一种融合在线学习的AGV实时调度方法与流程
一种融合在线学习的agv实时调度方法
技术领域
1.本发明属于航空智能制造技术领域,尤其涉及一种融合在线学习的agv 实时调度方法。
背景技术:
2.目前国内智能物流成为实现智能制造的关键环节,agv在物流系统中承担 零件的搬运工作,根据系统的要求,及时的将对应的零件送到合适的地方。因 此提高agv小车的工作效率对公司的发展意义重大。与国外相比,国内物流 需求量更大,实时调控的研究工作至关重要。
3.目前国内多agv在实时调度方面受算法的影响较大,复杂的空间环境影 响多agv的调度效率。若通过提高agv小车的硬件设施来提高运算速度需要 巨大的成本,不容易实现,但对目前的算法进行优化,可以大大提高agv的 工作效率,并在配送过程中实现最优配送安排,是适合推广的方法。
技术实现要素:
4.针对上述问题,本发明的目的在于提供一种融合在线学习的agv实时调 度方法,通过将遗传算法和强化学习系统相结合,使用遗传算法解决agv 小车的调度问题,在调度过程中使用强化学习系统解决agv避让及路径规 划问题,并且合理地为agv分配任务。该发明降低了算法的复杂度,提高 了agv小车的工作效率,可以带来更大的经济效益。
5.为解决上述技术问题,本发明所采用的技术方案是:
6.一种融合在线学习的agv实时调度方法,所述方法包括:
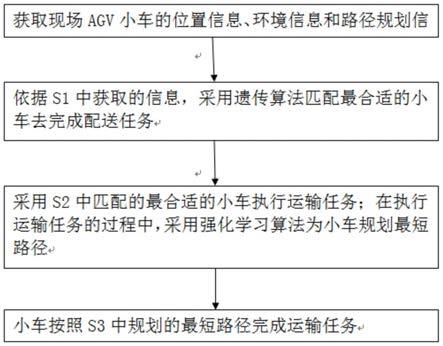
7.s1,获取现场agv小车的位置信息、环境信息和路径规划信息;
8.s2,依据s1中获取的信息,采用遗传算法匹配最合适的小车去完成配送任 务;
9.s3,采用s2中匹配的最合适的小车执行运输任务;在执行运输任务的过程 中,采用强化学习算法为小车规划最短路径;
10.s4,小车按照s3中规划的最短路径完成运输任务。
11.本发明技术方案的特点和进一步的改进为:
12.(1)s4中,小车在完成运输任务的过程中,使用改进的人工势场法实现 自主避障。
13.(2)s1中现场agv小车的位置信息、环境信息和路径规划信息,具体为: agv小车的位置信息指为agv小车设定的随机初始位置;
14.环境信息指agv小车可到达的区域内的多个障碍物的随机初始位置,以及 所需运输的多个工件的随机初始位置;
15.路径规划信息指agv小车的当前位置,需要运输的工件的位置,以及工件 要运输到的目的位置所组成的三点初始路径。
16.(3)s2中,采用遗传算法匹配最合适的小车的过程中,设计目标函数为: f=min
1≤k≤m
{max
1≤i≤n
{l
ik
}};
17.其中,f为目标函数,表示选择每种运输方案中完成某个工件运输所用 的最长时间,并在多种运输方案中,选择最长时间的最小值对应的运输方 案为最优运输方案;;
18.l为工件配送时间,l
ik
表示工件i在agv小车k上的完成配送的时间;i 为配送目标点,i=1,2,
…
,n;n为代配送的工件总数量;k为第k个agv小 车,k=1,2,
…
,m;m为agv小车的总数量。
19.(4)s3中,在执行运输任务的过程中,采用强化学习算法为小车规划最 短路径的过程,具体为:
20.s31,搭建预设大小的栅格地图作为二维仿真环境;
21.s32,设置agv小车在二维栅格图中所建的环境中所采取的运动;
22.s33,采用非线性的分段函数表示即时奖励函数,用一个标量r表示,通过 奖励函数的设计使agv小车碰到不同物体时反馈当前状态和奖励值,以此来改 变agv小车行为;
23.s34,初始化环境状态以及开始探索环境,小车从起始点出发,获取当前状 态对应的q值,通过贪婪决策找出该q值对应的动作,并记录当前状态的坐标; 再通过优势函数判断当前选取的动作是否有利,若该动作得到正的奖励值,执 行该动作并转移到下一个状态,得到奖励值,并存储到样本回放缓存区;
24.s35,以情景数的平均奖励值来评估当前策略是否为最优策略或最优路径。
