一种基于集群进化强化学习的飞行器路径规划方法与流程
1.本发明涉及一种基于集群进化强化学习的飞行器路径规划方法,属于飞行器控制技术领域。
背景技术:
2.飞行器飞行过程中,一般存在有不允许飞行的禁飞区。
3.传统基于迭代搜索的路径规划方法所需计算量较大,难以满足在线路径规划需求;而传统基于梯度的强化学习方法易陷入局部最优。因此,急需开发新的飞行路径规划方法。
技术实现要素:
4.为解决背景技术中存在的问题,本发明提供一种基于集群进化强化学习的飞行器路径规划方法。
5.实现上述目的,本发明采取下述技术方案:一种基于集群进化强化学习的飞行器路径规划方法,所述方法包括如下步骤:
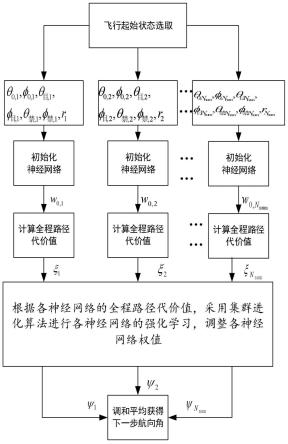
6.s1:起飞前,在预定的飞行空间内随机生成n
num
个飞行起始状态,每个所述飞行起始状态均包括:飞行器起飞时的经度θ
0,j
、飞行器起飞时的纬度φ
0,j
、目标经度θ
目,j
、目标纬度φ
目,j
、禁飞区中心经度θ
禁,j
、禁飞区中心纬度φ
禁,j
以及禁飞区半径rj;其中:j为飞行起始状态的编号,j=1,2
…nnum
;
7.s2:对每个飞行起始状态均随机初始化神经网络的权值;
8.s3:对每个飞行起始状态分别采用对应的路径规划的神经网络规划飞行器飞行动作,采用动力学方程进行飞行仿真,获得全程路径规划代价;
9.s4:根据各神经网络的全程路径规划代价,采用集群进化算法进行各神经网络的强化学习,调整各神经网络的权值;
10.s5:在线飞行时,输入当前飞行状态,采用训练的各路径规划的神经网络进行规划,将各网络输出的飞行航向角进行调和平均,得到飞行器下一步所需的飞行航向角。
11.与现有技术相比,本发明的有益效果是:
12.本发明采用神经网络线下强化学习以及线上规划的方式,减少了进行路径规划的时间,具有良好的工程应用价值。同时采用集群进化学习,具有可避免传统基于梯度的强化学习易陷入局部最优的缺点。此外,将各路径规划网络的规划结果进行调和平均,可防止路径规划结果出现较大波动。
附图说明
13.图1为本发明的网络构建-线下学习-线上规划的流程图;
14.图2为本发明在线飞行时规划得到下一步航向角的流程图。
具体实施方式
15.下面将结合本发明实施例中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
16.一种基于集群进化强化学习的飞行器路径规划方法,所述方法包括如下步骤:
17.s1:起飞前,在预定的飞行空间内随机生成n
num
个飞行起始状态,每个所述飞行起始状态均包括:飞行器起飞时的经度θ
0,j
、飞行器起飞时的纬度φ
0,j
、目标经度θ
目,j
、目标纬度φ
目,j
、禁飞区中心经度θ
禁,j
、禁飞区中心纬度φ
禁,j
以及禁飞区半径rj;其中:j为飞行起始状态的编号,j=1,2
…nnum
;
18.s2:对每个飞行起始状态均随机初始化神经网络的权值;
19.s201:定义路径规划的神经网络为fj(θ,φ,θ
目
,φ
目
,θ
禁
,φ
禁
,r),网络输入量为:飞行器经度输入值θ、飞行器纬度输入值φ、目标经度输入值θ
目
、目标纬度输入值φ
目
、禁飞区中心经度输入值θ
禁
、禁飞区中心纬度输入值φ
禁
以及禁飞区半径输入值r;定义路径规划的初始化神经网络的权值为ω
0,j
;
20.s202:将每个路径规划的初始化神经网络的权值ω
0,j
均设置为0。
21.s3:对每个飞行起始状态分别采用对应的路径规划的神经网络规划飞行器飞行动作,采用动力学方程进行飞行仿真,获得全程路径规划代价;
22.s301:设置参数,包括:
23.飞行器单步位移l、路径容许残差κ以及地球半径re;
24.s302:设置飞行起始状态:
25.初始化飞行状态量为:飞行器起飞时的经度θ
0,j
、飞行器起飞时的纬度φ
0,j
、飞行起始状态的目标经度θ
目,j
、飞行起始状态的目标纬度φ
目,j
、飞行起始状态的禁飞区中心经度θ
禁,j
