一种变学习步长的梯度迭代前馈整定方法
1.本发明涉及一种超精密运动台的前馈整定方法,尤其是一种变学习步长的梯度迭代前馈整定方法,属于超精密运动控制技术领域。
背景技术:
2.针对超精密运动控制领域中具有重复运动特性的超精密运动台的运动控制研究,目前比较有代表性的包括两类,一类为常规迭代学习算法,如授权公告号为cn110703693b、名称为“一种机床进给系统的迭代学习前馈控制方法及系统”的发明专利申请,将迭代学习前馈控制方法与pid控制方法结合起来,实现了跟踪位置跟踪误差、轮廓误差的控制,进而实现机床进给系统模块的控制,具有加工精度高、动态响应快的优点;另一类为模糊整定算法,如授权公告号为cn112486099b、名称为“基于模糊pid自整定计算的超精密车床运动控制方法”的发明专利申请,根据预设位置与实际位置的偏差值及偏差值变化率,采用模糊pid控制算法计算出控制输出量,并将控制输出量输入至控制系统中来控制直线运动导轨的运动。
3.然而前者存在当系统输入参考轨迹即机床加工任务发生变化时,系统性能将会明显恶化,任务适应性较差的问题。后者属于一种智能算法,应用条件需要大量的实验数据,适用于对系统的模型认识不是很深刻的情况,而在超精密运动台控制中系统的模型结构相对明确,采用模糊pid控制算法会存在实验成本过大的问题。
技术实现要素:
4.为解决背景技术存在的问题,本发明提供一种变学习步长的梯度迭代前馈整定方法,它引入了数据投影与变增益的方法,降低实验数据量的要求并且适应性更强,满足前馈参数的快收敛、强鲁棒性以及高精度的要求。
5.为实现上述目的,本发明采取下述技术方案:一种变学习步长的梯度迭代前馈整定方法,包括轨迹生成器cr和超精密运动台闭环控制系统形成的控制系统,所述超精密运动台闭环控制系统包括反馈控制器c
fb
(q)、前馈控制器和超精密运动台p(q),输入信号包括所述轨迹生成器cr生成的参考轨迹r、所述前馈控制器生成的前馈控制信号uj和已知结构的外部扰动fj,输出信号包括超精密运动台p(q)的实际位置信号yj和位置误差信号ej,所述前馈整定方法包括以下步骤:
6.步骤一:由轨迹生成器cr生成超精密运动台p(q)的参考轨迹r,规定最大迭代次数n和预期性能指标ma;
7.步骤二:根据超精密运动台p(q)与外部扰动fj的结构模型,确定参数化前馈基函数ψ
rf
,并通过对ψ
rf
进行qr分解得到正交投影矩阵γ;
8.步骤三:初始化,令j=0,θj=0;
9.步骤四:进行第j次迭代实验,测量实际位置信号yj,与参考轨迹r作差,得到第j次
迭代实验的位置误差ej,ej=r-yj;
10.步骤五:给出前馈参数更新算法通过基于投影的数据驱动方法估计梯度的投影其中ε表示误差的投影;
11.步骤六:根据公式更新前馈参数θj;
12.步骤七:得到更新后的前馈参数θj并判断其是否收敛,若是则停止迭代,若否则令j=j+1再返回步骤四,开始下一次迭代实验。
13.与现有技术相比,本发明的有益效果是:常规的迭代学习算法和模糊整定算法虽然可以实现控制误差的收敛,但任务适应性差、实验数据要求较多,并且易受到外部扰动与噪声影响,鲁棒性较差,而本发明引入数据投影与变增益的方法,降低了实验数据量的要求,在保证前馈参数收敛速度和精度的条件下,增强了对不同轨迹任务的适应性以及对模型不确定性和外部扰动的鲁棒性,减少了参数收敛后的波动现象,提升超精密运动台的运动性能。
附图说明
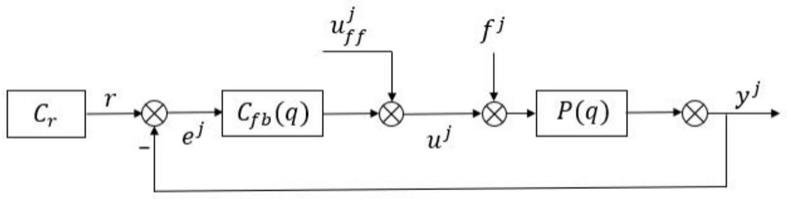
14.图1是本发明涉及的控制系统的结构原理图;
15.图2是本发明的变学习步长的梯度迭代前馈整定方法的流程示意图;
16.图3是本发明的前馈整定方法与现有方法的常规迭代学习算法在输入轨迹变动时任务适应性的对比参照图。
具体实施方式
17.下面将结合本发明实施例中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
18.参照图1所示,一种变学习步长的梯度迭代前馈整定方法,其涉及的控制系统为现有常规控制系统,包括轨迹生成器cr和超精密运动台闭环控制系统,所述超精密运动台闭环控制系统包括反馈控制器c
fb
(q)、前馈控制器和超精密运动台p(q),输入信号包括轨迹生成器cr生成的参考轨迹r、前馈控制器生成的前馈控制信号uj和已知结构的外部扰动fj,输出信号包括超精密运动台p(q)的实际位置信号yj和位置误差信号ej;
19.参照图2所示,具体的前馈整定方法包括以下步骤:
