基于Mist-边缘-雾-云计算的热误差预测系统及热误差补偿系统
本发明属于机械误差分析技术领域,具体的为一种基于mist-边缘-雾-云计算的热误差预测系统及热误差补偿系统。
背景技术:
齿轮轮廓磨床在运行过程中会产生过多的热量,从而导致热误差。热误差是影响加工零件的加工精度的最重要因素,因此,必须控制和补偿热误差。误差建模由于其灵活性而被广泛使用。过去,学者们一直在研究基于物理的热误差建模方法,并且受到了广泛关注。creighton等,对微铣削主轴进行了有限元分析,热误差降低了80%。li等,建立静态误差模型,然后根据历史温度数据和静态误差模型构建动态热误差。梁等,建立了一个瞬态热和静态结构仿真模型来验证中央冷却结构的适用性。altintas等,将主轴系统设计方法集成到专家系统中。刘等,考虑了热接触电阻(tcr),并精确建立了热结构模型。可以看出,为了获得准确的热分析结果,应考虑对流系数和tcr。基于物理的建模方法不需要收集大量的实验数据来建立经验关系,其优势显而易见;但是,由于复杂的结构和动态的工作条件,通常不采用基于物理的模型。此外,由于建模过程耗时,因此难以在实际工业场景中应用基于物理的模型进行误差补偿。
近年来,基于数据的建模方法由于其灵活性而相对流行并且被普遍使用。abdulshahed等,结合网络模型和灰色卷积积分建立误差模型。苗等,提出了一种基于主成分回归(pcr)算法的模型。刘等,建立了一种岭回归方法来消除温度变量之间的共线性。迈尔等,提出了一种使用加权最小二乘(wls)方法自适应更新参数的自回归模型。神经网络(nns)已受到越来越多的关注。wang等,提出了一种物理指导的工具磨损预测网络,并充分考虑了时间序列数据和物理信息的存储特性。与基于物理的建模方法相比,基于数据的模型和基于物理的模型的组合更加实用和灵活。基于数据的误差模型虽然建立了热误差和临界温度之间的映射关系,但是,有限的温度变量几乎无法完全反映整个机器的热信息。
为了避免温度变量之间的共线性,huang等人,提出了一个只需要热量作为输入的模型。shi等,提出了一种以转速为输入的基于指数函数的误差模型,从而避免了共线性的影响。
以上的模型仍然是经验模型,并且由于误差机制不明确而具有有限的鲁棒性。热误差具有滞后效应,热误差模型应揭示其记忆特性。此外,lstm网络可用于挖掘误差数据的内部和非线性定律,独特的内存性能可用于处理时间序列数据,通过输入热误差来避免温度变量之间的共线性,从而提高了鲁棒性。此外,可以在有监督的学习模式下更新lstm网络的参数和设置。与具有固定参数和设置的静态模型相比,lstm网络具有更优异的自学习和自适应功能。
另外,基于数据的误差模型的训练是一个涉及大量数据传输,处理和计算的过程。由于大容量数据的收集、传输、存储和处理,处理器的运行效率可能太低。云计算具有强大的计算能力和可靠的存储容量,因此是解决此类问题的最佳方法。作为一种新技术,云计算正在渗透到传统行业,但对于对执行效率非常敏感的工业场景,云计算的带宽是一个严重的问题。实际上,机床的加工过程是工业场景,对执行效率极为敏感。因此,云计算在该领域的广泛应用受到一定的限制。换句话说,由于高延迟、有限的带宽和高能耗的问题,云计算不能直接应用于机床的加工过程。
技术实现要素:
有鉴于此,为了解决现有工业互联网的带宽有限,传输、处理和计算速度低可能严重影响数据交换的效率,导致其不利于应对突发工作条件的问题,本发明的目的在于提供一种基于mist-边缘-雾-云计算的热误差预测系统及热误差补偿系统。
为达到上述目的,本发明提供如下技术方案:
本发明首先提出了一种基于mist-边缘-雾-云计算的热误差预测系统,包括mist计算层、边缘计算层、雾计算层和云计算层;
所述mist计算层包括:
树莓派(rpi),用于将安装在设备上的传感器采集得到的电流、电压信号转换为热误差数据;
边缘计算层包括:
过滤器,用于对经树莓派(rpi)转换得到的热误差数据进行过滤和降噪;
放大器,用于对经过滤器处理后的热误差数据进行放大处理;
路由器,用于将经放大器处理后的热误差数据传输至雾计算层;
微型数据中心,用于存储最近的热误差数据并判断设备运行状态是否正常并在设备运行状态异常时快速响应;
所述雾计算层包括:
服务器,用于接收经所述边缘计算层处理后的热误差数据;
热误差预测单元,根据热误差数据预测热误差,得到热误差预测值;
所述云计算层包括:
数据库,用于从所述服务器获取并存储热误差数据;
训练单元,根据数据库内存储的热误差数据训练热误差预测模型、并将训练得到的热误差预测模型传输至所述热误差预测单元以更新所述热误差预测单元内的热误差预测模型。
进一步,所述雾计算层内还包括:
预测精度判断单元,用于判断所述热误差预测单元的预测精度是否超过设定阈值;
误差补偿控制器,在所述热误差预测单元的预测精度未超过设定阈值时控制设备进行误差补偿;