25.(5)s32中,设置agv小车在二维栅格图中所建的环境中所采取的运动, 具体为:
26.定义agv小车的动作空间模型为上、下、左、右四个离散动作,即 a=[0,1;0.-1;-1,0;1,0],将agv小车作为为一个质点,用圆圈表示,目标点用 方框表示。
[0027]
(6)s34中,
[0028]
在小车探索状态时,若当前状态坐标上有障碍物,则奖励值为-1;如果当 前状态坐标上没有障碍物,则返回奖励值为1,进入下一个状态;如果当前状 态是目标点,则返回奖励值为2,规划出最终路径;
[0029]
(7)s4中,使用人工势场法实现自主避障的过程中,人工势场法具体为:
[0030]
在agv小车之间以及agv小车和周围障碍物中引入虚拟的势场;
[0031]
当agv小车之间的距离或是agv小车和障碍之间的距离小于期望的距离时 表现为斥力,使agv小车远离;
[0032]
当agv小车之间的距离大于期望的距离时为表现为引力,使agv小车相互 靠近。
[0033]
(8)使用人工势场法实现自主避障具体为:
[0034]
对于每个agv小车,将其视为质点,通信半径为r,agv小车之间的期望 距离为dα,agv小车和障碍物之间的期望距离为dβ;则agv小车所受到的力 为通信半径内来自其他agv小车的力和障碍物的斥力的合力,当合力为0时, agv小车达到平衡状态;
[0035]
当所有agv小车都能处于平衡状态时,就实现了自主避障。
[0036]
本发明与现有算法相比的优点在于:本发明中采用强化学习作为一种从环 境状态到行为映射的学习方法,可以用于不确定性环境,并且可以自动适应环 境的变化;本发明中强化学习运用q-learning算法,能实时更新状态,使智能 体能实时根据当前状态进行模型优化;本发明中多agv调度用的是遗传算法, 可以求解复杂结构的优化问题,并且算法的搜索性能不受函数的性能限制;本 发明中使用了云边协同技术实现agv小车得到现场运行的数据及物流运输的最 短路径与时间的定量评估。
附图说明
[0037]
图1为本发明实施例提供的一种融合在线学习的agv实时调度方法的流程 示意图;
[0038]
图2为本发明中的环境二维地图;
[0039]
图3为本发明中agv小车运行轨迹图;
[0040]
图4为本发明中q-learning算法流程框图;
[0041]
图5为车间小车路径规划时间与工件配送次序表。
具体实施方式
[0042]
下面结合附图和具体实施方式来对本发明的技术方案作进一步的阐述。
[0043]
本发明实施例提供一种融合在线学习的agv实时调度方法,如图1所示, 所述方法包括:
[0044]
s1,获取现场agv小车的位置信息、环境信息和路径规划信息;
[0045]
s2,依据s1中获取的信息,采用遗传算法匹配最合适的小车去完成配送任 务;
[0046]
s3,采用s2中匹配的最合适的小车执行运输任务;在执行运输任务的过程 中,采用强化学习算法为小车规划最短路径;
[0047]
s4,小车按照s3中规划的最短路径完成运输任务。
[0048]
s4中,小车在完成运输任务的过程中,使用改进的人工势场法实现自主避 障。
[0049]
s1中现场agv小车的位置信息、环境信息和路径规划信息,具体为:agv 小车的位置信息指为agv小车设定的随机初始位置;
[0050]
环境信息指agv小车可到达的区域内的多个障碍物的随机初始位置,以及 所需运输的多个工件的随机初始位置;
[0051]
路径规划信息指agv小车的当前位置,需要运输的工件的位置,以及工件 要运输到的目的位置所组成的三点初始路径。
[0052]
具体的,使用python语言和tkinter库来搭建二维仿真环境。路径规划算 法实验环境是30*30的栅格地图,设置的障碍与调研的某加工车间基本相同, 起始点和目标点也是随机设置。搭建的环境二维地图如图2。图中黑色部分为 障碍,白色部分为非障碍区域。matlab仿真算法的目标是初始化环境状态以及 开始探索环境。
