一种稳流仓仓重模糊控制方法与流程
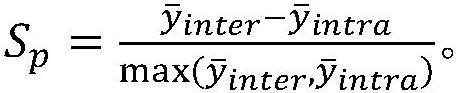
本发明涉及工业过程控制领域,具体涉及一种稳流仓仓重模糊控制方法。
背景技术:
1、稳流仓是一个储存熟料粉磨产品的设备,主要为了保证连续生产和改善生产制度。它的主要功能是缓冲和均衡熟料粉磨系统的物料流量,以稳定后续设备的运行。水泥熟料粉磨中的稳流仓控制主要是对稳流仓内物料量的控制,以保证稳定的物料流入生产线,从而提高生产效率与产品质量。如果稳流仓的控制不准确,可能会导致物料流量的波动,进而影响后续设备的正常运行,甚至可能引发生产线的停产。
2、现有的水泥熟料粉磨中的稳流仓控制方法主要采用pid控制法。pid控制器通过在稳流仓出料处设置的称重传感器实时检测料浆量,将检测值与设定值比较得到误差,然后将该误差按一定比例关系进行pid运算,综合计算出对喂入稳流仓料浆量的控制量,通过调节喂入量使稳流仓内料浆量稳定在设定点附近,以实现对稳流仓的闭环控制和稳定料浆量的自动调节。
3、然而,pid控制器中包含对应当前误差、误差积分、误差变化率三个部分。这三个部分的权重需要根据实际控制场景经验确定。不同料浆情况下,需要重新校准这三个部分的权重参数,否则难以达到良好控制效果。这是因为三个部分各自反映误差的不同特性,其权重需要针对具体被控对象设定。
4、而且,pid控制属于线性控制方法,其控制输出和误差之间假设为线性关系。但稳流仓控制是一个复杂的非线性过程,难以用线性模型准确描述。这会导致在不同工况下,pid控制器无法满足稳流仓控制的需求。
技术实现思路
1、为解决上述问题,本发明提供一种稳流仓仓重模糊控制方法。
2、该方法包括:
3、步骤一,准备输入数据集d,d={e1,…,ep,…,eq},p∈[1,q],其中,第p个仓储喂料数据ep={gep,gecp,qep},将q为d中样本数量,gep代表第p个仓重偏差,gecp代表第p个偏差变化率,qep代表第p个喂料量增量;
4、步骤二,计算输入数据集d的最优仓储喂料数据划分粒度;
5、步骤三,基于输入数据集d的最优仓储喂料数据划分粒度更新聚类中心;
6、步骤四,定义仓重偏差的聚类中心、偏差变化率的聚类中心、喂料量增量的聚类中心,仓重偏差的密度半径、偏差变化率的密度半径以及喂料量增量的密度半径;
7、步骤五,初始化仓重偏差的第g个聚类中心对应的隶属度μgeg,仓重偏差变化率的第g个聚类中心对应的隶属度μgecg,喂料量增量的第g个聚类中心对应的隶属度μqeg;
8、步骤六,基于三种隶属度构建模糊规则;
9、步骤七,设定称重仓的目标值ggoal,采集t时刻稳流仓的仓重gt,并与设定的目标值ggial比较后得到实时偏差get以及偏差变化率gect,并基于模糊规则得到喂料量增量qet;对喂料量增量qet进行反归一化,再与t-1时刻的喂料量qt-1相加后得到t时刻的喂料量qt并传输给皮带秤。
10、进一步的,步骤二具体包括:
11、预设仓储喂料数据划分粒度grain的范围为[grain1,...,graink,...,grainmax],k∈[1,max],max代表仓储喂料数据划分粒度的最大取值范围;
12、基于仓储喂料数据划分粒度grain的每个取值,利用k-means聚类对输入数据集d中仓储喂料数据进行聚类,得到仓储喂料数据划分粒度的不同取值所对应的簇;
13、计算仓储喂料数据划分粒度grain在所有取值下的所有仓储喂料数据的平均轮廓系数,选平均轮廓系数最小的仓储喂料数据划分粒度作为最终仓储喂料数据划分粒度k′。
14、进一步的,所述计算仓储喂料数据划分粒度grain在所有取值下的所有仓储喂料数据的平均轮廓系数中,计算仓储喂料数据划分粒度grain在取值graink时第p个仓储喂料数据ep的轮廓系数具体包括:
15、定义第p个仓储喂料数据ep与其所属的簇内其他仓储喂料数据的平均距离为第p个仓储喂料数据ep与离其最近的另一个簇内所有仓储喂料数据之间的平均距离为则第p个仓储喂料数据ep的轮廓系数sp为:
16、
17、进一步的,步骤三具体包括:
18、计算仓储喂料数据密度阈值maxdist;
19、对输入数据集d中的每个仓储喂料数据计算仓储喂料数据密度;以数值最大的仓储喂料数据密度对应的仓储喂料数据作为首个聚类中心ecenter1,center1∈[1,q],定义首个聚类中心ecenter1的仓储喂料数据密度为mcenter1;
20、计算输入数据集d中除去首个聚类中心ecenter1外,其他仓储喂料数据的仓储喂料数据密度mexcept_center1:
21、
22、其中,exp(.)代表以自然常数e为底的指数函数,mp代表第p个仓储喂料数据ep的仓储喂料数据密度,a为ep的邻域半径;
23、计算得到其他所有仓储喂料数据的仓储喂料数据密度mexcept_center1后,在其中挑选仓储喂料数据密度最大的仓储喂料数据作为下一个聚类中心;
24、持续生成聚类中心,直到更新后的聚类中心密度最大值与第一个选择的聚类中心密度比值小于maxdist。
25、进一步的,所述计算仓储喂料数据密度阈值maxdist具体包括:
26、第p个仓储喂料数据ep与第k个聚类中心ck之间的距离distpk为:
27、
28、其中,表示欧几里得距离计算。
29、选取每个簇与所有仓储喂料数据距离最大的距离作为该簇的仓储喂料数据半径;
30、将所有的簇之间的仓储喂料数据半径两两之间求比值,以比值最大的数值作为仓储喂料数据密度阈值maxdist。
31、进一步的,第p个仓储喂料数据ep的仓储喂料数据密度mp的计算方式为:
32、
33、其中,q为仓储喂料数据索引,a为ep的邻域半径,eq为输入数据集d中第q个仓储喂料数据;
34、其中,ep的邻域半径a为:
35、
36、进一步的,步骤五具体包括:
37、仓重偏差的第g个聚类中心对应的隶属度μgeg为:
38、
39、其中,gep为步骤一中所述第p个仓重偏差,cgeg为步骤四中定义的仓重偏差的第g个聚类中心,σgeg为步骤四中定义的仓重偏差的第g个密度半径;
40、仓重偏差变化率的第g个聚类中心对应的隶属度μgecg为:
41、
42、其中,gecp为步骤一中所述第p个偏差变化率,cgecg为步骤四中定义的仓重偏差变化率的第g个聚类中心,σgecg为步骤四中定义的仓重偏差变化率的第g个密度半径;
43、喂料量增量的第g个聚类中心对应的隶属度μqeg为:
44、
45、其中,qep为步骤一中所述第p个喂料量,,cqeg为步骤四中定义的喂料量增量的第g个聚类中心,σqeg为步骤四中定义的喂料量增量的第g个密度半径。
46、进一步的,步骤六具体包括:
47、如果第p个仓重偏差gep的隶属度为μgeg,且第p个偏差变化率gecp的隶属度为μgecg,则第p个喂料量增量qep的隶属度为μqeg。
48、本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
49、本发明可以在没有具体专家经验的情况下,通过现有稳流仓仓重数据以及喂料量数据,利用减法聚类,得到模糊控制器参数,并将之转换成模糊规则。通过上述过程,无需专家经验,即可得到合适的模糊规则,此外得到的控制器对于稳流仓仓重控制具有很好的效果。
50、本发明使用的聚类参数是通过计算得到,减少人为主观因素干扰,使得控制器更加贴近专家经验,得到的控制效果更好。
- 还没有人留言评论。精彩留言会获得点赞!