一种结合深度强化学习和RSS策略的商用车队列路径规划方法、控制器、存储装置
一种结合深度强化学习和rss策略的商用车队列路径规划方法、控制器、存储装置
技术领域
1.本发明属于人工智能中的自动驾驶领域,涉及一种结合深度强化学习和rss(责任敏感安全)模型的商用车队列路径规划方法、控制器、存储装置。
背景技术:
2.智能汽车是基于环境感知技术、智能驾驶技术、无线通信技术和计算机技术的高新科技产品,汽车产业转型升级的过程,将是汽车逐步实现智能化的过程。智能运行状态下的汽车将以安全、环保、节能、舒适等作为综合控制目标,协同构建高效有序的交通运输网络。
3.当前,商用车队在工程中被广泛应用。商用车,主要分为客车、货车、半挂牵引车、客车非完整车辆和货车非完整车辆,共五类。具有体积大,重量大,驾驶员视野盲区大等特点。当前,商用车队路径规划在训练过程中存在许多问题:首先,多车体同时参加训练,训练难度大,甚至可能导致网络难以收敛。其次,奖励函数设计困难,每个车队成员拥有一个奖励函数,车队成员输出的动作互相干扰,存在奖励抵消的现象,导致训练中探索困难。最后,商用车由于体积大,载荷大,在无人驾驶时安全性得不到很好的保障。所以,如何找到一个可以同时兼顾安全性和高效率的商用车队列规划方法成为一个重要的课题。
技术实现要素:
4.本发明为解决上述商用车队列的问题,引入a3c的框架,a3c利用多线程的方法,让车队中的车辆同时在多个线程里面分别和环境进行交互学习,每个线程都把学习的成果汇总起来,整理保存在global_net。并且,定期从global_net把车队中不同车辆的学习成果拿回来,指导自己和环境后面的学习交互。同时,使用lattice算法,取st图进行速度规划,能够有效地提高车队行驶的稳定性和舒适性,保证商用车行驶轨迹的平顺性。最后,本发明结合了一种安全约束策略,rss(责任敏感安全)策略,这套基于数学公式的自动驾驶汽车安全策略为隐性规则提供了一个框架,从而实现了与道路上其他参与者的有机融合,可以有效地解决队列行驶遇到其他车辆汇入时的安全问题。
5.本发明提供一种结合深度强化学习和rss(责任敏感安全)策略的商用车队列规划方法,利用a3c框架提高车队的学习效率,同时通过lattice算法和rss策略的约束提高车队行驶时的安全性和稳定性。
6.为实现上述目的,本发明采用如下技术方案:
7.结合深度强化学习和rss(责任敏感安全)策略的商用车队列规划方法,包括如下步骤:
8.步骤1:为了更好地获取周围交通环境的信息,本发明设计了一种有效简洁的时序鸟瞰图作为策略网络的状态量,大大提高了策略网络的学习,确保了输出轨迹的安全性。时序鸟瞰图的生成包括以下两个步骤:(1)获得周边的环境信息,包括动、静态障碍物,车道
线。利用预测模块(lstm和gcn网络均可)获得动态障碍物在未来0~t
end
的时间内的位置信息;(2)将感知模块和预测所获得的信息,生成横向、纵向和时间三个维度的特征鸟瞰图。
9.步骤2:进行frenet坐标变换,从特征鸟瞰图中获得当前时刻智能体的状态量。在笛卡尔坐标系下,车辆的坐标信息(x,θ
x
,k
x
,v
x
,a
x
)可以通过坐标变换转化为其中,x为车辆在笛卡尔坐标系下的坐标,是一个向量,θ
x
为车辆在笛卡尔坐标系下的朝向,k
x
为曲率,v
x
为车辆在笛卡尔坐标系下的线速度,a
x
为车辆在笛卡尔坐标系下的加速度。s为frenet坐标系下的纵向位移,为frenet坐标系下纵向位移s关于时间的一阶导数,为frenet坐标系下纵向位移s关于时间的二阶导数。从而获得状态量:动作空间设计为轨迹的纵向末状态:
10.步骤3:本发明使用a3c算法框架,在探索过程中使用车队共享网络的训练方法产生训练样本填充经验池。所有智能体共享策略网络,共同参与网络的训练,避免网络不收敛的问题。
11.将所获得的状态量和动作空间作为输入,利用策略梯度算法改进lattice规划算法,同时结合rss(责任敏感安全)策略设计奖励函数,训练出智能体的末状态采样点。
12.策略网络π
θ
(z,a)的优化目标为最大化输出规划轨迹的期望回报:
[0013][0014]
其中,z为周边交通环境的状态特征,a为网络输出动作(即轨迹的纵向末状态),θ为网络参数,p(τ,θ)为在参数θ和状态z下执行动作a输出轨迹τ的概率,r(τ)为轨迹τ的奖励函数,θ代表网络参数,π代表策略网络。
[0015]
上述策略网络π
θ
(z,a)的优化方法为梯度上升法:α表示梯度下降幅度的学习率。
[0016]
计算优化目标关于网络参数θ的导数:
[0017][0018]
在实际的采样过程中,智能体不断从交通场景中获得轨迹和奖励,然后再根据奖励调整策略,实时地将经验数据《z,a,τ,r》存入经验池(memory)。在训练时,利用蒙特卡洛法,随机从经验池中采样n条经验数据《z,a,τ,r》,根据大数定律对目标函数的梯度进行简化逼近:
[0019][0020]
可得最终策略参数θ的更新方向为:
[0021][0022]
为减小方差,在奖励r(τ)处增加基线b来减小方差:
[0023]
j(π)=∑
τ
p(τ,θ)
·
[r(τ)-b]
[0024]
接下来将目标函数j(π)中关于基线的部分进行拆分:
[0025]
对含有基线的部分bl对网络参数θ行求导:
[0026][0027]
明显的,根据bl对网络参数θ的求导结果,在目标函数j(π)中增加基线b不会影响最终优化目标j(π)的梯度添加与动作a无关的基线b不会影响最终策略的梯度。
[0028]
根据公式计算出方差:
[0029][0030]
明显的,越小,方差也就越小。设计该部分关于b的函数
[0031]
接着求f(b)关于b的导数:
[0032][0033]
f(b)关于b的导数f'(b)在b=∑
τ
r(τ)处为0,即当b=∑
τ
r(τ)时f(b)最小,方差最小。明显的,∑
τ
r(τ)为隐式的状态价值v(z),所以,可以用状态价值v(z)作为基线b来减小方差,提高策略网络的收敛速度和效果。
[0034]
强化学习的智能体在训练过程中,不断提升自身的能力,在这个过程中,需要智能
体在陌生的状态空间里不断试错。在陌生的状态特征下,新的行为可能会使智能体获得更高的奖励,同时也会使得行为动作更加糟糕。“探索行为”是去尝试一些新的动作。“利用行为”是采取已知的可以获得最大奖励的动作,只需要明确执行策略动作。过多的“探索行为”(较少的“利用行为”)会使智能体较难收敛,过少的“探索行为”(较多的“利用行为”)极有可能使智能体收敛在局部最优空间。因此在“探索行为”和“利用行为”之间需要取得一个权衡。为了使训练过程中强化智能体在陌生状态空间里的探索能力,避免智能体在训练过程中陷入局部最优空间,本发明设计的策略网络π
θ
(z,a)的输出将符合正态分布。具体包括均值μ(z,θ)和方差σ(z,θ)两个部分:
[0035][0036]
理论上,策略网络π
θ
(z,a)在学习的过程中,输出的均值μ(z,θ)会不断的逼近最优策略arg
max
q(z,a),q(z,a)表示动作价值函数,arg
max
是求使得q取得最大值所对应的变量点z,a。输出的方差σ(z,θ)会不断的逼近至0,策略的随机性会下降。执行策略时,从该正态分布中采样出动作进行输出并执行。
[0037]
步骤4:纵向轨迹多项式拟合。利用当前自车的纵向状态和强化学习输出的最优纵向末状态作为边界条件,即有s关于时间t的五次多项式:
[0038][0039]
由边界条件有:
[0040][0041]
根据纵向轨迹的五次多项式和边界条件:
[0042][0043]
根据所求得的a1a2a3a4a5可获得纵向轨迹五次多项式s
trajectory
。
[0044]
得到最优轨迹,输入给控制模块。
[0045]
本发明提供一种智能汽车控制器,所述控制器内置上述方法的执行程序。
[0046]
本发明还提供一种存储装置,其内置上述方法的程序代码。
[0047]
本发明的有益效果:
[0048]
(1)本发明针对自动行驶任务,在rss(责任敏感安全)策略下,采用lattice算法和深度强化学习的结合的方法解决商用车队列行驶的问题。运用a3c框架,极大地提高了训练的效率,促使网络收敛。同时,在rss(责任敏感安全)框架下,极大地提高了强化学习规划路径的安全性。
