一种基于课程学习的无人机对抗决策优化方法
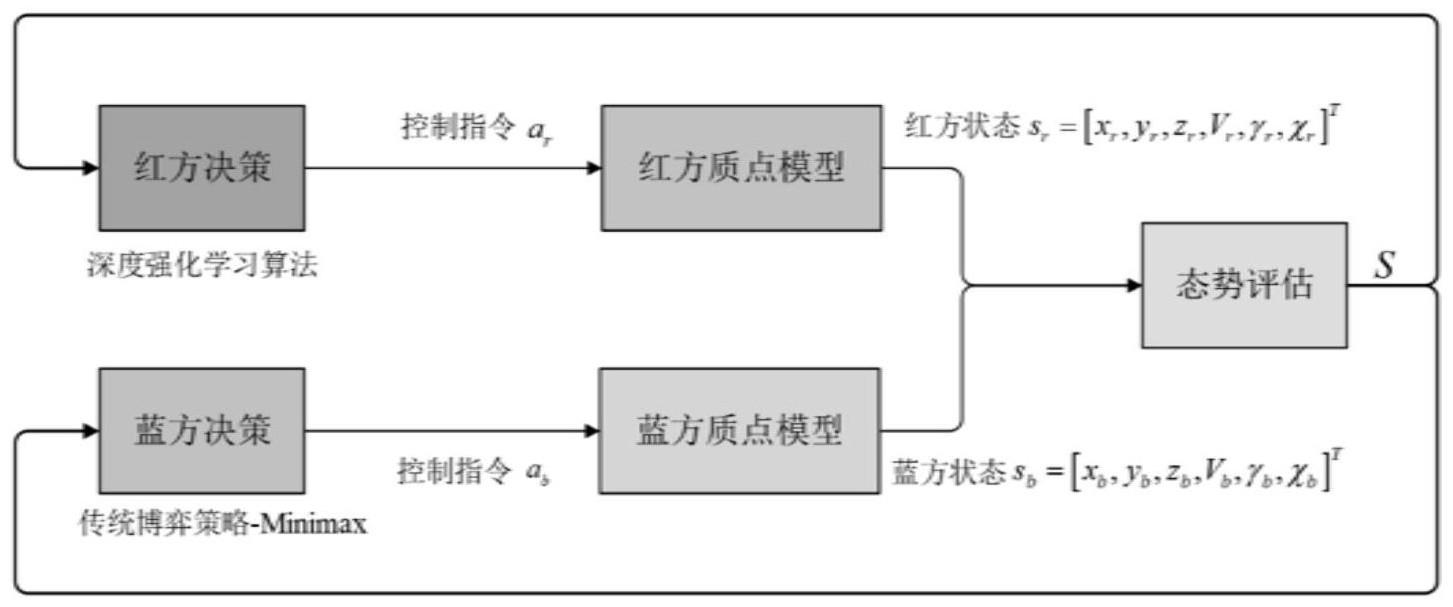
本发明涉及无人机决策,涉及一种基于课程学习的无人机对抗决策优化方法,具体涉及一种基于课程学习辅助深度强化学习的无人机对抗决策训练优化方法。
背景技术:
1、无人机空战对抗问题已成为研究热点,目前已在忠诚僚机、空战演进(air combatevolution,ace)、skyborg、alpha ai等项目中取得了重大进展。
2、空战决策是空战对抗的核心问题,由于空战对抗中无人机往往进行高速大机动飞行,空战态势高动态变化,且作战环境复杂,对敌信息感知不完全,因此如何面向信息不确定、高动态、强对抗的空战环境,进行实时决策十分关键。空战对抗决策的算法分为基于专家知识、博弈理论、优化理论、深度强化学习。
3、传统的基于规则的专家系统针对特定场景进行建模分析,适用性较差,已无法满足智能作战需求;基于博弈理论的空战对抗决策主要分为微分博弈和矩阵博弈,常用于解决一对一空战对抗问题,其中,微分博弈建立状态-决策微分博弈方程,求解在约束条件下的纳什均衡解作为最优策略,但是求解计算复杂、灵活性差;矩阵博弈实质是微分博弈的离散化,随着决策空间广度和深度的加大,求解时间急剧增加;空战对抗机动决策问题采用优化理论求解多目标优化问题;传统的优化算法求解需遍历整个搜索空间,效率低。因此需要研究一种更加高效、实时准确的求解算法来获取面向高动态、强对抗、信息不确定的复杂空战环境中无人机实时准确的决策方法。
技术实现思路
1、鉴于上述问题,本发明提供了一种基于课程学习的无人机对抗决策优化方法,依据深度强化学习算法设计空战对抗动作空间、状态空间、奖励函数、网络空间,基于sac算法训练获取无人机空战决策方法,结合课程学习优化训练过程,实现无人机空战对抗智能决策。
2、本发明的第一个目的在于提供一种基于课程学习的无人机对抗决策优化方法,具体提供了一种基于课程学习辅助深度强化学习的无人机对抗决策优化方法,具体包括:
3、s1、基于空战双方无人机的位置、速度、姿态,构建无人机空战对抗运动模型;将所述无人机空战对抗运动模型结合空战态势要素,基于优势函数法建立空战态势评估模型;
4、优选的,步骤s1所述无人机空战对抗运动模型包括:无人机质点运动模型和相对运动模型;
5、所述空战态势要素包括:空战双方无人机的角度、高度、速度、距离。
6、进一步的,建立所述无人机空战对抗运动模型,所述无人机空战对抗运动模型适用于红蓝双方无人机,具体步骤包括:
7、分别获取红蓝双方无人机在惯性坐标系下x,y,z轴的运动信息集,基于所述运动信息集建立三自由度质点模型;所述运动信息集包括位置矢量、速度大小、航迹倾角、航迹偏角;
8、更进一步,所述三自由度质点模型表达式为:
9、
10、
11、其中,为无人机x轴方向变化率,为无人机y轴方向变化率,为无人机z轴方向变化率,y轴是前进方向轴;v为无人机的速度大小,γ为无人机的航迹倾角,χ为无人机的航迹偏角,为无人机速度大小变化率,g为重力加速度;ny为无人机沿飞行速度方向,表示无人机的切向过载;为航迹倾角变化率;nz为无人机垂直于飞行速度方向,表示无人机法向过载,μ为无人机绕速度轴的滚转角,为航迹偏角变化率。
12、进一步的,建立所述无人机相对运动模型,如图2所示,表达式为:
13、vr=[vrcosγr sinχr,vrcosγr cosχr,vrsinγr]
14、vb=[vb cosγb sinχb,vb cosγb cosχb,vb sinγb]
15、dr=[xb-xr,yb-yr,zb-zr]
