面向高机动固定翼无人机的飞行动作控制装置及训练方法与流程
本申请属于无人机飞行器控制技术领域,特别涉及一种面向高机动固定翼无人机的飞行动作控制装置及训练方法。
背景技术:
飞行动作,尤其是基本战术机动是现代固定翼战斗机进行战术飞行的基本构成单元。传统的有人驾驶飞机主要通过飞行员操纵驾驶杆、油门杆和方向舵来完成机动飞行动作,从而实现完整的飞行或对抗任务。
而现有固定翼无人机的主要飞行控制模式是针对轨迹跟踪设计的,并不完全适用于高机动飞行,这主要是由以下几个缺点造成的:
1)现有固定翼无人机模式是通过给定航点或航线进行航迹跟踪,由于飞机跟踪目标航线相对于跟踪更为内环的指令过载、指令角速度等控制量有较大的指令滞后,因此导致现有方法无法适应高机动固定翼无人机做机动飞行;
2)已有固定翼无人机控制器控制模式为人类专家根据具体场景预先设计设定,一旦场景发生变化,则飞行轨迹控制模式无法自适应调整与进化。
技术实现要素:
为了解决上述技术问题至少之一,本申请提供了一种面向高机动固定翼无人机的飞行动作控制装置及训练方法。
第一方面,本申请公开了本申请公开了一种面向高机动固定翼无人机的飞行动作控制装置,包括:
上层控制器,用于宏观无人机飞行动作选择;
下层控制器,用于对上层选择的飞行动作进行相对精细的连续引导指令优化。
根据本申请的至少一个实施方式,所述上层控制器用于宏观无人机飞行动作选择包括:
选择飞行动作,以及输入飞行状态向量s,输出离散的one-hot编码机动控制向量。
根据本申请的至少一个实施方式,所述下层控制器用于对上层选择的飞行动作进行相对精细的连续引导指令优化包括:
根据上层控制器输出的one-hot编码机动控制向量和飞行状态向量s进行连续引导控制量解算,输出引导控制指令;其中
通过上层控制器、下层控制器两层指令协调生成内外环综合控制指令,能够控制外环指令以及调节内环高动态连续指令。
根据本申请的至少一个实施方式,所述外环指令至少包括指令速度、指令航向;所述内环高动态连续指令至少包括指令角速度、指令过载。
第二方面,本申请还公开了一种面向高机动固定翼无人机的飞行动作控制装置的训练方法,包括如下步骤:
步骤一、对上层控制器和下层控制器进行双层神经网络控制;
步骤二、对上层控制器和下层控制器进行双层神经网络训练。
根据本申请的至少一个实施方式,所述步骤一包括:
步骤1.1、建立双层神经网络结构,第一层作为机动编码meta-controller,负责宏观无人机飞行动作选择;
步骤1.2、第二层是低级别steer-controller,根据机动编码meta-controller给出的飞行动作,选择对应的指令进行神经网络计算,输出最终的action指令;
步骤1.3、到达预设时间后,重复由机动编码meta-controller开展新一轮调用;
步骤1.4、meta-controller接受外在奖励,同时给与低级别-steer-controller内在奖励;
步骤1.5、返回步骤1.1重复执行上述步骤。
根据本申请的至少一个实施方式,所述步骤1.1中,无人机飞行动作选择包括向左飞行、爬高、向右飞行、下滑、平飞;其中
所述步骤1.2中,是选择指令航向chi、指令爬升角gamma、指令航向角速率chi_dot、指令爬升角速度gamma_dot及指令飞行速度v的神经网络计算。
根据本申请的至少一个实施方式,所述步骤二包括:
步骤2.1、通过在飞行仿真器中持续调用双层神经网络控制阶段来进行采样,构成样本record,其中,样本record包括预定数量飞行状态向量s,、飞行机动动作编码g、飞行连续控制指令a、回报r及下一阶段飞行状态向量s’;
步骤2.2、下层steer-controller根据样本record中的飞行连续控制指令a向量,和飞行机动动作编码g,评估每一个样本record的steer-controller的最大累计回报值;
