一种多无人艇避碰决策控制系统
本发明属于无人艇避碰领域,具体涉及一种多无人艇避碰决策控制系统。
背景技术:
1、随着人工智能的快速发展,智能化体现在各个领域,传统船舶也迎来转折,以保障船员安全减少船员上船作业为目的的智能船舶和无人艇应运而生。无人船是无人驾驶技术研究的新领域,对于海洋开发利用,单条无人艇很难完美完成,无人艇集群可以有效完成水质采样、海上救援和辅助靠泊等协同作业任务。由于近海领域水体复杂以及船艇数量大,使无人艇在航行安全问题上面临严峻挑战,因此对无人艇航行控制与航行安全提出了更高要求。基于国际海上避碰规则(colregs)与船长经验提出一种适用于多无人艇航行避碰规则,对无人艇海上安全航行具有重要战略意义。
2、无人艇避碰研究中,一是当前技术大多针对单无人艇,对于无人艇集群研究较少,现阶段随着海洋开发利用逐步加大,应用场景逐步增多,对无人艇功能和数量提出更高要求,单无人艇限制了海上应用场景研究。二是当前技术大都停留在仿真阶段,从仿真到工程应用实现困难,且算法迭代趋于饱和,缺乏以实际船艇应用为主体的避碰决策控制系统。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种多无人艇避碰决策控制系统,实现多无人艇海上安全航行与安全作业。
2、为实现上述目的,本发明采用如下技术方案:
3、一种多无人艇避碰决策控制系统,包括终端、无人艇控制单元和底控单元;所述无人艇控制单元与终端通信连接;所述终端接收无人艇传感器数据获得环境信息与无人艇自身状态信息,通过避碰算法决策下一时刻无人船的状态,向无人艇控制单元发送下一时刻位置信息以及推力和力矩;所述无人艇控制单元根据接收到的数据信息,进行推力分配,并将推力分配指令发送给底层控制单元。
4、进一步的,所述无人艇控制单元与终端利用socket通信,无人艇控制单元作为server,终端作为client;所述无人艇控制单元启动,终端获取无人艇控制单元ip与端口,与控制器建立连接。
5、进一步的,所述底控单元通过pwm波驱动左右螺旋桨。
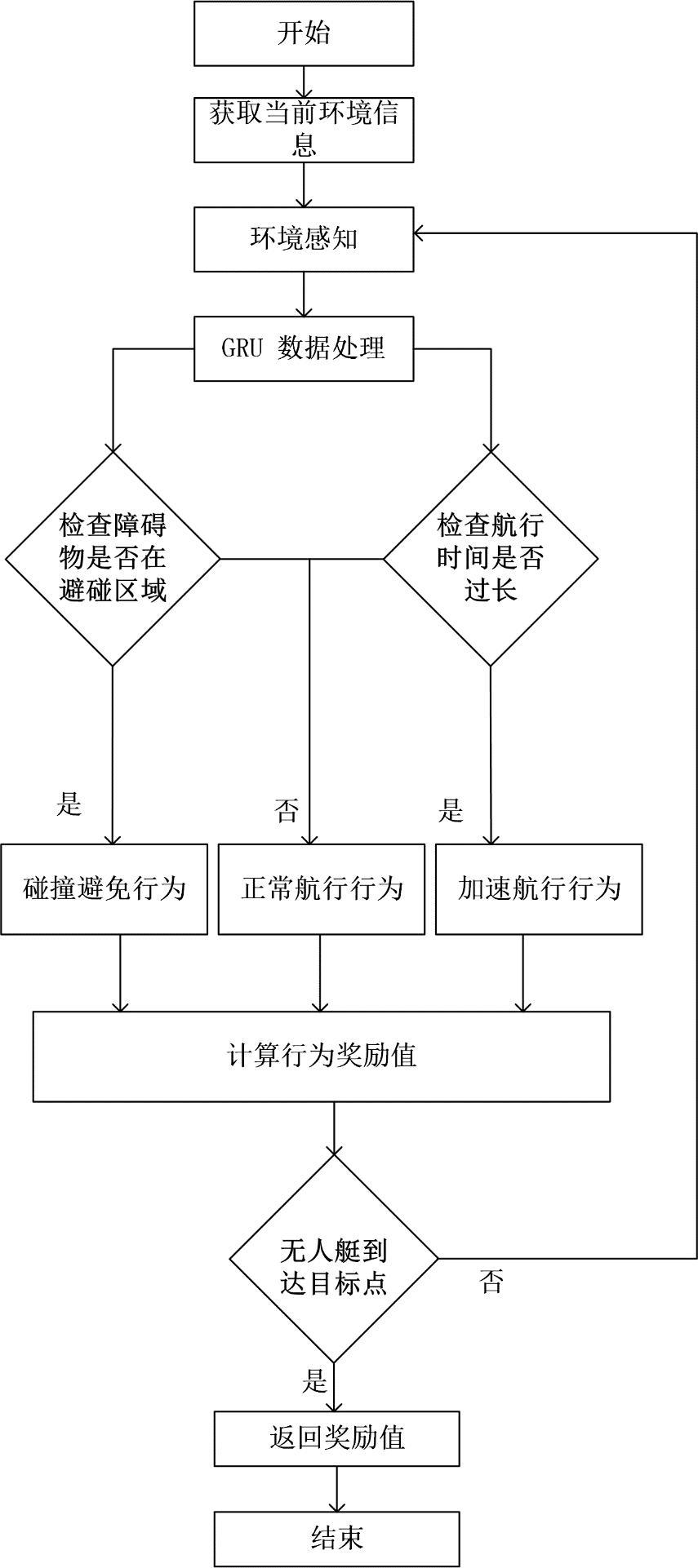
6、进一步的,所述避碰算法,具体如下:
7、步骤1:构建决策模型;
8、步骤2:载入未知环境,训练模型;
9、步骤3:设计测试环境,根据测试环境和当前无人艇位置状态,得到初步信息,用来进行下一时刻的决策;
10、步骤4:监测周围环境信息,用相互速度障碍向量表示;
11、步骤5:采用gru神经网络对输入信息处理成相同维度;
12、步骤6:每条无人艇的传感器需设置最大检测范围,接收信号为可检测范围内他艇尺寸、当前速度、当前艏向和避碰半径。获得局部环境的先验信息后,可实现局部避碰路径规划。
13、步骤7:根据相互速度障碍算法评估,执行避碰行为、正常航行或加速行为;
14、步骤8:根据无人艇当前状态与目标点的距离,反馈奖励,指导无人艇下一时刻的决策行为
15、步骤9:模型通过与环境持续交互来学习动作策略,学习效果由每个训练事件的累积奖励值表示,计算总奖励值与结果。
16、进一步的,所述决策模型,具体为:
17、设置了两个actor网络,结构为两层,每层256个神经元;
18、其中网络π采样,对旧网络πold更新;
19、在训练循环期间,π接收当前环境信息,根据信息选择动作更新状态s'并返回奖励r;
20、两个actor网络通过自适应kl惩罚,critic网络结构为两层,每层256个神经元,通过s',r评价动作好坏,对π更新。
21、进一步的,所述决策模型参数更新方式为离线更新.
