一种基于Q-Learning强化学习的状态空间缩减方法
本发明涉及电动汽车的能量管理,具体涉及一种基于q-learning强化学习的状态空间缩减方法。
背景技术:
1、基于强化学习的控制策略是人工智能技术在电动汽车领域的一种创新性应用,如:基于q-learning控制策略,其自我学习、系我增强的控制特点,规避了控制策略的控制缺陷,可有效解决未知动态工况下的最优控制问题。
2、但是该类策略对控制器的算力有着较高的要求,目前仅限于理论研究阶段,难以实际应用于实车控制。
3、原因在于:基于q-learning的控制策略要求当先动作能够精确捕捉当前状态,因此需要对状态空间进行精细化设计,以插电式混合动力汽车为例,需要至少3个变量为状态,如将每个状态划分为离散的100份,则状态矩阵的大小为100×100×100=1000000,如此庞大的状态矩阵将导致现有控制器的算力失效;基于深度强化学习的控制策略由于嵌入了多层神经网络,需要加装价格昂贵的gpu进行运算,但是,由于gpu价格昂贵和国外底层封锁等原因,基于该类算法的控制策略难以实现产业化应用。因此一个状态空间的缩减方法对于现阶段的能量管理的实车应用是至关重要的。
4、专利cn2021107548591公开了一种基于q-learning的强化学习的状态空间缩减方法,该方法面向q-learning强化学习算法中使用两状态参数的情况,对两状态所组成的二维状态平面的坐标轴进行规划,类似于国际象棋的棋盘,将原有二维平面拆解为n×m个棋格区域,并为每个小方格区域进行状态量命名,并以此进行回报函数的设定,通过这种方法将原有的二维状态空间大大缩减,同时实现了实现了无电池荷电状态soc参考轨迹的强化学习智能能量管理控制策略。其存在以下缺点:状态缩减方法在固定工况下的能量管理策略中的效果较好,但是在不同工况的情况下仅凭电池荷电状态soc和归一化路程ld很难表征不同的组合工况。
技术实现思路
1、本发明要解决的技术问题是提供一种基于q-learning强化学习的状态空间缩减方法,该方法将三状态参数下较大的状态空间进行缩减,从而可以将强化学习算法应用于整车控制器中。
2、为解决上述技术问题,本发明采用如下技术手段:
3、一种基于q-learning强化学习的状态空间缩减方法,该方法包括以下步骤:
4、p1:状态参数的选取,选取电池荷电状态soc、归一化路程ld以及当前行驶距离当前行驶距离dis为状态参数;
5、p2:以步骤p1选择的三种状态参数为x轴、y轴、z轴,构造一个三维空间,并对该空间进行区间划分,将x轴的归一化路程0~1划分为n等份,n小于100;将z轴的电池荷电状态soc 0~1划分为m等份,m小于100;将y轴的当前行驶距离划分为i等份,i小于100;沿x轴、y轴、z轴的等分点分别平行于坐标轴的直线将三维空间划分成由小的立方块构成的空间,空间类似于“魔方”结构,将每个小的立方块的三维区域视为一个状态变量,并进行依次编号,从而缩减了状态变量;
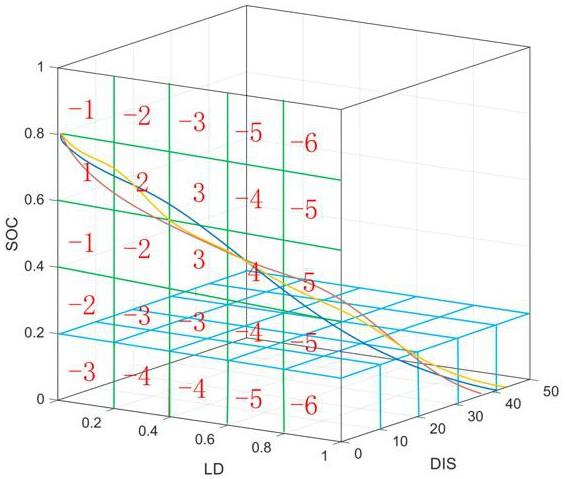
6、p3:获取最优电池荷电状态soc轨迹分布,以步骤p1选择的三种状态参数为x轴、y轴、z轴,构造出一个三维空间,以步骤p2中三维空间划分方法,将本步骤的上述三维空间同样划分为小的立方块构成的空间,在此基础上进行每个立方块的回报值的确定,根据最优电池荷电状态soc轨迹的分布获取有效控制区间,其中电池荷电状态soc轨迹经过的立方块的区域视为有效控制区间,有效控制区间内回报值为正,有效控制区外回报为负,同时偏离有效控制区间的程度越大,惩罚值越大。同时为了引导电池荷电状态soc逐渐接近目标范围,归一化路程ld值越大,有效控制区间内的奖励值越大,相应的偏离有效控制区间的惩罚值也越大;当前形式距离当前行驶距离dis越大,惩罚和奖励值也会相应增大。