模型更新单元,在所述热误差预测单元的预测精度超过设定阈值时,将经所述训练单元训练得到的热误差预测模型传输至所述热误差预测单元以更新所述热误差预测单元内的热误差预测模型。
进一步,所述热误差预测单元的预测精度等于热误差预测值与热误差实际值之间差值的绝对值。
进一步,所述热误差预测模型的构建方法为:
1)初始化灰狼个体的参数,包括要优化的参数的维数、灰狼个体的总体数量、最大迭代次数以及要优化的参数的上限和下限;
2)构建bi-lstm神经网络,并将灰狼的位置映射为bi-lstm神经网络的批处理大小;以热误差数据训练bi-lstm神经网络后、利用bi-lstm神经网络预测热误差,以热误差数据的热误差实际值和由bi-lstm神经网络预测得到的热误差预测值之间的平均绝对误差(mae)视为损失函数;
3)判断平均绝对误差(mae)是否小于设定阈值;若是,则以当前灰狼位置映射得到的批处理大小作为bi-lstm神经网络的最佳超参数;若否,则执行步骤4);
4)判断迭代次数是否达到最大迭代次数;若是,则终止循环,以平均绝对误差(mae)最小时的灰狼位置映射得到的批处理大小作为bi-lstm神经网络的最佳超参数;若否,则更新灰狼位置,迭代次数加1,执行步骤2);
5)以gwo算法优化得到的批处理大小作为bi-lstm神经网络的最佳超参数,构建得到热误差预测模型。
进一步,所述步骤1)中,初始化灰狼个体的参数后,判断灰狼的初始位置,若灰狼的初始位置超出预设范围,则以预设范围的边界作为灰狼的初始位置。
进一步,所述步骤2)中,将热误差数据以监督学习算法处理后,再作为bi-lstm神经网络的训练集和测试集。
进一步,所述步骤4)中,以余弦和正弦搜索策略更新灰狼位置。
进一步,gwo算法在迭代过程中的控制参数为:
其中,a3为控制参数,其关于(m,n)点是中心对称;k为中心点的变化率;且:
其中,tmax为最大迭代次数;t为当前的迭代次数。
本发明还提出了一种基于mist-边缘-雾-云计算的热误差补偿系统,包括如上所述的基于mist-边缘-雾-云计算的热误差预测系统和用于控制设备动作的cnc控制器;
所述雾计算层内还包括:
预测精度判断单元,用于判断所述热误差预测单元的预测精度是否超过设定阈值;
误差补偿控制器,在所述热误差预测单元的预测精度未超过设定阈值时控制设备进行误差补偿;
模型更新单元,在所述热误差预测单元的预测精度超过设定阈值时,将经所述训练单元训练得到的热误差预测模型传输至所述热误差预测单元以更新所述热误差预测单元内的热误差预测模型;
所述误差补偿控制器在所述热误差预测单元预测得到的热误差预测值大于热误差的设定阈值时,计算设备主轴系统在每一个方向上的热误差补偿分量并更新g代码,将更新后的g代码传输至所述cnc控制器。
本发明的有益效果在于:
本发明基于mist-边缘-雾-云计算的热误差预测系统,通过设置mist计算层、边缘计算层、雾计算层和云计算层,大容量的历史数据用于云计算层中的热误差预测模型的训练,热误差预测模型被嵌入到雾计算层中,雾计算层具有一定计算能力并且靠近物联网设备;数据过滤和降噪等相关工作被放置在边缘计算层以处理收集的原始热误差数据,从而可以减轻物联网带宽的压力;传感器设置在设备上,并可在线实时采集与热误差有关的热误差数据,树莓派(rpi)设置在mist计算层中,以将收集的电流、电压信号转换为热误差数据,这进一步减轻了物联网带宽的压力;另外,由mist计算层和边缘计算层组成的闭环可以不与雾计算层和云计算层通信,这有利于设备在异常运行状态下及时采取措施,以便于应对突发工作条件。
本发基于mist-边缘-雾-云计算的热误差预测系统还具有以下优点:
(1)基于物理的建模方法过于复杂且耗时,不适合热误差的预测和补偿;本发明通过建立基于物理的模型来揭示误差机理,可以证明热误差的磁滞效应,也即热误差和温度之间会有明显的滞后效应,这表明使用存储器类型的时间序列模型(如双向lstm(bi-lstm)神经网络)可以实现出色的鲁棒性和预测精度;
(2)为减少传统的超参数调整过程的繁琐和繁琐,提出了一种余弦和正弦灰狼优化算法,在原始灰狼优化算法(gwo)的基础上,引入了余弦和正弦搜索策略,以进一步提高搜索精度和速度,并对原始gwo算法的控制参数进行了修改;然后,还改进了原始gwo算法的本地和全局搜索功能;余弦和正弦灰狼优化算法(scgwo算法)用于优化热误差预测模型的批处理大小;最后,通过提出的scgwo算法可以有效地找到与热误差数据很好匹配的最佳批处理大小;
(3)由于工业互联网的带宽有限,传输、处理和计算速度低可能严重影响数据交换的效率,而传统的网络架构不利于应对突发的工作条件;本发明提出了一种新的分布式mefcs架构来解决这个问题;由mist计算层和边缘计算层组成的闭环可以确定机床是否处于异常工作状态,边缘计算层可以及时采取应急措施,而不需要与雾计算层和云计算层进行通讯;本发明将数据类型的转换放置在mist计算层中,将包括过滤和降噪在内的热数据预处理放置在边缘计算层中,基于数据的模型的预测和灰狼位置的更新位于雾计算层中,模型的训练和更新被放置在具有强大计算能力和可靠存储功能的云计算层中,从而改进了所提出的mefcs系统的性能;