[0053]
动作空间设置:该设置是设置agv小车在二维栅格图中所建的环境中所采 取的运动,本实验是定义机器人的真实动作空间模型为上、下、左、右四个离 散动作,即a=[0,1;0.-1;-1,0;1,0]。将agv小车近似为一个质点,用圆圈表 示,目标点用方框表示。
[0054]
奖励函数是通过反馈来评价agv小车从当前状态转移到另一状态所执行的 动作的优劣,通常用一个标量r表示。针对本课题验环境的agv小车采用非线 性的分段函数表示即时奖励函数,小车在探索环境时通过可行区域,则获得1 的立即奖赏;小车在碰到障碍物时,则获得-1的奖赏值,小车到达目标位置时, 会得到2的奖赏值。最后通过总的奖赏值来判断该策略是否为最优策略。
[0055]
图3为其中一次的路径仿真结果,通过多次运算获得最优的q函数后,便 能获取最优路径。q学习算法具体流程如图4所示。
[0056]
对于多agv的调度问题则需要使用遗传算法来解决,为了把问题表达的更 清楚,
下面用数学符号表示小车调度问题:设待配送工工件集ji={j1,j2,
…
, jn},配送的agv小车机器集mk={m1,m2,mi,
…
,mm},每个配送的工件ji有不 同的被配送次数,每个工件的配送次数是vi={v
1i
,v
2i
,
…
,v
jii
},每个配送的 工件v
jii
必须在配送在指定目标点m(v
jii
)∈mk,即每个工序v
jii
配送的目标点 m(v
jii
)固定,其中m(v
jii
)表示工件ji的第v
jii
道工序在由小车机器人mi上进行 配送。其中k=1,2,
…
,m。实际的车间调度系统较为复杂,作为其研究在建 模过程中为了满足调度目标使问题简化。
[0057]
作如下假设:
[0058]
1)在配送过程中,对加工设备损坏、小车出现故障的情况不予考虑。
[0059]
2)每台agv小车每次只能完成一个配送任务。
[0060]
3)各工件的配送路径及配送时间是实时规划的,其它辅助加工时间不予考 虑。
[0061]
4)所有agv小车机器在t=0时刻都可用。
[0062]
5)所有工件在t=0时刻都可被配送。
[0063]
6)除有紧急情况外,各工件的配送一旦开始配送就不能中断。
[0064]
7)工件各被配送次序之间一定要满足先后约束条件。
[0065]
由于研究的小车调度问题是以所有工件的配送最终完工时间最短为调度最 优目标,故目标函数可以设计为:
[0066]
f=min
1≤k≤m
{max
1≤i≤n
{l
ik
}}
[0067]
式中:f为目标函数,表示选择每种运输方案中完成某个工件运输所 用的最长时间,并在多种运输方案中,选择最长时间的最小值对应的运输 方案为最优运输方案;l为工件配送时间,l
ik
表示工件i在agv小车k上 的完成配送的时间;i为配送目标点,i=1,2,
…
,n;n为代配送的工件 总数量;k为第k个agv小车,k=1,2,
…
,m;m为agv小车的总数量。
[0068]
每种运输方案为当前环境下,采用不同的多个小车将待运输的工件运 输到目的地的方案。
[0069]
该目标函数的约束条件为:
[0070]
l
ik-t
ik
≥l
ih
ꢀꢀꢀ
(5)
[0071]
l
jk-l
ik
≥t
jk
ꢀꢀꢀ
(6)
[0072]
公式(5)可以描述为工件配送的优先约束条件:假设agv小车h先于小车 k对工件i进行配送,l
ik
表示工件i在agv小车k上的完成配送的时间(到达 目标点的时刻),l
ih
表示工件i在小车h上进行配送后的送达时间(到达目标 点的时刻),t
ik
表示工件i在agv小车k上的配送时间(配送花费的时间)。
[0073]
公式(6)可以描述为agv小车选择优先约束条件:假设工件i和工件j 在某一时刻都要需要小车k进行配送,如果工件i任务先于工件j任务下发, 先配送工件i。其中,l
ik
表示工件i在小车k上的完工时间,t
ik
