一种基于深度强化学习的陀螺减摇装置的控制方法
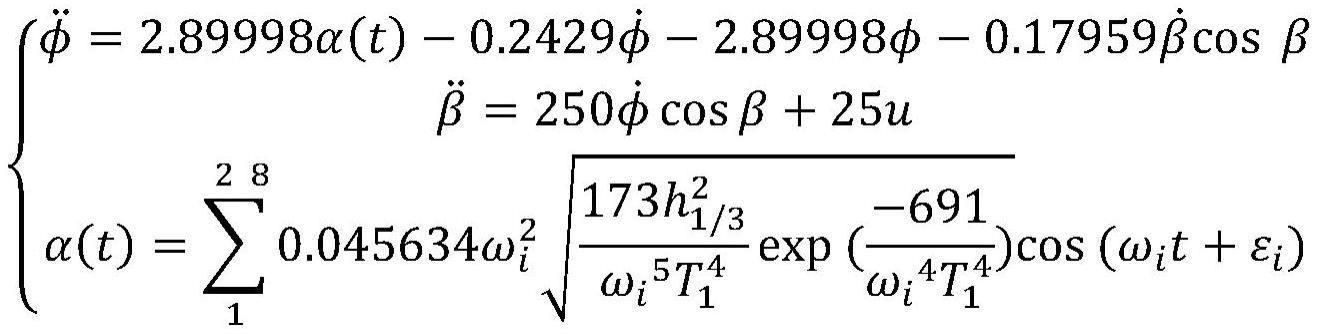
本发明属于船舶减摇装备的智能控制领域,具体地涉及一种基于深度强化学习方法的船舶陀螺减摇装置的控制方法。
背景技术:
1、目前主动式船舶陀螺减摇装置主要采用传统的控制方式,如复合pid、滑模控制等控制方法。然而研究陀螺减摇装置、船舶、海浪三者的联合数学模型发现该模型是一个非线性的复杂系统,且由于海浪的激励是平稳随机的导致系统有很强的随机性,因而当船舶遇到稍大的海浪时陀螺减摇装置的效果便不理想。
2、如复合pid控制器通过比例系数,微分系数以及船舶的横摇姿态,陀螺的进动姿态组成的计算式来就算陀螺的控制量,但由于海浪具有较大的随机性海浪时而大时而小为了保证陀螺在大海浪和小海浪时都具有减摇效果,控制器的各参数往往设置的较为保守,因此导致了在海浪较大时减摇的效果较差。
3、青岛科技大学公开一种船舶力矩陀螺减摇装置的减摇方法(cn103818524a,公开日:2014年05月28日),陀螺由两个磁悬浮轴承支撑在内框上,陀螺进动速率直接反映出船身横摇状况,通过传感器检测到内框的进动速率后,实时反馈到控制器,控制器对阻尼器及伺服电机工作进行控制,通过调节阻尼器输出的阻尼力的大小或者调节伺服电机转速米调节进动速度,实现所需的陀螺力矩,进而实现减轻横摇的目的。如上所述,陀螺进动速率本身设置的比较保守,导致在海浪较大时减摇效果也较差。
技术实现思路
1、为了解决现有的主动式陀螺减摇装置控制效果不理想,在较大海浪时控制效果显著下降的导致陀螺减摇装置的减摇效果差的问题,提出了陀螺减摇装置、船舶、海浪三者的联合数学模型以及深度强化学习方法,基于深度强化学习技术发明了一种能够有效用与陀螺减摇装置的控制方法。
2、本发明的技术方案如下:
3、一种基于深度强化学习的陀螺减摇装置的控制方法,其特征在于:该方法包括以下步骤:
4、步骤1:分析陀螺减摇装置工作时系统的运动特性,在计算机中搭建出陀螺-船舶-海浪三者联合虚拟仿真环境,在方法训练时与智能体进行交互。
5、步骤2:设计奖励函数用于评估智能体所作出的决策的优劣。
6、步骤3:设计智能体结构,智能体包含两个actor网络两个critic网络,设计四个神经网络的结构,设置方法的所有需要设置的参数,如学习率,裁剪率,衰减率,折扣因子,,并初始化4个神经网络。
7、步骤4:让智能体与虚拟仿真环境进行连续交互,得到一系列数据。
8、步骤5:步骤2中的奖励函数依据步骤4所得数据为智能体行为打分,根据该分数以及智能体的critic网络计算出智能体与环境每一次交互的优势函数值。
9、步骤6:根据步骤5所得的智能体行为的分数和优势函数值分别构造出适用的actor和critic网络的损失函数值,然后根据梯度优化的思想根据损失函数值优化actor网络的参数θ与critic网络的参数值
10、步骤7:重复步骤4-6,直至智能体中的actor网络的参数θ与critic网络的参数值均收敛为止。
11、步骤8:将收敛的智能体中的actor网络部署到陀螺减摇装置的控制系统中实现对陀螺减摇装置的控制。
12、具体地,按照步骤1所述的分析陀螺减摇装置安装在船舶上并遭遇海浪时的运动状态。在保证系统准确性的前提下为了减小仿真过程的计算量,缩短方法的训练时间对数学模型进行简化,最终建立三者的联合动力学模型如下:
13、
14、其中t为船舶排水量,h为船舶横稳心高,is为船舶沿横摇轴的转动惯性矩,α(t)为海浪激励的波倾角函数,nu为水面阻尼系数,h0为陀螺转子的角动量,j为陀螺转子沿进动轴的转动惯性矩,φ为船舶横摇角度,β为陀螺进动角度,u为陀螺进动控制力矩即为控制量。开发程序以系统当前状态φk、βk、以及控制量uk作为输入,系统的下一个状态φk+1、βk+1、作为输出。
15、按照步骤2所述的设计奖励函数,奖励函数以船舶的横摇角度φ,陀螺的进动角度β为评价指标。奖励函数采用分段函数的形式在保证方法能够收敛的前提下提高方法的控制效果。奖励函数如下:
16、
17、
18、r=rφ+rβ
19、其中φ1,φ2,β1,β2,β3是根据船舶和陀螺减摇装置的规格选取的横摇角和进动角的分界值,要求0<φ1<φ2<0.55rad,
20、按照步骤3所述智能体共包含4个线性全连接神经网络,分别是actor,actor′,critic,critic′。它们所对应的参数集(包括权值和偏置值)分别为:θ,θ′,其中actor与critic是实际要更新的神经网络,actor′和critic′是实际与环境交互的神经网络。actor′和critic′的参数值每完成1轮训练就从actor与critic中拷贝过来一次。其中actor神经网络结构为线性全连接多层神经网络,输入层的5个输入参数分别为船舶横摇角度φk、船舶横摇角速度陀螺进动角度βk、陀螺进动角速度上一控制周期海浪激励的估计值αk-1,记为sk。中间层有若干层线性神经网络,输出层输出2个值分别为正态分布的均值μ和标准差σ,激活函数分别为tanh和softplus,用均值和标准差构造正态分布依据概率输出的值即为陀螺减摇装置进动轴的控制力矩u。
21、
22、critic网络输入层的输入参数与actor网络一致,中间层为若干层线性神经网络,输出层输出的是当前状态sk的值函数的估计值。
23、按照步骤4所述智能体与环境交互的过程为初始化环境,获取环境的初始状态初始α-1=0,5个参数输入actor′网络,依据输出值构建正态分布依据概率随机输出陀螺进动控制力矩u0,然后输入到环境当中返回一组新的状态然后按照权利要求3所述奖励函数为当前交互结果打分得r0,根据和u0估算得到α0,然后将记为s1输入actor′得到u1。循环操作将会得到一个数据序列(此过程称为1轮交互过程):(s0,u0,r0,s1)、(s1,u1,r1,s2)…(sn,un,rn,sn+1),n为此轮交互的次数,其中每轮交互的次数取决于设定值n或者当船舶横摇角φ、陀螺进动角β超出范围时提前终止此轮交互。每次环境初始化时将会重新构造一个与之前不同的随机海浪激励,以防止神经网络过拟合以及提高控制器的鲁棒性。同时为了保证优势函数值的准确计算,以及actor网络损失函数的准确计算,n>2000数值越大越好,但是数值越大训练所需时间越长。
24、按照步骤5所述依据步骤4所得的数据序列:(s0,u0,r0,s1)、(s1,u1,r1,s2)…(sn,un,rn,sn+1)计算每一次与环境交互的优势函数值ak:
25、
26、ak=advk+γλak+1=advk+γλ(advk+1+γλ(advk+2+γλ(advk+3+…)))
