基于强化学习的自适应多无人艇追逃博弈方法及系统
本发明总的来说涉及无人艇。具体而言,本发明涉及一种基于强化学习的自适应多无人艇追逃博弈方法及系统。
背景技术:
1、近年来,随着陆地燃料资源的枯竭,占据地球面积约71%的海洋战略地位随之不断提高。为充分勘探和开采海洋资源,海洋装备技术的发展不可或缺。以无人艇(包括水下航行体、水下机器人、水面无人船等)为代表的海洋智能装备是现阶段海上作业的主要载体。
2、集群无人舰艇是指一组编队的多个无人舰艇。近年来,集群无人舰艇的应用日益增长,目前,集群无人艇已经在诸如围捕、驱离、扫雷、反潜之类的军事领域以及诸如物资补给、地形测绘、海面营救、无人搜索之类的民事领域发挥重要作用。
3、然而目前的基于强化学习的无人艇追逃博弈控制方法仍存在下列问题:
4、无人艇数量是固定的,无法根据环境情况、任务变更需求等对无人艇的数量进行动态扩展。此外,当发生故障或意外情况使得某一个或多个无人艇不能继续参加追击以及围捕任务时,目前算法的成功率会大大降低。
5、难以处理不等长的输入维度。当无人艇的局部观测,如障碍物、其它无人艇的数量不断变化时,则无人艇的局部观测其维度也是不断变化的,而常规的强化学习通常需要固定维度的输入。此外,同一任务内的不同时刻,可能需要控制不同数量的无人艇行动,而常规的用于单智能体或多智能体的强化学习算法的输出维度固定,难以处理此类场景。
6、现有的用于追逃博弈的强化学习算法为了保证智能体之间的有效合作,通常使用多智能体强化学习算法,而多智能体强化学习算法存在训练困难、难收敛、计算开销大的问题。并且多智能体强化学习算法很容易使追击无人艇在理想包围圈内外反复波动,在包围的平稳性上欠缺。
技术实现思路
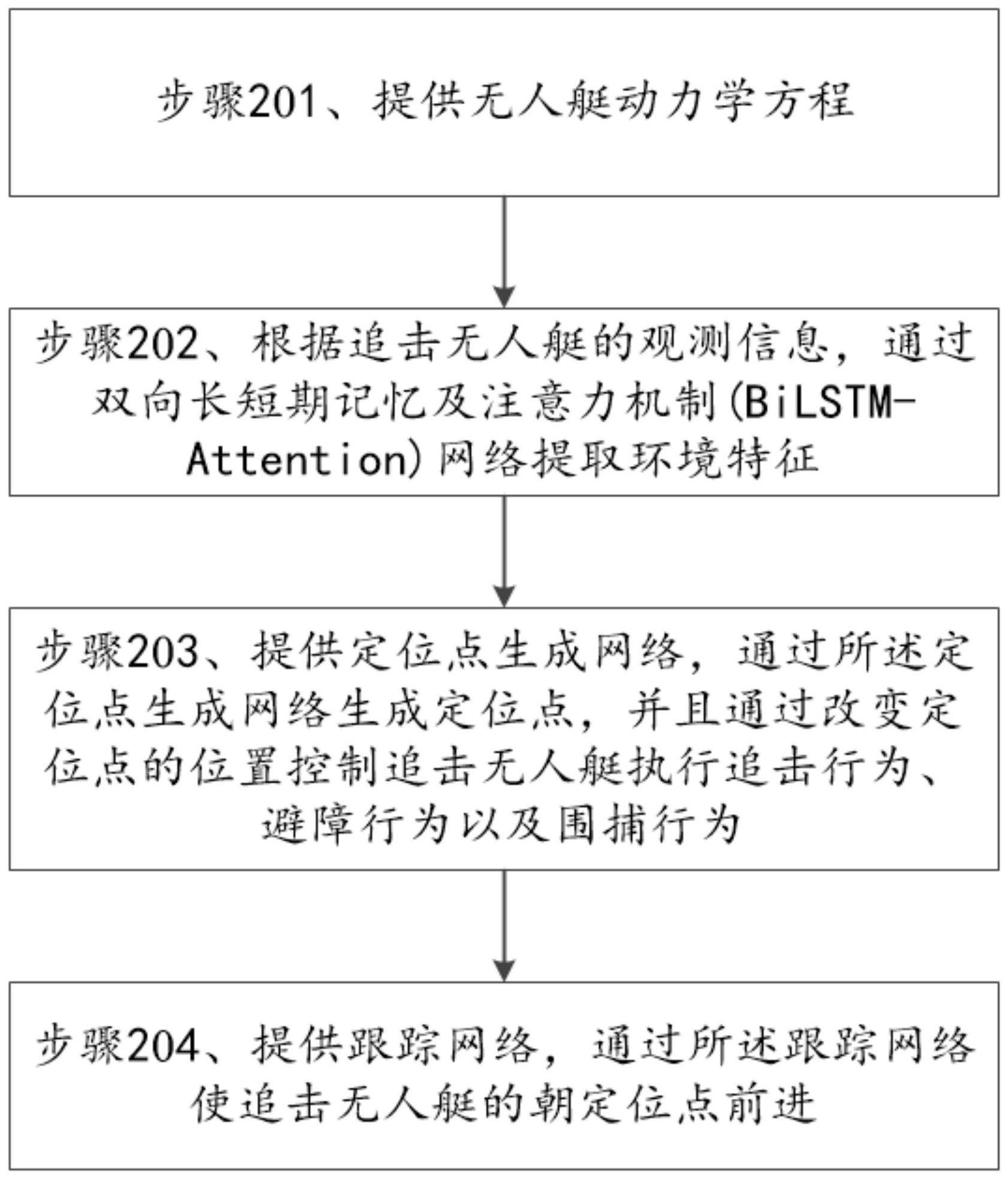
1、为至少部分解决现有技术中的上述问题,本发明提出一种基于强化学习的自适应多无人艇追逃博弈方法,包括下列步骤:
2、提供无人艇动力学方程;
3、根据追击无人艇的观测信息,通过双向长短期记忆及注意力机制(bilstm-attention)网络提取环境特征;
4、提供定位点生成网络,通过所述定位点生成网络生成定位点,并且通过改变定位点的位置控制追击无人艇执行追击行为、避障行为以及围捕行为;以及
5、提供跟踪网络,通过所述跟踪网络使追击无人艇朝定位点前进。
6、在本发明一个实施例中规定,提供无人艇动力学方程包括:
7、以(x,y)表示无人艇的位置、ψ表示偏航角、v表示速度矢量,其中速度矢量v包括浪涌速度u、摇摆速度υ以及船体坐标上的偏航角速度r;
8、以τ=[τu,0,τr]t表示控制输入,以d=[d1,d2,d3]t表示来自各个方向的未知扰动;