20.步骤一:由轨迹生成器cr生成超精密运动台p(q)的参考轨迹r,规定最大迭代次数n和预期性能指标ma;
21.步骤二:根据超精密运动台p(q)与外部扰动fj的结构模型,确定参数化前馈基函数ψ
rf
,并通过对ψ
rf
进行qr分解得到正交投影矩阵γ;
22.具体的,前馈控制器的参数化由两部分组成:
23.其中,部分目标在于补偿由参考轨迹r引起的误差。选取一组能体现控制对象逆模型特性的多项式基函数并选择对应的前馈参数将它们线性组合得到基于对象模型的参数化前馈控制量
[0024][0025]
令ψr(k)=ψ(q)r(k),得到
[0026]
其中,部分目标在于补偿由外部扰动fj引起的误差。测量外部扰动fj,得到其模型结构相反数的函数并选择对应的前馈参数将它们线性组合得到用于补偿外部扰动fj的前馈控制量
[0027][0028]
综合以上,得到系统前馈控制量的参数化方案:
[0029][0030]
其中,ψ
rf
(k)=[ψr(k) ψf(k)]∈r1×n,为前馈参数,n=nr+nf。
[0031]
系统前馈控制量对应的lifted形式为:
[0032][0033]
其中,ψ
rf
∈rn×n为ψ
rf
(k)对应的lifted形式。
[0034]
对得到的前馈基函数ψ
rf
进行qr分解得到正交投影矩阵γ。
[0035]
步骤三:初始化,令j=0,θj=0;
[0036]
步骤四:进行第j次迭代实验,测量实际位置信号yj,与参考轨迹r作差,得到第j次迭代实验的位置误差ej,ej=r-yj;
[0037]
步骤五:给出前馈参数更新算法通过基于投影的数据驱动方法估计梯度的投影其中ε表示误差的投影;
[0038]
具体的,有在已得到正交投影矩阵γ的基础上对进行估计:
[0039]
φ
rf
为φ
rf
(k)的lifted形式,φ
rf
(k)的定义如下:
[0040]
φ
rf
(k)=t(q)ψ
rf
(k)=t(q)[ψr(k) ψf(k)]=[φr(k) φf(k)]
[0041]
其中,
[0042]
首先估计φr(k),得到其表达式为:
[0043][0044]
其中,为实际位置信号yj中,仅由参考轨迹r激励的输出成份;
[0045]
用系统实际测量信号yj作为的估计值,即采用数据驱动的方法,得到:
[0046][0047]
再估计φf(k),得到其表达式为:
[0048]
φf(k)=t(q)ψf(k)=c
fb
(q)-1
g(q)ψf(k)
[0049]
由于在实际应用中,一般推力波动的主要谐波成分在系统控制带宽以内,所以认为g(q)ψf(k)=ψf(k),得到:
[0050][0051]
综合以上,得到φ
rf
(k)的估计值:
[0052][0053]
所以φ
rf
的估计值为:
[0054][0055]
其中,为φj(k)的lifted形式,分别为的lifted形式。
[0056]
步骤六:根据公式更新前馈参数θj;
[0057]
本步骤中,梯度的投影误差的投影εj=γ
tej
;
[0058]
步骤七:得到更新后的前馈参数θj并判断其是否收敛,若是则停止迭代,若否则令j=j+1再返回步骤四,开始下一次迭代实验;
[0059]
本步骤中,前馈参数θj是否收敛的判断条件为预期性能指标ma或最大迭代次数n,即当系统位置误差ej≤ma或实际迭代次数n≥n时,判断其满足收敛条件,否则不满足收敛条件。
[0060]
参照图3所示,通过本发明的前馈整定方法与现有方法的常规迭代学习算法在输入轨迹变动时任务适应性的对比可以看出:假设共进行80次仿真实验,前40次实验中,输入参考轨迹为r1,从第41次迭代开始,输入参考轨迹变为r1,可以看到现有的常规迭代学习算法在输入参考轨迹发现变化时,位置误差ej突然增大,即控制性能急剧恶化,而本发明的前馈整定方法则能一直保持较好的控制性能,即对不同输入参考轨迹的任务适应性较好。
[0061]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的装体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同条件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0062]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包
含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1