(4)设计精度阈值,并将其设置为判断条件;预测精度的阈值位于雾计算层中,可以大大提高数据传输速度,仅需要传输前三千个数据;设置精度阈值以判断是否需要更新热误差预测模型,与没有精度阈值的系统相比,其预测能力提高了8.31%;此外,温度变量被丢弃,从而可以完全避免温度变量之间的共线性,收集、传输、存储和处理的数据量减少了11/16;此外,与设计的系统的实现相比,传输的数据量减少到1/10;因此,对带宽的压力进一步减小,从而提高了系统的执行效率和预测精度;通过实施所提出的mefcs应用于齿轮轮廓磨床中,左齿表面的最大齿廓倾斜偏差从37.5μm减小到5.8μm,右齿表面的最大齿廓倾斜偏差从12.5μm减小到5.2μm,机加工齿轮的齿廓偏差的精度等级从iso5提高到iso3。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明基于mist-边缘-雾-云计算的热误差预测系统的框架图;
图2为本发明基于mist-边缘-雾-云计算的热误差补偿系统的框架图;
图3为主轴系统的结构示意图;
图4为温度和热误差之间的磁滞回归曲线图;
图5为gwo算法中的控制参数随迭代次数的变化曲线图;
图6为bi-lstm神经网络的结构图;
图7为scgwo-bi-lstm神经网络模型的流程图;
图8为实验设备和传感器的布置图;
图9为.mist计算层数据采集设备的流程图;
图10(a)为工作条件1中的转速随时间变化的曲线图;
图10(b)为工作条件2中的转速随时间变化的曲线图;
图11(a)为六个传递函数的损耗比较;
图11(b)为四种优化算法的损耗比较;
图12为不同批处理大小的预测结果;
图13(a)为工作条件1时的热伸长曲线;
图13(b)为工作条件2时的热伸长曲线;
图14(a)为更新前的scgwo3-bi-lstm网络模型的热伸长曲线;
图14(b)为更新后的scgwo3-bi-lstm网络模型的热伸长曲线;
图15(a)为未实施mefcs时的齿廓检测结果;
图15(b)为实施mefcs时的齿廓检测结果。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好的理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
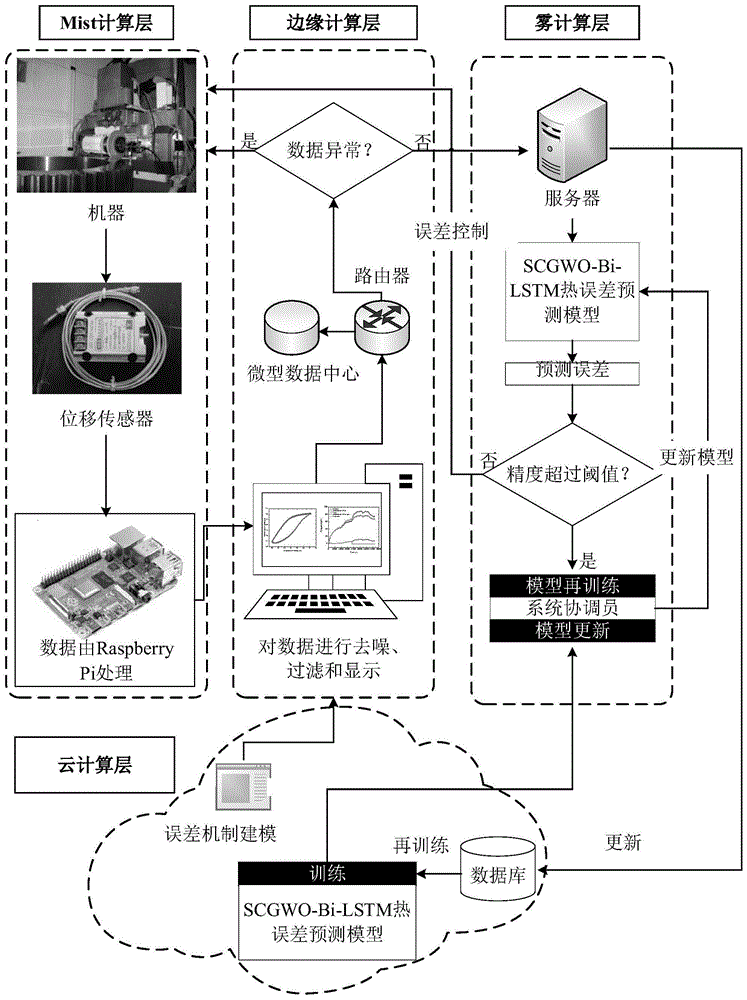
如图1所示,为本发明基于mist-边缘-雾-云计算的热误差预测系统的框架图,本实施例基于mist-边缘-雾-云计算的热误差预测系统包括mist计算层、边缘计算层、雾计算层和云计算层。
mist计算层包括:
树莓派(raspberrypi),用于将安装在设备上的传感器采集得到的电流、电压信号转换为热误差数据;
边缘计算层包括:
过滤器,用于对经树莓派(rpi)转换得到的热误差数据进行过滤和降噪;
放大器,用于对经过滤器处理后的热误差数据进行放大处理;
路由器,用于将经放大器处理后的热误差数据传输至雾计算层;
微型数据中心,用于存储最近的热误差数据并判断设备运行状态是否正常并在设备运行状态异常时快速响应;
雾计算层包括:
服务器,用于接收经所述边缘计算层处理后的热误差数据;
热误差预测单元,根据热误差数据预测热误差,得到热误差预测值;
云计算层包括:
数据库,用于从所述服务器获取并存储热误差数据;
训练单元,根据数据库内存储的热误差数据训练热误差预测模型、并将训练得到的热误差预测模型传输至所述热误差预测单元以更新所述热误差预测单元内的热误差预测模型。
优选的,本实施例的雾计算层内还包括:
预测精度判断单元,用于判断所述热误差预测单元的预测精度是否超过设定阈值;具体的,热误差预测单元的预测精度等于热误差预测值与热误差实际值之间差值的绝对值;
误差补偿控制器,在所述热误差预测单元的预测精度未超过设定阈值时控制设备进行误差补偿;
模型更新单元,在所述热误差预测单元的预测精度超过设定阈值时,将经所述训练单元训练得到的热误差预测模型传输至所述热误差预测单元以更新所述热误差预测单元内的热误差预测模型。
进一步,本实施例的热误差预测模型的构建方法为:
1)初始化灰狼个体的参数,包括要优化的参数的维数、灰狼个体的总体数量、最大迭代次数以及要优化的参数的上限和下限;具体的,在初始化灰狼个体的参数后,判断灰狼的初始位置,若灰狼的初始位置超出预设范围,则以预设范围的边界作为灰狼的初始位置。
2)构建bi-lstm神经网络,并将灰狼的位置映射为bi-lstm神经网络的批处理大小;以热误差数据训练bi-lstm神经网络后、利用bi-lstm神经网络预测热误差,以热误差数据的热误差实际值和由bi-lstm神经网络预测得到的热误差预测值之间的平均绝对误差(mae)视为损失函数;本实施例将热误差数据以监督学习算法处理后,再作为bi-lstm神经网络的训练集和测试集。