7、获取最优电池荷电状态soc轨迹分布为现有技术,简述如下,使用庞特里亚金极小值原理算法(pontryagin’s minimum principle, pmp),动态规划(dynamic programming,dp)等离线优化算法,预先对目标城市的历史工况进行离线优化,设定合适的电池荷电状态soc范围,本专利中以插电式混合动力汽车为例,电池荷电状态soc起始值设置为0.8,使用pmp算法,通过调整pmp算法中的控制参数“协调因子(co-state)”,使电池荷电状态soc轨迹控制在预先设定的起始值与终点值范围内,因而得到该城市工况下的最优电池荷电状态soc轨迹,对该城市下多组工况进行离线优化,得到该城市下多组电池荷电状态soc最优电池荷电状态soc轨迹,将以上最优电池荷电状态soc轨迹以归一化的行驶距离为x轴,电池荷电状态soc值为z轴,当前行驶的距离为y轴进行图线绘制,由此得到最优电池荷电状态soc轨迹分布。
8、本技术主要应用于强化学习能量管理策略与相应控制器硬件的深度融合。
9、进一步的优选技术方案如下:
10、所述的步骤p2中, m、n、i均为10,小的立方块个数为1000。
11、根据行驶工况,在不同路线的行驶距离及速度,将归一化的行驶距离(归一化路程ld)设计为强化学习的状态参数;由于电动汽车的能耗经济性可由电池荷电状态soc反馈,因此,将电池荷电状态soc设计为第二个状态参数;由于不同路线下的行驶总距离可能是不同的,因此将当前行驶的距离设计为第三个状态参数。如果想实现强化学习算法的精确控制,需要对三个状态参数进行细致划分,若将每个状态参数划分为100份的话,则总的状态变量为100×100×100=1000000个,难以烧录至控制器中,故应对状态空间进行状态缩减,利用类似于“魔方”结构的三维空间划分,将每个区域视为一个状态变量,并进行依次编号,从而实现了状态空间的缩减。
12、对上述组成整个“魔方”的每个独立“立方块”按照一定的顺序设定对应的状态值,并以此设定相应的回报值。有效控制区间的回报值为正回报,且距离终点值越近,奖励值越大,有效控制区歪的回报值为负回报值,且偏离有效控制区间越远,惩罚越大。通过这种方法,将原有的1000000个状态变量缩减至m×n×i个,m、n、i的具体数值可根据控制器的存储空间及控制精度进行调整。
13、本专利中所述的m、n、i均为10,“魔方”的区域个数为1000。总的状态变量、回报值的数量大大减少。
14、本发明的优点在于:
15、第一:使原本无法烧录到控制器上的上百万的状态变量得到状态缩减,从而大大增加了强化学习算法的实车应用的可能性,减少对高性能gpu的依赖,推进了整车控制的发展。
16、传统的能量管理策略是通过电池荷电状态soc轨迹来获取回报,本发明提出的三维空间划分方法,不仅可以进行状态空间的缩减,同时还可以依次进行强化学习汇报制度的设计,从而实现无电池荷电状态soc参考轨迹的强化学习智能能量管理控制策略。
17、由于归一化路程ld无法表示出不同的组合工况的差异,从而限制了能量管理策略的应用范围,本发明选取电池荷电状态soc、归一化路程ld、当前行驶距离dis作为状态参数,由于不同路线下的行驶总距离可能是不同的,因此将当前行驶的距离设计为第三个状态参数,通过dis参数的不同来表征出路线不同距离不同的工况,从而将状态缩减方法扩大了应用范围。
18、本发明选取电池荷电状态soc、归一化路程ld、当前行驶距离dis作为状态参数,不仅适用于固定路线下的能量管理策略,同时适用于不同路线下距离不同的能量管理策略。
- 还没有人留言评论。精彩留言会获得点赞!