22、进一步的,所述环境具体为:
23、设计训练环境,近端策略优化算法优化目标是极大化奖励的期望,在计算期望时,采样方法选择重要性采样方法;
24、重要性采样是实现在参数为θ'网络下收集数据对θ网络更新的关键,用两个分布函数p,q来描述两条无人艇,计算期望公式如下:
25、
26、理论上q可以是任何分布,但在实际中p和q相近,从两个分布方差来看
27、varx~p[f(x)]=ex~p[f(x)2]-(ex~p[f(x)])2 (2)
28、
29、当采样数据足够多时,p(x)=q(x);
30、利用重要性采样方法,进行在线策略到离线策略的转换;在策略梯度中,对期望的求解
31、
32、转换为
33、
34、其中是修正项;
35、进行梯度更新:
36、
37、其中aθ(st,at)是评估函数,用来评价在t时刻状态s下选取动作a的好坏;
38、新优化函数:
39、
40、由上式得到近端策略优化定义式
41、
42、其中β为权重系数,kl散度的作用是用来描述θ,θ'之间的差异性度量,差异性指参数对应的行为(actor)的差异;βkl(θ,θ')为限制条件;
43、对于无人艇a和b可选择的速度集合,互不通信前提下速度解有无数个,成对的速度解va和vb中,互为最大化的可选避碰速度集合中选择一对接近最优的速度,并表示为和互为最大化避碰速度集合表示为和速度集合如下式描述,
44、
45、
46、最优速度集合表示如下,
47、
48、式中d为无人艇的避碰圆,上式表示速度集合和包含接近和的速度对,且最优速度对超过其他速度集合;
49、假设无人艇a和b以最优速度和航行时会发生碰撞,即公式表示为,
50、
51、设u是以为起点,指向和到以边界最近点为终点的向量,如下式所示,
52、
53、设n为范围内,以为起点的法线,u为无人艇a和b在时间t内避碰速度最小改变值;无人艇集群中每条无人艇采取相同的策略,为避免碰撞,两条会遇无人艇均调整速度为这与相互速度障碍算法中将速度锥平移使其顶点位于一致。
54、进一步的,所述训练模型,具体为:
55、(1),根据设计的未知环境,确定多无人艇当前位置以及各无人艇目标点;
56、(2),相互速度障碍评估当前碰撞风险,并将结果反馈给近端策略优化,网络π执行动作并更新位置状态和动作状态,得到网络参数θ';
57、(3),网络πold根据环境进行决策,得到网络参数θ;
58、(4),通过kl散度进行θ'对θ的更新;
59、(5),相互速度障碍评估当前碰撞风险,若检测到碰撞风险,预测障碍物下一时刻的速度状态,通过障碍物下一时刻状态改变无人艇速度大小和方向,使无人艇避开障碍物;
60、(6),若距离目标点越来越远,则反馈较低奖励值,调整无人艇运动方向向目标点靠近;
61、(7),若选定速度与期望速度相差很大,则反馈较低奖励值,调整无人艇速度向期望速度靠近;
62、(8),判断是否完成避碰,若完成且到达目标点,则得到基本避碰路线;
63、(9),若没有完成避碰行为,则返回步骤(1),继续迭代更新直至到达目标点;
64、(10),训练n次,得到最优避碰路线算法训练完成,得到训练模型。
65、本发明与现有技术相比具有以下有益效果:
66、1、本发明以近端策略优化算法为基础,再辅以扩展策略,最优相互避碰算法算法对近端策略优化算法中奖励函数进行改进,解决了强化学习中稀疏奖励的问题;
67、2、本发明通过无人艇传感器收集环境信息和无人艇自身当前信息,通过socket通信协议对无人艇控制单元发送运动指令,控制指令主要包括算法根据获取的环境信息计算推力和力矩,控制单元根据指令进行推力分配,驱动左右两个螺旋桨工作,控制无人艇航行实现避碰决策行为,实现多无人艇海上安全航行与安全作业。
- 还没有人留言评论。精彩留言会获得点赞!