一种用于流程工业大规模过程控制的降维辨识方法与流程
本发明涉及参数辨识
技术领域:
,具体为一种用于流程工业大规模过程控制的降维辨识方法。
背景技术:
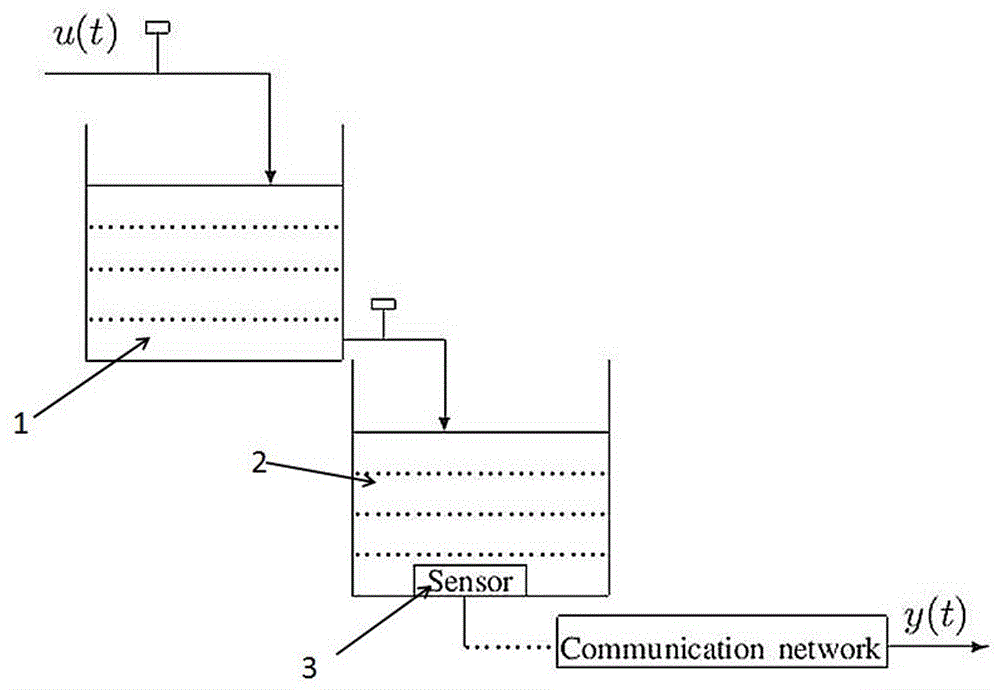
:随着物联网技术的高速发展,流程工业控制系统之间相互联系、相互通信,控制系统规模越来越大,需要用高阶的系统来描述其动态过程。现有技术中,使用传统的辨识算法如梯度迭代方法(gradientiterative,gi)和最小二乘方法(leastsquares,ls)针对大规模系统进行参数辨识。但是传统的辨识算法存在如下问题:(1)梯度算法在计算每次步长时,需要计算高阶矩阵的特征值从而来确定步长的区间,而求解特征值时,高次方程求根属于数学难题,导致目前对步长的选择都是依赖于技术人员的经验,无法确保计算结果的准确性;(2)最小二乘算法应用在大规模系统的在参数辨识时,需要计算高阶矩阵的逆,导致计算量很大,影响辨识效率。技术实现要素:为了解决现有技术中使用传统辨识算法存在过大的计算量导致辨识失败或者辨识效率过低的问题,本发明提供一种用于流程工业大规模过程控制的降维辨识方法,其计算过程通无需人工参与,可以在确保计算精度的基础上,以很低的计算量实现高阶系统的参数辨识。本发明的技术方案是这样的:一种用于流程工业大规模过程控制的降维辨识方法,其包括以下步骤:s1:根据工业过程系统的输入输出关系,构建系统的时间序列模型:a(z)y(t)=b(z)u(t)+v(t)其中:y(t)是系统的输出,u(t)是系统的输入,v(t)是系统的噪声,a(z)、b(z)分别是模型多项式,z是后移算子;s2:根据系统模型做如下定义:y(l)=[y(1),y(2),l,y(l)]t∈rlv(l)=[v(1),v(2),l,v(l)]t∈rl;可得到系统的方程为:y(l)=φ(l)θ+v(l);其中,y(t)是系统的输出,y(l)为输出向量矩阵,v(t)是系统的噪声,v(l)为噪声向量矩阵,为系统的信息向量,φ(l)为信息向量矩阵,θ为系统参数向量,t为采样时刻;其特征在于,其还包括以下步骤:s3:初始化;给系统变量赋初始值:u(t)=0,y(t)=0,t≤0,设置中间变量m,且赋初始值值m=0;s4:通过现有的数据通信与采集技术获取系统控制参数,共获取l组u(1),l,u(l),y(1),l,y(l);s5:根据步骤s4中获取的系统参数,构建所述信息向量的向量矩阵:s6:计算所述系统参数的寻优方向s7:利用arnoldi计算矩阵生成krylov子空间vm(k),构建与垂直的方向:vm(k)=[vm(1),l,vm(k)]其中:k为正整数,满足1≤k<2n;s8:基于φ(l)、y(l)、通过givens变换计算参数的寻优步长s9:基于所述系统参数向量θ的关系式,求出系统向量s10:比较和预先设置阈值δ,δ为正常数;如果则即为此次参数辨识的得到的最优解,此次参数辨识结束;否则,m+1后赋值给m;s11:重复步骤s6~s11。其进一步特征在于:步骤s6中,计算得到后,执行步骤s7之前,还需要进行归一化操作:步骤s7中,利用arnoldi计算矩阵的公式如下:式中,i=2,l,k,j=1,l,i-1;计算公式中,n为转换矩阵:n=φt(l)φ(l);步骤s7中,利用arnoldi计算矩阵之后,还需要进行归一化操作:步骤s8中,通过givens变换计算参数的寻优步长包括如下步骤:a1:通过givens变换求解得出矩阵a2:通过givens变换式中,ηm∈r1×k是一个k阶行向量;式中pm的计算方法如下:由公式nvm(k)=vm(k+1)pm计算得出pm;步骤s1中,u(t)、y(t)、v(t)都是服从均值为零、方差为σ的高斯分布;步骤s1中,a(z)、b(z)可以表示如下:a(z)=1+a1z-1+l+anz-nb(z)=b1z-1+b2z-2+l+bnz-n;步骤s1中,所述后移算子z表达式如下:(z-1y(t)=y(t-1))。