27、其中γ为折扣因子,λ为衰减率,表示将sk带入网络计算得到的值函数的估计值。
28、按照步骤6所述将所得(a0,a1,a2,…,an)用于构造actor网络的损失函数:
29、
30、注:uk表示根据当前sk所做出的动作,即输出的进动轴控制力矩因此同uk。
31、其中n≥2000,ε为裁剪函数的裁剪率。损失函数的含义是当船舶和陀螺减摇装置的状态在sk的情况下执行动作ak即陀螺进动轴控制力矩为uk时的优势函数值ak的期望值。我们的目标是使优势函数值期望越大越好,因此根据梯度上升的思想用下式更新θ:
32、
33、μa为actor网络的学习率
34、为了保证优势函数计算的准确性还需要不断的优化critic网络,构造critic网络的损失函数:
35、
36、当该损失函数值最小时critic网络输出的值函数的估计值越接近值函数的真实值,则此时优势函数值ak的计算越准确,保证了actor网络参数θ梯度优化的有效性。因此根据梯度下降的思想critic网络的参数的更新为:
37、
38、μc为critic网络的学习率
39、由于actor网络的损失函数应用了重要性采用方法,因此步骤4中所述的1轮交互中获取的数据序列:(s0,u0,r0,s1)、(s1,u1,r1,s2)…(sn,un,rn,sn+1)可多次用于优化actor网络的参数θ,提高训练效率及方法稳定性,即多次重复步骤6过程。一轮步骤4所述过程加上多次步骤5、6所述过程,后将actor网络和critic网络参数全部拷贝到actor′网络和critic′网络。上述1轮交互过程、多次优化过程、1次拷贝过程即为1轮训练。
40、7.按照步骤7所述,重复步骤4-6,即进行多轮训练直至智能体中的actor网络的参数θ与critic网络的参数值均收敛为止。重复步骤4-6的过程中要根据每1轮智能体与环境交互所得的总得分r=r1+r2+…+rn,的值来降低神经网络的学习率μa和μc,防止过拟合。
41、8.按照步骤8所述,将步骤7所得的actor神经网络部署到陀螺减摇装置的控制系统中。actor的输入层为5个参数,陀螺减摇装置通过电子陀螺仪检测船舶横摇角度φk、船舶横摇角速度利用编码器检测陀螺进动角度βk,并根据采样频率解算出陀螺的进动角速度利用上一个控制周期的状态φk-1、βk-1、和上一个控制周期的进动控制力矩uk-1以及当前状态估算得到上一控制周期海浪激励的估计值α′k-1,将5个参数作为actor网络的输入参数,经过actor网络的正向传播输出2个参数为正态分布的均值μ和标准差σ,然后构建正态分布依据该正态分布随机取值得到陀螺减摇装置的进动控制力矩uk,然后控制系统控制陀螺减摇装置的进动伺服电机在力矩输出的模式下输出大小为uk的力矩,作用在进动轴上,完成当前控制周期的控制。不断重复上述过程即为陀螺减摇装置的控制过程。
42、本发明基于深度强化学习方法的船舶陀螺减摇装置的控制方法,采用上述技术方案带来的有益效果有:
43、(1)使用了该控制方法的陀螺减摇装置具有更好的减摇效果,特别是在海浪激励较大的时候,减摇效果仍能保持着一个较好的水平。
44、(2)使用了该控制方法的控制系统具有较强的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!