基于强化学习的蝠鲼式仿生鱼控制方法、装置及存储介质
1.本发明涉及人工智能与机器人领域的强化学习算法,尤其涉及一种基于强化学习的蝠鲼式仿生鱼控制方法、装置及存储介质。
背景技术:
2.海洋中蕴含着大量的资源,近年来对海洋资源的开发探索日益重视,仿生鱼作为一种重要的探索工具,近年来也在加快发展步伐。为实现对仿生鱼的运动控制,国内外学者也在对仿生鱼的控制算法中做了大量研究,大都局限于非智能控制算法。汪明、喻俊志、谭民,胸鳍推进型机器鱼的cpg控制及实现,机器人期刊,20100315中公开了基于cpg的仿生机器鱼实现了仿生鱼的前进、转向和后退等模态的平稳切换和稳定性,但并不能实现自主游动,具有控制效率低,鲁棒性差等缺点。
3.近些年,将深度强化学习算法在仿生机器人控制上的案例越来越多,也有部分学者将其应用到仿生鱼的控制上。中国专利cn 110909859公开了一种基于对抗结构化控制的仿生机器鱼运动控制方法,这种方法以深度强化学习作为优化算法,以运动至目标点的精度与速度为奖励项,以舵机功率和为损失项,构建优化目标函数。但是这种方法通过直接控制舵机来控制仿生鱼游动,训练效率较低。tianhao zhang,runyutian,chen wang,guangmingxie.path-following control of fish-like robots:a deep reinforcement learning approach[j].ifac papersonline,2020,53-2(8166-8167)中公开了基于强化学习控制的仿生鱼可以通过路径追踪实现自主游动,但是通过摄像机拍摄仿生鱼位姿状态的方式很难应用于真实的江河湖泊等环境,实用性较差。
[0004]
现有的应用于蝠鲼式仿生鱼上的控制方法具有适应能力差、鲁棒性差等问题,而基于强化学习控制的仿生鱼具有训练效率低、实用性差等问题。
技术实现要素:
[0005]
发明目的:本发明旨在提供一种提高训练效率、实用性、控制效率和鲁棒性的基于强化学习的蝠鲼式仿生鱼控制方法。本发明还提供一种基于强化学习的蝠鲼式仿生鱼控制方法的控制装置。
[0006]
技术方案:本发明所述的基于强化学习的蝠鲼式仿生鱼控制方法,包括以下步骤:
[0007]
(1)建立世界坐标系:以初始点作为坐标原点,东方向为x正方向,北方向为y正方向;
[0008]
(2)构建ins和gps组合导航系统,输出t时刻仿生鱼的位置信息,推导t时刻误差角度err_yaw和当前位置与目标点距离err_dist;
[0009]
(3)构建强化学习模型,使用ddpg作为强化学习模型框架,输入t时刻状态state=[err_yaw,v,err_dist,v_yaw],其中v为蝠鲼式仿生鱼的实时移动速度,v_yaw为转向速度,输出动作action=[kv,kt],其中kv为速度系数,kt为方向系数;
[0010]
(4)通过仿真系统对强化学习模型进行训练;
[0011]
(5)完成训练后,强化学习模型输出动作action=[kv,kt]作为蝠鲼式仿生鱼的舵机的控制曲线的输入值,控制鱼体的速度和游动方向。
[0012]
进一步地,步骤(2)中,实时航向角与目标航向角之间的偏差err_yaw公式如下:
[0013]
err_yaw=new_yaw
‑‑
tar_yaw
[0014][0015][0016]
其中,new_yaw为当前偏航角,taw_yaw为目标航向角,p
x
和py分别表示目标点的横坐标和纵坐标,n
x
和ny分别表示ins和gps组合导航系统输出的当前位置的x坐标和y坐标,e
x
和ey分别表示目标点与当前位置x坐标之差和y坐标之差。
[0017]
当前位置与目标点距离err_dist公式如下:
[0018][0019]
进一步地,步骤(3)中强化学习模型的奖励函数r公式如下:
[0020]
r=rs+rc[0021]rs
=r
yaw
+r
dist
+rv+r
v_yaw
[0022]
rc=ra+rd[0023]
其中,rs为日常奖励,rc为回合终止时的结算奖励,r
yaw
为方向奖励,r
dist
为距离奖励,rv为速度奖励,r
v_yaw
为转速奖励,ra为完成任务奖励,rd为装置损毁奖励。
[0024]
