一种面向eVTOL空中旅游观光的轨迹规划方法与流程
一种面向evtol空中旅游观光的轨迹规划方法
技术领域
1.本发明涉及智慧空中交通领域,尤其涉及一种面向evtol空中旅游观光的轨迹规划方法。
背景技术:
2.近年来,电动垂直起降(evtol)飞机开发吸引了包括航空航天企业、汽车行业、运输行业、政府、军方以及学术界的广泛关注。evtol是一种利用电力实现垂直悬停、起飞和降落的vtol(垂直起降)飞机。这项技术的出现要归功于电力推进(电机、电池、燃料电池、电子控制器)的重大进步以及城市空中交通(空中出租车)对新型车辆的需求不断增长。
3.有着绿色环保和便捷等特点的evtol飞行器正成为激发旅游市场活力的加速剂。它有着灵活机动、快捷便利、纯电力驱动等优势,非常适合应用在景区观光、海岛观光等空中游览场景。此外,还可以通过根据预设航线实现定点高频的自动化和集群调度飞行,也更加符合景区未来实现自动化、提升观光体验的趋势,对景区运营方无疑有着更大的吸引力。
4.然而,当前evtol的研发主要集中于飞控算法的开发和飞行器机械结构的设计,智能化方面涉及较少。轨迹规划作为智能化的一部分,现阶段大多借鉴无人机的轨迹规划方法,即采用类似a*、rrt*及其变体等算法规划出离散路径点,然后通过轨迹插值的方式使其连续平滑。但此类方法将轨迹规划的过程分为两个不相关的步骤,无法保证轨迹的最优性。并且,在此过程中没有考虑飞行器的性能约束、飞行平稳性和能量消耗等问题,而这些问题对于载人飞行器的安全飞行和乘客舒适性感受至关重要。
技术实现要素:
5.针对现有技术的不足,本发明提出一种面向evtol空中旅游观光的轨迹规划方法,以实现飞行器通过所有设定的观景点为导向,乘客舒适性为约束、减少能量消耗为优化目标,对飞行器的工作空间进行充分的搜索,得到了无碰撞、符合飞行器性能约束(控制器可跟踪)、乘客舒适性好、耗能少的轨迹。
6.本发明的具体技术方案如下:
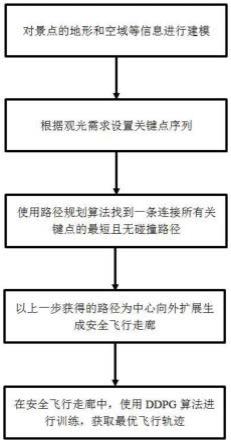
7.一种面向evtol空中旅游观光的轨迹规划方法,包括以下步骤:
8.s1:对某一景点的地形、空域信息进行建模,获得用于路径规划的地图;
9.s2:根据观光需求,设置evtol飞行器需要途经的关键路径点序列;
10.s3:采用路径规划算法找到一条连接所有关键路径点的最短且无碰撞的路径;
11.s4:以s3生成的路径为中心,向外扩展生成一个安全飞行走廊,所述安全飞行走廊内部无障碍物;
12.s5:在所述安全飞行走廊中,采用深度强化学习算法进行仿真训练,获得能够完成飞行任务且消耗能量最少的轨迹,完成轨迹规划。
13.进一步地,步骤s1所述的建模通过使用无人机搭载激光雷达在景点上空飞行,获取该景点地形的三维点云数据得到。
14.进一步地,所述用于路径规划的地图采用octomap地图或voxblox地图,所述octomap地图需将所述三维点云数据转换为八叉树数据格式,所述voxblox地图需将所述三维点云数据转换为截断符号距离场数据格式。
15.进一步地,所述步骤s3具体通过以下子步骤实现:
16.(3.1)在s2得到的关键路径点序列(p1,p2,
…
,p
n-1
,pn)中依次选取相邻的两个关键路径点作为起点和终点,形成一系列起始点对(p1,p2)、(p2,p3)、
…
、(p
n-1
,pn);
17.(3.2)分别对每一组起始点对(pj,p
j+1
)采用路径规划算法在octomap地图中进行寻路,得到分段路径path_j,其中j=1,2,
…
,n-1;
18.(3.3)将分段路径path_1,path_2,
…
,path_n-1依次相连,整合成完整路径path。
19.进一步地,所述路径规划算法采用a*算法。
20.进一步地,所述步骤s4具体通过以下子步骤实现:
21.(4.1)以s3获得的所述路径中的各个关键路径点为中心,在与路径切线方向垂直的平面内以一定范围内的半径做圆,所有圆形相连形成一个管道;其中半径的范围由人为设定,至少大于飞行器的最大宽度;
22.(4.2)将(4.1)得到的管道与环境障碍物相交的部分剔除,得到最终的安全飞行走廊。
23.进一步地,所述步骤s5具体通过以下子步骤实现:
24.(5.1)获取飞行器动力学参数,采用单刚体动力学模型对该飞行器进行建模;
25.(5.2)设计动作空间,以飞行器位置的四阶导数和偏航角的三阶导数为动作空间,根据飞行器的运动-动力学约束,给出所述飞行器位置的四阶导数和偏航角的三阶导数的上下界,作为动作采样的范围;
26.(5.3)设计状态空间,飞行器状态取飞行器的位置及其一至四阶导数、偏航角的一至三阶导数,将所有信息合并成一个列向量,得到第i个仿真步下飞行器的状态s(ti),i为自然数;
27.(5.4)设定奖励函数,将关键路径点序列中的点依次作为目标关键路径点;若某一仿真步时,飞行器通过当前目标关键路径点,则给予飞行器一个正的奖励值,并将当前目标路径点的后一个点设置为新的目标关键路径点;飞行器未通过目标关键路径点的其余每个仿真步,都给予飞行器第一负值作为惩罚;若飞行器飞出安全飞行走廊,则给予飞行器第二负值作为惩罚,所述第一负值大于所述第二负值;第i个仿真步的奖励记为r(ti);
28.(5.5)进行仿真训练;采用深度强化学习算法进行训练,每个仿真回合将飞行器初始状态s(ti)输入到训练网络中,输出动作a(ti),初始状态时i=0;根据步骤(5.1)得到的模型进行仿真,得到下一仿真步的状态s(t
i+1
)、奖励r(ti);重复上述操作,直到飞行器到达最终目标点,或超出最大仿真步数,或飞行器飞出所述安全飞行走廊,终止该仿真回合;
29.进行多个仿真回合,直至收敛至最优策略,将其作为飞行器的全局轨迹,完成面向evtol空中旅游观光的轨迹规划。
30.进一步地,步骤(5.5)所述的最优策略得到的轨迹满足:输出的飞行器运行轨迹既满足飞行器的运动-动力学约束,又能沿着规定的关键路径点飞行,并且不会与环境障碍物发生碰撞,能通过轨迹跟踪控制器实现轨迹跟踪。
31.进一步地,所述深度强化学习算法选用深度确定性策略梯度算法,即ddpg算法。
32.一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现面向evtol空中旅游观光的轨迹规划方法。
33.本发明的有益效果是:
34.(1)本发明采用飞行器状态(即飞行器位置和偏航角)的高阶导数作为动作空间,使飞行器状态的变化平缓,不会出现急转弯或急加减速的情况,提高了乘客的舒适性,同时节省飞行器的能源消耗。
35.(2)本发明所提出的方法在安全飞行走廊中进行轨迹规划,避免与障碍物发生碰撞,保障了飞行过程中的安全性。
36.(3)本发明所提出的方法对飞行器的动作空间进行充分的搜索,使得到的轨迹符合飞行器性能约束,即控制器可跟踪。
37.(4)本发明所提出的方法在规划轨迹时将飞行品质作为考量,避免了经常性的急加减速,给乘客提供了良好的乘坐体验。
38.(5)本发明所提出的方法使整个飞行器系统的耗能减少,提升可飞行次数,降低成本,增加景区收益。
附图说明
39.图1是本发明方法的流程图。
40.图2是本发明实施例中环境模型的octomap地图。
41.图3是本发明步骤s5的流程图。
具体实施方式
42.下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
43.如图1所示,为本发明面向evtol空中旅游观光的轨迹规划方法的流程图,具体步骤如下:
44.s1:对某一景点的地形、空域等环境地图信息进行建模,获得一个可用于路径规划的地图。
