一种基于柔性轴的矢量推进器控制系统及方法
本发明涉及船舶控制,尤其是一种基于柔性轴的矢量推进器控制系统及方法。
背景技术:
1、传统的控制方法通常基于预先设计的模型或规则,对于柔性轴矢量推进器这种复杂、非线性的系统往往难以建立准确的模型,
2、离散动作空间的限制:传统控制方法中常用的离散动作空间限制了对柔性轴姿态和推力的精确控制;
3、缺乏自适应性和鲁棒性:传统控制方法通常需要事先调整参数或手动设计控制策略,对于不同工况和环境变化的适应性有限;
4、多智能体协同控制的困难:柔性轴矢量推进器系统中涉及多个推进器的协同控制是一个挑战,传统的分散式控制方法通常需要设计复杂的通信和协调机制。
5、本发明针对提出上述缺点提出解决方案为:
6、强化学习通过与环境的交互学习最优策略,不需要依赖精确的模型,能够更好地适应柔性轴推进器的特性,而强化学习算法能够根据奖励信号进行自适应调整,实时优化控制策略,并通过实时训练提高鲁棒性,采用连续动作空间处理的方法,可以更灵活地选择柔性轴的动作,并避免了离散化带来的信息损失,例如,确定性策略梯度算法能够直接输出连续的动作值,提高控制精度;
7、具体为:系统建模搭建:定义柔性轴的状态空间,并根据需求将其离散化或连续化处理,状态包括位置、姿态和推力等参数;
8、设计柔性轴的动作空间,如弯曲角度或扭转力矩的范围,确保动作空间能够覆盖所需的姿态调整和推力控制范围;
9、建立奖励函数,用于评估柔性轴在不同状态下采取的动作好坏程度,奖励函数应考虑期望位置附近的动作奖励较高、避免受到过大外部扰动等;
10、强化学习模型构建:
11、构建策略网络(actor)和价值网络(critic)的深度神经网络架构;
12、策略网络接收当前状态作为输入,并输出动作的概率分布,价值网络评估状态-动作对的价值;
13、选择适合柔性轴矢量推进器控制的强化学习算法,如ppo算法,并设置超参数;
14、训练强化学习模型:
15、初始化策略网络和价值网络的参数,并将其作为训练的初始状态;
16、在每个时间步骤中,根据当前状态使用策略网络选择动作,并执行在柔性轴上;
17、接收环境的反馈信息,包括新的状态和即时奖励;
18、使用ppo算法更新策略网络的参数,以最大化预期奖励;
19、使用蒙特卡洛方法更新价值网络的参数,减小价值估计与实际回报的差距;
20、通过不断重复以上步骤,直到达到预设的训练次数或满足收敛条件;
21、控制策略执行:
22、在训练结束后,根据训练得到的最优控制策略,利用策略网络选择最优动作;
23、根据当前状态和策略网络输出的动作,控制柔性轴矢量推进器执行相应的姿态调整和推力控制;
24、实时监测柔性轴的状态,并根据需要进行实时调整和反馈控制。
技术实现思路
1、本发明为了解决上述存在的技术问题,提供一种基于柔性轴的矢量推进器控制系统及方法。
2、本发明的技术方案是是这样实现的:一种基于柔性轴的矢量推进器控制系统及方法,包括,所述一种基于柔性轴的矢量推进器控制系统,包括系统建模模块、奖励函数模块、学习模块、训练模块、执行策略模块;
3、所述系统建模模块与奖励函数模块连接,用于定义柔性轴的状态空间和动作空间,为奖励函数模块提供基本框架;柔性轴的状态空间,包括位置、姿态和推力等参数;柔性轴的动作空间,如弯曲角度或扭转力矩范围;
4、所述奖励函数模块与系统建模模块、学习模块连接,用于评估柔性轴在不同状态和动作下的表现,考虑柔性轴的位置偏离目标位置的距离、姿态误差的大小、能耗的大小等因素;
5、所述学习模块与奖励函数模块、学习模块连接,用于构建策略网络(actor)和价值网络(critic)的深度神经网络架构;策略网络接收当前状态作为输入,并输出动作的概率分布,价值网络评估状态-动作对的价值;不断收集新的状态-动作对和奖励信号,用于在线学习和调整模型参数;
