一种基于深度强化学习的无人机应急场景巡检方法及其系统与流程
本发明涉及人工智能领域、无线通信领域,具体是一种基于深度强化学习的无人机应急场景巡检方法及其系统。
背景技术:
1、近年来,在很多自然灾害的救援活动中,如地震、海啸、洪水、森林火灾,应急通信的需求急剧增长。受灾地区通常面临着通信基础设施的毁损、难以及时获得灾区的详细信息,这给快速救援带来了许多的困难。因此,如何快速获得灾区的数据信息对于减少人员伤亡、降低经济损失至关重要。目前的应急巡检体系在巡检时通常需要花费大量的时间,而且在进行通信时通常面临着传输速率低、带宽不足、时延高等缺点。因此,如何构建一个在应急场景中能够快速完成巡检任务并将巡检信息发送给数据处理中心至关重要,其可以节约救援时间,减少人员伤亡和降低经济损失。
2、而随着科技的进步和经济的快速发展,无人机的造价越来越廉价,其不仅在军事上被广泛的应用,其在民用中也受到的极大的欢迎。尤其是无人机巡检被认为可以提高巡检效率的有效方式,这是因为无人机具有灵活的机动性、可以快速部署、飞行不受地形限制、在通信中具有高概率的line-of-sight(los)信道等优点。但是,无人机通信系统的通信资源块(如通信带宽)是有限的,合理的对通信资源进行分配可大大减少无人机在巡检过程中的数据传输时间。
技术实现思路
1、针对现有技术存在的上述不足,本发明提出了一种基于深度强化学习的无人机应急场景巡检方法及其系统,无人机在获取应急场景中巡检点的位置后,通过优化自身的轨迹和无线通信资源,从而减少系统总的巡检时间。
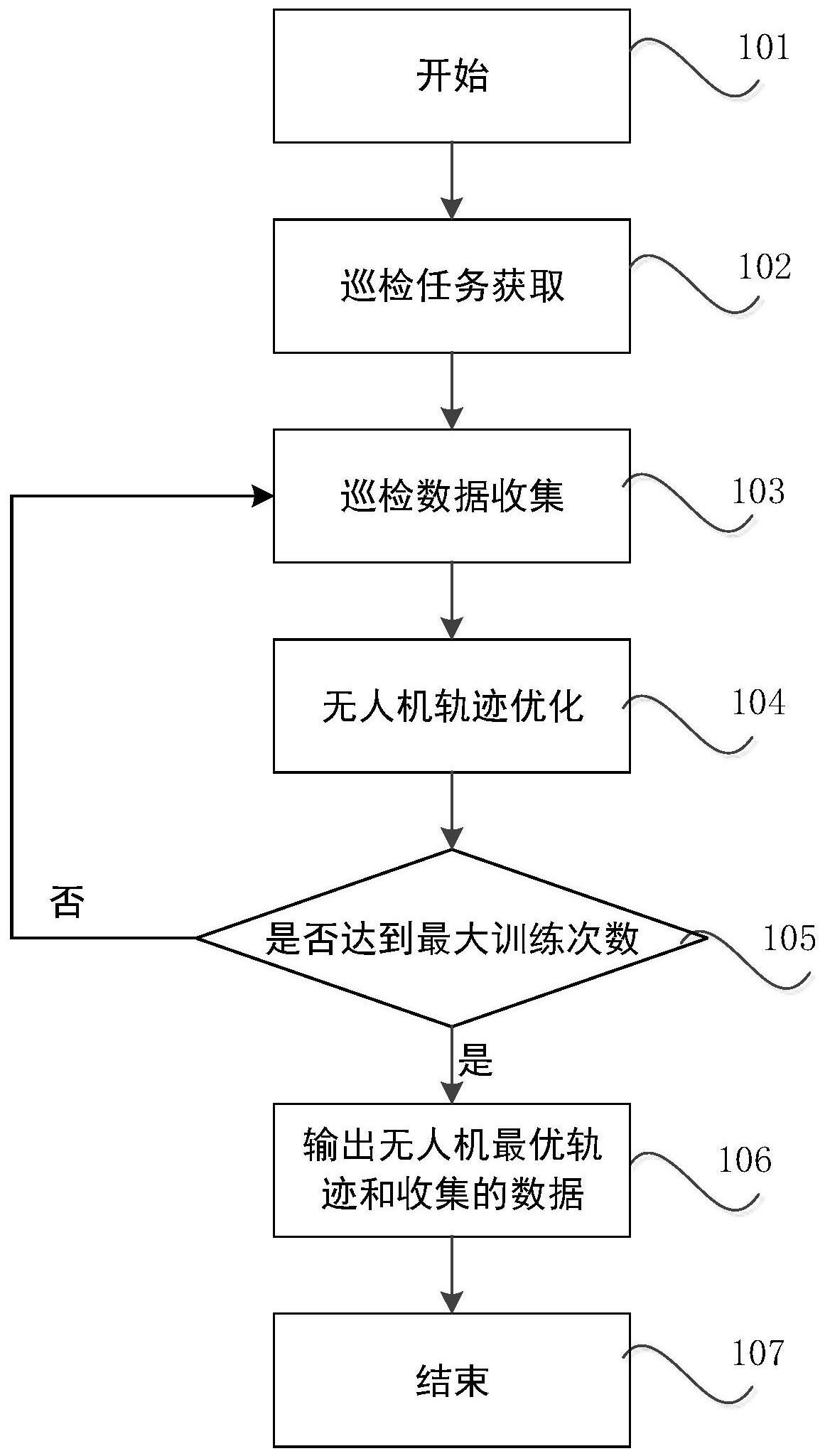
2、一种基于深度强化学习的无人机应急场景巡检方法,包括如下步骤:
3、步骤s1.巡检控制中心根据应急区域发送的请求确定无人机需要巡检的位置坐标以及各个地面救援人员的位置信息;
4、步骤s2.无人机根据获得的需要巡检的位置坐标以及各个地面救援人员的位置信息开始执行巡检任务,在无人机执行巡检任务的过程中,通过已知巡检点的位置坐标,使用深度强化学习中的dueling-dqn算法对无人机的轨迹进行优化来最小化无人机巡检过程中的数据收集时间;
5、步骤s3.输出优化的无人机巡检的最优轨迹与收集的巡检数据。
6、进一步的,所述步骤s2具体流程如下:
7、步骤s21.参数初始化:无人机初始化系统的各项参数,包括无人机当前的位置坐标、初始化模型的参数;
8、步骤s22.无人机获取距离当前位置最近的巡检点的位置坐标,确定自己当前时刻所巡检的巡检点位置wm=[xm,ym,zm],其中xm、ym、zm分别表示巡检点在x轴、y轴与z轴的坐标;
9、步骤s23.对无人机的轨迹进行优化设计:无人机使用深度强化学习优化巡检轨迹的过程中,首先将所建立的问题转化为马尔科夫决策问题,其中其可由四部分组成,即<s,a,p,r>,其中s为状态空间,a为动作空间,p为无人机执行任务时的状态转移概率,r为无人机执行巡检任务时的奖励函数,假设无人机当前的位置为qn=[xn,yn,zn],其中xn、yn、zn分别表示无人机在x轴、y轴与z轴的坐标,然后无人机根据策略选择机制p从动作空间a中选择一个当前的飞行方向vn,进而无人机转移到下一个位置qn+1=[xn+1,yn+1,zn+1],假设无人机在一个时隙内移动的距离为则无人机的状态转移遵循公式:
10、
11、步骤s24.无人机根据移动前后距离所选择巡检点的距离的差值获得一个奖励rn,其中表示当前无人机与所选择巡检点的距离,表示无人机根据策略选择机制p从动作空间a中选择一个当前的飞行方向vn后与所选择巡检点的距离,其中奖励的设计表示为:
12、
13、其中ra为一个正值,其表示无人机在经过策略选择移动之后其距离选择的巡检点越来越近;rb为一个负值,其表示无人机在经过策略选择移动之后其距离选择的巡检点越来越远;此外,如果无人机完成该巡检任务其会获得一个较大的正奖励rc;
14、步骤s25.将状态转移的结果(qn,vn,rn,qn+1)保存到系统的经验池中;
15、步骤s26.从经验池中选择n1步样本,并使用梯度下降的方法来减小神经网络的损失函数从而优化无人机的轨迹,获得更大的奖励,其中损失函数定义为:
16、
17、其中rn+1表示无人机在n+1时隙获的奖励,λ表示折扣因子,θ*与θ表示影响神经网络模型参数的因子,q(qn,an|θ)表示current网络中无人机在当前位置qn采取动作an的q值,表示在target网络中无人机在当前位置qn+1采取动作的q值,无人机收集当前位置qn+1巡检点的数据并将通信资源进行优化分配,从而节约巡检时数据收集的时间;
18、步骤s27.判断无人机是否完成该巡检任务,若否,则无人机执行步骤s22.),若是则执行步骤s28);
19、步骤s28.判断无人机是否完成所有巡检任务,若否,则执行步骤s22.),若是,巡检任务结束;
20、步骤s29.判断是否达到最大迭代次数,若否,重复步骤s22)-步骤s28),直至算法达到最大迭代次数。
21、一种基于多无人机的智能电力线路巡检系统,包括巡检任务获取模块、巡检数据收集模块、无人机轨迹优化模块、结果输出模块;
22、所述巡检任务获取模块,用于根据应急区域发送的请求确定无人机需要巡检的位置坐标以及各个地面救援人员的位置信息;
23、所述无人机轨迹优化模块,用于在无人机执行巡检任务的过程中,通过已知巡检点的位置坐标,使用深度强化学习中的dueling-dqn算法对无人机的轨迹进行优化来最小化无人机巡检的时间;
24、所述巡检数据收集模块,用于在无人机执行巡检任务的过程中收集巡检数据;
25、所述结果输出模块步骤,用于输出优化的无人机巡检的最优轨迹与收集的巡检数据。
26、进一步的,所述无人机轨迹优化模块在无人机执行巡检任务的过程中,通过已知巡检点的位置坐标,使用深度强化学习中的dueling-dqn算法对无人机的轨迹进行优化来最小化无人机巡检的时间,具体包括:
27、步骤s21.参数初始化:无人机初始化系统的各项参数,包括无人机当前的位置坐标、初始化模型的参数;
28、步骤s22.无人机获取距离当前位置最近的巡检点的位置坐标,确定自己当前时刻所巡检的巡检点位置wm=[xm,ym,zm],其中xm、ym、zm分别表示巡检点在x轴、y轴与z轴的坐标;