[0049]
(2)本发明与lattice算法相比,舍弃了时间复杂度较高的采样和各个备选轨迹代价函数评价过程,大大提高的算法的时效性。同时,强化学习的训练过程普适性更好,基于最终的控制效果的奖励函数的设计,会使其更加适应复杂的交通场景和复杂的车辆动力学特性。
附图说明
[0050]
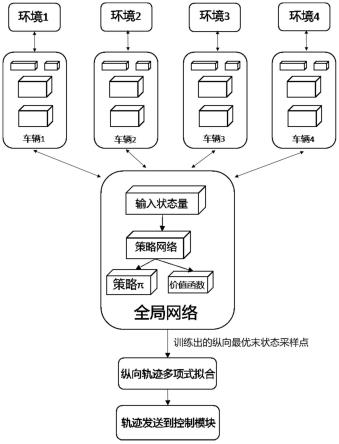
图1本发明的方法流程图;
[0051]
图2本发明所使用的policy gradient网络神经网络结构;
[0052]
图3st图轨迹点采样。
具体实施方式
[0053]
下面结合附图对本发明作进一步说明。
[0054]
本发明提供了一种在rss(责任敏感安全)策略下,结合深度强化学习(drl)和lattice算法的商用车队列路径规划方法,可实现商用大型车辆在队列行驶时安全性,平稳性的提高,如图1所示,具体包括以下步骤:
[0055]
如图1所示,使用a3c框架,在探索过程中使用车队共享网络的训练方法产生各自梯度填充global_net。相比于把所有车队成员状态作为输入,输出成员个数的轨迹,本发明只将每一个智能体自身的状态作为输入,输出自身的轨迹,促使网络收敛,避免出现成员动作互相干扰、奖励抵消的现象。与此同时所有智能网联汽车共享决策网络,共同参与网络的
训练。下面介绍每一个智能体单独的训练过程。
[0056]
利用深度强化学习训练的智能体输出纵向末状态采样点:
[0057]
(1)特征鸟瞰图设计。本发明设计了一种有效简洁的时序鸟瞰图作为策略网络的状态量,大大提高了策略网络的学习,确保了输出轨迹的安全性。
[0058]
时序鸟瞰图的生成包括以下两个步骤:(1)根据自动驾驶汽车的感知模块,获得周边的环境信息,包括动、静态障碍物,车道线。利用预测模块获得动态障碍物在未来0~t
end
的时间内的位置信息;(2)将感知模块和预测所获得的信息,生成横向、纵向和时间三个维度的特征鸟瞰图。
[0059]
所述的三维时序鸟瞰图矩阵的尺寸为(40,400,80)。其中第一维40表示参考线左右各10m的横向范围,横向位移间隔为0.5m;第二维400表示以自车为原点向前纵向200m的范围,纵向位移间隔为0.5m,第三维80表示未来8s内的时间范围,时间间隔为1s。具体的,当时序鸟瞰图矩阵中的点[α,β,γ]为-1,表示该点在时空间中存在障碍物或为不可行驶区域;当时序鸟瞰图矩阵中的点[α,β,γ]为0,表示该点在时空间中为可行驶区域;当时序鸟瞰图矩阵中的点[α,β,γ]]为1,表示该点为参考线的一个点。
[0060]
(2)状态量设计。为从特征鸟瞰图中获得当前时刻智能体的状态量,进行frenet坐标变换,在笛卡尔坐标系下,车辆的坐标信息(x,θ
x
,k
x
,v
x
,a
x
)可以通过坐标变换转化为其中,x为车辆在笛卡尔坐标系下的坐标,是一个向量,θ
x
为车辆在笛卡尔坐标系下的朝向,k
x
为曲率,v
x
为车辆在笛卡尔坐标系下的线速度,a
x
为车辆在笛卡尔坐标系下的加速度。s为frenet坐标系下的纵向位移,为frenet坐标系下纵向位移s关于时间的一阶导数,为frenet坐标系下纵向位移s关于时间的二阶导数。从而获得状态量:动作空间设计为轨迹的纵向末状态:
[0061]
(3)策略网络的设计。将所获得的状态量和动作空间作为输入,利用策略梯度算法改进lattice规划算法,同时结合rss(责任敏感安全)策略设计奖励函数,训练出智能体的末状态采样点。策略网络π
θ
(z,a)的优化目标为最大化输出规划轨迹的期望回报:
[0062][0063]
其中,z为周边交通环境的状态特征,a为网络输出动作(即轨迹的纵向末状态),θ为网络参数,p(τ,θ)为在参数θ和状态z下执行动作a输出轨迹τ的概率,r(τ)为轨迹τ的奖励函数。
[0064]
策略网络π
θ
(z,a)的优化方法为梯度上升法:
[0065]
