基于深度强化学习的渡船路径规划方法
本发明涉及内河渡船路径规划领域,更具体地说,涉及一种基于深度强化学习的渡船路径规划方法。
背景技术:
1、智能算法也称为无模型算法,可以通过与障碍物的互动和沟通来适应复杂的情况。在智能算法中,drl(深度强化学习)结合了dl(深度学习)和rl(强化学习),dl具有感知能力,而rl具有决策能力。因此,drl具有人类层面的决策能力来处理高维感官输入和动作输出。结合深度学习和q学习的深度q网络(dqn)提高了模型的稳定性,并允许智能体根据收到的奖励或惩罚修改其策略。由于dqn的能力,它已被用于机器人和车辆路径规划。yuan,j.等人为自主水下航行器建立了双dqn算法,以避免与考虑运行时间、总路径和规划时间的移动障碍物发生碰撞。bhopale,p.等人修改了传统的q学习算法,以处理自主水下航行器的多重避障问题。同时,在最近的一些研究中,dqn已被用于模拟船舶路径规划和导航。shen,h.等人开发了一种基于dqn的自动避免多艘船碰撞的方法,包括船舶机动性、人类经验和导航规则。wang,w.等人将colreg集成到drl算法中,并在丰富的遭遇情况下同时训练多艘船舶。这些研究表明,dqn在路径规划中的应用是可行的,特别是在船舶的自主导航方面。
2、从航行规则来看,渡船的航行环境以狭窄水域为主,在横渡内河河道时常与目标船形成交叉会遇,故在满足colregs的同时,仍需对内河渡船这一特殊场景作进一步的规则量化。从路径规划方法来看,现有大多数算法将全局路径与局部避让相分离,即在进行局部避让时较少考虑到目标导向的制约,未能较好地平衡航行经济性和安全性要求。
技术实现思路
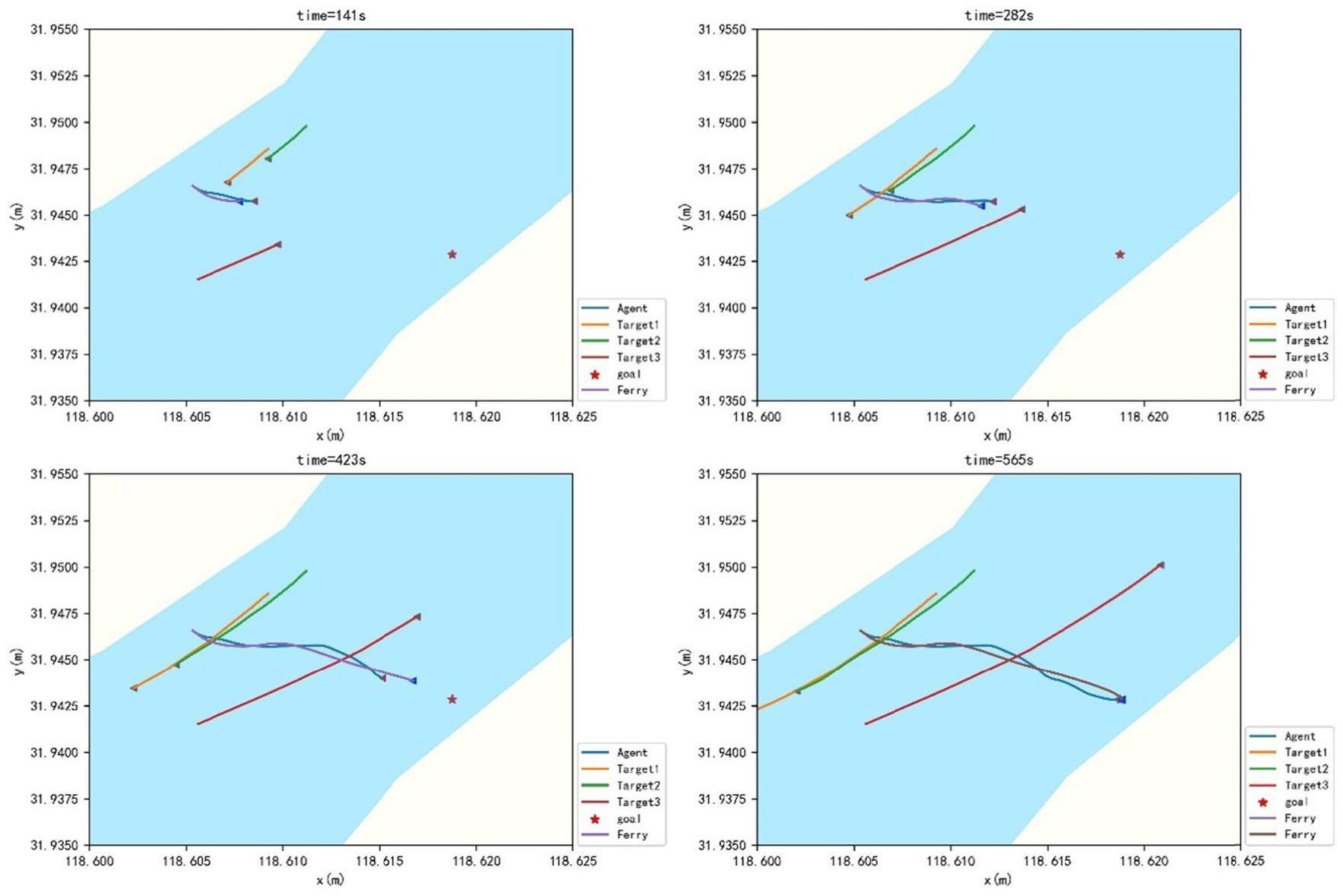
1、本发明要解决的技术问题在于,提供一种基于深度强化学习的渡船路径规划方法,其会遇量化方案,并融合历史航行经验进行穿越行为预测,使得规划的路径更加切合船员操作习惯。
2、本发明解决其技术问题所采用的技术方案是:构造一种基于深度强化学习的渡船路径规划方法,包括以下步骤:
3、s1、确定渡船航行规则:结合colregs和内河避碰规则,将渡船与目标船的会遇态势量化为穿越方式;
4、s2、划分碰撞风险:渡船的碰撞风险包括渡船和目标船舶之间的相对距离,渡船的相对距离和碰撞风险分为一级、二级和三级三个等级;
5、s3、构建基于dqn的路径规划:为渡船分别建立状态空间、行为空间、奖励函数和仿真实验,状态空间为一系列可用于路径规划的采集数据,动作空间为用作路径关键元素的操作相关参数,奖励函数包括经济性奖励函数和安全性奖励函数,仿真实验通过仿真实验对于项目进行可行性分析。
6、按上述方案,所述步骤s1中,渡船在河道中航行会遇其他船舶的类型包括交叉、追越和对遇三种情况;渡船的正常航行应遵循colregs以避让。