45.首先利用无人机获取该景点的三维点云数据,可直接使用三维点云数据作为用于路径规划的地图,也可将三维点云数据进行转换,转换为八叉树数据格式,形成可用于路径规划的octomap地图,或转换为截断符号距离场即tsdfs(truncated signed distance fields)数据格式,形成可用于路径规划的voxblox地图。转换得到octomap地图或voxblox地图,可以节省数据存储的空间,便于大范围地图的保存,并且使碰撞检测过程变得更易于实现。
46.本实施例中选取南湖部分地区构建的地图为环境模拟的octomap地图,结果如图2所示,具体通过以下子步骤实现:
47.(1.1)使用无人机搭载激光雷达在景点上空飞行,获取该景点地形的三维点云数据。
48.(1.2)将三维点云数据转换为八叉树数据格式,形成可用于路径规划的octomap地
图。
49.s2:根据景点的观光需求,设置evtol飞行器需要途经的关键路径点序列。
50.s3:采用路径规划算法找到一条连接所有关键路径点的最短且无碰撞的路径。
51.在环境模型的octomap地图中,采用路径规划算法找到一条连接所有关键路径点的最短且无碰撞路径,此处的无碰撞指不与环境障碍物发生碰撞。本实施例中采用a*算法作为路径规划算法,具体通过以下子步骤实现:
52.(3.1)在s2得到的关键路径点序列(p1,p2,
…
,p
n-1
,pn)中依次选取相邻的两个关键路径点作为起点和终点,形成一系列起始点对(p1,p2)、(p2,p3)、
…
、(p
n-1
,pn)。
53.(3.2)分别对每一组起始点对(pj,p
j+1
)采用a*算法在octomap地图中进行寻路,在每一步路径搜索的过程中,将evtol飞行器的轮廓进行膨胀处理,结合地图进行碰撞检测,以确保搜索的路径上没有障碍物,并且保证evtol飞行器有较高的安全裕度。最终得到分段路径path_j,其中j=1,2,
…
,n-1。
54.(3.3)将分段路径path_1,path_2,
…
,path_n-1依次相连,整合成完整路径path。
55.s4:生成安全飞行走廊。
56.以s3生成的路径path为中心,向外扩展一定范围,生成一个安全飞行走廊,生成的安全飞行走廊需保证内部无障碍物,具体通过以下子步骤实现:
57.(4.1)以完整路径path中的各个路径点为中心,在与路径切线方向垂直的平面内以一定的范围为半径做圆,所有圆相连形成一个管道。其中半径的范围需人为设定,至少大于飞行器的最大宽度,且避免形成的管道与过多的环境障碍物相交。
58.(4.2)将管道与环境障碍物相交的部分剔除,得到最终的安全飞行走廊。
59.s5:采用深度强化学习算法进行仿真训练,获得能够完成飞行任务且消耗能量最少的轨迹,完成轨迹规划。
60.如图3所示,该步骤具体通过以下子步骤实现:
61.(5.1)获取飞行器动力学参数,动力学参数包括:质量、惯量、几何尺寸。采用单刚体动力学模型对该飞行器进行建模,列出动力学方程。
62.(5.2)设计动作空间,以飞行器位置p(t)=[x(t),y(t),z(t)]
t
的四阶导数p
(4)
(t)和偏航角的三阶导数为动作空间,根据飞行器的运动-动力学约束,给出p
(4)
(t)和的上下界作为动作采样的范围。采用飞行器状态(即飞行器位置和偏航角)的高阶导数作为动作空间,使飞行器状态的变化平缓,不会出现急转弯或急加减速的情况。
[0063]
(5.3)设计状态空间,飞行器某一时刻的状态取该时刻下飞行器的位置p(t)及其一至四阶导数p
(1)
(t)、p
(2)
(t)、p
(3)
(t)、p
(4)
(t),以及飞行器的偏航角的一至三阶导数等信息,将所有信息合并成一个列向量s(t),将其作为该时刻的状态。
[0064]
(5.4)设定奖励函数,将关键路径点序列中的点依次作为目标关键路径点。若某一仿真步飞行器通过当前目标关键路径点,则给予飞行器+1的奖励,并将当前目标路径点的后一个点设置为新的目标关键路径点;飞行器未通过目标关键路径点的其余每个仿真步,都给予飞行器-0.001的惩罚,使飞行器趋于尽快到达目标关键路径点以获得奖励;若飞行器飞出安全飞行走廊,则给予飞行器-100的惩罚,使飞行器趋于避免飞出安全飞行走廊,保持在安全飞行走廊内飞行。第i个仿真步的奖励记为r(ti),i为自然数。
