一种基于强化学习和视线法的无人艇路径跟踪方法与流程
本发明属于无人艇路径跟踪控制技术领域,具体涉及一种基于强化学习和视线法的无人艇路径跟踪方法。
背景技术:
强化学习(reinforcementlearning,rl),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习的常见模型是标准的马尔可夫决策过程(markovdecisionprocess,mdp)。按给定条件,强化学习可分为基于模式的强化学习(model-basedrl)和无模式强化学习(model-freerl),以及主动强化学习(activerl)和被动强化学习(passiverl)。强化学习的变体包括逆向强化学习、阶层强化学习和部分可观测系统的强化学习。求解强化学习问题所使用的算法可分为策略搜索算法和值函数(valuefunction)算法两类。深度学习模型可以在强化学习中得到使用,形成深度强化学习。
视线法的导航原理体现在它对舵手操舵和船舶运动的直观理解上。该原理认为:如果使被控船舶的航向保持对准视线角(los角),那么经过适当的控制,就能使被控船舶到达期望的位置,达到航迹跟踪的效果。而且los算法能将传统的控制量从3个自由度的船舶位置和航向角减少到2个自由度的船舶航向角和航行速度,这种特性对于欠驱动船舶的控制尤为重要。视距导航的控制方法就是通过在目标路径上选取合适的导航点,引导无人水面艇跟踪目标导航点,最终使无人水面艇沿着目标路径航行。
在工程实际中,应用最为广泛的调节器控制规律为比例、积分、微分控制,简称pid控制,又称pid调节。pid控制器问世至今已有近70年历史,它以其结构简单、稳定性好、工作可靠、调整方便而成为工业控制的主要技术之一。当被控对象的结构和参数不能完全掌握,或得不到精确的数学模型时,控制理论的其它技术难以采用时,系统控制器的结构和参数必须依靠经验和现场调试来确定,这时应用pid控制技术最为方便。比例控制是一种最简单的控制方式。其控制器的输出与输入误差信号成比例关系。当仅有比例控制时系统输出存在稳态误差(steady-stateerror)。在积分控制中,控制器的输出与输入误差信号的积分成正比关系。对一个自动控制系统,如果在进入稳态后存在稳态误差,则称这个控制系统是有稳态误差的或简称有差系统(systemwithsteady-stateerror)。为了消除稳态误差,在控制器中必须引入“积分项”。积分项对误差取决于时间的积分,随着时间的增加,积分项会增大。这样,即便误差很小,积分项也会随着时间的增加而加大,它推动控制器的输出增大使稳态误差进一步减小,直到接近于零。因此,比例+积分(pi)控制器,可以使系统在进入稳态后几乎无稳态误差。在微分控制中,控制器的输出与输入误差信号的微分(即误差的变化率)成正比关系。自动控制系统在克服误差的调节过程中可能会出现振荡甚至失稳。其原因是由于存在有较大惯性组件(环节)或有滞后(delay)组件,具有抑制误差的作用,其变化总是落后于误差的变化。解决的办法是使抑制误差的作用的变化“超前”,即在误差接近零时,抑制误差的作用就应该是零。这就是说,在控制器中仅引入“比例”项往往是不够的,比例项的作用仅是放大误差的幅值,而需要增加的是“微分项”,它能预测误差变化的趋势,这样,具有比例+微分的控制器,就能够提前使抑制误差的控制作用等于零,甚至为负值,从而避免了被控量的严重超调。所以对有较大惯性或滞后的被控对象,比例+微分(pd)控制器能改善系统在调节过程中的动态特性。
由于los理论认为只要使被控船舶的航向保持对准los角,被控船舶就能达到期望的位置,所以如何获得los角便成了研究的重点所在。在传统los方法中,los角由可视距离δ确定,而δ=n×l是一个固定值,且常常根据人工经验设置.不同船长比n对路径跟踪的影响比较明显,当船长比较小时(目标航向与当前航向偏差较大),跟踪曲线超调量较大;当船长比较大时,无人水面艇靠近目标路径较为缓慢(目标航向与当前航向偏差较小),调节时间过长。常见的调整船长比的方法是模糊控制,但也需要根据人工经验调整。