对参数θ的期望回报j(θ)进行求导以求出最优的θ,此时策略网络π最优,轨迹最优,计算优化目标关于网络参数θ的导数:
[0066][0067]
在实际的采样过程中,智能体不断从交通场景中获得轨迹和奖励,然后再根据奖励调整策略,实时地将经验数据《z,a,τ,r》存入经验池(memory)。在训练时,利用蒙特卡洛法,随机从经验池中采样n条经验数据《z,a,τ,r》,根据大数定律对目标函数的梯度进行简化逼近:
[0068][0069]
为减小方差,在奖励r(τ)处增加基线b来减小方差:
[0070]
j(π)=∑
τ
p(τ,θ)
·
[r(τ)-b]
[0071]
接下来将目标函数j(π)中关于基线的部分进行拆分:
[0072]
对含有基线的部分bl对网络参数θ行求导:
[0073][0074]
明显的,根据bl对网络参数θ的求导结果,在目标函数j(π)中增加基线b不会影响最终优化目标j(π)的梯度添加与动作a无关的基线b不会影响最终策略的梯度。
[0075]
根据公式计算出方差:
[0076][0077]
明显的,越小,方差也就越小。设计该部分关于b的函
数
[0078]
接着求f(b)关于b的导数:
[0079][0080]
f(b)关于b的导数f'(b)在b=∑
τ
r(τ)处为0,即当b=∑
τ
r(τ)时f(b)最小,方差最小。明显的,∑
τ
r(τ)为隐式的状态价值v(z),所以,可以用状态价值v(z)作为基线b来减小方差,提高策略网络的收敛速度和效果。
[0081]
为了使训练过程中强化智能体在陌生状态空间里的探索能力,避免智能体在训练过程中陷入局部最优空间,本发明设计的策略网络π
θ
(z,a)的输出将符合正态分布。具体包括均值μ(z,θ)和方差σ(z,θ)两个部分:
[0082][0083]
理论上,策略网络π
θ
(z,a)在学习的过程中,输出的均值μ(z,θ)会不断的逼近最优策略arg
max
q(z,a),输出的方差σ(z,θ)会不断的逼近至0,策略的随机性会下降。执行策略时,从该正态分布中采样出动作进行输出并执行。
[0084]
(4)设计奖励函数。奖励函数reward包括以下几个部分,k1~k3为每部分奖励对应的比例系数:
[0085]
reward=k1·rspeed
+k2·racc
+k3·rsafe
[0086]
其中r
speed
为速度奖励,目标为将车速保持在目标车速,v
target
为期望目标车速,t
total
为该轨迹以时间为单位对应的轨迹点的个数,v
t
为规划轨迹在时间t处的车速:
[0087][0088]
其中r
acc
为纵向舒适度奖励,目标为保持较小的纵向加加速度,为规划轨迹在时间t处的纵向加速度:
[0089][0090]
其中r
safe
为安全奖励,目标为生成的轨迹符合安全标准,在rss(责任敏感安全)策略下,对奖励函数进行进一步的设计。
[0091]
纵向安全距离:
[0092][0093]
vf为前车速度,vr为后车速度,ρ为驾驶员反应时间,a
min,brake
为最小刹车加速度,a
max,brake
为最大刹车加速度,a
max,accel
为最大加速度。
[0094]
横向安全距离:
[0095][0096]
其中,v1为自车速度,v2为横向的别车速度,即为试图加塞进入车队的别车速度,μ为两车横向速度为0时,横向距离的最小值。为横向最大加速度,为横向最小刹车加速度,ρ为驾驶员反应时间。
[0097]
当按照策略网络生成的轨迹行驶时,与前后车或者加塞进车队的其他车辆的横纵向距离小于最小安全距离时,奖励为-100,否则为0:
[0098][0099]
其中,d为与其他车辆之间的距离。
[0100]
(5)纵向轨迹多项式拟合。利用当前自车的纵向状态和强化学习输出的最优纵向末状态作为边界条件,即有s关于时间t的五次多项式:
[0101][0102]
由边界条件有:
[0103][0104]
根据纵向轨迹的五次多项式和边界条件:
[0105][0106]
根据所求得的a0a1a2a3a4a5可获得纵向轨迹五次多项式s
trajectory
。
[0107]
