基于先验知识的深度强化学习机器人运动控制方法及系统
本发明属于机器人控制,尤其涉及基于先验知识的深度强化学习机器人运动控制方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、强化学习算法的收敛速度慢、学习效率低,机器人与环境交互时需要大量的试错性学习才能获得有效奖励,同时,对于四足机器人的运动控制任务来说,除了要保证运动过程中机身的稳定性,还要协调各腿之间的运动使其产生步态特征,因此,如何使四足机器人腿部规律性运动及提高强化学习的训练效率是本文的研究重点。强化学习前期很难获得有效奖励,在学习的过程中获得的回报持续上升但中后期学习的效果并不稳定。虽然从零开始学习可以消除专业知识的需求,但没有先验知识引导,四足机器人前期的学习效率较低,不易学习到高回报的动作。当智能体与环境交互的时间有限,智能体很难学习到最佳的控制策略。
技术实现思路
1、为克服上述现有技术的不足,本发明提供了基于先验知识的深度强化学习机器人运动控制方法及系统,将虚拟模型控制动作输出曲线作为四足机器人的先验知识,指导四足机器人的学习过程,将深度强化学习网络作为反馈调整部分增加机器人的学习能力,提高四足机器人对地形的适应能力和学习效率。
2、为实现上述目的,本发明的一个或多个实施例提供了如下技术方案:
3、本发明第一方面提供了基于先验知识的深度强化学习机器人运动控制方法。
4、基于先验知识的深度强化学习机器人运动控制方法,包括以下步骤:
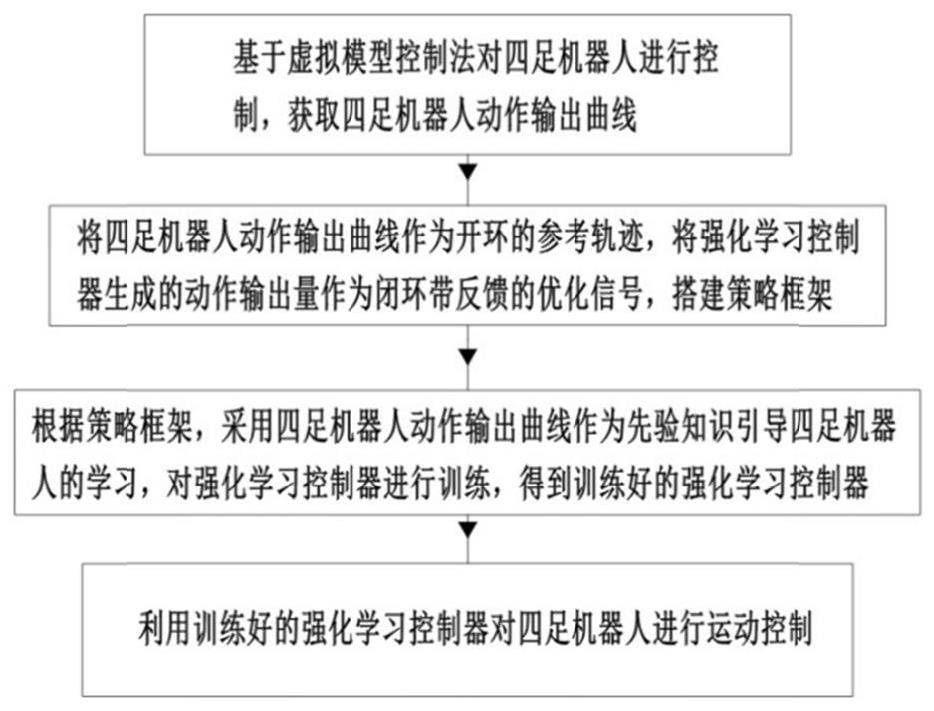
5、基于虚拟模型控制法对四足机器人进行控制,获取四足机器人动作输出曲线;
6、将四足机器人动作输出曲线作为开环的参考轨迹,将强化学习控制器生成的动作输出量作为闭环带反馈的优化信号,搭建策略框架;
7、根据策略框架,采用四足机器人动作输出曲线作为先验知识引导四足机器人的学习,对强化学习控制器进行训练,得到训练好的强化学习控制器;
8、利用训练好的强化学习控制器对四足机器人进行运动控制。
9、本发明第二方面提供了基于先验知识的深度强化学习机器人运动控制系统。
10、基于先验知识的深度强化学习机器人运动控制系统,包括:
11、虚拟模型控制模块,被配置为:基于虚拟模型控制法对四足机器人进行控制,获取四足机器人动作输出曲线;
12、策略框架搭建模块,被配置为:将四足机器人动作输出曲线作为开环的参考轨迹,将强化学习控制器生成的动作输出量作为闭环带反馈的优化信号,搭建策略框架;
13、训练模块,被配置为:根据策略框架,采用四足机器人动作输出曲线作为先验知识引导四足机器人的学习,对强化学习控制器进行训练,得到训练好的强化学习控制器;
14、运动控制模块,被配置为:利用训练好的强化学习控制器对四足机器人进行运动控制。
15、本发明第三方面提供了计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现如本发明第一方面所述的基于先验知识的深度强化学习机器人运动控制方法中的步骤。