技术实现要素:
为解决上述问题,本发明公开了一种基于强化学习和视线法的无人艇路径跟踪方法,采用强化学习的方法对可视距离进行合理的预测,让无人艇“学会”根据当前状态动态地调整可视距离,从而使得船舶在航行过程中获得更高精度、更快速的航迹跟踪。
上述的目的通过以下的技术方案实现:
一种基于强化学习和视线法的无人艇路径跟踪方法,该方法包括如下步骤:
s1.搭建仿真模型并定义无人艇运动参数。可利用软件如vrep和gazebo搭建无人艇仿真环境,也可根据无人艇实际运动数据对它的运动模型进行拟合从而获得仿真模型;
s2.设计基于强化学习模型的基本框架,拟采用双层全连接神经网络作为actor当前网络μ(s|θμ)、actor目标网络ν′(s|θμ′)、critic当前网络q(s,a|θq)、critic目标网络q′(s,a|θq′)基本结构,激活函数采用leaky-relu;
s3.设计强化学习和视线法结合的pid控制框架;
s4.对步骤s3中设计好的模型进行训练并保存训练参数。
s5.对于同样的初始状态做对比仿真实验、实艇实验。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s1中所述无人艇运动参数定义为:
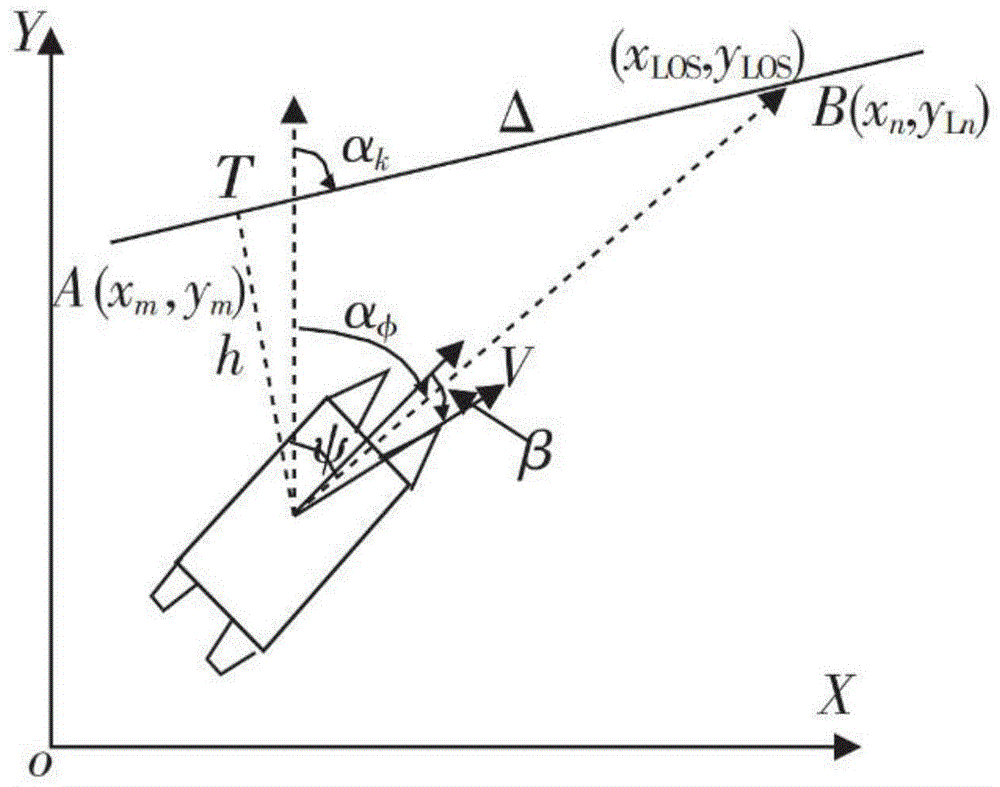
无人艇运动速度v、x轴速度u、y轴速度v、航向角ψ、角速度w、无人艇与目标航线的垂直距离h、目标航线的倾斜角度αk,航向角与目标航线倾角的偏差为αk-ψ,αφ为无人艇期望航向,β为漂角且β=tan-1(v/u),δ为无人水面艇的可视距离,是无人水面艇在路径上的投影点t与导航点(xlos,ylos)之间的距离;
智能体动作a(可视距离δ)为一个连续的正实数,范围为0-m,m可根据航线长度调整;
奖励值r设置为:r=-h;
观测状态s定义为:
s=[u,v,cos(ψ),sin(ψ),w,h,cos(αk),sin(αk),cos(αk-ψ),sin(αk-ψ)]。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s2中所述基于强化学习模型的基本框架中:
(a).actor当前网络μ(s|θμ):负责actor当前网络参数θμ迭代更新,负责根据当前状态s选择当前动作a,用于和环境交互生成下一状态和奖励值r;
(b).actor目标网络μ′(s|θμ′):负责根据经验回放池中采样的状态选择最优动作,actor目标网络参数θμ′定期根据actor当前网络参数θμ更新;
(c).critic当前网络q(s,a|θq):负责critic当前网络参数θq的迭代更新,负责计算当前动作价值q值;
(d).critic目标网络q′(s,a|θq′):负责计算预测动作价值q′值,critic目标网络参数θq′定期根据critic当前网络参数θq更新。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s3中所述强化学习和视线法结合的pid控制框架,其第i步的控制量的计算公式如下:
δi=ai
αφ,i=αk,i+tan-1(-hi/δi)-βi
erri=αφ,i-ψi
ii=ii-1+ki×erri
dui=kp×erri+ii
其中δi为无人艇第i步的可视距离,ai为第i步强化学习网络计算得到的动作值,αφ,i、αk,i分别是第i步无人艇期望航向和直线路径方向,ψi、βi、erri、dui分别为第i步无人艇航向、漂角、航向误差、控制量偏差,ii、ii-1分别为第i步、第i-1步的积分项,ki为积分控制的系数,kp为比例控制的系数,min、max分别为最小控制量、最大控制量,ul、ur分别为左电机控制量、右电机控制量,u0为基础控制量。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s4中所述对步骤s3中设计好的模型进行训练并保存训练参数的具体方法是:
1)初始化参数:迭代次数m,每次迭代最大步数t,软更新参数τ,critic网络和actor网络学习率,衰减因子γ;
2)随机初始化权重θq、θμ、θq′和θμ′,初始化经验池r,初始化仿真环境;
3)初始化随机噪声η;
4)从仿真环境获得第i步观测状态si:
si=[ui,vi,cos(ψi),sin(ψi),w,h,cos(αk),sin(αk),cos(αk-ψ),sin(αk-ψ)]
5)对于第i步,根据当前网络和随机噪声获得动作值ai=μ(si|θμ)+ηi,并根据下式计算控制量,执行控制命令与环境交互,获得第i步奖励值ri=-hi和第i+1步观测状态si+1,存储记录(si,ai,ri,si+1)在经验池r中;
δi=ai
αφ,i=αk,i+tan-1(-hi/δi)-βi
erri=αφ,i-ψi
ii=ii-1+ki×erri
dui=kp×erri+ii
6)当经验池存储数量达到一万以上,从中随机抽取n个记录(st,at,rt,st+1),其中t是随机的,计算目标值函数yt:
yt=rt+γq′(st+1,μ′(st+1|θμ′)|θq′)
7)根据损失l更新critic网络:
8)根据梯度
9)更新参数θq′、θμ′:
θq′←τθq+(1-τ)θq′
θμ′←τθμ+(1-τ)θμ′
10、若未达到最大步数t,重复4-9;
11、若未达到最大迭代次数m,重复3-10;
12、保存训练参数。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s5中所述具体实验方法为:
对于同样的初始状态(无人艇具有同样的起始位置、航向、速度、目标航线等),对使用强化学习方法进行可视距离调整和未使用强化学习的两种情况做对比仿真实验和实艇实验。
本发明的有益效果是:
解决了传统los方法中可视距离δ不可调或根据人工经验调整δ既依赖经验、复杂繁琐,且不具有广泛适应性的问题。本发明根据船舶实际运动状态利用强化学习对可视距离进行合理的、连续的预测,让无人艇“学会”根据当前状态动态地调整控制量,从而使得船舶在航行过程中获得更高精度、更快速的航迹跟踪。
附图说明
图1是视线法原理图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
基于强化学习和视线法的无人艇路径跟踪方法,该方法包括如下步骤:
s1.搭建仿真模型并定义无人艇运动参数。可利用软件如vrep和gazebo搭建无人艇仿真环境,也可根据无人艇实际运动数据对它的运动模型进行拟合从而获得仿真模型;
s2.设计基于强化学习模型的基本框架,拟采用双层全连接神经网络作为actor当前网络μ(s|θμ)、actor目标网络μ′(s|θμ′)、critic当前网络q(s,a|θq)、critic目标网络q′(s,a|θq′)基本结构,激活函数采用leaky-relu;
s3.设计强化学习和视线法结合的pid控制框架;
s4.对步骤s3中设计好的模型进行训练并保存训练参数。
s5.对于同样的初始状态做对比仿真实验、实艇实验。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s1中所述无人艇运动参数定义为:
无人艇运动速度v、x轴速度u、y轴速度v、航向角ψ、角速度w、无人艇与目标航线的垂直距离h、目标航线的倾斜角度αk,航向角与目标航线倾角的偏差为αk-ψ,αφ为无人艇期望航向,β为漂角且β=tan-1(v/u),δ为无人水面艇的可视距离,是无人水面艇在路径上的投影点t与导航点(xlos,ylos)之间的距离;
智能体动作a(可视距离δ)为一个连续的正实数,范围为0-m,m可根据航线长度调整;
奖励值r设置为:r=-h;
观测状态s定义为:
s=[u,v,cos(ψ),sin(ψ),w,h,cos(αk),sin(αk),cos(αk-ψ),sin(αk-ψ)]。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s2中所述基于强化学习模型的基本框架中:
(a).actor当前网络μ(s|θμ):负责actor当前网络参数θμ迭代更新,负责根据当前状态s选择当前动作a,用于和环境交互生成下一状态和奖励值r;
(b).actor目标网络μ′(s|θμ′):负责根据经验回放池中采样的状态选择最优动作,actor目标网络参数θμ′定期根据actor当前网络参数θμ更新;
(c).critic当前网络q(s,a|θq):负责critic当前网络参数θq的迭代更新,负责计算当前动作价值q值;
(d).critic目标网络q′(s,a|θq′):负责计算预测动作价值q′值,critic目标网络参数θq′定期根据critic当前网络参数θq更新。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s3中所述强化学习和视线法结合的pid控制框架,其第i步的控制量的计算公式如下:
δi=ai
αφ,i=αk,i+tan-1(-hi/δi)-βi
erri=αφ,i-ψi
ii=ii-1+ki×erri
dui=kp×erri+ii
其中δi为无人艇第i步的可视距离,ai为第i步强化学习网络计算得到的动作值,αφ,i、αk,i分别是第i步无人艇期望航向和直线路径方向,ψi、βi、erri、dui分别为第i步无人艇航向、漂角、航向误差、控制量偏差,ii、ii-1分别为第i步、第i-1步的积分项,ki为积分控制的系数,kp为比例控制的系数,min、max分别为最小控制量、最大控制量,ul、ur分别为左电机控制量、右电机控制量,u0为基础控制量(一般设置为无人艇正常直行时的控制值)。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s4中所述对步骤s3中设计好的模型进行训练并保存训练参数的具体方法是:
1)初始化参数:迭代次数m,每次迭代最大步数t,软更新参数τ,critic网络和actor网络学习率,衰减因子γ;
2)随机初始化权重θq、θμ、θq′和θμ′,初始化经验池r,初始化仿真环境;
3)初始化随机噪声η;
4)从仿真环境获得第i步观测状态si:
si=[ui,vi,cos(ψi),sin(ψi),w,h,cos(αk),sin(αk),cos(αk-ψ),sin(αk-ψ)]
5)对于第i步,根据当前网络和随机噪声获得动作值ai=μ(si|θμ)+ηi,并根据下式计算控制量,执行控制命令与环境交互,获得第i步奖励值ri=-hi和第i+1步观测状态si+1,存储记录(si,ai,ri,si+1)在经验池r中;
δi=ai
αφ,i=αk,i+tan-1(-hi/δi)-βi
erri=αφ,i-ψi
ii=ii-1+ki×erri
dui=kp×erri+ii
6)当经验池存储数量达到一万以上,这里可根据计算机内存适当修改,从中随机抽取n个记录(st,at,rt,st+1),其中t是随机的,计算目标值函数yt:
yt=rt+γq′(st+1,μ′(st+1|θμ′)|θq′)
7)根据损失l更新critic网络:
8)根据梯度
9)更新参数θq′、θμ′:
θq′←τθq+(1-τ)θq′
θμ′←τθμ+(1-τ)θμ′
10、若未达到最大步数t,重复4-9;
11、若未达到最大迭代次数m,重复3-10;
12、保存训练参数。
所述的基于强化学习和视线法的无人艇路径跟踪方法,步骤s5中所述实验方法为:
对于同样的初始状态(无人艇具有同样的起始位置、航向、速度、目标航线等),对使用强化学习方法进行可视距离调整和未使用强化学习的两种情况做对比仿真实验和实艇实验。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!