方向奖励err_yaw表示实时航向角与目标航向角之间的偏差;距离奖励d表示初始时刻蝠鲼式仿生鱼与目标点的距离;速度奖励v表示蝠鲼式仿生鱼的实时移动速度,单位为m/s;转速奖励v_yaw表示转向速度,单位为
°
/s。
[0025]
完成任务奖励ra公式如下:
[0026][0027]
其中,表示当前蝠鲼式仿生鱼的位置与目标位置点的水平面距离,单位为m;δh表示蝠鲼式仿生鱼与目标点的深度偏差,单位为m;s为回合中的训练步数,s
max
最大训练步数;
[0028]
装置损毁奖励rd公式如下:
[0029][0030]
其中,xi,yi,zi为当前蝠鲼式仿生鱼的三维坐标,x
max
,y
max
,z
max
为蝠鲼式仿生鱼最大活动位置的三维坐标。
[0031]
进一步地,步骤(5)中,所述蝠鲼式仿生鱼的舵机的控制曲线为正弦波曲线,舵机
的角度输出控制函数为:
[0032][0033][0034][0035]
其中,α
l
为左侧扑荡舵机的转动角度,α0为扑荡舵机的最大俯仰角,ω为角频率,θ
l
为左侧旋转舵机的转动角度,k
tl
表示左方向系数,θ0为旋转舵机的最大旋转角,φ为同侧两舵机的相位差,αr为右侧扑荡舵机的转动角度,θr为右侧旋转舵机的转动角度,k
tr
表示右方向系数;速度系数kv的输出范围为[0,1],方向系数kt的输出范围为[-1,1]。
[0036]
一种蝠鲼式仿生鱼控制装置,包括:
[0037]
ins和gps组合导航模块,得到仿生鱼的速度v、位置、转速的组合导航结果;
[0038]
强化学习模块,使用ddpg作为强化学习模型框架,基于深度确定性策略梯度网络训练仿生鱼的速度系数和方向系数;
[0039]
控制模块,速度系数和方向系数作为仿生鱼的舵机的控制曲线的输入值,用于舵机控制仿生鱼的运动;
[0040]
所述深度确定性策略梯度网络包括策略网络和评价网络;
[0041]
所述策略网络包括第一动作状态估计模块、第一动作状态现实模块、和策略梯度模块;
[0042]
所述评价网络包括第二动作状态估计模块、第二动作状态现实模块、和损失函数模块;
[0043]
所述第一动作状态估计模块连接第二动作状态估计模块、策略梯度模块,并且所述第一动作状态估计模块输出所述状态参数,并接收奖励值;
[0044]
所述第一动作状态现实模块连接第二动作状态现实模块,并且所述第一动作状态现实模块接收所述奖励值;
[0045]
所述策略梯度模块连接所述第一动作状态估计模块、第二动作状态估计模块;
[0046]
所述第二动作状态估计模块连接所述第一动作状态估计模块、策略梯度模块和损失函数模块,并接收奖励值;
[0047]
所述第二动作状态现实模块连接所述第一动作状态现实模块、损失函数模块,并接收奖励值;
[0048]
所述损失函数模块连接第二动作状态现实模块和第二动作状态估计模块。
[0049]
一种电子设备,包括:存储器和处理器;所述存储器,用于存储计算机程序;其中,所述处理器执行所述存储器中的计算机程序,以实现上述的方法。
[0050]
一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时用于以实现上述的方法。
[0051]
有益效果:本发明与现有技术相比,其显著优点是:1、本发明通过强化学习算法控制蝠鲼式仿生鱼实现了仿生鱼的自主游动至目标点的任务,提高了控制效率和鲁棒性;2、
本发明通过观测仿生鱼当前运动状态作为强化学习算法的输入,输出方向与速度系数来控制仿生鱼的游动方向和速度,相对于控制关节运动角度的方法提高了训练效率;3本发明以gps/ins作为定位导航系统,相较于通过拍摄仿生鱼位姿的定位方法更具有实用性。
附图说明
[0052]
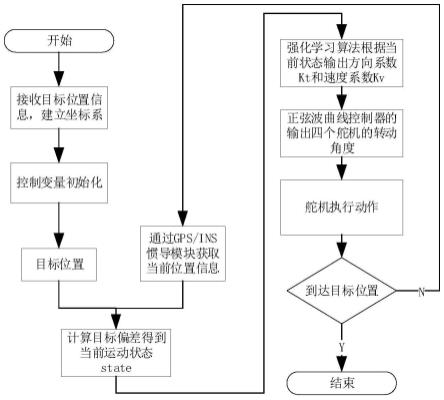
图1为本发明中的蝠鲼式仿生鱼控制方法的流程图;
[0053]
图2为松耦合的gps/ins集成结构的示意图;
[0054]
图3为强化学习算法框架结构的示意图;
[0055]
图4为pycharm和webots联合仿真环境的示意图;
[0056]
图5为仿生鱼的胸鳍与舵机的结构示意图;
[0057]
图6为舵机的控制曲线图。
具体实施方式
[0058]
下面结合附图对本发明作进一步说明。
[0059]
如图1所示,本发明所述基于强化学习的蝠鲼式仿生鱼控制方法,包括以下步骤:
[0060]
(1)获取上位机发送的目标点位置,建立东北天坐标系,以初始点作为坐标原点,东方向为x正方向,北方向为y正方向。
[0061]
(2)构建ins和gps组合导航系统。从gps获取初始点经纬度数据,获取t时刻仿生鱼的位置经纬度数据。获取jy901数据,包括当前偏航角、三个轴向加速度、角速度和当前地磁场等数据。通过三个轴向加速度、角速度和地磁场数据经过计算可以实现惯性导航定位,获得当前速度(v)、位置等信息。
[0062]
为实现gps和ins的互补特性,采用松耦合的gps/ins集成架构,如图2所示。gps与ins均独立工作并各自提供导航参数的结果。为了提高导航精度,通常将gps的位置与速度输入到滤波器中,同时,ins的位置、速度、姿态也作为滤波器的输入,滤波器通过比较二者的差值,建立误差模型以估计ins的误差。利用这些误差对惯导结果进行修正,得到速度(v)、位置、转速(v_yaw)的组合导航结果。
[0063]
其中,ins惯性导航系统要使用误差模型来分析和估计与ins相关的各种误差源,包含了沿大地曲面的误差(纬度误差、精度误差、海拔误差)、沿地球系的速度误差(东向速度误差ve、北向速度误差vn、天向速度误差vu)、以及三个姿态角的误差(俯仰pitch、横滚roll、航向yaw)、同时还包括加速度计的bias和陀螺仪的drift。
[0064]
将gps/ins惯导组合获取的位置信息经过计算可获得t时刻误差角度(err_yaw)和t时刻距离(err_dist)。
[0065]
实时航向角与目标航向角之间的偏差err_yaw公式如下:
[0066]
err_yaw=new_yaw-tar_yaw
[0067][0068][0069]
其中,new_yaw为从传感器获取的当前偏航角,taw_yaw为通过反正切函数算出的
目标航向角,p
x
和py分别表示目标点的横坐标和纵坐标,n
x
和ny分别表示1ns和gps组合导航系统输出的当前位置的x坐标和y坐标,e
x
和ey分别表示目标点与当前位置x坐标之差和y坐标之差。
[0070]
当前位置与目标点距离err_dist公式如下:
[0071][0072]
强化学习算法需要输入的t时刻状态值为state=[err_yaw,v,err_dist,v_yaw],至此速度(v)通过惯性导航系统获取,转速(v_yaw)通过传感器获取,误差角(err_yaw)和距离(err_dist)通过计算获取。
[0073]
(3)构建强化学习模型。获取t时刻状态值state,输出动作action=[kv,kt],作为方向系数和动作系数,当仿生鱼动作后再次与环境进行交互,令t:=t+1,跳转到步骤(2),获得t+1时刻状态值。
[0074]
本发明的强化学习基础算法为深度确定性策略梯度算法(ddpg),如图3所示为强化学习算法架构示意图,主要分为主网络和目标网络,主网络中的actor网络输出动作,然后仿生鱼与环境交互后得到状态值,critic网络进行评价,经过不断的交互后,仿生鱼可以不断进行自主学习,更新策略,到最后可以实现根据不同的环境状态做出最优动作。为实现定点游动控制任务,需要构建观测空间、动作空间和奖励函数。然后在我们搭建的仿真环境中进行仿真训练。
[0075]
所述的观测空间是蝠鲼式仿生鱼所处世界中的所有状态的集合,由蝠鲼式仿生鱼当前位姿状态和目标位置点状态两部分组成。因此,整个系统的观测空间由三部分组成,第一部分当前位姿状态包括蝠鲼式仿生鱼当前的位置信息三维坐标、偏航角、航行速度、转向速度;第二部分包括蝠鲼式仿生鱼目标位置的三维坐标信息。
[0076]
所述的动作空间是指蝠鲼式仿生鱼所能够采取的所有动作的集合。我们将强化学习的动作输出做为正弦波曲线的输入,所以动作输出应为方向系数kt和速度系数kv。
[0077]
所述的奖励函数是为了能够使强化学习完成设定的定点游动控制任务,我们将奖励值分为日常奖励和回合终止奖励。日常奖励包括方向奖励、速度奖励、距离奖励和转速奖励,结算奖励包括完成任务和装置损毁奖励。
[0078]
所述的方向奖励,实时航向角与目标航向角之间的偏差越大,给出的负奖励也应该越大,当实时航向角与目标航向角之间的偏差为0时,奖励值为0。方向奖励公式如下:
[0079][0080]
其中,err_yaw表示实时航向角与目标航向角之间的偏差。