9、确定旋转矩阵r(ψ),表示为下式:
10、
11、确定惯性矩阵m,表示为下式:
12、
13、其中,xu,yv,yr,zv,zr以及表示机动系数;
14、确定科里奥利-向心矩阵c(v)以及阻尼矩阵d(v),表示为下式:
15、
16、
17、其中,x|u|u,y|v|v,y|v|r,z|v|v以及z|v|r表示流体动力学系数;以及
18、确定无人艇动力学方程,表示为下式:
19、
20、其中η=[x,y,ψ]t,v=[u,υ,r]t。
21、在本发明一个实施例中规定,根据追击无人艇的观测信息,通过双向长短期记忆及注意力机制网络提取环境特征包括:
22、将追击无人艇的可观测范围表示为dobs,将第i个追击无人艇的状态信息表示为将第i个追击无人艇的位置表示为pi=[xi,yi]t;
23、将第i个追击无人艇观测到的其他追击无人艇状态信息表示为其中
24、将第i个追击无人艇的观测范围内的障碍物的状态信息表示为其中表示障碍物的位置;
25、将第i个追击无人艇观测到的其他追击无人艇状态信息以及障碍物的状态信息输入双向长短期记忆及注意力机制网络,输入信息表示为下式:
26、以及
27、由双向长短期记忆及注意力机制网络提取追击无人艇探测范围内的环境状态信息,其中第i个追击无人艇探测范围内的环境状态信息表示为下式:
28、在本发明一个实施例中规定,提供定位点生成网络,通过所述定位点生成网络生成定位点包括:
29、提供定位点生成网络,根据所述环境特征基于强化学习确定追击无人艇的动作信息;以及
30、根据所述无人艇动力学方程,基于追击无人艇的位置、逃逸无人艇的位置以及所述追击无人艇的动作信息确定追击者无人艇的定位点。
31、在本发明一个实施例中规定,提供定位点生成网络,根据所述环境特征基于强化学习确定追击无人艇的动作信息包括:
32、确定第i个追击无人艇与在其观测范围内的第j个障碍物、第j个无人艇之间的距离以及表示为下式:
33、
34、构造定位点生成网络在t时刻的即时奖励函数表示为下式:
35、
36、其中,oi和ui分别表示在无人艇i观测范围dobs内观测到的障碍物集合以及其它无人艇集合,a1,a2,k1,k2,k3,κ1,κ2表示调节奖励分布的超参数,δθi表示角度偏移量的惩罚项;
37、根据所述即时奖励函数确定折扣回报gt,表示为下式:
38、
39、其中,γ表示折扣系数;
40、以所述环境状态信息表示第i个追击无人艇的状态,以角度偏移量以及偏移权重ωi表示第i个追击无人艇的动作,并且以将定位点生成网络的策略表示为π;
41、将第i个追击无人艇的动作价值函数q-value,状态价值函数v-value,以及优势函数表示为下式:
42、
43、
44、
45、根据所述即时奖励函数、所述环境状态信息角度偏移量以及偏移权重ωi,通过近端策略优化(pp0,proximal policy optimization)强化学习算法,对策略网络(actor)以及价值网络(critic)进行拟合,其中所述环境状态信息是所述策略网络以及价值网络中的共用向量;以及
46、通过所述策略网络生成第i个追击无人艇的最优动作,所述最优动作包括最优角度偏移量δθi和最优定位权重ωi。
47、在本发明一个实施例中规定,根据所述无人艇动力学方程,基于追击无人艇的位置、逃逸无人艇的位置以及所述追击无人艇的动作信息确定追击者无人艇的定位点包括:
48、根据所述无人艇动力学方程,将第i个追击无人艇的位置表示为pi=[xi,yi],将逃逸无人艇的位置表示为pe=[ex,ey],将追击无人艇的观测范围表示为dobs、围捕半径表示为dr;
49、确定定位角度θi,其表示第i个追击无人艇i以及逃逸无人艇之间的连线与x轴正方向的夹角,表示为下式:
50、
51、
52、其中,μ表示围捕时的旋转角速度;
53、确定以逃逸无人艇当前位置pe为圆心、以包围半径dr为半径的第一圆,并且确定以逃逸无人艇当前位置pe为圆心、以||pi-pe||2为半径的第二圆;
54、根据所述角度偏移量δθi以及定位权重ωi,沿角度θi+δθi的方向与一圆以及第二圆相交于以及表示为下式:
55、
56、
57、其中,αi和βi用于产生定位向量;
58、将从第i个追击无人艇的位置pi指向αi和βi的向量分别表示为下式:
59、
60、
61、其中,表示用于驱使追击无人艇达到目标点的目标导向需求向量,表示用于避障需求的向量。
62、根据目标导向需求向量避障需求向量以及定位权重ωi确定第i个追击无人艇的定位向量表示为下式:
63、以及
64、确定第i个追击无人艇的定位点向量表示为下式:
65、
66、
67、其中,dms表示定位点的约束半径,定位点向量的起点是第i个追击无人艇的当前位置pi,当时,定位点是定位点向量与圆心为pi,半径为dms的第三圆的交点,否则定位点是定位点向量的终点。
68、在本发明一个实施例中规定,提供跟踪网络包括:
69、根据所述最优角度偏移δθi以及最优定位权重ωi,更新第i个追击无人艇的定位角度θi=θi+δθi,并且更新定位点向量
70、在t时刻,以第i个追击无人艇的状态信息以及定位点的状态信息作为跟踪网络的输入,表示为下式:
71、由跟踪网络输出第i个追击无人艇的控制信息以及
72、根据跟踪网络输出的控制信息以及定位点生成网络输出的角度偏移量δθi,更新第i个追击无人艇的状态信息以及定位点的位置信息,表示为下式:
73、将跟踪网络表示为nnpos,将跟踪网络的权重为wp,将跟踪网络的损失函数表示为下式:
74、
75、通过反向传播更新跟踪网络的参数,表示为下式:
76、
77、其中,α表示学习率;以及
78、重复上述步骤直至跟踪网络的损失收敛至预设阈值th。
79、本发明还提出一种基于强化学习的自适应多无人艇追逃博弈系统,包括:
80、追击无人艇;
81、逃逸无人艇;
82、动力学模块,其被配置为提供无人艇动力学方程;
83、环境特征提取模块,其被配置为根据追击无人艇的观测信息,通过双向长短期记忆及注意力机制网络提取环境特征;
84、定位点生成网络,其被配置为生成定位点,并且通过改变定位点的位置控制追击无人艇执行追击行为、避障行为以及围捕行为;以及
85、跟踪网络,其被配置为使追击无人艇朝定位点前进。
86、本发明还提出一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序在被处理器执行时执行根据所述方法的步骤。
87、本发明还提出一种计算机系统,包括:
88、处理器,其被配置为执行机器可执行指令;以及
89、存储器,其上存储有机器可执行指令,所述机器可执行指令在被处理器执行时执行根据所述方法的步骤。
90、本发明至少具有如下有益效果:本发明在使用强化学习算法进行追逃博弈时,可以用于无人艇局部观测内有不定数量障碍物的避障、追击者数量动态变化的情况。
91、本发明将无人艇追逃任务分解成定位点生成任务和跟踪任务。通过任务分解的方式克服多无人艇之间的强合作需求,并能达到合作的效果,从而应对单智能体强化学习算法在合作性能上的缺陷,将其有效应用于多无人艇合作问题。并且这种方式相对于常规强化学习算法,具有较小的计算开销。
92、并且本发明中无人艇数量可增减,对于多无人艇追逃博弈,使用单智能体算法完成多无人艇合作任务,为每个无人艇配备相同参数的神经网络以加快训练。由于每艘无人艇配备独立的决策网络,因此在追逃博弈任务过程中,可以克服常规算法需要固定无人艇数量的局限,追击无人艇可根据实际情况进行追击数量自适应。
93、并且本发明能够处理不等长的输入维度,可以有效应对非完整信息,如局部观测下所观测到的其它无人艇、障碍物数量不一致问题,能够有效提取无人艇观测范围内的环境特征并合理做出决策。
94、此外本发明具有较高的包围平稳,其中定位点的生成是通过定位点生成网络输出的角度偏移量和权重,然后经过向量合成的方式产生的,避免了直接通过神经网络输出定位点带来的波动性,向量合成的方式能够保证定位点始终在以逃逸者为中心的包围圈上,具有较高的包围平稳性。
- 还没有人留言评论。精彩留言会获得点赞!