一种基于强化学习的无人机编队路径规划方法
本发明属于无人机编队路径规划,具体涉及一种基于强化学习的无人机编队路径规划方法。
背景技术:
1、无人机在近些年来被广泛应用于各行各业,单台无人机具备较高的操作性和便捷性,但是也存在着有效载荷能力受限、抗干扰能力弱等突出缺点。其无法适用于复杂任务,在任务执行过程中,若无人机发生故障,则宣布任务的失败。为此,无人机编队的全新架构被逐步运用于任务执行中。依靠无人机编队的集群优势,无人机编队在任务执行中实现功能的互补和能力的叠加,可以显著提高任务的成功率。
2、在无人机编队的任务执行中,路径规划和编队控制是其中重要的研究内容。已有的编队协同控制方法主要是分层控制的方式,其主要思想是将问题分为上中下三层,上层进行决策,中层传递指令,下层执行任务,从而将问题进行降维处理,简化求解空间。大多数学者运用仿生学方法如遗传算法、模拟退火算法、蚁群优化算法等进行编队问题求解。这类算法虽然求解快速有效,但是其依赖于提前获取环境信息,面对不断变化的动态环境则无能为力。近年来多智能体强化学习(multi-agent reinforcement learning,marl)给编队协同控制提供了新的思路,将无人机编队问题建模为马尔科夫决策过程(markov decisionprocess,mdp),各无人机自主与环境交互学习经验,通过环境给予的奖惩调整各自的行为,达到协同控制的目的。
3、liu等人将长机-僚机法引入到了编队控制中,运用离线的强化学习方法进行训练,实现了五台无人机的编队控制和路径规划问题,但是仅仅考虑了无障碍物环境的情形。pan等人将分布式的编队控制方法与基于模型的强化学习方法结合,解决了一字型编队在复杂环境中的避障问题,但是未考虑其它更复杂的编队结构。
4、现有编队控制方法,发现其存在以下问题:
5、1.现有方法一般将编队控制问题分解为编队保持和编队调整,然后分别采用不同的方法进行处理,这会使得算法复杂度过高,不利于算法快速收敛。
6、2.现有方法非常依赖于先验环境,同时对环境和编队的各自情况考虑得比较简单,无法对环境中的突发威胁及时进行规避,算法的泛化能力有限。
技术实现思路
1、为了克服上述现有技术存在的不足,本发明的目的在于提供一种基于强化学习的无人机编队路径规划方法,通过设置动态障碍物,能够增强系统抵抗突发威胁的能力,通过设置动态编队奖励函数,实现了编队结构的稳定性和队形变换自主性。
2、为了实现上述目的,本发明采用的技术方案是:
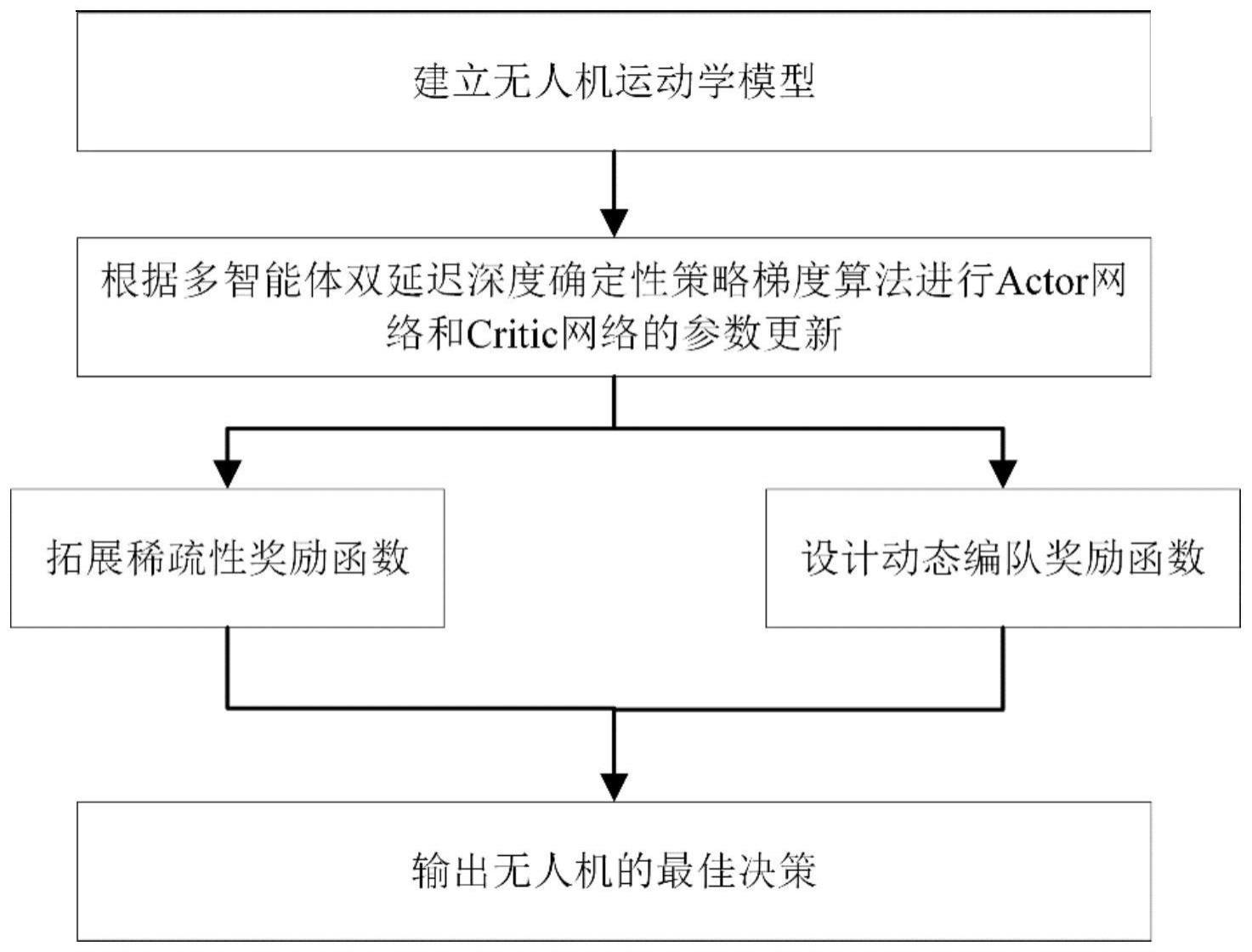
3、一种基于强化学习的无人机编队路径规划方法,包括以下步骤;
4、步骤s1:根据无人机的运动学方程和状态转移方程建立无人机的运动学模型,更新无人机的运动状态,所述无人机的运动状态包括状态空间和动作空间;
5、步骤s2:将步骤s1获得的状态空间的状态参数和动作空间的运动参数代入actor-critic网络模型,根据多智能体双延迟深度确定性策略梯度算法对actor网络和critic网络进行参数更新,得到actor-critic网络参数;