本发明提供的一种用于流程工业大规模过程控制的降维辨识方法,进行系统参数辨识的过程中,将待辨识的2n维的参数利用arnoldi方法构建krylov子空间,实现了由2n维降低到k维,降低了系统的计算量;随后通过givens变换方法求解参数寻优步长,确保了本发明的计算方法是收敛的;通过预先设置的阈值δ以及迭代的方法,提高系统参数的辨识精度;通过本发明的参数辨识方法,其计算过程通无需人工参与,可以在确保计算精度的基础上,以很低的计算量快速的实现高阶系统的参数辨识,进而确保整个系统的调整过程都会以更短的时间实现。附图说明图1为双容水箱系统的仿真示意图;图2为基于双容水箱系统,使用传统梯度迭代方法辨识参数的效果图;图3为基于双容水箱系统,使用本发明技术方案进行参数辨识的效果图。具体实施方式如图1~图3所示,本发明一种用于流程工业大规模过程控制的降维辨识方法,其包括以下步骤:s1:根据工业过程系统的输入输出关系,构建系统的时间序列模型:a(z)y(t)=b(z)u(t)+v(t)其中:y(t)是系统的输出,u(t)是系统的输入,v(t)是系统的噪声,u(t)、y(t)、v(t)都是服从均值为零、方差为σ的高斯分布,a(z)、b(z)分别是模型多项式;a(z)、b(z)可以表示如下:a(z)=1+a1z-1+l+anz-nb(z)=b1z-1+b2z-2+l+bnz-n;后移算子z表达式如下:(z-1y(t)=y(t-1))。s2:根据系统模型做如下定义:y(l)=[y(1),y(2),l,y(l)]t∈rlv(l)=[v(1),v(2),l,v(l)]t∈rl;可得到系统的方程为:y(l)=φ(l)θ+v(l);其中,y(t)是系统的输出,y(l)为输出向量矩阵,v(t)是系统的噪声,v(l)为噪声向量矩阵,为系统的信息向量,φ(l)为信息向量矩阵,θ为系统参数向量,t为采样时刻。s3:初始化;给系统变量赋初始值:u(t)=0,y(t)=0,t≤0,设置中间变量m,且赋初始值值m=0;s4:通过现有的数据通信与采集技术获取系统控制参数,共获取l组u(1),l,u(l),y(1),l,y(l);s5:根据步骤s4中获取的系统参数,构建所述信息向量的向量矩阵:s6:计算所述系统参数的寻优方向进行归一化操作:s7:构建与垂直的方向:利用arnoldi计算矩阵并进行归一化操作:式中,i=2,l,k,j=1,l,i-1;n为转换矩阵:n=φt(l)φ(l);生成krylov子空间vm(k):vm(k)=[vm(1),l,vm(k)]其中:k为正整数,满足1≤k<2n;s8:基于φ(l)、y(l)、通过givens变换计算参数的寻优步长由公式nvm(k)=vm(k+1)pm计算得出pm;a1:通过givens变换求解得出矩阵a2:通过givens变换式中,ηm∈r1×k是一个k阶行向量;s9:基于所述系统参数向量θ的关系式,求出系统向量s10:比较和预先设置阈值δ,δ为正常数;如果则即为此次参数辨识的得到的最优解,此次参数辨识结束;否则,m+1后赋值给m;s11:重复步骤s6~s11。系统参数初始值赋值为其计算公式为:其中的矩阵的阶数为k×k,与于传统算法相比,不用对高阶方程求根,同时与最小二乘方法(leastsquares,ls)相比,使用最小二乘方法的辨识参数时,可得即每次需要求解一个大型矩阵的逆(2n×2n);的阶数为k×k远远小于2n×2n,因而系统计算量也是大大降低,确保了使用较少的系统资源,在更短的时间内得到准确的参数辨识结果。