最后将所得到的的轨迹输入到控制模块进行轨迹跟踪控制。
[0108]
如图2所示,策略网络π
θ
(z,a)具体包括卷积(cnn)特征提取网络和全连接网络(fcn)两部分。其中z为策略网络的输入状态量,包括时序鸟瞰图矩阵和自车的历史轨迹;a为策略网络的输出,即规划轨迹的末状态θ为网络的权重和偏置参数。卷积(cnn)特征提取网络的输入为上述的时空鸟瞰图矩阵,输出为最终提取的环境特征信息。全连接网络(fcn)的输入为卷积(cnn)特征提取网络输出的环境特征信息和自动驾驶汽车的历史轨迹信息,输出为轨迹的末状态
[0109]
策略网络的卷积神经网络包括三层卷积层,两层池化层和三层全连接层。所述的输入层将3个256*256*3的矩阵合并为256*256*9的矩阵;所述的卷积层conv1由(3*3*9)*32,步长stride=2的卷积核组成,其输入是输入层的输出,为256*256*9的矩阵,其输出为128*128*32的特征;所述的池化层pool1由(2*2),步长stride=2的池化核组成,其输入是卷积层conv1的输出,为128*128*32的特征,其输出为64*64*32的特征;所述的卷积层conv2由(3*3*32)*64,步长stride=2的卷积核组成,其输入是池化层pool1的输出,为64*64*32的特征,其输出为32*32*128的特征;所述的池化层pool2由(2*2),步长stride=2的池化核组成,其输入是卷积层conv2的输出,为32*32*128的特征,其输出为16*16*128的特征;所述的卷积层conv3由(3*3*128)*128,步长stride=2的卷积核组成,其输入是池化层pool2的输出,为16*16*128的特征,其输出为8*8*128的特征;所述的全连接层fc的尺寸为(8*8*128)*512,其输入是卷积层conv3的输出,为8*8*128的特征,其输出为1*1*512的特征。所述的全连接层fc-μ和全连接层fc-σ为并联结构,输入均是卷积神经网络提取的特征,为1*1*512的特征,全连接层fc-μ的输出为1*1*512的特征,全连接层fc-σ的输出为1*1*512的特征。全连接层fc-μ和全连接层fc-σ提取的特征共同构成状态特征z。
[0110]
如图3所示,在st图中,主要将交通场景分为两种主要情况:
[0111]
(1)自车前方没有障碍物。由初始的状态量和从深度强化学习训练出来的末状态轨迹点,拟合出轨迹,并进行纵向速度规划。
[0112]
(2)自车前方有障碍物。本发明将障碍物绘制为在特定时间段内阻挡部分道路的平行四边形。例如在下方动图中,预测模块预测车辆将在t0到t1的时间段内驶入车道,该车将在此期间占据位置s0到s1,因此在st图上绘制出一个矩形,它将在时间段t0到t1期间阻挡位置s0到s1。为避免碰撞,速度曲线不得与此矩形相交。
[0113]
跟车时,速度曲线在跟车采样下界之下。超车时,速度曲线在超车采样下界之上。
[0114]
综上所述,本发明针对自动行驶任务,在rss(责任敏感安全)策略下,采用lattice算法和深度强化学习的结合的方法解决商用车队列行驶的问题。运用a3c框架,极大地提高了训练的效率,促使网络收敛。同时,在rss(责任敏感安全)框架下,极大地提高了强化学习规划路径的安全性。本发明与lattice算法相比,舍弃了时间复杂度较高的采样和各个备选轨迹代价函数评价过程,大大提高的算法的时效性。同时,强化学习的训练过程普适性更好,基于最终的控制效果的奖励函数的设计,会使其更加适应复杂的交通场景和复杂的车辆动力学特性。
[0115]
此外,本发明实施例还提供一种智能汽车控制器,所述控制器内置上述方法的执行程序。
[0116]
本发明实施例还提供一种存储装置,其内置上述方法的程序代码。
[0117]
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技术所创的等效方式或变更均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1