一种模型训练方法、装置、存储介质及电子设备与流程
本说明书涉及自动驾驶,尤其涉及一种模型训练方法、装置、存储介质及电子设备。
背景技术:
1、随着科技的发展,自动驾驶技术逐渐普及。
2、自动驾驶设备的行驶依赖于搭载在其自身的自动驾驶系统,为了保证行驶安全,自动驾驶设备在行驶的过程中需要以避让周围的障碍物为目的实现对自身的控制。例如,在纵向上作出超过障碍物的先行决策,或指示自动驾驶设备在障碍物之后行驶的让行决策,等等。
3、但是,在实际的行车过程中,若以所感知到的所有障碍物都不加区分地进行避让,往往会由于避让对自动驾驶设备行驶影响较小的障碍物而限缩自动驾驶设备可选的控制量的范围,从而导致难以实现对自动驾驶设备较为理想的控制。
技术实现思路
1、本说明书提供一种模型训练以及自动驾驶设备的控制方法、装置、存储介质及电子设备,以部分的解决现有技术存在的上述问题。
2、本说明书采用下述技术方案:
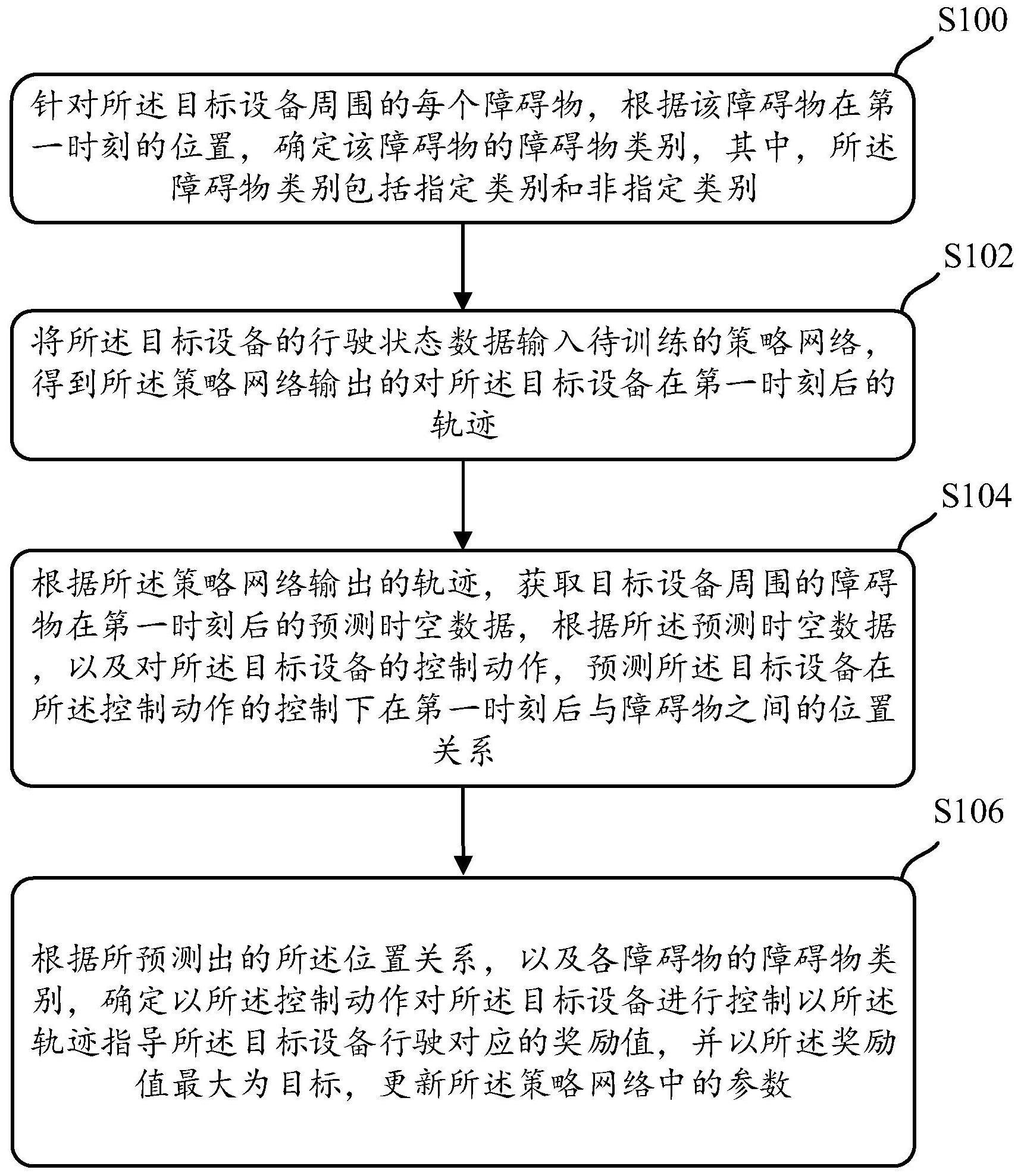
3、本说明书提供了一种模型训练方法,包括:
4、针对所述目标设备周围的每个障碍物,根据该障碍物在第一时刻的位置,确定该障碍物的障碍物类别,其中,所述障碍物类别包括指定类别和非指定类别;
5、将所述目标设备的状态数据输入待训练的策略网络,得到所述策略网络输出的所述目标设备在第一时刻后的轨迹;
6、根据所述策略网络输出的轨迹,预测所述目标设备在第一时刻后与障碍物之间的位置关系;
7、根据所预测出的所述位置关系,以及各障碍物的障碍物类别,确定以所述轨迹指导所述目标设备行驶对应的奖励值,并以所述奖励值最大为目标,更新所述策略网络中的参数。
8、可选地,确定该障碍物的障碍物类别,具体包括:
9、确定第一时刻该障碍物在指定方向上与所述目标设备之间的相对位置;
10、将在指定方向上位于所述目标设备前方的障碍物确定为指定类别的障碍物;将在指定方向上位于所述目标设备后方的障碍物确定为非指定类别的障碍物。
11、可选地,所述状态数据包括第一状态数据和第二状态数据,其中,所述第一状态数据所基于的坐标系为第一坐标系,所述第二状态数据所基于的坐标系为第二坐标系;
12、将所述目标设备的状态数据输入待训练的策略网络,得到所述策略网络输出的所述目标设备在第一时刻后的轨迹,具体包括:
13、将第一状态数据输入所述策略网络的第一特征提取子网,得到所提取出的第一状态特征;将第二状态数据输入所述策略网络的第一特征提取子网,得到所提取出的第二状态特征;
14、将所述第一状态特征和所述第二状态特征输入所述策略网络的融合特征子网,得到所述融合特征子网输出的所述目标设备在第一时刻后的轨迹。
15、可选地,确定以所述轨迹指导所述目标设备行驶对应的奖励值,具体包括:
16、当预测出指定类型的障碍物满足预先设定的风险条件时,将第一奖励值作为以所述轨迹指导所述目标设备行驶对应的奖励值;当预测出非指定类型的障碍物满足预先设定的风险条件时,将第二奖励值作为以所述轨迹指导所述目标设备行驶对应的奖励值;其中,所述第一奖励值小于所述第二奖励值。
17、可选地,确定以所述轨迹指导所述目标设备行驶对应的奖励值,具体包括:
18、将所述目标设备的在第一时刻的状态数据,以及所述策略网络输出的所述目标设备在第一时刻后的轨迹输入至评价网络,得到所述评价网络输出的以所述目标设备在第一时刻后的轨迹指导所述目标设备行驶对应的奖励值;
19、更新所述策略网络中的参数之前,所述方法还包括:
20、通过所述评价网络,确定以样本轨迹指导所述目标设备行驶所对应的预测奖励值;
21、获取以所述样本轨迹指导所述目标设备行驶所对应的标准奖励值,以所述预测奖励值和所述标准奖励值之间的差异最小为目标,更新所述评价网络中的参数。
22、可选地,更新所述策略网络中的参数,具体包括:
23、当评价网络中的参数满足指定条件时,将第一时刻所述目标设备的状态数据,以及所述策略网络输出的所述目标设备在第一时刻后的轨迹输入所述评价网络,得到所述评价网络输出的以所述轨迹指导所述目标设备行驶对应的奖励值;
24、以所述评价网络输出的奖励值最大为目标,更新所述策略网络中的参数。
25、本说明书提供了一种自动驾驶设备的控制方法,包括:
26、获取当前时刻目标设备的状态数据;
27、将所述状态数据输入策略网络,得到所述策略网络输出的所述目标设备未来的轨迹,其中,所述策略网络为通过如上所述任一训练得到的;
28、根据所述轨迹对所述目标设备进行控制。
29、可选地,根据所述轨迹对所述目标设备进行控制,具体包括:
30、获取目标设备周围的障碍物在未来的预测位置数据;
31、根据所述预测位置数据以及所述轨迹,针对每个障碍物,确定出所述目标设备对该障碍物的行驶决策,并以所确定出的行驶决策对所述目标设备进行控制。
32、本说明书提供了一种模型训练装置,包括:
33、类别确定模块,用于针对所述目标设备周围的每个障碍物,根据该障碍物在第一时刻的位置,确定该障碍物的障碍物类别,其中,所述障碍物类别包括指定类别和非指定类别;
34、轨迹确定模块,用于将所述目标设备的行驶状态数据输入待训练的策略网络,得到所述策略网络输出的所述目标设备在第一时刻后的轨迹;
35、位置预测模块,用于根据所述策略网络输出的轨迹,预测所述目标设备在第一时刻后与障碍物之间的位置关系;
36、参数更新模块,用于根据所预测出的所述位置关系,以及各障碍物的障碍物类别,确定以所述轨迹指导所述目标设备行驶对应的奖励值,并以所述奖励值最大为目标,更新所述策略网络中的参数。
37、本说明书提供了一种自动驾驶设备的控制装置,包括:
38、状态获取模块,用于获取当前时刻目标设备的状态数据。
39、轨迹确定模块,用于将所述状态数据输入策略网络,得到所述策略网络输出的所述目标设备未来的轨迹,其中,所述策略网络为通过如上所述任一所述方法训练得到的;
40、设备控制模块,用于根据所述轨迹对所述目标设备进行控制。
41、本说明书提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述模型训练以及自动驾驶设备的控制方法。
42、本说明书提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述模型训练以及自动驾驶设备的控制方法。
43、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
44、在本说明书提供的模型训练以及自动驾驶设备的控制方法中,将障碍物以不同的障碍物类型进行区分,包括指定类型的障碍物以及非指定类型的障碍物,然后,根据满足风险条件的障碍物的障碍物类型来确定以策略网络输出的轨迹控制目标设备行驶所对应的奖励值,当满足风险条件的障碍物的障碍物类型不同时,所确定出的奖励值也不同,进而,在以奖励值最大为目标更新策略网络中的参数时,更新后的策略网络会倾向于输出的轨迹会指导目标设备优先避让对目标设备的行驶影响较高的障碍物。
- 还没有人留言评论。精彩留言会获得点赞!