16、本发明第四方面提供了电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如本发明第一方面所述的基于先验知识的深度强化学习机器人运动控制方法中的步骤。
17、以上一个或多个技术方案存在以下有益效果:
18、本发明提出了一种基于先验知识的深度强化学习机器人运动控制方法及系统,将虚拟模型控制(vmc)动作输出曲线作为四足机器人的先验知识,指导四足机器人的学习过程,将深度强化学习ddpg网络作为反馈调整部分增加机器人的学习能力,利用深度强化学习算法的学习能力调整动作输出,提高四足机器人对地形的适应能力和学习效率,既保证了四足机器人的稳定性又增强了四足机器人的运动能力,最终在仿真环境下验证了算法的可靠性。
19、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.基于先验知识的深度强化学习机器人运动控制方法,其特征在于,包括以下步骤:
2.如权利要求1所述的基于先验知识的深度强化学习机器人运动控制方法,其特征在于,利用虚拟模型控制方法对四足机器人进行摆动相控制、支撑相控制和转向控制。
3.如权利要求2所述的基于先验知识的深度强化学习机器人运动控制方法,其特征在于:
4.如权利要求1所述的基于先验知识的深度强化学习机器人运动控制方法,其特征在于,搭建的策略框架表达式为:
5.如权利要求1所述的基于先验知识的深度强化学习机器人运动控制方法,其特征在于,在面对斜坡地形时,深度强化学习控制器的奖励函数设计为:
6.如权利要求1所述的基于先验知识的深度强化学习机器人运动控制方法,其特征在于,在面对不连续地形时奖励函数设计为:
7.如权利要求1所述的基于先验知识的深度强化学习机器人运动控制方法,其特征在于,强化学习控制器的训练过程为:
8.基于先验知识的深度强化学习机器人运动控制系统,其特征在于:包括:
9.计算机可读存储介质,其上存储有程序,其特征在于,该程序被处理器执行时实现如权利要求1-7任一项所述的基于先验知识的深度强化学习机器人运动控制方法中的步骤。
10.电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-7任一项所述的基于先验知识的深度强化学习机器人运动控制方法中的步骤。
技术总结
本发明提出基于先验知识的深度强化学习机器人运动控制方法及系统,涉及机器人控制技术领域。包括基于虚拟模型控制法获取四足机器人动作输出曲线;将四足机器人动作输出曲线作为开环的参考轨迹,将强化学习控制器生成的动作输出量作为闭环优化信号,搭建策略框架;根据策略框架,采用四足机器人动作输出曲线作为先验知识引导四足机器人学习,对强化学习控制器进行训练,得到训练好的强化学习控制器,对四足机器人进行运动控制。本发明将虚拟模型控制动作输出曲线作为四足机器人的先验知识,指导四足机器人的学习过程,将深度强化学习网络作为反馈调整部分增加机器人的学习能力,提高四足机器人对地形的适应能力和学习效率。
技术研发人员:宋勇,李昊原,刘萍萍,夏一帆,许庆阳,袁宪锋,庞豹,李贻斌
受保护的技术使用者:山东大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!