6、步骤s3:将步骤s2获得的actor-critic网络参数代入根据奖励函数,获得奖励值;
7、步骤s4:actor网络和critic网络循环计算,直至奖励值收敛,根据无人机的状态得到需要执行的动作参数。
8、所述s1中,所述无人机的状态空间的状态参数包括无人机的横坐标、纵坐标、飞行角度、速度;
9、无人机的动作空间的运动参数包括无人机的角速度和加速度。
10、所述步骤s1中中,根据无人机的运动学方程和状态转移方程,获得第i台无人机t+1时刻的运动状态空间;所述步骤s1中的无人机运动学方程如下:
11、
12、无人机的状态转移方程如下:
13、
14、其中,xi表示为各台无人机的横坐标、yi表示各台无人机的纵坐标、ψi表示各台无人机的飞行角度、vi表示各台无人机的速度、ωi表示各台无人机的角速度、ai表示各台无人机的加速度。
15、所述步骤s2中,采用多智能体双延迟深度确定性策略梯度算法进行参数更新,actor网络输入无人机的自身状态信息,输出无人机执行的动作,critic网络输入所有无人机的状态和动作,输出评估q值,critic网络有1个输入层,3个隐藏层,1个输出层。
16、所述输入层输入无人机的状态信息和当前执行的动作;第一个隐藏层为全连接层,有32个神经元,激活函数为relu;第二个隐藏层为全连接层,有32个神经元,激活函数为relu;第三个隐藏层为全连接层,有1个神经元;输出层为全连接层,有1个神经元,用于输出对应的q(s,a)作为动作评价;各台无人机每次进行状态转移的数据存储进缓存池中,每次批量获取数据输入进网络中进行参数更新,网络训练收敛之后,输出各台无人机的策略集合。所述步骤s2中,多智能体双延迟深度确定性策略梯度算法采用集中式训练、分布式执行的架构;
17、对actor网络输入无人机的自身状态信息,所述无人机的自身状态信息包括无人机当前的位置坐标和状态参数,输出无人机所执行的动作,根据梯度上升法进行参数更新,其所依据的梯度计算公式如下:
18、
19、其中,θi代表其网络参数,l代表损失函数,n代表数据量大小,q代表无人机的q值,o代表各台无人机的状态,a代表无人机的动作,wi,j代表q网络参数,μ代表动作策略;
20、对critic网络输入所有无人机的状态和动作,所述无人机的状态和动作包括所有无人机当前的位置坐标、状态参数以及执行的动作参数,输出评估q值,根据梯度下降法进行参数更新,其损失函数计算公式如下:
21、
22、其中,wi,j代表其网络参数,l代表损失函数,n代表数据量大小,q代表无人机的q值,o代表各台无人机的状态,a代表无人机的动作。
23、所述步骤s3中各台无人机所依据的奖励函数如下:
24、ri=α1r1+α2r2+α3r3+α4r4+α5r5+α6r6+α7r7
25、其中,α1、α2、α3、α4、α5、α6、α7为加权系数,r1、r2、r6为稀疏性奖励,触发稀疏性奖励时无人机会结束本回合训练,r3、r4、r5、r7为引导性奖励,每次状态转移都会获得引导性奖励;
26、无人机若抵达目的地,获得环境给予的奖励值r1,其定义如下:
27、
28、其中,δd代表无人机与目的地之间的欧式距离,d1为距离阈值,δθ为无人机飞行角度和无人机与目的地所成角度的差值;
29、无人机在运动过程中如果与障碍物或者边界撞击,则获得负向奖励r2,其定义如下:
30、r2=-10
31、无人机每走一步就获得一个负向奖励r3,模拟无人机行驶过程中所消耗的能量:
32、r3=-1
33、对于复合障碍物环境,因为需要避开障碍物,所以无人机的运动轨迹一般不是直线,即理解为当无人机与目的地连线中间存在障碍物时,无人机的飞行方向和无人机与终点连线需要存在一定夹角,通过分类讨论无人机、障碍物、目的地的相对位置关系,确定无人机的最佳飞行角度如下:
34、θbest=θl±θε
35、其中,θbest为无人机的最佳飞行角,θl为无人机沿障碍物切线方向的角度,θε为偏离切线的角度值;
36、为此,根据无人机的当前飞行角度和最佳飞行角度确定奖励r4的定义如下:
37、
38、在无人机避障过程中,无人机可能短暂远离终点,为了加快算法收敛速度,这种情况是可以容忍的,为此提出针对距离目的地远近程度的奖励函数:
39、
40、无人机之间发生碰撞产生的负向奖励r6定义如下:
41、
42、稳定的编队结构意味着每两台无人机之间的间距都保持稳定,为此依据每两台无人机之间最优间距和当前间距设计奖励函数,能够保证编队在无障碍物时保持稳定,而在碰到障碍物时进行队形微调;深入分析其意味着每两台无人机之间的距离稳定在一个合理的值附近;为此,以距离为突破口,设置一条关于无人机i和无人机j之间实际距离与最优距离的奖励函数如下:
43、
44、其中,di(j)为无人机i与无人机j的实际距离,dopt,ij为无人机i与无人机j之间的最优距离。所述奖励值与di(j)/dopt,ij呈二次函数关系,当di(j)/dopt,ij为1时,二次函数取得最大值1,即无人机i与无人机j的实际距离和最优距离相等时,奖励值最大为1;di(j)/dopt,ij与1偏离越远,即无人机i与无人机j的实际距离与最优距离偏离越远,奖励值越小,符合本设计奖励函数的初衷。所述步骤s4中,各台无人机根据下式输出动作at:
45、at=μ(ot;θi)
46、其中,at为t时刻执行的动作,ot为t时刻状态,μ为策略函数,θi为策略网络的参数;
47、critic网络参数θ的梯度运用梯度下降法进行θ参数更新,运用梯度上升法进行actor网络参数φ更新;根据奖励值函数计算q值,并与上一轮q值进行比较,若误差在收敛范围内,模型收敛结束计算,反之继续进行循环计算直至q值收敛。
48、本发明的有益效果:
49、本发明具备对环境中的突发威胁进行应对的能力。同时本发明针对编队结构稳定性和队形变换自主性问题,设计了动态编队奖励函数,提升了编队的协同能力。
50、本发明由于采用了动态障碍物环境,因此增强了系统抵抗突发威胁的能力。
51、本发明由于拓展了稀疏性奖励函数,因此解决了编队内部避碰问题。
52、本发明由于采用了动态编队奖励函数,因此同时实现了编队结构稳定性和队形变换自主性。
- 还没有人留言评论。精彩留言会获得点赞!