16、
17、
18、其中,假定我方为红方无人机,vr为红方无人机速度矢量,vr为红方的速度大小,γr为红方的航迹倾角,χr为红方的航迹偏角;假定对手为蓝方无人机,vb为蓝方无人机速度矢量,vb为蓝方的速度大小,γb为蓝方的航迹倾角,χb为蓝方的航迹偏角;dr为红蓝双方相对位置矢量,xr,yr,zr,表示红方在惯性坐标系下的位置坐标,xb,yb,zn表示蓝方在惯性坐标系下的位置坐标;ata为偏离角,即红方无人机速度矢量与红蓝无人机相对位置矢量的夹角;aa为脱离角,即蓝方无人机速度矢量与红蓝无人机相对位置矢量的夹角。
19、优选的,步骤s1所述空战态势评估模型为红方无人机空战态势评估模型,表达式为:
20、s=k1*sa+k2*sh+k3*sv+k4*sd
21、其中,s为红方无人机空战态势评估值,sa为红方无人机空战角度的态势,sh为红方无人机空战高度的态势,sv为红方无人机空战速度的态势,sd为红方无人机空战距离的态势;k1表示红方无人机空战角度的态势对应的权重,k2表示红方无人机空战高度的态势对应的权重,k3表示红方无人机空战速度的态势对应的权重,k4表示红方无人机空战距离的态势对应的权重,满足k1+k2+k3+k4=1。
22、进一步的,所述红方无人机的空战角度态势,表达式为:
23、
24、其中,sa为红方无人机空战角度的态势,ata为偏离角,即红方无人机速度矢量与红蓝无人机相对位置矢量的夹角;aa为脱离角,即蓝方无人机速度矢量与红蓝无人机相对位置矢量的夹角。
25、进一步的,所述红方无人机空战高度的态势,表达式为:
26、
27、其中,sh为红方无人机空战高度的态势,dz为红蓝双方无人机z轴坐标差,dopt为红蓝双方最优的高度优势差。
28、进一步的,所述红方无人机空战速度的态势,表达式为:
29、
30、其中,sv为红方无人机空战速度的态势,dv为红蓝无人机速度大小差,vmax为无人机飞行最大速度,vmin为无人机飞行最小速度。
31、进一步的,所述红方无人机空战距离的态势,表达式为:
32、
33、其中,sd为红方无人机空战距离的态势,表示红蓝双方无人机相对距离的大小,ymin为红蓝双方无人机仿真飞行区域y轴的边界坐标最小值,ymax为红蓝双方无人机仿真飞行区域y轴的边界坐标最大值,dmax为红蓝双方无人机机载武器攻击的最大距离,dmin为红蓝双方无人机机载武器攻击的最小距离。
34、s2、使用步骤s1所述无人机空战对抗运动模型分别设计深度强化学习算法的状态空间和动作空间;
35、基于无人机空战对抗运动模型、空战态势评估模型以及所述状态空间和动作空间获取空战对抗的状态转移函数并设计奖励函数;
36、基于所述状态空间、动作空间、状态转移函数和奖励函数建立无人机空战对抗决策的马尔可夫决策过程;
37、优选的,步骤s2所述无人机空战对抗决策的马尔可夫决策过程由元组{s,a,p,r,γ}描述;
38、优选的,步骤s2所述所述深度强化学习算法为sac(soft actor critic)算法;
39、优选的,所述状态空间基于所述无人机空战对抗运动模型获取相对状态与绝对状态,将所述相对状态与绝对状态进行组合来设计状态空间变量,体现出双方无人机的位置、姿态等信息;
40、所述状态空间共十一维,状态变量在传入网络前先进行归一化处理,以更好的训练网络。
41、进一步的,所述状态空间的表达式为:
42、sr=[ata,aa,dx,dy,dz,vr,γr,χr,vb,γb,χb]t
43、其中,sr为红方无人机空战对抗模型的状态空间;dx表示红蓝双方x轴相对位置变量,dy表示红蓝双方y轴相对位置变量,dz表示红蓝双方z轴相对位置变量。