3)判断平均绝对误差(mae)是否小于设定阈值;若是,则以当前灰狼位置映射得到的批处理大小作为bi-lstm神经网络的最佳超参数;若否,则执行步骤4)。
4)判断迭代次数是否达到最大迭代次数;若是,则终止循环,以平均绝对误差(mae)最小时的灰狼位置映射得到的批处理大小作为bi-lstm神经网络的最佳超参数;若否,以余弦和正弦搜索策略更新灰狼位置,迭代次数加1,执行步骤2);
5)以gwo算法优化得到的批处理大小作为bi-lstm神经网络的最佳超参数,构建得到热误差预测模型。
如图2所示,为本发明基于mist-边缘-雾-云计算的热误差补偿系统实施例的框架图。本实施例基于mist-边缘-雾-云计算的热误差补偿系统,包括如上所述的基于mist-边缘-雾-云计算的热误差预测系统和用于控制设备动作的cnc控制器;误差补偿控制器在所述热误差预测单元预测得到的热误差预测值大于热误差的设定阈值时,计算设备的主轴系统在每一个方向上的热误差补偿分量并更新g代码,将更新后的g代码传输至所述cnc控制器。
下面对本发明基于mist-边缘-雾-云计算的热误差预测系统及热误差补偿系统的具体实施方式进行进一步详细说明。
1、热误差机理:
热误差的根本原因是温度场不均匀,并且热量是由轴承和电机产生的。本实施例建立了主轴系统模型,如图3所示。电动机将对温升产生一定的影响。前后滚动轴承产生的热量将进一步增加轴的热误差。因此,主要的内部热源表示为:
qb=1.047×10-4nm
其中,n表示转速;摩擦力矩m由m1和m0等项组成;m1和m0与f0和f1的系数以及fa和fr的负载有关,则m表示为:
m=m0+m1
m1=f1dmmax(0.9fa/tanα-0.1fr,fr)
其中,dm表示节圆直径;v0表示运动粘度;α表示接触角。
当温度被认为仅取决于轴向位置时,该模型会更简单,因为轴是良好的导热组件。轴离散为n个点。
其中,ac表示横截面面积;k表示导热系数;δt表示温差;
其中,l表示长度。
每个节点tcjx的热容表示为:
tcjx=cpmjx
质量mjx为:
节点jq以q的供热率持续供热时间为0≤t≤th,系统冷却时间th<t≤tstop。q表示供热率,jq表示节点。每个节点的温度变化δtjx的计算如下:
当jx=1时,
当2≤jx≤jq-1和jq+1≤jx≤n-1时,
当jx=jq时,
当jx=n时,
其中,asi表示ith元素的圆柱表面积。
然后,温度历史记录数组th中itime行的温度为:
一维轴的热伸长为:
其中,ε表示热膨胀系数。为了显示记忆行为,建立了仿真模型。表1中列出了模型的参数,加热时间和冷却时间用作输入,轴承温度和两端的热误差用作输出。
表1热物理性质参数。
加热时间和冷却时间设置为300min。形成磁滞回线必须考虑两个因素:(1)两个变量之间存在磁滞效应。如果两个变量的变化同步,则不存在磁滞效应,并且磁滞曲线为直线。(2)应该有加热和冷却阶段。如果只有加热阶段而没有冷却阶段,则只有一条曲线不会形成磁滞环。磁滞环是由于加热和冷却阶段的热误差变化不同而引起的。事实是,在温度下降阶段,热误差将不会沿着加热轨道回到原始状态。本实施例以三角函数用作温度输入,然后证据表明,磁滞回线应具有加热和冷却阶段。此外,如图4所示,获得了可以反映热特性的磁滞回线。很明显,温度和误差之间存在磁滞关系。温度范围两端的数据点比其他温度范围的数据点密集。这意味着在温度范围的两端温度响应都更快,然后系统很快达到稳定状态。另外,轴的当前热误差受先前的热状态影响。然后,应考虑其影响。
可以看出,当前的热误差取决于当前时刻的热状态,并且还受先前的热信息影响。复杂的热量产生和传递过程将导致热误差,并且误差被证明是非线性的且随时间变化的。lstm网络的独特存储性能使其能够很好地处理时间序列数据,并且前一时刻的数据被视为输入,还可以解决递归神经网络中梯度消失的问题。lstm网络的独特门结构可以确定是保留还是遗忘了过去的信息,从而使模型具有长期存储能力。因此,lstm网络具有强大的存储功能。此外,lstm网络具有出色的自学习和自适应能力。然后证明了lstm网络更适合作为热误差的预测模型这一事实。具有记忆功能的lstm网络可用作热误差记忆特征的建模工具。可以链接过去和将来的信息的bi-lstm网络用于挖掘潜在的映射关系。超参数是影响网络性能的重要因素。批处理大小是bi-lstm神经网络最重要的超参数之一。gwo算法具有很强的搜索能力,并引入了余弦和正弦搜索策略来提出scgwo算法。最后,在本研究中,scgwo算法用于搜索lstm网络的最佳批处理大小。
2、余弦和正弦灰狼优化(scgwo)算法