[0081]
所述的距离奖励,我们希望蝠鲼式仿生鱼在水平面上与目标位置的距离越近越好,所以设置一个水平面距离的负奖励,蝠鲼式仿生鱼越靠近目标位置时,负奖励越小。通过距离的负奖励设置可以更好的促进蝠鲼式仿生鱼朝向目标点靠近。距离奖励公式如下:
[0082][0083]
其中err_dist表示的是蝠鲼式仿生鱼与目标点的距离,d表示的是初始时刻蝠鲼式仿生鱼与目标点的距离。
[0084]
所述的转速奖励,过高的转向速度容易造成蝠鲼式仿生鱼在调整到正确的航向角时不能及时的停下来的情况,是不利于蝠鲼式仿生鱼的控制的,因此需要增加一个转向速度限速的负奖励,当超过可以接受的最大转向速度时,基于一个超速的负奖励。转速奖励公式如下:
[0085][0086]
其中,v
yaw
表示的是转向速度,单位为
°
/s。当转向速度超过2
°
/s时,给出固定的负奖励。
[0087]
所述的速度奖励,当蝠鲼式仿生鱼停止在原地不动时,将给予一个负奖励,以此来鼓励蝠鲼式仿生鱼能够动起来。速度奖励公式如下:
[0088][0089]
其中,v表示的是蝠鲼式仿生鱼的实时移动速度,单位为m/s,当移动速度低于0.05m/s时给出固定的负奖励。
[0090]
日常奖励最终结果为
[0091]rs
=r
yaw
+r
dist
+rv+r
v_yaw
[0092]
所述的完成任务奖励,当蝠鲼式仿生鱼在世界坐标系中的位置落入以目标位置为圆心,允许误差为半径,允许深度误差的圆柱体内部区域时即为任务完成。完成任务奖励公式如下:
[0093][0094]
上式中表示当前蝠鲼式仿生鱼的位置与目标位置点的水平面距离,δh表示的是蝠鲼式仿生鱼与目标点的深度偏差,当回合中的训练步数小于等于最大训练步数时且水平面距离与深度偏差同时小于0.5米时,判定任务完成,回合结束,给予结算奖励为0,当蝠鲼式仿生鱼在本回合训练中已经消耗最大回合步数设定还未到达目标位置时,回合终止并判定任务失败,则结算奖励为-1。
[0095]
所述的装置损毁奖励,在训练过程中,当蝠鲼装置游动到世界最大活动位置时,若蝠鲼式仿生鱼依然选择继续执行超出边界的动作,将会使蝠鲼式仿生鱼损毁,此时回合终止并判定任务失败。装置损毁奖励函数具体如下:
[0096][0097]
结算奖励函数具体为:
[0098]
rc=ra+rd[0099]
训练过程中的日常奖励函数及回合终止时的结算奖励函数确定后,整个深度强化学习任务的奖励函数确定如下:
[0100]
r=rs+rc[0101]
(4)通过仿真系统对强化学习模型进行训练。仿真环境如图4所示,首先在webots中创建了蝠鲼式仿生鱼的基本模型与仿真实验环境。其次,在pycharm中将webots的库文件
包含进项目中;最后,在webots中将控制器设置为外部控制器,即可通过pycharm对webots中的机器人及仿真环境进行控制。
[0102]
(5)完成训练后,强化学习模型输出动作action=[kv,kt]作为蝠鲼式仿生鱼的舵机的控制曲线的输入值,控制鱼体的速度和游动方向。
[0103]
为使蝠鲼式仿生鱼产生转弯动作,本发明将蝠鲼式仿生鱼的游动控制任务与汽车的自动驾驶做类比,首先需要考虑的为驾驶的方向问题,即为蝠鲼式仿生鱼的航向角,我们必须要在保证驾驶方向正确的情况下才能确保可以游到目标点;其次需要考虑的是驾驶的速度问题,即为蝠鲼式仿生鱼的航行速度问题,在方向正确的前提下,我们需要尽快的游动到目标点。则蝠鲼式仿生鱼的四个舵机的角度输出控制函数为:
[0104][0105]
如图5所示为左侧胸鳍结构示意图,1号舵机负责扑荡运动,其舵机转动角度为α
l
。2号舵机负责旋转运动,其舵机转动角度为θ
l
。上式中,kv表示的是速度系数,ktl表示的是左方向系数,ktr表示的是右方向系数。其中速度系数kv的输出范围为[0,1],方向系数kt的输出范围为[-1,1]。对方向系数kt进行相应处理:
[0106][0107][0108]
如图6所示为四个舵机的控制曲线,曲线i为左侧扑荡舵机,曲线ii为左侧旋转舵机,曲线iii为右侧扑荡舵机,曲线iv为右侧旋转舵机。当速度和方向系数改变后,对应的舵机控制曲线改变从而改变仿生鱼的游动状态。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1