基于深度强化学习的智能网联汽车路径跟踪控制方法
本发明属于智能网联汽车领域,涉及一种基于深度强化学习的智能网联汽车路径跟踪控制方法。
背景技术:
1、随着智能网联汽车(intelligent and connected vehicle,icv)的发展,路径跟踪控制(path-following control,pfc)技术作为基于传统自主驾驶辅助系统(advancedriver assistance systems,adas)功能的进一步提升,其本质是现代通信及网络环境下智能车辆按照领航车轨迹或预定轨迹安全、平稳的行驶。对于此问题,依据现有的技术积累,难点在于基于动力学(车辆自身的结构特征)进行路径跟踪控制器的设计,主要包括车辆动力学特性的限制(如质心侧偏角阙值)、车身转向系统裕度等约束性条件。
2、目前,现有的技术包括公开的专利大都集中在对控制方法的突破上,如传统滑模控制、pid算法、预瞄跟踪控制、鲁棒控制等一系列控制方法都集中在对于实现更好控制效果的研究上。此类方法往往以忽略车辆自身的结构特征限制为基础进行模型设计,存在不合理性。随着强化学习的发展,结合深度学习实现端到端控制效果的深度强化学习(deepreinforcement learning,drl)方法的出现为解决无法建立精确系统模型提供了新的思路。如公开号为cn11322017a,名称为:基于深度强化学习的自动驾驶智能车轨迹跟踪控制策略的专利申请,该专利申请集中在利用基于深度强化学习的方法改进传统控制模型算法上。此技术方案虽然从控制策略上实现路径跟踪控制效果,但其在领航轨迹信息的获取、控制系统坐标系以及车辆的动力学约束等信息获取上依旧没有考量,只集中在实现端到端的控制效果上,对于整个路径跟踪控制系统难以保证驾驶的安全性。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于深度强化学习的智能网联汽车路径跟踪控制方法,兼顾车辆动力学约束特性和模型精确度,实现在保证车辆稳定性的条件下完成路径跟踪控制。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于深度强化学习的智能网联汽车路径跟踪控制方法,包括以下步骤:
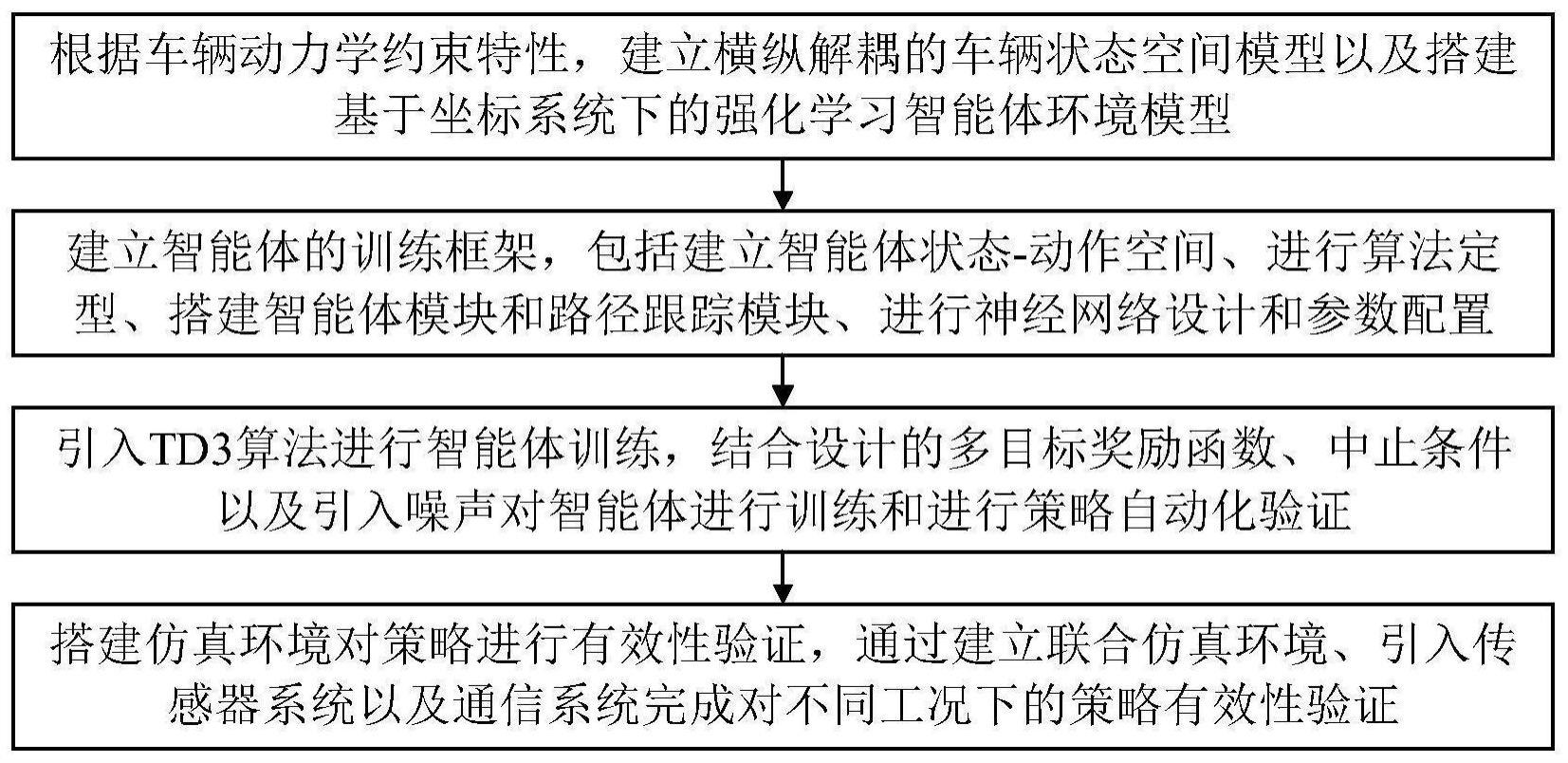
4、s1、根据车辆动力学约束特性,建立横纵解耦的车辆状态空间模型以及搭建基于坐标系统下的强化学习智能体环境模型;
5、s2、建立智能体的强化学习训练框架,包括:建立智能体状态-动作空间、进行算法定型、搭建智能体模块和路径跟踪模块以及进行神经网络设计和参数配置;
6、s3、对智能体进行训练以及进行策略自动化验证;
7、s4、搭建仿真环境对策略进行有效性验证,通过建立联合仿真环境、引入传感器系统以及通信系统完成对不同工况下的策略有效性验证。
8、进一步地,步骤s1具体为:
9、s11、建立跟随车辆状态空间模型,如下式所示:
10、
11、该状态空间模型的输入为车辆加速度aego以及前轮转向角角度θsteer,输出为车辆质心位置的纵向速度vx、横向速度vy以及偏航角速度eyaw;
12、同时,在跟随车辆的纵向控制上建立安全跟驰模型:
13、ddes=dsafe+ta×vego
14、式中,ddes表示期望车间间距,dsafe表示最小静止距离,ta表示期望车间时距常数,vego表示跟随车辆速度;
15、s12、建立环境模型:
16、1)基于大地坐标系,利用车载传感器构建传感系统进行车道检测,获取道路以及车辆信息,包括道路曲率rho,跟随车辆横向偏差e1、相对偏航角e2等信息;
17、2)基于大地坐标系和车身坐标系,并结合传感器,检测领航车设定速度vlead、领航车位置plead、跟随车辆纵向速度vego、跟随车辆位置pego、前后车辆之间的相对距离drel以及前后车辆之间的相对速度verr。
18、更进一步,跟随车辆状态空间模型由纵向状态空间模型和横向状态空间模型耦合而成;
19、其中纵向状态空间模型如下式所示:
20、
21、式中,τ表示车辆纵向加速度跟踪时间常数;
22、纵向状态空间模型的输入为纵向加速度aego,输出为纵向速度vx;
23、横向状态空间模型如下式所示:
24、
25、
26、式中,m表示车辆质量,lf和lr分别表示车辆质心到前轴和后轴的距离,cf和cr分别表示前轮和后轮的侧偏刚度,iz表示车辆横摆转动惯量;
27、横向状态空间模型的输入为前轮转向角θsteer,输出为横向速度vy以及偏航角速度eyaw。
28、进一步地,步骤s2具体为:
29、s21、建立智能体的状态空间和动作空间;
30、状态空间如下所示:
31、s=[vego,drel,vlead,e1,e2]
32、式中,vego表示跟随车辆纵向速度,vlead表示领航车设定速度,drel表示前后车辆之间的相对距离,e1表示跟随车辆横向偏差,e2表示相对偏航角;
33、动作空间如下所示:
34、a=[aego,θego]
35、式中,aego表示车辆纵向加速度,θego表示跟随车辆前轮转向角;aego和θego的幅度区间由车辆特征确定;
36、s22、进行算法设计与神经网络搭建
37、1)根据步骤s21中确定的状态空间和动作空间,建立马尔科夫决策过程:
38、<s,a,p,r,γ>
39、其中,p表示状态转移概率矩阵,即智能体在状态s下执行策略π选取动作a,并转移到状态s′的概率;r表示奖励函数,即智能体在状态s下执行动作a获取的期望奖励;γ表示折扣因子,用于计算累计奖励值;
40、2)采用基于actor-critic(ac)架构的双延迟深度确定性策略梯度算法(td3)对智能体进行训练;
41、3)搭建神经网络:神经网络输入层、输出层层数各为一层,神经元个数由智能体状态空间与动作空间确定;神经网络的隐含层层数以及神经元个数通过下式计算:
42、
43、ynum=β1ylay+β2
44、式中,ynum表示隐含层中神经元个数,ylay表示隐含层层数,a表示神经网络输入节点个数,b表示输出节点个数,α和β表示计算权重参数;
45、s23、搭建智能体模块:智能体模块的输入包括:智能体状态、奖励值以及训练终止条件;输出包括智能体执行的动作;
46、s24、搭建路径跟踪模块,包括坐标转换模块和位置更新模块;所述坐标转换模块用于将车身坐标系下的参数转换为大地坐标系下的参数;所述位置更新模块用于输出下一时刻跟随车辆在大地坐标系下的位置;