步骤2.3、上层meta-controller建立全局累计飞行回报值,来对不同目标情况下,上下两层协同控制飞行机动动作编码g和飞行连续控制指令a的共同外在奖励情况;
步骤2.4、上下两层controller进行学习更新,建立双层单步更新误差,通过随机梯度下降方法进行经验风险最小化,得到累积回报,完成双层神经网络训练;
步骤2.5、返回步骤2.1开展下一轮训练。
本申请至少存在以下有益技术效果:
本申请的面向高机动固定翼无人机的飞行动作控制装置及训练方法,通过上下两层指令协调生成内外环综合控制指令,能够控制从指令航向、指令速度这样的外环指令的同时,还能够调节指令角速度、指令过载等内环高动态连续指令,避免了只控制飞行轨迹产生的较大的指令滞后;另外,通过分层强化学习方法,自动产生大量样本来学习和适应复杂高维的多种动态飞行场景,避免人为设计只能覆盖数个设计点导致的局限性,且能够适应场景发生变化,实现控制器自学习和自演化。
附图说明
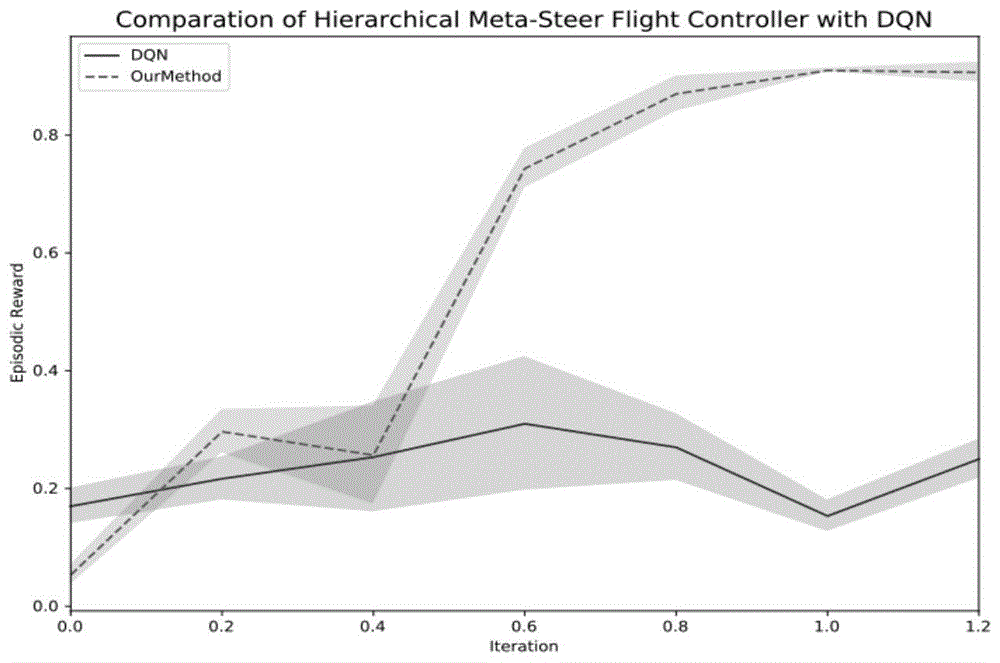
图1是本申请面向高机动固定翼无人机的飞行动作控制装置的训练方法的一实施例训练结果对比图。
具体实施方式
为使本申请实施的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行更加详细的描述。在附图中,自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。所描述的实施例是本申请一部分实施例,而不是全部的实施例。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。下面结合附图对本申请的实施例进行详细说明。
第一方面,本申请公开了一种面向高机动固定翼无人机的飞行动作控制装置,可以包括上层控制器meta-controller和下层控制器steer-controller。
其中,上层控制器用于宏观无人机飞行动作选择;具体地,包括选择飞行动作,以及输入飞行状态向量s,输出离散的one-hot编码机动控制向量。
下层控制器用于对上层选择的飞行动作进行相对精细的连续引导指令优化;具体地,包括根据上层控制器输出的one-hot编码机动控制向量和飞行状态向量s进行连续引导控制量解算,输出引导控制指令。通过上下两层协调工作最终输出飞行控制系统能够接受的有效离散-连续混杂指令输入,从而实现复杂高动态机动动作。
综上,本申请的面向高机动固定翼无人机的飞行动作控制装置,通过上下两层指令协调生成内外环综合控制指令,能够控制从指令航向、指令速度这样的外环指令的同时,还能够调节指令角速度、指令过载等内环高动态连续指令,避免了只控制飞行轨迹产生的较大的指令滞后。
第二方面,本申请还公开了一种面向高机动固定翼无人机的飞行动作控制装置的训练方法;经过学习训练,使得上层控制器可用于宏观无人机飞行动作选择,而下层控制器则可在上层已选飞行动作基础上提供更为精细的连续引导指令优化,使高机动固定翼无人机能够实现与人类驾驶员媲美的机动飞行动作控制与自进化。
具体地,面向高机动固定翼无人机的飞行动作控制装置的训练方法包括如下步骤:
步骤一、对上层控制器和下层控制器进行双层神经网络控制。
其中,步骤一又具体包括:
步骤1.1、建立双层神经网络结构,第一层作为机动编码meta-controller,负责选择宏观机动动作,例如包括向左飞行、爬高、向右飞行、下滑、平飞。
步骤1.2、第二层是低级别steer-controller,根据机动编码meta-controller给出的目标选择指令航向chi、指令爬升角gamma、指令航向角速率chi_dot、指令爬升角速度gamma_dot及指令飞行速度v的神经网络计算,输出最终的action指令。
