一种基于深度强化学习的部分可观测多船避碰方法
本发明涉及船舶控制,具体而言,尤其涉及一种基于深度强化学习的部分可观测多船避碰方法。
背景技术:
1、随着航运经济的快速发展,现代船舶设备逐渐先进。但是船舶碰撞、触礁等事故仍频繁发生。据统计数据显示,89-96%的碰撞事故是由人为因素造成的。一方面,船舶未能严格遵守《国际海上避碰规则公约》(colregs)。另一方面,海上环境的复杂性给舵手带来了挑战。特别是当多艘船舶会遇时,舵手很难评估和确定船舶的最佳避碰策略。因此该领域对无人系统需求逐步增加,无人船成为提高水路运输智能化的一种重要手段。
2、到目前为止,在已知环境下的静态避碰研究已经取得了很多成果,而在未知环境下的动态避碰则成为无人船领域的一个热点问题。随着海上环境的高动态变化以及不确定性因素越来越多,传统求解方法已经无法满足需求。近几年,强化学习做为一种新兴的机器学习技术,可以良好的处理智能体决策问题,给该领域的问题求解带来了新的突破口。在强化学习中,几乎所有的问题都可以形式化地建模为马尔可夫决策过程(mdp)。目前大多数工作通过mdp构建模型并采用强化学习算法来求解动、静态障碍环境下的船舶避障问题。
3、这些方法在使用mdp时有很多问题。首先在求解过程中,基于假设的完整海图,设定仅使用ais数据便可以随时捕捉到海上所有未知信息。而实际上,整个海洋是高度动态的,它的状态通常不能被完全观察到,这导致了现有mdp模型在实际船舶避障领域输出低效的避碰和不良的决策行为。其次,采集ais数据进行训练和测试的成本高。雷达作为船舶避碰的主要助航仪器,可以将扫描到的海面信息以回波的方式显示,从而获取到全面的交通地图。在此背景下,如果采用mdp构建模型,则需要将获取到的航海图全部输入到算法中进行训练。然而宏观上完整航海图矩阵十分巨大,将整个航海图作为输入需要极高的计算力;如果将航海图按比例缩小则缩小了目标障碍物的体积而无法做到微观上的决策。
4、另外,强化学习用于存在死胡同情况的迷宫环境时,需要对全局信息有一个全面的了解,在决策时多次记录死胡同信息,最终可以学习到一个全局最优决策。然而海域环境不存在死胡同,导致mdp构建模型训练出来的算法并不能适应实际情况。
技术实现思路
1、本发明提供一种基于深度强化学习的部分可观测多船避碰方法,基于部分可观测马尔可夫决策输出避碰策略。克服了现有技术中因为基于假设的完整海图构建的mdp模型无法适应高度动态的海洋环境,不能高效控制无人船实现避碰的技术问题。
2、本发明采用的技术手段如下:
3、一种基于深度强化学习的部分可观测多船避碰方法,包括以下步骤:
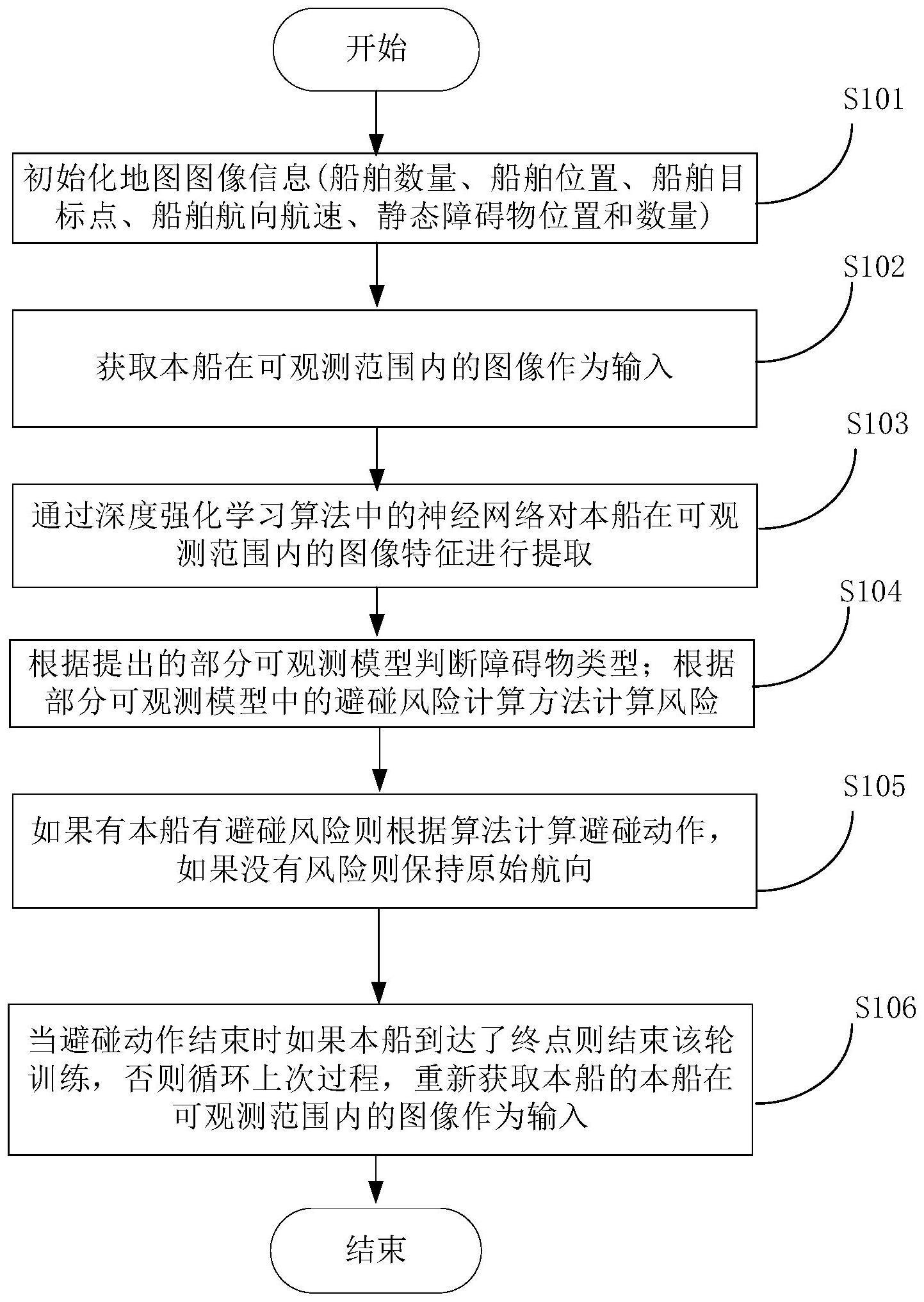
4、s101、初始化地图信息,所述地图信息包括船舶数量、船舶位置、船舶目标点、船舶航向航速、静态障碍物位置和数量;
5、s102、获取本船在可观测范围内的图像作为输入,通过神经网络对本船在可观测范围内的图像特征进行提取;
6、s103、构建部分可观测模型,并根据所述部分可观测模型判断障碍物类型,所述部分可观测模型的构建包括:
7、基于图像状态观测方法构建状态空间,以每一时刻本船的可观测范围内的图像作为输入,
8、根据船舶控制特点构建动作空间,所述动作空间包括左舷、右舷以及保向动作,
9、根据船舶避障运行特点构建密集奖励机制;
10、s104、根据部分可观测模型中的避碰风险计算方法计算风险;
11、s105、如果有本船有避碰风险则根据算法计算避碰动作,如果没有风险则保持原始航向;
12、s106、当避碰动作结束时如果本船到达了终点则结束该轮训练,否则循环s102-s106,直至到达终点。
13、进一步地,所述初始化地图信息,包括对会遇场景进行划分,所述会遇场景包括:对遇场景、让路船情况下的交叉场景、直航船情况下的交叉相遇场景以及追越场景。
14、进一步地,所述初始化地图信息还包括对搭建船舶运动学模型,所述船舶运动学模型为:
15、
16、
17、
18、
19、
20、dcpa=dot*sin(θot-αt-π)
21、tcpa=dot*cos(θot-αt-π)/vot
22、其中,其中(xo,yo)表示本船坐标,(xgoal,ygoal)表示终点坐标,(xt,yt)表示目标船坐标,θo表示本船与目标点的夹角,θt表示目标船速度夹角,θot表示本船与目标船的相对航向角度,αt表示本船与目标船的夹角,dcpa表示两船间最近会遇距离,tcpa表示两船间最近会遇时间。
23、进一步地,所述密集奖励机制包括本船成功到达目标区域的奖励、本船与其他船舶或静态障碍物发生碰撞时的惩罚、本船驶出观测范围外的惩罚以及本船每时每刻与目标区域的航向奖励。
24、进一步地,动作奖励根据以下计算获得:
25、
26、其中,r表示动作奖励值,(xgoal,ygoal)表示目标点坐标,(xo,yo)表示本船当前坐标,θo表示本船初始航向。
27、进一步地,采用ppo算法对所述部分可观测模型进行训练,所述ppo算法主要包含actor网络和critic网络,所述其中actor网络用于学习一个策略以获得尽可能高的回报,所述critic网络用于对当前策略的价值函数进行估计。
28、进一步地,根据部分可观测模型中的避碰风险计算方法计算风险,包括根据以下计算获取碰撞风险指数:
29、cri=(a·dcpa)2+(b·tcpa)2
30、其中,cri为碰撞风险指数,a,b为权重参数。
31、进一步地,所述神经网络为cnn网络,所述cnn网络网络包括提取层和处理层,其中所述提取层为conv2d,所述处理层为relu,结果在展平操作后由全连接层输出。
32、较现有技术相比,本发明具有以下优点:
33、1、本发明首先基于部分可观测马尔可夫决策过程(pomdp)构建了一种无人船避碰决策模型。通过pomdp构建模型,可以解决船舶无法获取到所有的未知信息而导致的避碰效率低、决策行为差的问题。
34、2、本发明设计了一种密集奖励机制,将以往的稀疏奖励变为密集奖励,从而提升强化学习的学习速度和策略结果。
35、3、本发明在模型中提出了一种图像状态观测法,将船舶每时每刻的可观测范围内的图像作为算法的输入,从而解决采集ais数据进行训练和测试的成本高的问题。