47、s25、连接各个模块,搭建强化学习训练框架,将已构建好的智能体模块和路径跟踪模块接入仿真环境中,按照需求进行配置连接,完成整体模块的搭建;
48、s26、配置训练参数,开始训练;其中,训练参数包括:
49、最大迭代次数:即训练回合最多可迭代次数;
50、训练停止条件:即当智能体的平均奖励或回合奖励达到一定值时,停止训练;
51、训练停止条件达到数值:即平均奖励需要达到的数值;
52、平均奖励数据长度:即平均奖励使用的累计奖励回合次数。
53、更进一步,在步骤s23中,智能体模块的奖励函数为多目标奖励函数,如下式所示:
54、
55、式中,ut-1表示智能体上一时刻输出动作,verr表示与设定轨迹的相对速度差,verr=vlead-vego,at-1表示跟随车辆上一时刻输出加速度,ρ表示计算权重参数,e表示科学计数;
56、且:
57、ct=i,if isdone=η1
58、
59、
60、其中,isdone表示训练终止条件,i表示固定奖励值,η表示奖励计算权重;
61、训练终止条件为:
62、1)横向误差过大:|e1|>b1;
63、2)跟随车辆纵向速度出现较小速度甚至减速为0:|vego|<b2;
64、3)前后两车之间发生碰撞:drel<b3;
65、其中,b表示训练条件中的计算参数。
66、进一步地,步骤s3具体为:
67、s31、针对路径跟踪过程中领航车与跟随车的初始训练状态引入噪声:
68、p′lead(0)=plead(0)+random[-δ1,δ1]
69、p′ego(0)=pego(0)+random[-δ2,δ2]
70、v′ego(0)=vego(0)+random[-δ3,δ3]
71、式中,plead和p′lead分别表示加入噪声前和加入噪声后领航车的位置,pego和p′ego分别表示加入噪声前和加入噪声后跟随车的位置,vego和v′ego分别表示加入噪声前和加入噪声后跟随车的纵向速度,random(·)表示随机函数,δ表示产生随机数的限幅;
72、s32、对智能体进行回合训练;
73、s33、对智能体的深度强化学习模型进行测试,自动验证深度强化学习训练收敛过程中产生的可执行策略,并保存有效策略。
74、进一步地,在步骤s4中,通过采用仿真环境(matlab/simulink+prescan)进行闭环测试;其中,matlab负责提供智能体状态-动作空间以及神经网络结构的配置;simulink负责车辆智能体模块以及路径跟踪模块的搭建;prescan负责提供整个环境模型。
75、本发明的有益效果在于:
76、(1)本发明可以在保证车辆稳定性的条件下完成路径跟踪控制,且具有较强的鲁棒性;
77、(2)由于本发明采用了深度强化学习的端到端控制方法,且通过多目标奖励函数设计方式设计控制器,并不需要依赖于精确车辆数学模型,简化系统模型,降低了控制器设计难度以及计算的复杂度,能够有效提高系统的实时性,同时还能实现高控制精度;
78、(3)本发明的路径跟踪方法算法简单,整体系统易于工程实现。
79、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!