、飞行起始状态的禁飞区中心纬度φ
禁,j
以及飞行起始状态的禁飞区半径rj;初始化全程路径规划代价ξj=0;
26.s303:采用对应的路径规划的神经网络输出飞行航向角ψj:
27.ψj=sum([θ
0,j
,φ
0,j
,θ
目,j
,φ
目,j
,θ
禁,j
,φ
禁,j
,rj]
·
ω
0,j
)
ꢀꢀ
(1)
[0028]
式(1)中:
[0029]
sum表示求和函数符号;
[0030]
s304:计算终端状态:
[0031][0032]
式(2)中:
[0033]
θ
f,j
表示飞行器终端状态的经度;
[0034]
φ
f,j
表示飞行器终端状态的纬度;
[0035]
s305:判断:
[0036]
(a):若飞行器到目标距离小于路径容许残差,即:
则全程路径规划代价输出全程路径规划代价ξj,结束s3;否则转到(b);
[0037]
(b):若飞行器到禁飞区边界距离小于路径容许残差,即:则全程路径规划代价输出全程路径规划代价ξj,结束s3;否则转到(c);
[0038]
(c):若全程路径规划代价ξj=100000,结束s3。
[0039]
s4:根据各神经网络的全程路径规划代价,采用集群进化算法进行各神经网络的强化学习,调整各神经网络的权值;
[0040]
s401:设定初始化各神经网络参数权值变化速度v
j,0
=0,初始化总进化次数n
进化
,初始化当前进化次数m
进化
=0;
[0041]
s402:根据各神经网络的全程路径规划代价获得最小路径规划代价ξ
min
和对应的编号n
min
;
[0042]
s403:更新各神经网络参数权值变化速度:
[0043][0044]
式(3)中:
[0045]vj,k+1
表示第k+1步网络参数权值变化速度;
[0046]vj,k
表示第k步网络参数权值变化速度;
[0047]
表示第k步最小路径规划代价对应的神经网络权值;
[0048]
ω
j,k
表示第k步网络参数权值;
[0049]
s404:更新各神经网络参数权值:
[0050]
ω
j,k+1
=ω
j,k
+0.1v
j,k+1
ꢀꢀ
(4)
[0051]
s405:对更新后的各神经网络,基于s3计算全程路径规划代价以及第k+1步进化次数m
进化,k+1
=m
进化,k
+1;
[0052]
s406:判断是否跳出:
[0053]
若第k+1步进化次数m
进化,k+1
>n
进化
,则输出更新后的各神经网络参数权值ω
j,k+1
,结束s4;否则转到s402。
[0054]
s5:在线飞行时,输入当前飞行状态,采用训练的各路径规划的神经网络进行规划,将各网络输出的飞行航向角进行调和平均,得到飞行器下一步所需的飞行航向角。
[0055]
s501:对n
num
个神经网络分别输入当前飞行状态,包括飞行器当前的经度θs、飞行器当前的纬度φs、当前的目标经度θ
目,s
、当前的目标纬度φ
目,s
、当前的禁飞区中心经度θ
禁,s
、当前的禁飞区中心纬度φ
禁,s
以及当前的禁飞区半径rs;计算更新后的飞行航向角:
[0056]
ψi=sum([θs,φs,θ
目,s
,φ
目,s
,θ
禁,s
,φ
禁,s
,rs]
·
ω
i,k
)
ꢀꢀ
(4)
[0057]
式(4)中:
[0058]
ψi表示飞行航向角ψj经过计算更新后的飞行航向角;
[0059]
ω
i,k
表示第k步网络参数权值经过计算更新后的第k步网络参数权值;
[0060]
i为飞行起始状态的编号,i=1,2
…nnum
;
[0061]
s502:将各网络计算结果进行调和平均,得到最终输出的飞行航向角ψs:
[0062][0063]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同条件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0064]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1