29、步骤s23.对无人机的轨迹进行优化设计:无人机使用深度强化学习优化巡检轨迹的过程中,首先将所建立的问题转化为马尔科夫决策问题,其中其可由四部分组成,即<s,a,p,r>,其中s为状态空间,a为动作空间,p为无人机执行任务时的状态转移概率,r为无人机执行巡检任务时的奖励函数,假设无人机当前的位置为qn=[xn,yn,zn],其中xn、yn、zn分别表示无人机在x轴、y轴与z轴的坐标,然后无人机根据策略选择机制p从动作空间a中选择一个当前的飞行方向vn,进而无人机转移到下一个位置qn+1=[xn+1,yn+1,zn+1],假设无人机在一个时隙内移动的距离为则无人机的状态转移遵循公式:
30、
31、步骤s24.无人机根据移动前后距离所选择巡检点的距离的差值获得一个奖励rn,其中表示当前无人机与所选择巡检点的距离,表示无人机根据策略选择机制p从动作空间a中选择一个当前的飞行方向vn后与所选择巡检点的距离,其中奖励的设计表示为:
32、
33、其中ra为一个正值,其表示无人机在经过策略选择移动之后其距离选择的巡检点越来越近;rb为一个负值,其表示无人机在经过策略选择移动之后其距离选择的巡检点越来越远;此外,如果无人机完成该巡检任务其会获得一个较大的正奖励rc;
34、步骤s25.将状态转移的结果(qn,vn,rn,qn+1)保存到系统的经验池中;
35、步骤s26.从经验池中选择n1步样本,并使用梯度下降的方法来减小神经网络的损失函数从而优化无人机的轨迹,获得更大的奖励,其中损失函数定义为:
36、
37、其中rn+1表示无人机在n+1时隙获的奖励,λ表示折扣因子,θ*与θ表示影响神经网络模型参数的因子,q(qn,an|θ)表示current网络中无人机在当前位置qn采取动作an的q值,表示在target网络中无人机在当前位置qn+1采取动作的q值,无人机收集当前位置qn+1巡检点的数据并将通信资源进行优化分配,从而节约巡检时数据收集的时间;
38、步骤s27.判断无人机是否完成该巡检任务,若否,则无人机执行步骤s22.),若是则执行步骤s28);
39、步骤s28.判断无人机是否完成所有巡检任务,若否,则执行步骤s22.),若是,巡检任务结束;
40、步骤s29.判断是否达到最大迭代次数,若否,重复步骤s22)-步骤s28),直至算法达到最大迭代次数。
41、本发明具有以下优点:
42、1、本发明通过优化无人机的轨迹来达到在应景场景中巡检时间最小化问题,可以达到用最短的时间完成给定的应急场景中的巡检任务,具有低成本、低延时,高精度的优点。
43、2、将dueling-dqn算法应用于应急场景时间最小化巡检系统,使得算法更加稳定、收敛更快。
44、3、算法的可扩展性较强,其不仅可以用于无人机的巡检来达到应急巡检的目的,其还可以适用于更加复杂的场景,所改进的算法具有较强的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!