6、所述训练模块与学习模块、执行策略模块连接,用于初始化策略网络和价值网络的参数,并将其作为训练的初始状态,接收环境的反馈信息,包括新的状态和即时奖励,使用强化学习算法(如ppo)更新策略网络的参数,以最大化预期奖励,使用蒙特卡洛方法更新价值网络的参数,减小估计值与实际回报的差距;
7、所述执行策略模块与训练模块连接,用于在训练结束后,根据训练得到的最优控制策略,利用策略网络选择最优动作,根据当前状态和策略网络输出的动作,控制柔性轴矢量推进器执行相应的姿态调整和推力控制。
8、所述一种基于柔性轴的矢量推进器控制方法:
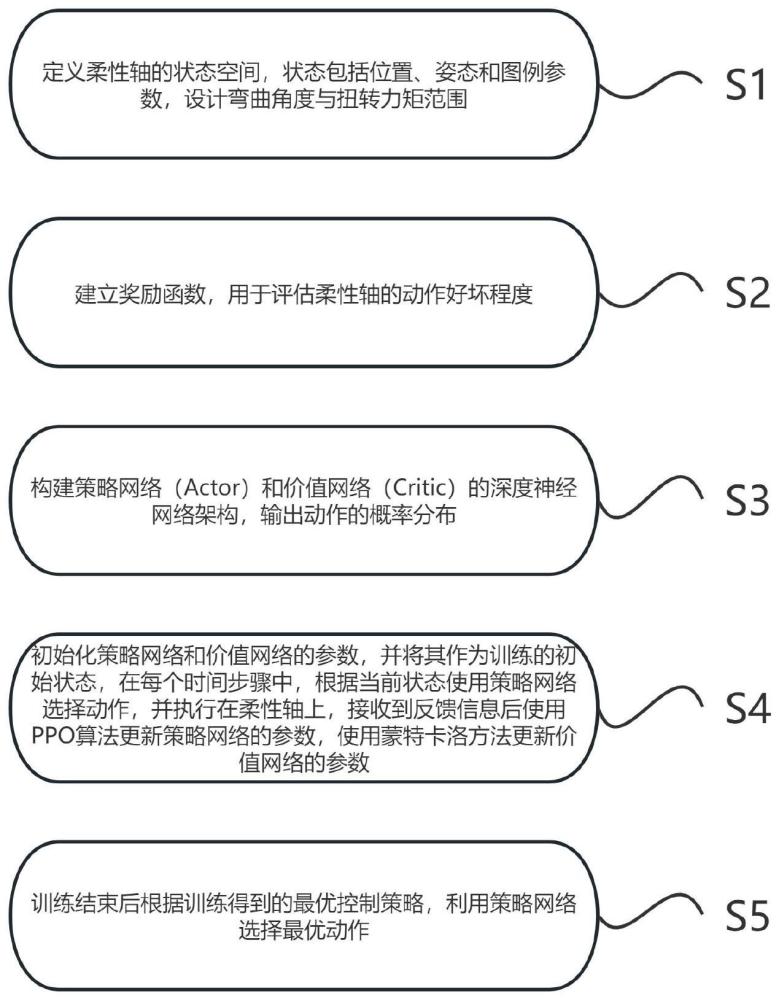
9、s1、定义柔性轴的状态空间,状态包括位置、姿态和图例参数,设计弯曲角度与扭转力矩范围;
10、s2、建立奖励函数,用于评估柔性轴的动作好坏程度;
11、s3、构建策略网络(actor)和价值网络(critic)的深度神经网络架构,输出动作的概率分布;
12、s4、初始化策略网络和价值网络的参数,并将其作为训练的初始状态,在每个时间步骤中,根据当前状态使用策略网络选择动作,并执行在柔性轴上,接收到反馈信息后使用ppo算法更新策略网络的参数,使用蒙特卡洛方法更新价值网络的参数;
13、s5、训练结束后根据训练得到的最优控制策略,利用策略网络选择最优动作。
14、具体计算过程为:
15、s1.定义柔性轴的状态空间,状态包括位置、姿态和图例参数,设计弯曲角度与扭转力矩范围:
16、柔性轴的状态空间定义为:s={p,θ,λ},其中p表示位置,θ表示姿态,λ表示图例参数;
17、弯曲角度范围设定为[-θ_max,θ_max],表示柔性轴可弯曲的最大角度;
18、扭转力矩范围设定为[-τ_max,τ_max],表示柔性轴可施加的最大扭转力矩;
19、s2.建立奖励函数,用于评估柔性轴的动作好坏程度:
20、预设柔性轴当前状态为s,执行的动作为a,即根据策略网络输出的动作概率分布选择的动作;
21、奖励函数r(s,a)用于评估柔性轴在特定状态和动作下的表现;
22、具体的奖励函数设计取决于具体任务需求,考虑柔性轴的位置偏离目标位置的距离、姿态误差的大小、能耗的大小等因素;
23、s3.构建策略网络(actor)和价值网络(critic)的深度神经网络架构,输出动作的概率分布:
24、策略网络接收柔性轴的当前状态s作为输入,并输出一个动作a的概率分布π(a|s);
25、策略网络的输出可以使用softmax函数处理,使得所有动作的概率之和为1;
26、价值网络根据柔性轴的当前状态s和动作a,估计其在当前状态下采取该动作的长期回报期望值v(s,a);
27、s4.初始化策略网络和价值网络的参数,并将其作为训练的初始状态,在每个时间步骤中,根据当前状态使用策略网络选择动作,并执行在柔性轴上,接收到反馈信息后使用ppo算法更新策略网络的参数,使用蒙特卡洛方法更新价值网络的参数:
28、初始化策略网络和价值网络的参数θ和ω;
29、在每个时间步骤t中,基于当前状态s_t,使用策略网络采样动作a_t~π(a|s_t);
30、将动作a_t应用于柔性轴上,观察环境反馈得到新的状态s_{t+1}和即时奖励r_t;
31、根据新状态s_{t+1},使用策略网络计算新动作的概率π(a|s_{t+1});
32、使用ppo算法更新策略网络的参数θ,使得通过策略梯度方法最大化期望奖励;
33、使用蒙特卡洛方法更新价值网络的参数ω,减小估计值与实际回报的差距;
34、s5.训练结束后根据训练得到的最优控制策略,利用策略网络选择最优动作:
35、在训练结束后,通过策略网络选择动作的方式来执行最优控制策略;
36、对于柔性轴的当前状态s,使用策略网络输出的动作概率分布π(a|s)来选择最优的动作a。
37、进一步地,所述预设数据带入s1-s5计算过程示例为:
38、位置p∈[-10,10]
39、姿态θ∈[-π/4,π/4]
40、图例参数λ∈[0,1]
41、弯曲角度范围设定为[-30°,30°]
42、扭转力矩范围设定为[-5,5]
43、s1.定义柔性轴的状态空间:
44、根据预设数据,我们有:
45、位置p∈[-10,10]
46、姿态θ∈[-π/4,π/4]
47、图例参数λ∈[0,1];
48、s2.建立奖励函数:
49、根据奖励函数r(s,a)来评估柔性轴在特定状态和动作下的表现,定义以下奖励函数:
50、预设目标位置为p_target,姿态目标为θ_target
51、定义位置奖励:reward_p=exp(-0.1*|p-p_target|)
52、定义姿态奖励:reward_θ=exp(-0.5*|θ-θ_target|)
53、定义能耗奖励:reward_λ=1-λ^2
54、s3.构建策略网络(actor)和价值网络(critic)的深度神经网络架构:
55、根据预设数据构建策略网络(actor)和价值网络(critic)的深度神经网络架构,使用多层感知机(mlp)来实现这两个网络;
56、s4.初始化策略网络和价值网络的参数,并进行训练:
57、预设已经根据预设数据构建了策略网络和价值网络的深度神经网络架构;
58、初始化策略网络和价值网络的参数θ和ω;
59、在每个时间步骤t中,根据当前状态s_t使用策略网络选择动作a_t~π(a|s_t);
60、将动作a_t应用于柔性轴上,观察环境反馈得到新的状态s_{t+1}和即时奖励r_t;
61、根据新状态s_{t+1},使用策略网络计算新动作的概率π(a|s_{t+1});
62、使用ppo算法更新策略网络的参数θ,以最大化期望奖励;
63、使用蒙特卡洛方法更新价值网络的参数ω,减小估计值与实际回报的差距;
64、s5.训练结束后,根据训练得到的最优控制策略选择最优动作:
65、在训练结束后,利用策略网络选择最优动作来执行最优控制策略;
66、对于柔性轴的当前状态s,使用策略网络输出的动作概率分布π(a|s)来选择最优的动作a。
67、进一步地,所述s3步骤中构建策略网络(actor)和价值网络(critic)的深度神经网络架构:
68、下面是构建策略网络(actor)和价值网络(critic)的具体实现步骤:
69、定义输入和输出:
70、输入:柔性轴的状态空间变量,例如位置p、姿态θ和图例参数λ;
71、输出:根据动作空间的定义,设计一个包含每个动作的概率的向量,预设动作空间有n个动作,则输出为一个长度为n的向量;
72、构建策略网络(actor):
73、使用深度神经网络模型,多层感知机(mlp),作为策略网络;
74、将柔性轴的状态空间作为输入传递给网络;
75、在输出层使用softmax函数来生成动作的概率分布;
76、构建价值网络(critic):
77、使用深度神经网络模型,多层感知机(mlp),作为价值网络;
78、将柔性轴的状态空间和执行的动作作为输入传递给网络;
79、输出一个估计的长期回报期望值,表示柔性轴在给定状态和动作下的预期收益;
80、初始化网络参数:
81、随机初始化策略网络(actor)和价值网络(critic)的参数;
82、前向传播:
83、将当前状态s作为输入,通过策略网络(actor)获得动作概率分布π(a|s);
84、将当前状态s和执行的动作a作为输入,通过价值网络(critic)估计长期回报期望值v(s,a);
85、反向传播和更新参数:
86、根据环境反馈信息,计算损失函数,并进行反向传播;
87、使用优化算法(如随机梯度下降法)来最小化损失函数,更新策略网络(actor)和价值网络(critic)的参数。
88、进一步地,所述在s4步骤中,我们使用ppo算法更新策略网络的参数θ以最大化期望奖励,同时使用蒙特卡洛方法更新价值网络的参数ω来减小估计值与实际回报的差距,下面是它们的作用和实际实现过程:
89、ppo算法更新策略网络的参数θ:
90、ppo(proximal policy optimization)算法是策略梯度算法,用于更新策略网络的参数θ;
91、目标是通过最大化期望奖励来改进策略网络的输出,使其能够选择更优的动作;
92、ppo算法采用kl散度来限制策略网络的更新范围,以确保更新不会太远离当前策略;
93、具体实现过程:
94、在每个时间步骤t中,根据环境反馈信息计算出损失函数;
95、使用ppo算法的更新规则对损失函数进行优化,得到更新后的策略网络参数θ;
96、优化过程中采用优化算法,随机梯度下降法(sgd);
97、重复进行多次训练迭代,直到达到一定的收敛条件或训练次数;
98、蒙特卡洛方法更新价值网络的参数ω:
99、蒙特卡洛方法是一种基于样本回报的估计方法,用于更新价值网络的参数ω,以减小估计值与实际回报的差距;
100、通过使用历史的样本轨迹来估计状态-动作对的回报,并利用这些回报来调整价值网络的参数;
101、具体实现过程:
102、在每个时间步骤t中,根据环境反馈信息(包括新的状态和即时奖励)进行采样;
103、使用蒙特卡洛方法计算出样本轨迹中每个状态-动作对的长期回报,作为实际回报的估计;
104、利用这些回报和对应的状态-动作对来进行训练,更新价值网络的参数ω;
105、使用强化学习算法,如均方误差损失函数、td(λ),来优化价值网络;
106、综上所述,ppo算法和蒙特卡洛方法在s4步骤中的作用是分别用于更新策略网络的参数θ和价值网络的参数ω。
107、进一步地,根据上述内容阐述ppo算法控制更新步长,利用kl散度来限制策略网络的更新范围,以确保更新不会太远离当前策略,下面是更详细的说明:
108、kl散度:kl散度(kullback-leibler divergence)是一种衡量两个概率分布之间差异的度量方式,在ppo算法中使用kl散度来度量更新前后策略网络输出动作概率分布的差异;
109、限制更新范围:
110、为了控制更新步长,ppo算法使用通过最大化受限的kl散度来限制策略网络的更新范围,
111、具体而言,引入一个超参数ε,表示允许的最大kl散度值;
112、ppo算法中的ppo clip函数:
113、在ppo算法中,更新时采用的是ppo clip函数,该函数可以将更新的步长限制在一个合理的范围内,避免过大的策略变动;
114、具体实现过程如下:
115、在每次更新时,计算更新前后的策略网络输出动作概率分布的kl散度;
116、如果kl散度小于某个阈值(例如超参数ε),则可以直接进行参数更新;
117、如果kl散度超过阈值,需要对更新步长进行限制,这时候使用ppo clip函数来剪裁策略网络输出动作概率分布的比例,确保在更新时不会走得太远离当前策略;
118、ppo clip函数的具体形式为:
119、l_clip=min(r_t*a_t,clip(r_t,1-ε,1+ε)*a_t)
120、其中,r_t表示更新前后的策略网络输出动作概率分布的比例,a_t表示优势估计,即实际回报与价值网络预测值之差;
121、通过ppo clip函数,控制更新步长在一个合理的范围内,使得策略网络更新不会过于剧烈地改变,从而稳定地最大化期望奖励;