步骤1.3、到达规定时间后,重复由机动编码meta-controller开展新一轮调用。
步骤1.4、meta-controller接受外在奖励,同时给与低级别-steer-controller内在奖励。
步骤1.5、返回步骤1.1重复执行上述步骤(即整个步骤一)。
步骤二、对所述上层控制器和下层控制器进行双层神经网络训练。
其中,步骤二又具体包括:
步骤2.1、通过在飞行仿真器中持续调用双层神经网络控制阶段来进行采样,构成样本record,其中,样本record包括预定数量飞行状态向量s,、飞行机动动作编码g、飞行连续控制指令a、回报r及下一阶段飞行状态向量s’;进一步,优选上述预定数量为不少于32000个。
步骤2.2、下层steer-controller根据样本record中的飞行连续控制指令a向量,和飞行机动动作编码g,评估每一个样本record的steer-controller的最大累计回报
其中,t代表当前时刻,πag为在当前飞行机动动作编码g下计算a向量的策略函数,γ为回报折扣因子,整个式子代表在πag作用下,下层steer-controller在当前s条件下面向g目标得到的累计预期回报的期望,在a向量下最大化该期望定义为最优q函数即
步骤2.3、上层meta-controller根据建立全局累计飞行回报
其中n为时间步,代表每n时间步切换一次上层控制策略,f为累计外部奖励,在机动号g下最大化累计预期f的期望定义为最优q函数即
步骤2.4、上下两层controller进行学习更新,建立双层单步更新误差,通过随机梯度下降方法进行经验风险最小化,从而在当前
y1,i=r+γmaxa′q1(s′,a′;θ1,i-1,g).;
其中θ1为学到的下层控制器参数,yi,i代表当前引导向量a作用下,预期最佳的累计q函数,因此l1(θ1,i)代表预期最佳的累计q函数与当前由神经网络表示的q函数的差值,即时间差分误差,因此运用随机梯度下降方法,即可对这一误差针对下层控制器的神经网络参数θ1进行持续优化,实现基于采样的训练与进化;上层控制器的神经网络参数θ2的训练方式与下层控制器相同,区别在于其随机梯度的求解为在飞行机动动作编码g条件下的上层时间差分误差对上层控制器的神经网络参数θ2求梯度。
步骤2.5、返回步骤2.1开展下一轮训练。
因此,本申请的上述方法在以往的控制方法设计上进行了改进,控制与学习流程简单明确,易于工程实现,彻底解决了以往方法无法适应高机动固定翼无人机做机动飞行和飞行轨迹控制模式无法自适应调整与进化的问题。
综上所述,本申请的面向高机动固定翼无人机的飞行动作控制装置的训练方法,至少包括如下优点:
1)对无人机机动飞行达到指定的位置与速度这一任务进行了仿真分析实验。其中每次迭代采样32000样本。该方法与dqn直接控制底层指令航向chi、指令爬升角gamma、指令航向角速率chi_dot、指令爬升角速度gamma_dot及指令飞行速度v相比(参见图1所示),累计飞行回报在50轮迭代后提升了3000左右,证明本方法能够明显提升飞行机动动作的学习效率;
2)通过上下两层指令协调生成内外环综合控制指令,能够控制从指令航向、指令速度这样的外环指令的同时,还能够调节指令角速度、指令过载等内环高动态连续指令,避免了只控制飞行轨迹产生的较大的指令滞后;
3)通过分层强化学习方法,自动产生大量样本来学习和适应复杂高维的多种动态飞行场景,避免人为设计只能覆盖数个设计点导致的局限性,且能够适应场景发生变化,实现控制器自学习和自演化。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!