由于k<2n,用降维算法得到的参数可能不是最优估计,因此为得到最优估计,进一步引入迭代算法,即,前一次得到的参数作为初始参数,重新进行下一次计算过程,通过迭代方法来提高参数的辨识精度,进而确保参数辨识结果的精确度。双容水箱是工业生产过程中的常见控制对象,如图1所示,它是由两个具有自平衡能力的单容水箱:上水箱1和下水箱2,上下串联而成,通常要求对其下水箱2的液位进行定值控制,双容水箱中的下水箱2液位即为这个系统中的被控量(输出y(t)),通常选取上水箱1的进水流量为操纵量(输入u(t))。利用本发明所提出的大规模控制系统降维方法对一个双容水箱进行了建模,水箱模型具有十个参数,分别是由水箱的横截面积,阀的横截面积,液位以及水的密度等组合而成的,即:θ=[a1,a2,a3,a4,a5,b1,b2,b3,b4,b5]t=[0.2,0.1,1,0.4,0.3,0.7,0.2,0.6,1,1]t系统的输入u(t)是上水箱1的进水量大小,根据下水箱2的液位来调节上水箱1进水量的大小,当下水箱2液位低于理想值时,调大上水箱1的进水量;当下水箱2的液位高于理想值时,调低上水箱1的进水量。输出y(t)是下水箱2的液位测量值,在下水箱2的底部放置压力传感器3,由传感器3采集的真实水箱的液位通过网络传输到控制中心,由于网络的不确定性,导致测量误差的产生,用v(t)来表示误差。即测量值y(t)是由真实液位值加噪声v(t)构成。实验过程中,当下水箱2的液位稳定在理想值附近时,可以认为双容水箱模型达到稳定状态,此时采集l组数据:输入数据u(1),l,u(l)、对应的利用传感器3采集并传输到控制中心的输出值为y(1),l,y(l),、对应的测量误差v(1),l,v(l);利用传统梯度迭代方法和本专利技术方案对双容水箱分别进行建模,实验结果验证了本发明的有效性。如图2和图3所示其中横坐标m代表迭代的次数,纵坐标δ代表估计的参数和真实参数之间的误差,从图中可以看出,本发明所提出的降维方法速度快,能快速辨识出双容水箱的参数,只需迭代12次,而传统的方法需要迭代1000次。针对最小二乘方法(ls)以及本发明提出的降维方法(i-ro),采用不同的采集数据量、不同的迭代次数以及krylov空间不同的维数,将算法中的乘除法个数作为统计量(flops),比较ls和i-ro的flops;如:5×3+2÷3×5,其flops为3;具体的情况如下面表1中所示;通过表格中的数据可知,本发明所提出的降维方法(i-ro),和传统最小二乘方法方法(ls)相比较,每种情况下,本发明方法的计算量都大大小于ls方法;也即是说,同样的前提条件下,本发明的技术方案所需的计算量的更低,因而本发明的技术方案的辨识效率更高。表1:不同条件下的计算量的比较算法lsi-roflops(m2-1)m!+m+ml+ml2[2ml+km2+k2m+km+(k2-1)k!]mm=10,l=20,m=10,k=535925541040800m=100,l=20,m=10,k=5359255410408000m=10,l=60,m=50,k=107.6×10673592877000m=10,l=100,m=50,k=107.6×10673592917000m=10,l=100,m=50,k=207.6×10679.7×1021表1中,m是迭代次数,l为采集的数据个数,m为未知参数的个数,k是krylov子空间中列向量的个数。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1