确定bi-lstm网络的最佳超参数不容易,本实施例为了节省搜索时间,提高训练效率,提出了scgwo算法来优化bi-lstm网络的批处理大小。gwo算法是从灰太狼种群的独特等级和狩猎行为中得出的。在该算法中,α,β和δ的三个高等级狼引导ω的低等级狼搜索目标猎物。狼的第一步是包围它们的猎物。毫无疑问,他们将迅速走向猎物,灰太狼与其猎物之间的距离表示为:
x(t)={xi(t)∣i=1,2,…,d}
其中,t表示当前的迭代次数;x(t)表示第一代灰太狼的位置;d表示灰太狼与猎物之间的距离。
灰太狼的位置更新表示为:
x(t+1)=xp(t)-ad
其中,xp(t)表示tth猎物的位置;a和c是两个系数变量。
c=2r2
a=2ar1-a
其中,a表示在迭代过程中从2线性减少到零的变量;tmax表示最大迭代次数;r1和r2表示两个随机数,并且均匀分布在[0,1]的范围内;若|a|>1,灰太狼将被驱逐出当前的猎物,以扩大搜索范围并进行全球探索。若|a|<1,灰太狼会接近猎物进行捕猎。
然后,狼的第二步是狩猎猎物。根据狼的适应度获得最优解xα,第二最优解xβ和当前第三最优解xδ。将更新α-,β-和δ-狼的位置。
x1=xα-adα
x2=xβ-adβ
x3=xδ-adδ
其中,x1,x2和x3表示α-,β-和δ-狼的位置更新。
ω-狼的位置更新由α-,β-和δ-狼来指引。
其中,x(t+1)表示ω-狼的位置更新。
狼的最后一步是开始攻击猎物,狼的位置是最佳解决方案。gwo算法结构清晰,几乎不需要调整任何参数。有许多方法可以进一步提高gwo算法的性能,为了避免局部最优,本实施例引入了余弦和正弦搜索策略以提高其搜索能力,然后提出了scgwo算法以增强全局搜索能力。因此,提高了收敛速度和优化精度。ω-狼的位置由α-,β-和δ-狼指示。随着余弦和正弦搜索策略的引入,ω-狼的位置在最优解的方向上波动,以找到全局最优解。余弦和正弦搜索策略表示为:
r4∈(0,360°)
此外,控制参数a的线性减小,但是优化算法应该是非线性过程,线性控制参数不能准确地模拟非线性过程,导致搜索精度和收敛速度低。这需要对该算法进行进一步的改进。控制参数a起着获取功能的作用,因此,提出了各种策略来修改该关键参数。bi-lstm神经网络的训练和预测过程非常耗时。为了节省计算时间,需要更多的本地搜索以加快收敛速度。将控制参数a修改为对数控制参数a2以加快收敛速度。
控制参数a越大,全局勘探性能越好;控制参数a越小,局部开采性能越好。对于scgwo算法,总体越大,收敛速度越低,如何提交收敛速度是关键。为了减少模型训练的时间,使用人口规模较小的scgwo算法来减少计算时间。大的控制参数a用于在早期寻求全局最优。在稍后的阶段,找到全局最优值,然后应减小控制参数a以加快收敛速度。为了同时满足上述两个要求,引入了s形函数进行修正以获得指数控制参数a3。
控制参数a3表示为:
控制参数a3关于(m,n)点是中心对称的,并且中心点的变化率是k;具体的,控制参数a3由以下参数决定:
不同的控制参数随x的变化如图5所示。可以看出,所提出的控制参数从大到小的变化很快,这非常有利于改善全局搜索和局部收敛。
3、bi-lstm神经网络
lstm网络由几个具有输入、忘记和输出门控制的存储单元组成。存储器单元的存储内容可以由三个门控制。存储内容分为长期和短期状态,以传递到下一个单元。lstm网络保留了过去信息的长期和短期记忆,传递过程如图6所示。因此,lstm网络将捕获热误差的长期和短期特征,以改善预测性能。
每个门在lstm网络中都有特定而独特的功能。遗忘门ft用于丢弃先前状态中的信息;输入门it的功能是决定是否更新单元状态;输出门ot用于控制输出到下一单元的当前单元的长期和短期状态。
ft=δ(wf[ht-1,xt]+bf)
其中,xt表示lstm网络单元的输入,ht-1表示先前隐藏层的单位,并与xt结合以增加三个门的权重;
信息在两个方向上传播,因此bi-lstm网络完全保留了热误差的特征。因此,bi-lstm网络可用于捕获时间序列数据的特征。输入x在bi-lstm网络的正向和反向传播,输出结果是两个输出结果在两个方向上的拼接,如图6所示。由于权重的重复使用,预测能力增强,并且不需要增加数据量。因此,减少了欠拟合的风险。
4、scgwo-bi-lstm网络模型
本实施例提出了scgwo算法来优化bi-lstm网络的批处理大小,以利用强大的全局搜索能力和快速收敛性能。本实施例以scgwo-bi-lstm网络模型为热误差预测模型,如图7所示,其构建方法如下。
步骤1:初始化gwo的参数,包括要优化的参数的维数,总体数量,最大迭代以及要优化的参数的上限和下限。然后判断狼的初始位置。如果超出预设范围,则其值将更改为边界。最后,将狼的初始位置的位置映射到批次大小,并将其输入到模型中以训练bi-lstm神经网络。