7、与普通船舶的正常航行相比,穿越河道是渡船的一种典型航行模式,它会产生与目标船舶的交叉会遇情况。因此,制定了内河避碰规则,以进一步描述渡船的责任。此外,渡船穿越河道时的穿越模式可划分为从目标船舶船艏与船艉穿越。与普通船舶相似当渡船穿越河道时也会产生四种会遇情况。按上述方案,所述步骤s2中,一级区域称为临界区域,一级区域由禁止穿越行为的船舶安全领域形成,不允许导致侵犯该区域的穿越行为;
8、二级区域为黄色区域,二级区域受一级和三级限制,航行员在二级区域采取穿越行为,当发生复杂的会遇情况时,渡船将根据奖励选择一系列令人满意的行为,以满足经济和安全要求,穿越行为在此区域内的相对距离将导致路径的二级碰撞风险;
9、三级区域为蓝色区域,目标船舶与渡船保持较远距离,进行交叉穿越非常耗时,不发生穿越行为。
10、按上述方案,所述步骤s3中,状态空间分为两部分:渡船和目标点之间的相对状态空间send,渡船和目标船之间的相对状态空间starget,send表示如下:
11、
12、xf、yf、vf、cf表示渡船的位置、速度和航向,xend、yend表示目标点的位置,starget表示如下:
13、
14、xt、yt、vt、ct表示目标船的位置、速度和航向,监测范围rpolicy,状态空间为:
15、
16、当发生会遇情况时,xgboost预测的穿越模式会集成到状态空间中,预测结果分为“1”和“0”;“1”表示从目标船船艏穿越,“0”表示从目标船船艉穿越;
17、当未出现会遇情况,将穿越模式调整为-1,以保持状态空间的结构不变;
18、态空间更新如下:
19、
20、p=[lonf,latf,vf,cf,lont,latt,vt,ct],
21、cp为渡船的穿越模式,com为布尔值,un为交叉会遇未结束,fn为交叉会遇己完成,dtf为渡船和目标船之间的相对距离;
22、渡船选择转向右舷、左舷或在避让期间保持渡船航线,动作空间离散化为三个离散值:
23、a=[-δc,0,δc] (5)
24、按上述方案,所述步骤s3中,经济性奖励确定更短的路径和更短的航行时间,当渡船在时间片t处比在时间片t-1处更接近终点时,则将生成正奖励;当渡船在时间片t处比在时间片t-1处更远离终点时,将获得负奖励,当渡船到达终点时,奖励为500。
25、
26、当渡船驶出范围时,奖励设置为:
27、
28、假设d′表示时间片t处渡船与目标点之间的距离,d表示时间片t-1处渡船与目标点之间的距离,则时间片t处的奖励表示为:
29、
30、通过使用衰减因子确保随着航行时间的增加,奖励减少,从而实现更短的航行时间,经济奖励表示为:
31、
32、当渡船接近终点时,将应用衰减因子;引入加权因素ω,整体经济性奖励列出如下:
33、
34、按上述方案,所述步骤s3中,安全性奖励中,假设表示时间切片t处渡船和目标船只之间的距离,表示时间片t-1处渡船和目标船只之间的距离,当则时间切片t处的奖励表示为:
35、
36、当渡船航行靠近时τrpolicy,经济权重设置为0,负奖励增加;如果奖励描述如下:
37、
