一种基于强化学习的制造过程工艺参数优化方法及系统
本发明涉及参数优化,具体涉及一种基于强化学习的制造过程工艺参数优化方法及系统。
背景技术:
1、在工业制造领域,高质量的工艺产品严重依赖于最优的工艺参数设置;过程参数优化是一种关键的任务,可以帮助改善生产效率、降低成本并提高产品质量;在实际工业场景中,工艺参数取值对零件质量的影响存在各种不确定性和随机性;零件加工制造过程中需要事先设定多种关键生产工艺参数,生产工艺参数设定值的合理与否,与最终生成出来的产品品质有着直接的影响;目前,实际工业生成中的工艺参数主要是根据工程师经验确定及手动试错调整,耗时耗力,导致产品品质一致性不高。产品质量与工艺参数之间的关系常常模糊且受到不同变量之间的复杂影响,使得确定高质量产品的工艺参数变得具有挑战性;特别是对于尺寸精度要求极高的产品,其工艺窗口往往狭窄且不规则,使得获得适当的工艺参数设置比一般产品更为困难;因此,如何快速寻求有效的工艺参数优化方法以解决生产高精度产品的难题至关重要。
2、传统的工艺参数调整方法依赖于工程师的经验,通过现场工程师的反复试错进行最优工艺参数的选择;但是,方法存在一些问题;首先,它们依赖于先验知识,这可能限制了它们在动态环境下的适用性;其次,它们不足以实现自动化,需要人工干预和多次试验;此外,方法常常是静态的,基于固定的数据集进行优化,无法适应动态和复杂的制造过程中可能出现的变化和挑战。
3、针对问题,现有技术提出了一些解决方案;其中一些技术基于实验设计和统计过程映射,通过对参数空间进行有限采样和分析,寻找最佳或可行的参数;然而,方法存在一些限制。现有技术需要大量初始数据来建立参数与性能之间的关系,在一些领域如注塑成型、金属增材制造等具有高昂的数据生成成本时,成为制约因素;其次,现有技术大多数是倾向于静态模型,无法很好地适应动态和复杂的生产环境。
4、另外,现有技术往往缺乏实时或在线的反馈机制;不能对实时的过程监测或质量检测结果进行参数调整,导致无法及时应对制造过程中的变化和波动。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明提供一种基于强化学习的制造过程工艺参数优化方法及系统,用于替代传统人工调优调参,以提高产品质量和生产效率,更好地适应动态和复杂的生产环境,对实时的过程监测或质量检测结果进行参数调整,导及时应对制造过程中的变化和波动。
2、为实现上述效果,本发明的技术方案如下:
3、第一个方面,本发明提供基于强化学习的制造过程工艺参数优化方法方法,包括以下步骤:
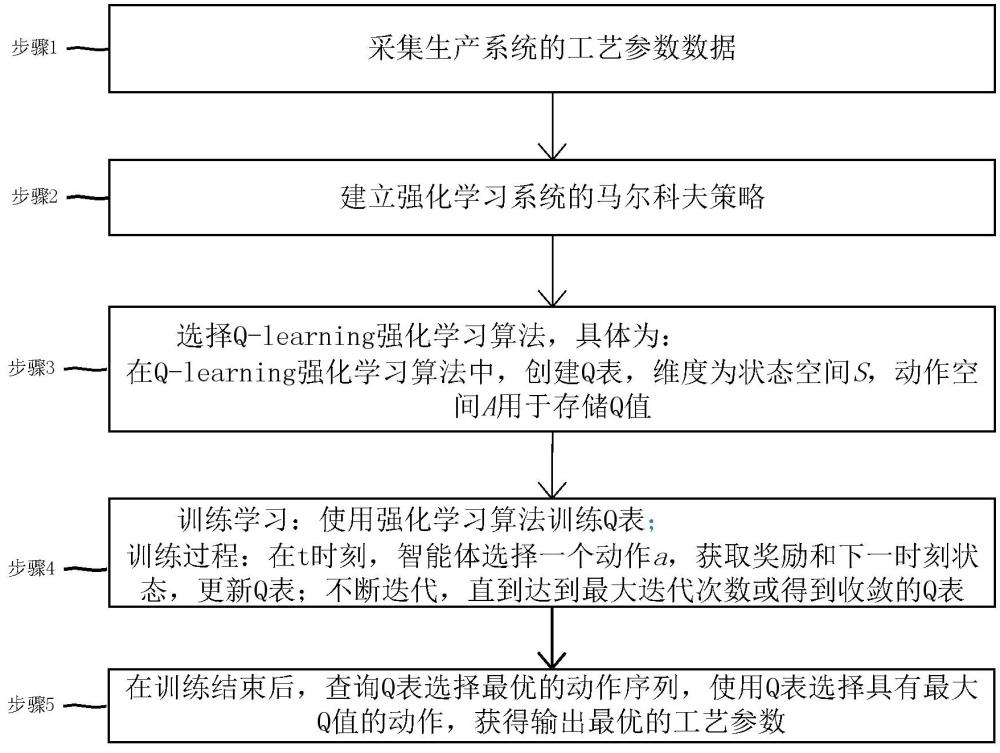
4、步骤1:采集生产系统的工艺参数数据;
5、步骤2:建立强化学习系统的马尔科夫策略,具体为:
6、建立面向制造过程工艺参数推理决策的马尔科夫策略,马尔科夫策略表示制造过程中产品的状态、工艺参数拟采取的动作 a、产品转移状态以及工艺参数输入下的奖励函数r;估计工艺参数与产品品质之间的关系,将制造过程工艺参数优化问题定义为最大化奖励;所述马尔科夫策略中的智能体为执行任务的机器;
7、步骤3:选择q-learning强化学习算法,具体为:
8、在q-learning强化学习算法中,创建q表,维度为状态空间 s,动作空间 a用于存储q值;
9、步骤4:训练学习:使用强化学习算法训练q表;
10、训练过程:在t时刻,智能体选择一个动作 a,获取奖励和下一时刻状态,更新q表;不断迭代,直到达到最大迭代次数或得到收敛的q表;
11、步骤5:在训练结束后,查询q表选择最优的动作序列,使用q表选择具有最大q值的动作,获得输出最优的工艺参数。
12、进一步的,步骤2所述建立面向制造过程工艺参数推理决策的马尔科夫策略,具体为:
13、定义状态空间 s:状态空间表示强化学习系统的当前状况,包括机器的温度、材料的类型、注射速度、保压时间;用状态空间 s表示当前强化学习系统的状态;在注塑成型工艺参数优化问题中,状态包括注射速度 v、保压时间 t和注射压力 p;