步骤2:将误差数据作为一维矢量输入到转换函数,转换函数可以将时间序列数据转换为监督学习。然后建立原始的lstm网络,并将其初始批次大小设置为狼的位置。然后将原始lstm网络依次连接到完全连接层和激活层。然后将数据输入到模型中,并将平均绝对误差(mae)视为损失函数,并且可以通过模型训练和预测获得。
步骤3:确定mae是否满足预设要求。如果不是,则更新狼的位置,并且通过交换狼的位置来改变适应度。然后在高级狼的指导下更新狼的位置。为了进一步提高搜索精度,引入了余弦和正弦搜索策略来更新狼的位置。
步骤4:判断迭代次数是否达到最大值。如果达到最大值,则终止循环,然后获得最佳解。如果未达到最大值,则重复迭代,并将更新的狼位置用作批处理大小以更新bi-lstm网络。
5、mefcs体系
具有强大的集中式数据存储和处理功能的云服务器已被广泛用于工业互联网。但是,由于云服务器和终端设备之间的物理距离相当大,因此集中处理和存储数据的云计算模型面临着诸如工业互联网延迟,带宽有限以及制造公司的能耗之类的挑战性问题。除了网络层面临上述挑战,在物理层面,还存在对物理设备的响应延迟,如果在运行过程中发生异常事件,则不宜等待来自云计算层或雾计算层的指令。为了解决物联网面临的问题,提出了一种新的mefcs体系结构来预测和控制热误差,如图1所示。
5.1、mist计算层
mist计算层位于物理世界中,可以独立实现其功能,而无需与雾计算层,边缘计算层和云计算层进行通信。该层主要包括机床等设备、传感器和一些树莓派(raspberrypi)。raspberrypi被认为是典型的薄雾计算层设备,具有感应和驱动功能。raspberrypi采用raspbian作为操作系统,并具有16gb的microsd存储卡。本实施例在微型计算机上编程以完成数据转换,不断收集电流和电压信号,并通过a/d转换器pcf8591将其转换为热误差数据。a/d转换器pcf8591是一个八位数模转换器模块。它的scl和sda与raspberrypi的scl和sda连接。此外,raspberrypi的“相机”模块还可以允许用户查看实时图像。
5.2、边缘计算层
所收集的具有明显噪声的原始数据将在边缘计算层进行过滤和去噪。此操作的优点是消除了奇异值,然后数据变得更平滑以反映实际工况。此外,减少了处理数据量,有利于减轻工业互联网的带宽压力。去噪的数据由路由器上传到雾计算层,路由器被认为是边缘计算层的典型设备。此外,微型数据中心(也称为云小程序)放置在该层上,以存储部分热数据,所存储的数据可以用作与连续输入的热数据进行比较以确定机器是否正常运行的标准。微数据中心将用于可能的异常事件的控制方法预先存储在边缘计算层中,以进行快速响应。边缘计算层靠近设备,并且响应迅速,如果发生异常事件,则可以在不与雾计算层和云计算层通信的情况下采取措施,从而可以减少意外损失,工作原理如图2所示。误差控制过程如下:在mist计算层中,由位移传感器收集误差数据,然后用a/d转换器的树莓派将数字转换为模拟热误差信号。然后,对热误差数据进行滤波,并在边缘计算层中进行放大。此外,将经过滤波和放大的误差数据传输到雾计算层以进行实时预测。然后通过计算各个方向的误差分量来获得控制值。大量历史数据存储在云计算层上的数据库中。当系统运行一段时间后,应更新scgwo3-bi-lstm网络模型,因为热误差会随运行条件而显着变化,将经过重新训练的scgwo3-bi-lstm网络模型转移到雾计算层,实现模型的更新,并使用更新后的模型预测误差。此外,由于建模过程非常耗时,因此在云计算层上进行误差机制建模,然后将通过误差机制建模获得的结果显示在边缘计算层上,以方便用户查看。然后将控制值从雾计算层反馈到plc,然后cnc控制器读取存储在plc中的控制值,控制值与加工指令叠加,以驱动齿轮轮廓磨床的进给驱动系统,实现误差控制。
5.3、雾计算层
scgwo3-bi-lstm网络的预测需要一定的计算能力,并需要与补偿控制器进行通信。因此,将scgwo3-bi-lstm网络模型嵌入到雾计算层中以预测误差并更新狼的位置。另外,机床的运行条件在不断变化,并且该层中的模型需要更新。雾计算层的计算能力和存储容量受到限制,因此更多的历史数据被上载到云计算层,热误差数据的存储以及scgwo3-bi-lstm网络模型的更新和重新训练将在云计算层中完成这减轻了对云计算层带宽的压力。
5.4、云计算层
云计算层具有强大的计算能力和可靠的存储能力,上述三层均不具有以上能力。此外,云计算也比雾计算和边缘计算便宜。云计算的类型很多,例如私有云、公共云和联合云,它们可以帮助保护和交换制造公司的热数据。因此,将在云计算层上定期训练和更新scgwo3-bi-lstm网络模型,这有助于长期使用误差补偿,并降低了物联网的带宽压力和能耗。
6、实验验证
6.1、实验装置
主轴系统是精密齿轮磨床yk73200的核心部件,并进行了热特性实验,如图8所示。涡流位移传感器固定在主轴轴向端面的中心。从传感器的检测表面到端面的距离被确定为1mm,这是因为涡电流传感器的最大范围是2mm。然后确保准确的测量.
