小车的路径跟随控制器及其实现方法
本发明涉及移动机器人,尤其是一种小车的路径跟随控制器及其实现方法。
背景技术:
1、agv小车属于移动机器人,通过自主运输,能够减低人工损耗,缩短物流周期,被广泛应用生产、仓储物流当中。随着工业时代的到来,自主无人化、智能化的agv是未来物流领域发展趋势。路径跟随是agv在工厂车间、仓库等地方运动控制基本任务之一,也是实现agv自主智能运动的关键。
2、相关技术中的一种方法是通过强化学习思想控制小车的路径跟随。然而,由于人工智能的控制方法本质上是依靠神经网络的权重训练而优化迭代而形成,在不断与所构建的环境进行交互过程中,会造成资源紧张、时间代价过大,产生采样效率低的问题。另一种方法是通过模型预测控制进行路径跟随,模型预测控制是一种基于优化的控制方法,其在求解过程中,能够对状态量和控制量进行约束,最终预测得出较为精确的控制。然而,对于模型预测控制,其代价函数的权重系数,通常要根据具体实际情况来进行拟定,采用人工系数设定调节方法会造成优化失准问题。
技术实现思路
1、本发明的目的在于至少一定程度上解决现有技术中存在的技术问题之一。
2、为此,本发明的目的在于提供一种高效的小车的路径跟随控制器、方法、装置及存储介质。
3、为了达到上述技术目的,本发明实施例所采取的技术方案包括:
4、一方面,本发明实施例提供了一种小车的路径跟随控制器,包括:
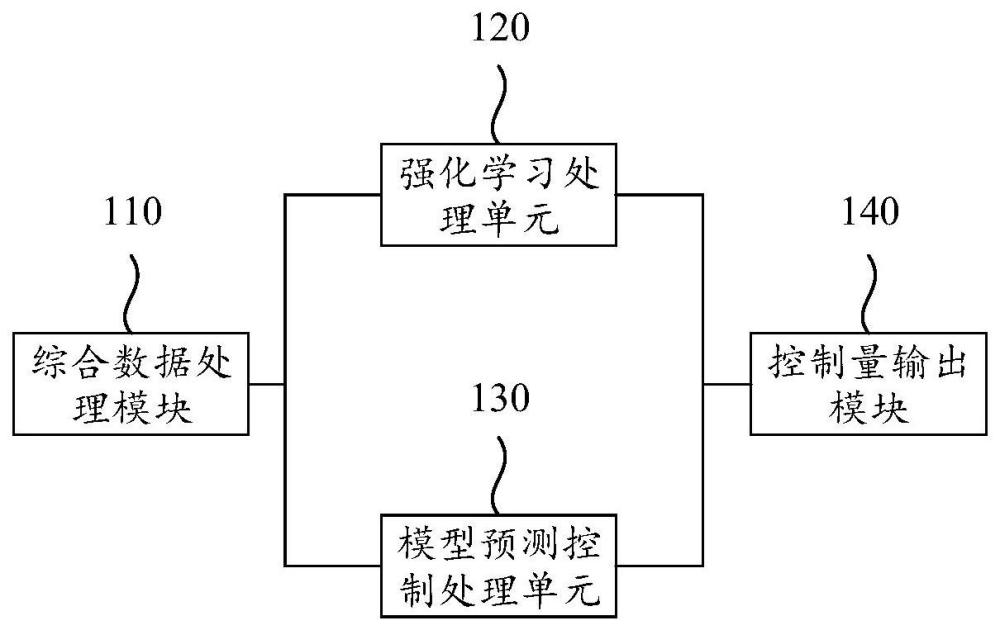
5、本发明实施例的小车的路径跟随控制器,所述路径跟随控制器包括:综合数据处理模块、强化学习处理单元、模型预测控制处理单元、控制量输出模块;其中,所述综合数据处理模块用于获取路径跟随模态控制信息,并将所述路径跟随模态控制信息发送至所述强化学习处理单元和所述模型预测控制处理单元;所述强化学习处理单元用于根据所述路径跟随模态控制信息更新强化学习网络,并根据所述强化学习网络得到第一信息;并将所述第一信息发至所述模型预测控制处理单元和所述控制量输出模块;所述第一信息包括目标控制量所需的决策融合系数;所述模型预测控制处理单元用于根据所述第一信息和所述路径跟随模态控制信息,生成预测控制量,并将所述预测控制量发至所述控制量输出模块;所述控制量输出模块用于根据所述预测控制量和所述第一信息,生成目标控制量。本申请实施例通过强化学习单元和模型预测控制处理单元的深度融合处理,实现小车在复杂运输环境下的精准路径跟随控制,提升跟随控制的准确度。
6、另外,根据本发明上述实施例的小车的路径跟随控制器,还可以具有以下附加的技术特征:
7、进一步地,本发明实施例的小车的路径跟随控制器,所述强化学习处理单元包括环境单元、代理单元和参数输出模块;所述环境单元用于配置状态量,并根据连续时刻的状态量生成奖励量,将所述状态量和所述奖励量发至所述代理单元;所述代理单元用于根据所述状态量和所述奖励量,基于所述强化学习网络生成第一控制量、代价函数权重系数和决策融合系数,并将所述第一控制量和所述决策融合系数通过所述参数输出模块发至所述控制量输出模块,将所述代价函数权重系数发至所述模型预测控制处理单元。