[0065]
(5.5)在仿真环境中通过深度强化学习算法让evtol飞行器进行试错学习。
[0066]
本实施例中采用深度确定性策略梯度算法(deep deterministic policy gradient,以下简称ddpg)进行训练。ddpg是为了解决连续动作控制问题而提出的算法,其结构形式类似actor-critic。ddpg可以分为策略网络和价值网络两个大网络。
[0067]
策略网络,也就是actor。actor输出的是一个确定性的动作,产生这个确定性动作的网络定义为a=μ
θ
(s),其中,s为飞行器状态,a为输出动作。以往的策略梯度(policy gradient)采取的是随机策略,每一次获取动作都需要对当前的最优策略的分布进行采样,而ddpg采取的则是确定性策略,直接通过函数μ确定。actor的估计网络是μ
θ
(s),θ是神经网络的参数,这个估计网络就是用来输出实时的动作。此外,actor还有一个相同结构但不同参数的目标网络,是用来更新价值网络critic的。actor的估计网络和目标网络都是输出动作a。
[0068]
价值网络,也就是critic。它的作用是拟合价值函数q
ω
(s,a)。critic同样也有一个估计网络和一个目标网络,这两个网络在输出端都输出当前状态的价值q-value,在输入端则有所不同。critic的目标网络输入有两个参数,分别是当前状态的观测值s和actor的目标网络输出的动作a。critic的估计网络的输入则是当前actor的估计网络输出的动作a。
[0069]
将飞行器初始状态s(ti)输入到策略网络actor中,输出动作a(ti),初始状态时i=0。将飞行器初始状态s(ti)和动作a(ti)作为输入,根据步骤(5.5)得到的单刚体动力学模型进行仿真,即将输入代入动力学方程,得到下一仿真步时刻的状态s(t
i+1
)、奖励r(ti),并将每一次的状态转移数据(s(ti),a(ti),r(ti),s(t
i+1
))存入经验池中。以一定的频率对网络进行训练更新,每次更新通过在经验池中采样一个小批次(如16组、32组)的状态转移数据作为输入,按照ddpg算法的优化目标进行网络权重的更新。critic的估计网络的优化目标为最小化该损失函数actor的估计网络通过采样数据的策略梯度进行更新,其中,l为损失函数,n表示在经验池中采样小批次的状态转移数据的大小,
▽
表示策略梯度的算子,表示策略梯度。
[0070]
重复上述仿真操作,直到飞行器到达最终目标点,或超出最大仿真步数,或飞行器飞出安全飞行走廊,则终止该仿真回合,其中最大仿真步数为人为设定。
[0071]
进行多个仿真回合,直至收敛至最优策略;最优策略得到的轨迹满足:输出的飞行器运行轨迹既满足飞行器的运动-动力学约束,又能沿着规定的关键路径点飞行,并且不会与环境障碍物发生碰撞,可以将其作为飞行器的全局轨迹,通过轨迹跟踪控制器实现轨迹跟踪。
[0072]
本发明方法能够生成无碰撞、符合飞行器性能约束、乘客舒适性好、耗能少的轨迹规划。本发明提前获取工作空间的三维地图,规划了一条无碰撞路径;为了保障良好的用户体验,在规划轨迹时将飞行品质作为考量,采用连续动作空间的深度学习算法,保证了飞行轨迹的平滑性,避免了飞行器经常性的急加减速;减少整个系统的耗能,提升可飞行次数,增加景区收益。
[0073]
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限
制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1