获得温度和误差,每秒钟记录一次实验数据,然后将其传输到mist计算层,如图9所示。为了理解热特性,将机床的结构特性和实际工作条件一起考虑。测量了前轴承、后轴承、电机、环境温度以及轴向伸长率和径向误差,表2中列出了实验中的频道设置。
表2实验传感器的机器位置和通道号
为了尽可能接近机床的实际工作条件,对不同速度下的温度和误差进行了测量,以获得一组实际的热特性数据。设置步进速度以实现从1500r/min到3000r/min的速度调节。步进速度分为1500rpm,2000rpm,2500rpm和3000rpm四个阶段,每个阶段运行三个小时,如图10所示。打开冷却系统,关闭切削液。
6.2、mefcs体系结构验证
机床的工作条件复杂,在运行过程中可能会出现异常的热数据。异常的热数据会影响其他正常数据的预测。mae适用于出现异常数据的情况,然后由于其独特的鲁棒性而被用作损失函数。其他两个超参数,包括传递函数和优化算法,对模型也很重要。具有不同传递函数的模型的损失函数曲线,包括elu,softplus,softsign,swish和tanh函数,如图11(a)所示。可以看出,softplus,softsign和tanh函数不适用于所提出的模型,而使用swish传递函数的模型的收敛速度和拟合精度最高。测试了模型的损失函数曲线,其中使用了四种算法作为优化算法:自适应最大池化(adamax),自适应梯度(adagrad),自适应矩(adam)和加速自适应矩(nadam),如图11(b)所示。从中可以看出,以加速自适应矩(nadam)算法为优化算法的模型具有最佳的性能。因此,将nadam优化用作优化算法,将adam算法与加速自适应矩(nadam)结合在一起,即为scgwo-bi-lstm网络模型选择了swish函数和nadam算法。
如图12所示,使用不同的批处理大小拟合工作条件1下的热数据,然后获得损耗曲线。当批处理大小为64时,收敛速度最慢,损耗最小,优化批处理大小以提高预测准确性和收敛速度非常重要。scgwo算法用于优化批处理,以提高bi-lstm网络模型的综合性能。
在本实施例的scgwo算法中,灰狼的位置被视为批处理大小,限制在[0,4]的范围内。批处理大小设置为灰狼位置与128之间的乘积。因此,批处理大小的范围为[0,512]。另外,scgwo算法的填充数和最大迭代数分别设置为3和4。这意味着scgwo算法将总共执行十二个优化。较少的优化可以提高计算效率,因为训练scgwo-bi-lstm网络模型非常耗时。表3中列出了scgwo算法的参数。
表3.scgwo的参数设置
然后将提出的模型的epoch大小设置为300,并将callback函数的earlystopping子函数也引入模型。earlystopping子函数的patience参数设置为5。然后,如果适应性没有显着提高,则模型的训练过程将在五个迭代中提前停止,以有效避免模型的过拟合。隐藏层中的神经元数设置为128,特征和时间步长设置为1。scgwo-bi-lstm网络模型由两个lstm层组成,并且这两个lstm层反向连接。此外,建立了lstm网络和bi-lstm网络模型。它们使用相同的网络参数。当使用scgwo算法的不同控制参数时,将获得不同的批处理大小,最终影响模型的预测性能。然后在scgwo算法中使用,a1,a2和a3三个不同的控制参数,最后根据以上三个控制参数,提出了scgwo1-bi-lstm网络,scgwo2-bi-lstm网络,scgwo3-bi-lstm网络。通过对scgwo算法进行优化,使用,a1,a2和a3的三个不同控制参数,批处理大小分别为128、142和225。为了便于比较,采用random函数,并随机设置lstm网络和bi-lstm网络模型的批处理大小。它们的批处理大小相同,并且使用82作为上述lstm网络和bi-lstm网络模型的批处理大小。最终将获得这些模型的不同性能。
在图13(a)中示出了在工作条件#1下的热伸长曲线,将其用作训练集,然后在工作条件#2下的热伸长率被视为测试集。热伸长率数据的快速变化也客观地反映了运行过程的变化。获得这五个模型的预测结果,如图13(b)所示。结果表明,上述五个模型的预测性能存在一定差异。
lstm网络,bi-lstm网络,scgwo1-bi-lstm网络,scgwo2-bi-lstm网络和scgwo3-bi-lstm网络模型的预测能力η分别为95.77%,96.79%,97.51%,98.45%和98.92%,如表4所示。由于误差数据在bi-lstm网络模型中沿两个方向传播,因此有利于模型理解误差数据的非线性和潜在关系。控制参数a1是线性的,不能很好地处理非线性优化过程,所提出的指数控制参数a3在早期具有较大的值,在后期具有急剧下降的趋势,有利于寻找全局最优值。
表4.模型的预测性能
大批量的历史热数据会连续传输到云平台,以进行存储和模型训练。但是由于工业互联网的带宽有限,因此对于大量误差数据的传输速度极低。此外,因为热误差数据会随着工作条件而发生显着变化,基于scgwo3-bi-lstm网络的误差模型应在系统的实际执行过程中每隔一定时间进行更新。为了控制scgwo3-bi-lstm网络模型的更新频率,设置了精确度阈值以给出该模型的更新标准。如果预测结果降到精度阈值以下,则将向云服务器发送信号,以使用新传输的误差数据来重新训练scgwo3-bi-lstm网络模型以进行误差预测。在上述预测过程中,将使用工作条件1#的所有数据来训练误差模型。但是,不可能将所有工作条件1#的误差数据立即上载到云平台,并且这些数据会逐渐在实际应用中上载。因此,为了减少发送的数据量,仅使用前三千个数据。
