量xt与历史数据库中数据向量xi之间的第n种相似度为sn(xt,xi);其中,n∈{1,...,n};
步骤2.2.2:在每种相似度下,均查询历史数据库中与xt最相似的k个xi,组成相似学习子集{(xi,yi),i=1,2,...,k},k∈[kmin,kmax],从而共有(kmax-kmin+1)个相似学习子集;
步骤2.2.3:在每种相似度下,均计算每个相似学习子集的留一法交叉验证均方误差为
其中,mseloo(k)为对应近邻数为k的留一法交叉验证均方误差;
步骤2.2.4:在每种相似度下,均从(kmax-kmin+1)个相似学习子集中选择留一法交叉验证均方误差最小的相似学习子集作为最优相似学习子集{(xi,yi),i=1,2,...,kbest},得到第n种相似度下的最优相似学习子集subn(x,y)={(xi,yi),i=1,2,...,kn,best},n=1,...,n。
本实施例中,所述步骤2.2.1中,n=2;
利用基于空间的夹角和距离的k-vnn方法,计算s1(xt,xi)=σ·exp(-dti)+(1-σ)cos(αti);dti、cos(αti)分别为xt与xi之间的距离相似性、角度相似性,σ为权重参数,dti=||xi-xt||,
利用基于互信息熵的欧式加权距离方法,计算s2(xt,xi)=exp(-d(xt,xi)2);
其中,sn(xt,xi)∈[0,1],sn(xt,xi)越接近1表示xt与xi越相似。
本实施例中,所述步骤2.2.1中,通过互信息熵来确定权重向量,包括:
基于k近邻熵估计,计算历史数据库中输入变量xi=[xi1,...,xid,...,xim]t中子变量xid与输出变量yi之间的互信息为
计算xi,yi的互信息总和为
计算权重
步骤2.3:处理异常数据:在每种相似度下,根据最优相似学习子集,计算平均数据向量为
步骤2.4:进行局部arx建模:将第n种相似度下的最优相似学习子集subn(x,y)作为训练集,得到第n个预测模型
其中,
本实施例中,所述步骤2.4中,采用信息熵法确定ωn,包括下述步骤:
步骤2.4.1:计算第n个预测模型在第k时刻的相对误差为
其中,yk为第k时刻的实际输出;
步骤2.4.2:计算第n个预测模型在第k时刻的相对误差的比重为
步骤2.4.3:计算第n个预测模型的熵值为
步骤2.4.4:计算第n个预测模型的相对误差序列的变异程度为dn=1-en;
步骤2.4.5:计算第n个预测模型的权重为
步骤3:对集成预测模型进行滚动优化控制:
步骤3.1:计算集成预测模型的np步预测输出并对预测输出进行在线校正,得到校正后的np步预测输出为
其中,
其中,为了防止模型失配或环境干扰对控制器的影响,反馈校正采用对未来的误差做出预测并加以补偿。
步骤3.2:根据被控量的设定期望值ysp建立参考轨迹方程,使输出y(t)能够平滑过渡到设定期望值ysp;所述参考轨迹方程为
其中,yr(t+j)为t+j时刻的被控量参考值,η为柔化系数,0<η<1。
步骤3.3:构架污水处理过程预测控制优化模型为
s.t.umin≤u(t+j-1)+δu(t+j)≤umax
其中,j为优化控制性能指标,np为预测步长,nc为控制步长,u(t+j)为t+j时刻的控制量,δu(t+j)为t+j时刻的控制量增量,ry和ru均为加权系数,umin、umax分别为控制量约束的下限、上限。
其中,预测控制性能指标为预测值和参考轨迹之间误差的加权平方和,同时在指标中加入对控制量增量的惩罚项。
步骤3.4:采用序贯二次规划算法求解所述污水处理过程预测控制优化模型,得到使优化控制性能指标j最小的控制量增量δu*(t),进而得到最优控制量u*(t)=u(t-1)+δu*(t)。本实施例中,优化问题通过调用matlab工具箱中的fmincon()函数来求解。
步骤4:上位机将最优控制量u*(t)发送给plc系统,plc系统调节第五分区氧气量调节阀,使第五分区氧气转换系数达到最优控制量,然后采集最新一组污水处理过程测量数据u(i),y(i),进行与步骤1中相同的预处理后,更新历史数据库。
本实施例中,根据污水处理厂采集数据进行实验。第五分区溶解氧浓度的控制在污水处理过程中一般控制在2mg/l,实验同时增加了改变不同设定期望值的跟踪实验。分别进行了设定值跟踪实验、输入脉冲干扰抑制实验、输出脉冲干扰抑制实验。
如图4和图5所示,分别为设定值跟踪实验中被控量的控制效果图和控制量的变化曲线图;其中,被控量的设定期望值在150时刻由2更改为2.5、在300时刻再由2.5更改为2。如图6和图7所示,为输入脉冲干扰抑制实验的结果,200和250时刻在控制量中加入脉冲干扰。图8和图9为输出脉冲干扰抑制实验,100和350时刻在被控量中加入输出脉冲干扰。图10和图11为同时加入输入输出脉冲干扰抑制实验,200和400时刻加入输入脉冲干扰和输出脉冲干扰。由图4至图11的实验结果可以看出,本发明能够有效抑制输入和输出干扰对控制的影响,且预测控制的精度高,能够使输出平滑过渡到设定期望值。
显然,上述实施例仅仅是本发明的一部分实施例,而不是全部的实施例。上述实施例仅用于解释本发明,并不构成对本发明保护范围的限定。基于上述实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,也即凡在本申请的精神和原理之内所作的所有修改、等同替换和改进等,均落在本发明要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!