14、定义动作空间 a:动作空间a表示针对工艺参数优化过程进一步采取的动作,即定义如何调整工艺参数;在注塑工艺制造过程中,动作包括调整注射速度、保压时间和注射压力后的变化量,即δ v、δ t和δ p;动作空间是所有可能动作的集合,是连续值或离散化后的值;状态空间是注射速度 v、保压时间 t和注射压力 p变化的取值范围;
15、定义奖励函数 r:奖励函数度量用于衡量智能体在一定状态下执行动作后获得的即时奖励;定义奖励函数,根据产品品质指标计算奖励值;
16、若产品品质低于预设的目标品质,则奖励为负值;若产品品质在预设的目标品质范围内,则奖励为零或较小的正值;
17、确定状态转移概率:模拟工艺参数的调整对产品品质的影响;
18、定义目标函数j:目标函数j用于表示最大化总奖励的累积。
19、进一步的,步骤2所述将制造过程工艺参数优化问题定义为最大化奖励,具体为:
20、定义制造过程工艺参数优化问题的优化目标、环境、状态、动作以及奖励;其中,制造过程为零件加工的注塑成型过程;优化目标表示优化零件加工制造过程中的工艺参数;环境表示零件加工生产环境,包括工艺参数的设定范围以及对零件质量的影响;状态表示当前工艺参数的设定值;动作表示对工艺参数进行调整;奖励表示通过衡量产品的品质指标,最终的优化目标设定为制造过程中获得的最大奖励。
21、进一步的,所述状态空间为注射速度 v、保压时间 t和注射压力 p变化的取值范围,表述为:
22、
23、式中,{“{ min}”}、{“{ max}”}分别表示最小值、最大值。
24、进一步的,所述动作空间a表示为:
25、。
26、进一步的,在注塑成型问题中,奖励函数 r基于实际收缩率与期望收缩率的差异,表示为:
27、
28、式中, s表示当前状态的收缩率, starget表示期望的收缩率, a表示当前的动作。
29、进一步的,在注塑成型制造过程工艺问题中,目标函数j为最大化总奖励的累积,即:
30、
31、式中,γ表示折扣因子。
32、进一步的,所述q表的更新规则为:基于贝尔曼方程更新q值,即:
33、
34、式中,α表示学习率, s′为下一个状态, a′为下一个状态的动作。
35、第二个方面,本发明提供基于强化学习的制造过程工艺参数优化系统,包括:
36、数据获取模块,用于采集生产系统的工艺参数数据;
37、马尔科夫策略构建模块,用于建立强化学习系统的马尔科夫策略,具体为:
38、建立面向制造过程工艺参数推理决策的马尔科夫策略,马尔科夫策略表示制造过程中产品的状态、工艺参数拟采取的动作 a、产品转移状态以及工艺参数输入下的奖励函数r;估计工艺参数与产品品质之间的关系,将制造过程工艺参数优化问题定义为最大化奖励;所述马尔科夫策略中的智能体为执行任务的机器;
39、强化学习算法设定模块,用于选择q-learning强化学习算法,具体为:
40、在q-learning强化学习算法中,创建q表,维度为状态空间 s,动作空间 a用于存储q值;
41、训练模块,用于训练学习:使用强化学习算法训练q表;
42、训练过程:在t时刻,智能体选择一个动作 a,获取奖励和下一时刻状态,更新q表;不断迭代,直到达到最大迭代次数或得到收敛的q表;
43、工艺参数优化模块,用于在训练结束后,查询q表选择最优的动作序列,使用q表选择具有最大q值的动作,获得输出最优的工艺参数。
44、与现有技术相比,本发明技术方案的有益效果是:
45、1.提高产品品质:现有技术中,工艺参数是根据工程师的经验或手动试错来调整的,导致产品品质的一致性不高;而本发明建立强化学习系统的马尔科夫策略,引入q-learning强化学习方法,根据设计的产品质量目标自动优化最佳工艺参数输入,使产品质量更加稳定和可控;
46、2.减少人工干预:传统方法中,工艺参数的调整需要大量的人工干预和监控,耗费时间和资源;而本发明引入强化学习可以自动优化工艺参数,减少了人为错误的风险,提高了生产效率;
47、3.应对复杂性:在工业生产中,工艺参数是多维的,相互关联复杂;本发明引入强化学习可以有效应对工艺参数的多维度和复杂性,选择最佳的参数,以满足产品质量要求;
48、4.实时优化:强化学习可以在实时监测下进行工艺参数的优化,根据不断变化的生产条件和需求做出调整,以保持产品质量。
- 还没有人留言评论。精彩留言会获得点赞!