本实施例使用的scgwo3-bi-lstm网络模型,将工作条件为1#的前三千个数据用于模型训练,如图14(a)所示,一开始就可以接受预测结果。由于工作条件的变化,预测误差将不再根据先前的状态而变化。因此,经过训练的模型不再适用,并且及时更新模型至关重要。精度阈值设置为6μm。当预测误差超过精度阈值时,激活反馈机制,然后提示云计算更新模型以获得满意的预测结果。如图14(a)所示,预测误差在22431s时超过阈值点。一方面,该模型早期的误差很小,表明该模型非常可靠和适用。另一方面,预测误差增加,并且大于精度阈值。因此,有必要在22431秒后更新scgwo3-bi-lstm网络模型。3000s之后,将在工作条件1#下的下一个3000s中收集的热数据传输到云平台。因此,总共有6000个热数据用于scgwo3-bi-lstm网络模型的再训练。通过scgwo3算法获得了再训练模型的批处理大小,其值为64。在图14(b)中比较了预测的性能,然后在表5中列出。可以看到,更新后的模型的所有指标都得到了极大的优化。另外,将判断程序写入微数据中心,并在边缘计算层判断工作状态是否异常。
表5.更新后的模型和更新前的模型之间的预测性能
本实施例开发了mefcs的界面。诸如平滑,模拟显示,预测模型选择和准确度阈值设置等功能已集成在系统中。平滑功能用于过滤噪声并平滑数据。提供了savitzky-golay方法,二项式方法,fft滤波方法和loess方法。模拟显示功能用于显示通过误差机制建模获得的结果。预测模型选择功能提供了五个建议的模型可供选择,并且所选模型用于预测热误差。精度阈值设置功能用于设置精度阈值,以调整和控制预测误差。选择scgwo3-bi-lstm网络的预测模型,然后在该接口上设置精度阈值。可以获取并显示预测的误差。还评估了所选模型的预测性能。
使用齿轮磨床加工齿轮,在有或没有实施mefcs的情况下,均可获得机加工齿轮的第一,第二,四十一和六十一齿的齿廓偏差。其中,图15显示了采用和未采用mefcs时的齿廓检测结果。采用mefcs时,左齿面的最大齿廓倾斜偏差fhαl从37.5μm减小至5.8μm,右齿面的最大齿廓倾斜偏差fhαr从12.5μm减小到5.2μm。机加工齿轮的齿廓偏差fhα的精度等级从iso5提高到iso3。总齿廓偏差fα的精度等级也从iso6提高到iso5。提出的mefcs的重要意义对于提高齿廓偏差的准确度水平具有重要意义。还证明了热误差的控制模型。一致性好,模型精度高,可以满足实际加工的需要。另外,可以发现,齿廓偏差ffα改善是微不足道的。
在基于数据的误差预测和控制系统中,工业互联网的带宽限制问题一直存在。提出了一种mefcs体系结构用于误差预测和控制。提出了一种具有不同控制参数的scgwo算法,以搜索bi-lstm网络的最佳批处理大小,并将其嵌入到mefcs架构中。所提出的mefcs架构可以准确地预测热误差并大大提高执行效率。最后,在工业数控机床上验证了开发的mefcs体系结构。主要结论如下。
(1)将基于物理的模型与基于数据的模型相结合,建立scgwo3-bi-lstm网络模型。热数据是时间序列数据的一种典型类型,基于数据的模型应具有存储功能。基于物理模型从误差机制的角度证明了bi-lstm网络在误差模型训练中的适用性。网络的预测性能始终是mefcs体系结构的核心。通过scgwo3算法优化了作为关键超参数的批处理大小。结合控制参数的改进以及余弦和正弦搜索策略的引入,提出了scgwo3算法。结果表明,所提出的scgwo3模型可以获得bi-lstm网络模型的最佳批处理大小,然后提出了scgwo3-bi-lstm网络模型,具有最佳的预测性能和收敛速度。
(2)在scgwo1算法中使用了原始控制参数。对数控制参数用于scgwo2算法中。在scgwo3算法中使用了指数控制参数。然后使用的控制参数提出了scgwo3-bi-lstm网络模型,该模型的相应预测精度高于和作为控制参数。使用的控制参数提出了scgwo2-bi-lstm网络模型,该模型的相应预测精度高于作为控制参数的模型。将sigmoid函数引入scgwo3算法可以提高全局和局部搜索能力。
(3)lstm网络,bi-lstm网络,scgwo1-bi-lstm网络,scgwo2-bi-lstm网络和scgwo3-bi-lstm网络模型的预测能力分别为95.77%,96.79%,97.51%,98.45%和98.92%。随着网络中串行数据的双向传播,可以进一步挖掘时序误差数据中的电势和非线性关系。预测能力从95.77%提高到96.79%。将余弦和正弦搜索策略引入到gwo中,然后提出scgwo算法。scgwo算法的控制参数对批处理大小有重大影响。通过优化bi-lstm网络的批处理大小,可以提高bi-lstm网络的预测准确性。然后,scgwo1-bi-lstm网络,scgwo2-bi-lstm网络,scgwo3-bi-lstm网络模型的预测准确性分别从96.79%提高到97.51%,98.45%和98.92%。
(4)通过mefcs架构可以提高误差预测系统的数据传输效率。一方面,边缘计算层的闭环可以实时检测异常工况。另一方面,雾计算层和云计算层的闭环可以实时更新基于数据的模型。然后,使用建议的基于数据的模型(误差数据作为输入),将传输的数据量减少11/16。此外,与设计的系统的实现相比,传输的数据量减少到1/10。设置精度阈值以确定何时需要更新模型。结果表明,具有精度阈值的系统与没有精度阈值的系统相比,预测精度提高了8.31%。通过实施所提出的mefcs,左齿表面的最大齿廓倾斜偏差从37.5μm减小到5.8μm,右齿表面的最大齿廓倾斜偏差从12.5μm减小到5.2μm。机加工齿轮的齿廓偏差的精度等级从iso5提高到iso3。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!