38、当时,渡船正在驶向目标船只,引入加权因素ρ以增加负面奖励;当时,渡船试图远离目标船只,引入加权因子σ,当相对距离小于船舶安全领域,则奖励为-500,安全奖励函数如下式所示:
39、
40、实施本发明的基于深度强化学习的渡船路径规划方法,具有以下有益效果:
41、1、本发明针对交叉会遇场景,提出一种新的会遇量化方案,并融合历史航行经验进行穿越行为预测,使得规划的路径更加切合船员操作习惯;
42、2、本发明以经济性和安全性作为主要考量指标,构建自主航行路径规划系统,使得规划的路径能在满足安全要求的前提下,力求路径最短。
技术特征:
1.一种基于深度强化学习的渡船路径规划方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于深度强化学习的渡船路径规划方法,其特征在于,所述步骤s1中,渡船在河道中航行会遇船舶的类型包括交叉、追越和对遇三种情况;渡船的正常航行遵循colregs以避让。
3.根据权利要求1所述的基于深度强化学习的渡船路径规划方法,其特征在于,所述步骤s2中,一级区域称为临界区域,一级区域由禁止穿越行为的船舶安全领域形成,不允许导致侵犯该区域的穿越行为;
4.根据权利要求1所述的基于深度强化学习的渡船路径规划方法,其特征在于,所述步骤s3中,状态空间分为两部分:渡船和目标点之间的相对状态空间send,渡船和目标船之间的相对状态空间starget,send表示如下:
5.根据权利要求1所述的基于深度强化学习的渡船路径规划方法,其特征在于,所述步骤s3中,经济性奖励确定更短的路径和更短的航行时间,当渡船在时间片t处比在时间片t-1处更接近终点时,则将生成正奖励;当渡船在时间片t处比在时间片t-1处更远离终点时,将获得负奖励,当渡船到达终点时,奖励为500;
6.根据权利要求1所述的基于深度强化学习的渡船路径规划方法,其特征在于,所述步骤s3中,安全性奖励中,假设表示时间切片t处渡船和目标船只之间的距离,表示时间片t-1处渡船和目标船只之间的距离,当则时间切片t处的奖励表示为:
技术总结
本发明涉及一种基于深度强化学习的渡船路径规划方法,包括以下步骤:S1、确定渡船航行规则:针对狭窄水域渡船横越河道的特殊场景,结合COLREGs和内河避碰规则,将渡船与目标船的会遇态势量化为穿越方式;S2、划分碰撞风险:渡船的碰撞风险包括渡船和目标船舶之间的相对距离,渡船的相对距离和碰撞风险分为一级、二级和三级三个等级;S3、构建基于DQN的路径规划:为渡船分别建立状态空间、行为空间、奖励函数和仿真实验,状态空间为一系列可用于路径规划的采集数据,动作空间为用作路径关键元素的操作相关参数。本发明以经济性和安全性作为主要考量指标,构建自主航行路径规划系统,使得规划的路径能在满足安全要求的前提下,力求路径最短。
技术研发人员:袁晓丽,袁承基,刘干,张金奋,刘炯炯
受保护的技术使用者:武汉理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!