36、4、由于船舶不能获取到全局状态,为了让船舶跟随原始航向,并更好地进行决策,本发明设计了一种航线指引法。通过与目标点与船舶之间添加的一条指引线,可以让船舶在部分可观测模型下时刻跟随航线,提升学习效率。
技术特征:
1.一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,所述初始化地图信息,包括对会遇场景进行划分,所述会遇场景包括:对遇场景、让路船情况下的交叉场景、直航船情况下的交叉相遇场景以及追越场景。
3.根据权利要求1所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,所述初始化地图信息还包括搭建船舶运动学模型,所述船舶运动学模型为:
4.根据权利要求1所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,所述密集奖励机制包括本船成功到达目标区域的奖励、本船与其他船舶或静态障碍物发生碰撞时的惩罚、本船驶出观测范围外的惩罚以及本船每时每刻与目标区域的航向奖励。
5.根据权利要求4所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,动作奖励根据以下计算获得:
6.根据权利要求5所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,采用ppo算法对所述部分可观测模型进行训练,所述ppo算法主要包含actor网络和critic网络,所述其中actor网络用于学习一个策略以获得尽可能高的回报,所述critic网络用于对当前策略的价值函数进行估计。
7.根据权利要求1所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,根据部分可观测模型中的避碰风险计算方法计算风险,包括根据以下计算获取碰撞风险指数:
8.根据权利要求1所述的一种基于深度强化学习的部分可观测多船避碰方法,其特征在于,所述神经网络为cnn网络,所述cnn网络网络包括提取层和处理层,其中所述提取层为conv2d,所述处理层为relu,结果在展平操作后由全连接层输出。
技术总结
本发明提供一种基于深度强化学习的部分可观测多船避碰方法,包括以下步骤:初始化地图信息;获取本船在可观测范围内的图像作为输入;通过神经网络对本船在可观测范围内的图像特征进行提取;根据提出的部分可观测模型判断障碍物类型;根据部分可观测模型中的避碰风险计算方法计算风险;如果有本船有避碰风险则根据算法计算避碰动作,如果没有风险则保持原始航向;当避碰动作结束时如果本船到达了终点则结束该轮训练,否则循环上次过程,重新获取本船的本船在可观测范围内的图像作为输入。本发明基于部分可观察马尔可夫决策过程提出了一个多船会遇下部分可观测的的避碰决策模型,并设计了密集奖励机制,有效实现无人船避碰,同时提高了算法的学习效率。
技术研发人员:张新宇,郑康洁,王程博,姜玲玲,李元奎,崔浩,王警,刘震生
受保护的技术使用者:大连海事大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!