表示工件i在 小车k上的配送时间,l
ih
表示工件i在小车h上的完工时间,l
jk
表示工件j在 小车k上的完工时间,t
jk
表示工件j在小车k上的配送时间,m为小车数量,n 为工件数。
[0074]
进行仿真实验,以6
×
10调度问题为例,算例相关参数为:工件配送任务 ji={1,2,3,4,5,6},其中i=1,2,3,4,5,6;agv小车数量mj={1,2, 3,4,5,6,7,8,9,10},其中j=1,2,3,4,5,6,7,8,9,10;每个 工件优对应的最终目标点及目标点过程中设置的配送次序点。从图5可以看出, 每个工件的配送次序和各配送中所花费的时间。
[0075]
经多次仿真,当取种群数目是100、选择概率0.8、交叉概率是0.8、变异 概率是0.6、迭代次数50时,适应度最优且最优解为42。
[0076]
云边协作中,中心云对所处不同位置的机器人下达指令,将其取得目标物, 同时送回到指定地点,为了在配送过程中完成自主避障,使用改进的人工势场 法,考虑行进过程中的拓扑切换,改进控制协议使agv小车集群在完成编队任 务时能够实现避障算法的优化。
[0077]
人工势场法是在智能agv小车之间以及智能agv小车和周围环境中引入虚 拟的势场,当智能agv小车之间的距离或是智能agv小车和障碍之间的距离小 于期望的距离时表现为斥力,使智能agv小车远离;当智能agv小车之间的距 离大于期望的距离时为表现为引力,使智能agv小车相互靠近。对于每个智能 agv小车,不考虑其复杂的机械模型和气动原理,将其视为质点,通信半径为r, 智能agv小车之间的期望距离为dα,智能agv小车和障碍物之间的期望距离 为dβ。那么,智能agv小车所受到的力为通信半径内来自其他智能agv小车 的力和障碍物的斥力的合力,当合力为0时,智能agv小车达到平衡状态。当 所有智能agv小车都能处于平衡状态时,就能实现安全的编队避障行走。
[0078]
使用云边协同计算后,实现agv小车物流配送,智能agv小车配送货物、 运动状态情况及环境情况说明如下:
[0079]
(1)以一架智能agv小车为中心,它周围的区域是指包括障碍物和其邻域 内的智能agv小车的范围。
[0080]
(2)环境中的动态障碍物是可以被智能agv小车检测到的。
[0081]
(3)所有智能agv小车都能接收到领域内的智能agv小车,以及障碍物的 信息。包括位置,速度,障碍物半径等。
[0082]
(4)领队的一台小车带领一队小车在行驶过程中实现自主动态避障,并实 时记录小车当前的运动状态,以及周围环境障碍物状态等。
[0083]
(5)小车完成一次配送货物的任务后,在当前位置继续开始第二次的配送 任务。小车在任意起始地,可以完成到目标点的配送任务。
[0084]
本发明实施例提供了一种融合在线学习的agv实时调度模型的构建方法, 优化了agv调度的实时性,实现了为多agv小车合理分配任务的功能。通过将 遗传算法和强化学习系统相结合,使用遗传算法解决agv小车的调度问题,在 调度过程中使用强化学习系统解决agv避让及路径规划问题,并且合理地为agv 分配任务。引入了云边协同计算技术,完成航空加工车间的小车调度及路径规 划任务,且在调度过程中实现资源与需求的合理匹配,小车的路径规划距离最 短的目标。该发明降低了算法的复杂度,提高了agv小车的工作效率,可以为 公司带来更大的经济效益。
[0085]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领 域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则 之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之 内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1