44、进一步的,所述动作空间为红方无人机连续动作空间,表达式为:
45、a=[nry,nrz,μr]t
46、其中,a为红方无人机动作空间,nry为红方无人机切向过载,nrz为红方无人机法向过载,μr为红方无人机绕速度轴的滚转角。
47、优选的,所述奖励函数为稀疏奖励和稠密奖励;所述稀疏奖励根据空战结果设置;所述稠密奖励基于步骤s1所述空战态势评估模型设计。
48、s3、利用步骤s2所述状态空间和动作空间设计网络空间;基于所述状态空间、动作空间、网络空间以及步骤s2所述马尔可夫决策过程,构建深度强化学习算法;
49、优选的,步骤s3所述网络空间为mlp网络,包括策略网络和价值网络;所述策略网络的输入为无人机当前状态值,输出为动作值;所述价值网络的输入为无人机当前状态和动作值,输出为当前状态下执行该动作的价值。
50、优选的,获得步骤s3所述网络空间包括策略网络和价值网络,具体步骤包括:
51、设计策略网络的输入层和输出层,所述输入层为状态向量,输出层有两个分支,一个分支用于计算生成的随机动作高斯分布的均值,另一个分支用于计算生成的随机动作高斯分布的对数方差;
52、设计价值网络的输入层为状态向量与动作向量的拼接,输出层为一个标量即估计的动作价值,如图3和图4所示。
53、s4、基于所述空战态势评估模型对所述奖励函数进行重塑,获得重塑后奖励函数;
54、基于所述重塑后奖励函数和所述深度强化学习算法训练所述网络空间;
55、将步骤s2所述奖励函数基于课程学习进行改进,获取改进后的奖励函数,使用所述改进后的奖励函数对训练过程进行优化,获得训练后的网络空间;
56、基于所述训练后的网络空间建立无人机空战对抗策略模型;
57、优选的,步骤s4所述使用所述改进后的奖励函数对训练过程进行优化,具体步骤包括:
58、基于课程学习对奖励函数中稀疏奖励和稠密奖励进行动态调整,训练前期采用稠密奖励函数快速学习基础策略,引入时序退化因子,不断降低稠密奖励比重,训练后期取稀疏奖励进行训练增大探索范围,克服奖励函数只设计稀疏奖励训练困难问题。
59、本发明基于课程学习对训练过程进行优化,克服基于人为设计稠密奖励可能使训练无人机空战对抗策略模型引入人为偏差,以及只基于稀疏奖励训练困难问题,提升了无人机空战对抗策略模型的对战胜率。
60、优选的,步骤s4所述改进后的奖励函数表达式为:
61、rcl=αtrs+(1-at)rl
62、
63、stepexp lore=steptotal×texp lore
64、其中,rcl为改进后的奖励函数,αt为课程学习时序退化因子,rs为稠密奖励,rl为稀疏奖励,stepexplore为无人机当前状态对应的课程学习探索步长,stepcur为无人机当前状态的仿真步长,steptotal为仿真总步长,texplore为课程学习探索系数。
65、进一步的,所述稠密奖励,表达式为:
66、rs=wara+wr+wvrv+wdrd
67、其中,rs为稠密奖励,wa为无人机空战角度奖励的权重,ra为角度奖励,w为无人机空战高度奖励的权重,rh为高度奖励,wv为无人机空战速度奖励的权重,rv为速度奖励,wd为无人机空战距离奖励对应的权重,rd为距离奖励。
68、更进一步的,所述角度奖励、高度奖励、速度奖励、距离奖励,表达式分别为:
69、
70、
71、
72、
73、其中,ata为偏离角,即红方无人机速度矢量与红蓝无人机相对位置矢量的夹角;dv表示红蓝双方无人机速度大小差,aa为脱离角,即蓝方无人机速度矢量与红蓝无人机相对位置矢量的夹角;dz表示红蓝双方无人机z轴坐标差;dmax表示无人机机载武器攻击的最大距离,dmin表示无人机机载武器攻击的最小距离,表示红蓝双方无人机相对距离的大小。