8、进一步地,在本发明的一个实施例中,所述代理单元还用于将所述决策融合系数发至所述环境单元,所述环境单元用于根据所述决策融合系数更新所述状态量和所述奖励量。
9、进一步地,在本发明的一个实施例中,所述模型预测控制处理单元包括:误差计算模块和滚动优化计算模块;其中,所述误差计算模块用于计算位姿误差,并将所述位姿误差发至所述滚动优化计算模块;所述滚动优化计算模块用于根据所述位姿误差生成所述预测控制量。
10、进一步地,在本发明的一个实施例中,所述滚动优化计算模块还用于根据代价函数生成所述预测控制量,所述代价函数为:用于表征从第i时刻到第i+n-1时刻位姿误差,i代表某一时刻,ηi为代价函数权重系数。
11、另一方面,本发明实施例提出了一种小车的路径跟随控制器的实现方法,应用于上述的小车的路径跟随控制器,所述方法包括:
12、获取路径跟随模态控制信息;
13、根据所述获取路径跟随模态控制信息,建立强化学习网络;
14、将所述路径跟随模态控制信息输入所述强化学习网络,得到第一信息;所述第一信息包括目标控制量所需的决策融合系数;
15、根据所述第一信息和所述路径跟随模态控制信息,生成预测控制量;
16、根据所述预测控制量和所述第一信息,生成目标控制量。
17、进一步地,本发明实施例的小车的路径跟随控制器的实现方法,所述方法还包括:
18、根据所述获取路径跟随模态控制信息,配置状态量,并根据连续时刻的状态量生成奖励量;
19、根据所述状态量和所述奖励量,基于所述强化学习网络生成第一控制量、代价函数权重系数和决策融合系数。
20、进一步地,本发明实施例的小车的路径跟随控制器的实现方法,所述方法还包括:
21、根据所述决策融合系数,更新所述状态量和所述奖励量。
22、进一步地,本发明实施例的小车的路径跟随控制器的实现方法,还包括:
23、根据所述获取路径跟随模态控制信息,计算位姿误差;
24、根据所述位姿误差,确定预测控制量。
25、进一步地,本发明实施例的小车的路径跟随控制器的实现方法,所述根据所述位姿误差,确定预测控制量,包括:
26、根据代价函数,确定预测控制量;所述代价函数为:用于表征从第i时刻到第i+n-1时刻位姿误差,i代表某一时刻,ηi为代价函数权重系数。
27、另一方面,本发明实施例提供了一种小车的路径跟随控制器的实现装置,包括:
28、至少一个处理器;
29、至少一个存储器,用于存储至少一个程序;
30、当所述至少一个程序被所述至少一个处理器执行时,使得所述至少一个处理器实现上述的小车的路径跟随控制器的实现方法。
31、另一方面,本发明实施例提供了一种存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于实现上述的小车的路径跟随控制器的实现方法。
32、本申请实施例通过强化学习单元和模型预测控制处理单元的深度融合处理,实现小车在复杂运输环境下的精准路径跟随控制,提升跟随控制的准确度。
技术特征:
1.一种小车的路径跟随控制器,其特征在于,所述路径跟随控制器包括:综合数据处理模块、强化学习处理单元、模型预测控制处理单元、控制量输出模块;
2.根据权利要求1所述的小车的路径跟随控制器,其特征在于,所述强化学习处理单元包括环境单元、代理单元和参数输出模块;所述环境单元用于配置状态量,并根据连续时刻的状态量生成奖励量,将所述状态量和所述奖励量发至所述代理单元;所述代理单元用于根据所述状态量和所述奖励量,基于所述强化学习网络生成第一控制量、代价函数权重系数和决策融合系数,并将所述第一控制量和所述决策融合系数通过所述参数输出模块发至所述控制量输出模块,将所述代价函数权重系数发至所述模型预测控制处理单元。
3.根据权利要求2所述的小车的路径跟随控制器,其特征在于,所述代理单元还用于将所述决策融合系数发至所述环境单元,所述环境单元用于根据所述决策融合系数更新所述状态量和所述奖励量。
4.根据权利要求1所述的小车的路径跟随控制器,其特征在于,所述模型预测控制处理单元包括:误差计算模块和滚动优化计算模块;其中,所述误差计算模块用于计算位姿误差,并将所述位姿误差发至所述滚动优化计算模块;所述滚动优化计算模块用于根据所述位姿误差生成所述预测控制量。
5.根据权利要求1所述的小车的路径跟随控制器,其特征在于,所述滚动优化计算模块还用于根据代价函数生成所述预测控制量,所述代价函数为:用于表征从第i时刻到第i+n-1时刻位姿误差,i代表某一时刻,ηi为代价函数权重系数。
6.一种小车的路径跟随控制器的实现方法,其特征在于,应用于如权利要求1所述的小车的路径跟随控制器,所述方法包括:
7.根据权利要求6所述的小车的路径跟随控制器的实现方法,其特征在于,所述方法还包括:
8.根据权利要求7所述的小车的路径跟随控制器的实现方法,其特征在于,所述方法还包括:根据所述决策融合系数,更新所述状态量和所述奖励量。
9.根据权利要求7所述的小车的路径跟随控制器的实现方法,其特征在于,所述方法还包括:根据所述获取路径跟随模态控制信息,计算位姿误差;
10.根据权利要求7所述的小车的路径跟随控制器的实现方法,其特征在于,所述根据所述位姿误差,确定预测控制量,包括:
技术总结
本发明公开了一种小车的路径跟随控制器及其实现方法。该路径跟随控制器包括:综合数据处理模块、强化学习处理单元、模型预测控制处理单元、控制量输出模块;综合数据处理模块用于获取路径跟随模态控制信息;强化学习处理单元用于根据路径跟随模态控制信息更新强化学习网络,并根据强化学习网络得到第一信息;模型预测控制处理单元用于根据第一信息和路径跟随模态控制信息,生成预测控制量;控制量输出模块用于根据预测控制量和第一信息,生成目标控制量。本申请实施例通过强化学习单元和模型预测控制处理单元的深度融合处理,实现小车在复杂运输环境下的精准路径跟随控制,提升跟随控制的准确度;可广泛应用于移动机器人技术领域内。
技术研发人员:程思竹,张少波,陈明星,程秀全,夏琴香
受保护的技术使用者:广州民航职业技术学院
技术研发日:
技术公布日:2024/1/25
- 还没有人留言评论。精彩留言会获得点赞!