122、ppo算法利用kl散度和ppo clip函数来控制策略网络的更新步长,以确保更新不会太远离当前策略,这样可以平衡新旧策略之间的权衡,使得策略网络能够选择更优的动作,并稳定地提高性能。
123、有益效果
124、强化学习是一种通过与环境的交互学习最优策略的方法,它不需要依赖精确的模型,这使得它能够更好地适应柔性轴推进器的特性,与传统方法相比,强化学习算法可以根据奖励信号进行自适应调整,并实时优化控制策略,此外,通过实时训练,强化学习算法还能够提高系统的鲁棒性;
125、为了处理柔性轴推进器的连续动作空间,采用连续动作空间处理的方法,其中,确定性策略梯度算法能够直接输出连续的动作值,从而提高控制精度,具体而言,通过定义柔性轴的状态空间和动作空间来实现这一点;
126、首先,在系统建模阶段,定义了柔性轴的状态空间,包括位置、姿态和推力等参数,根据需求,将状态空间离散化或连续化处理;
127、然后,设计柔性轴的动作空间,如弯曲角度或扭转力矩的范围,确保动作空间能够覆盖所需的姿态调整和推力控制范围;
128、接下来,建立奖励函数,用于评估柔性轴在不同状态下采取的动作好坏程度,奖励函数应考虑期望位置附近的动作奖励较高,并避免受到过大外部扰动等因素的影响;
129、为了构建强化学习模型,设计策略网络(actor)和价值网络(critic)的深度神经网络架构,策略网络接收当前状态作为输入,并输出动作的概率分布;而价值网络评估状态-动作对的价值;
130、在训练阶段,我们首先初始化策略网络和价值网络的参数,并将其作为训练的初始状态,然后,在每个时间步骤中,根据当前状态使用策略网络选择动作,并执行在柔性轴上,接收到环境的反馈信息后,使用ppo算法更新策略网络的参数,以最大化预期奖励,同时,使用蒙特卡洛方法更新价值网络的参数,减小估计值与实际回报的差距;
131、训练结束后,根据训练得到的最优控制策略,利用策略网络选择最优动作,根据当前状态和策略网络输出的动作,控制柔性轴矢量推进器执行姿态调整和推力控制。
132、工作原理:
133、首先,通过系统建模模块,定义柔性轴的状态空间和动作空间,并提供基本框架,柔性轴的状态空间包括位置、姿态和图例参数等参数,而动作空间则定义了可行的动作范围,例如弯曲角度或扭转力矩;
134、接着,奖励函数模块根据系统建模模块提供的状态空间和动作空间,评估柔性轴在不同状态和动作下的表现,奖励函数考虑了柔性轴的位置偏离目标位置的距离、姿态误差的大小以及能耗的大小等因素;
135、然后,学习模块利用奖励函数模块的评估结果,构建策略网络(actor)和价值网络(critic)的深度神经网络架构,策略网络接收当前状态作为输入,并输出动作的概率分布;而价值网络则评估状态-动作对的价值;
136、在训练模块中,首先初始化策略网络和价值网络的参数,然后,在每个时间步骤中,根据当前状态使用策略网络选择动作,并执行在柔性轴上,接收到环境的反馈信息后,使用ppo算法更新策略网络的参数θ,以最大化预期奖励,同时,利用蒙特卡洛方法更新价值网络的参数ω,减小估计值与实际回报的差距;
137、最后,在执行策略模块中,根据训练得到的最优控制策略,利用策略网络选择最优动作,根据当前状态和策略网络输出的动作,控制柔性轴矢量推进器执行相应的姿态调整和推力控制;
138、基于柔性轴的矢量推进器控制系统通过建模、奖励函数、学习、训练和执行策略等步骤,实现对柔性轴的控制,系统通过定义状态空间和动作空间,利用深度神经网络进行策略评估和优化,并通过ppo算法和蒙特卡洛方法来更新策略网络和价值网络的参数,这样,在训练结束后,该系统能够根据最优控制策略,选择最佳动作来控制柔性轴的姿态和推力,以满足所需的任务要求。
- 还没有人留言评论。精彩留言会获得点赞!