74、进一步的,所述稀疏奖励,表达式为:
75、
76、其中,rl为稀疏奖励,是双方空战每回合结束对抗的回报值。
77、更进一步,所述双方空战每回合结束对抗需满足的约束条件包括:红蓝双方无人机击中或被击中、超出仿真边界或超出每回合最大仿真步长;
78、所述红蓝双方无人机击中或被击中的约束条件表达式为:
79、
80、其中,dmin为红蓝双方无人机武器攻击的最小距离,dmax为红蓝双方无人机武器攻击的最大距离。
81、所述超出仿真边界的约束条件表达式为:
82、
83、其中,xmin为x轴仿真边界的最小值,ymin为y轴仿真边界的最小值,zmin为z轴仿真边界的最小值,xmax为x轴仿真边界的最大值,ymax为y轴仿真边界的最大值,zmax为z轴仿真边界的最大值,xr,yr,zr,表示红方在惯性坐标系下的位置坐标,xb,yb,zb表示蓝方在惯性坐标系下的位置坐标。
84、所述每回合仿真步长需满足约束条件,表达式为:
85、stepnow<stepmax
86、其中,stepmax为红蓝双方空战对抗每回合最大仿真步长,stepnow为红蓝双方空战对抗每回合仿真步长。
87、可以理解的是,课程学习是一种训练策略,模仿人类学习过程,主张让模型从容易学习的样本开始学习,逐步进阶到复杂的样本和知识。
88、优选的,步骤s4所述获得无人机空战对抗决策模型的具体步骤为:
89、基于所述空战态势评估模型对奖励函数进行重塑,获得重塑后奖励函数;
90、依据步骤s1所述无人机空战对抗运动模型以及重塑后奖励函数获取当前时刻红蓝双方无人机的状态;将步骤s2所述奖励函数基于课程学习进行改进,获取改进后的奖励函数;;
91、将所述当前时刻红蓝双方无人机的状态输入步骤s2所述马尔可夫决策过程,基于无人机空战态势评估模型、策略网络以及所述改进后的奖励函数获得当前时刻红方无人机的动作、相应动作的奖励值以及下一时刻的红蓝双方无人机的状态;
92、将当前时刻红蓝双方无人机的状态、红方无人机的动作、相应动作的奖励值以及下一时刻的红蓝双方无人机的状态作为经验数据存入经验池中;
93、依据经验池的数据,采用深度强化学习算法的梯度下降法更新价值网络和策略网络参数,获得训练后的网络空间;基于所述训练后的网络空间获得无人机空战对抗策略模型。
94、步骤s5、使用步骤s4所述无人机空战对抗策略模型进行无人机空战对抗。
95、优选的,步骤s5获得无人机空战对抗的具体包括:
96、在无人机空战对抗过程中,依据步骤s1所述无人机空战对抗运动模型获取当前时刻红蓝双方无人机的状态;
97、将当前时刻红蓝双方无人机的状态输入所述无人机空战对抗策略模型,输出无人机当前动作值,将所述无人机当前动作值表征为无人机空战对抗决策。
98、与现有技术相比,本发明至少具有如下有益效果:
99、(1)本发明面向空战对抗模型对无人机模型进行合理简化,建立了无人机三自由度质点模型,同时关注空战中动态几何要素,基于角度、高度、速度、距离要素建立空战态势评估模型,为空战决策建立基础;
100、(2)本发明采用sac算法,设计算法状态空间、动作空间、网络空间、奖励函数,通过与环境交互训练策略网络与价值网络,训练的策略网络可实现空战对抗实时决策;
101、(3)本发明结合课程学习改进训练过程,调节奖励函数中稀疏奖励与稠密奖励比重,训练前期逐步降低稠密奖励的比重,快速学习基本策略,训练后期只采用稀疏奖励,增大探索空间,提升了无人机空战对抗的胜率。
- 还没有人留言评论。精彩留言会获得点赞!