一种基于强化学习的船舶循迹航行的方法与流程
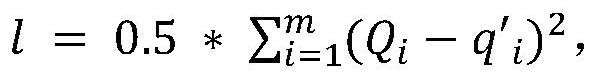
本发明属于航海与人工智能,涉及一种基于强化学习的船舶循迹航行的方法。
背景技术:
1、远洋航运中使用的传统自动舵通过惯导陀螺仪与卫星系统定位,运用程控方法操作船舶在既定的航行轨迹航行,然而由于海上风、浪、洋流的干扰这种方法往往并不精确,会产生较大的偏离并需要不断矫正,因此船舶的实际航行轨迹会在目标轨迹两侧来回摆荡,这会增加大量非必要航程,降低航运效率、浪费燃料并产生不必要的排碳。尽管也有通过提升定位与矫正频率来减轻这一问题的做法,但过于频繁船舵操作(尤其是连续反向打舵)会加速舵机系统的机械老化,较少设备的使用寿命和可靠工时,怎加维护成本。
技术实现思路
1、本发明提出了一种基于强化学习的船舶循迹航行的方法,旨在解决传统自动舵在海上风、浪、洋流干扰下精度不高、降低效率,以及船舵过度操作导致的设备老化问题。
2、本发明解决上述问题所采用的技术方案是:一种基于强化学习的船舶循迹航行的方法,其特征在于:包括如下步骤:
3、一、构建坐标序列;
4、对航行中的目标轨迹等距采样后,将其表示为由离散的采样点所构成的坐标序列,具体步骤为:设海平面为由x,y轴所构成的二维平面,则目标轨迹的函数为y=f(x),x′0≤x≤x′m,x′0和x′m分别为x的取值上下限,等距采样后,目标轨迹表示为由离散的采样点所构成的坐标序列:[(x′i,y′i)|i=0...m];采样过程中,将目标轨迹分割成若干分段依次进行采样处理;
5、二、构建船舵操作模型;
6、基于q网络构建船舵操作模型;船舵操作模型输入的船舶航行的状态s为:代表风、浪、洋流的强度与方向的矢量(vwi,vwa,vcu)、船的当前坐标(xt,yt)、船舶的推进速度矢量vpr,以及舵位相对于船的反向延长单位矢量以及坐标序列[(x′i,y′i)|i=0...m]所构成的向量[x′0,y′o,...,x′m,y′m];船舵操作模型输出为船舵操作指令集;
7、三、模型强化学习训练;
8、采用深度q网络的强化学习训练策略来训练船舵操作模型;
9、四、循迹航行;
10、在航行过程中,如果船舶未能行驶到目标轨迹前一段终点(即为后一分段起点),则需对之后的路径重新规划,而如果出现单一分段内船舶检测出现任何环境因素的突变则仅需以当前点为起点,无需重新规划路径。船舶在使用模型循迹过程中,在分段路径内每一时间点(时间点采样频率由各传感器最小采样频率与船载算力而定),通过将船载传感器实时检测到的风、浪、流数据与推进系统所给出的速度矢量、船舶坐标等测量数据输入船舵操作模型,船舵操作模型给出向左打舵、向右打舵、或保持舵位的船舵等操作指令,从而操控船舶沿轨迹行驶。
11、本发明步骤一中,分割点(x′i,y′i)的选择标准如下:
12、(x′i-x′i-1)(x′i+1-x′i)(y′i-y′i-1)(y′i+1-y′i)<0。
13、本发明所述的船舵操作指令集为:{“向左”,“向右”,“不变”}。
14、本发明步骤三具体步骤如下:
15、1.预设若干个模拟场景,每个模拟场景中船推进速度、目标轨迹以及风、浪、洋流的流向和强度各不同但都保持不变;
16、2.初始化大小为h的重放缓冲区h;
17、3.对于所有的状态s和动作a,随机初始化q网络q(s,a;θ)的权重θ;
18、4.对于所有的状态s和动作a,用与q网络相同的权重初始化目标网络q’q′(s,a;θ′),θ′=θ;
19、在每个模拟场景下重复进行以下操作直至k次或收敛:
20、a.将环境重置为初始状态;
21、b.对于每个时间步t进行以下操作:
22、i.使用基于q网络的贪心ε策略选择动作a;
23、ii.执行动作a并观察下一个状态s′和奖励r;
24、iii.将转换元组(s,a,r,s′)存储在重放缓冲区h中:
25、h.push((s,a,r,s′));
26、iv.从重放缓冲区中随机抽取m个转换元组:(si,ai,ri,s′i)~h,i=1...m;
27、v.对于所有的ai,使用目标网络q′计算每个转换的q′i值:
28、q′i=ri+γ*max q′(s′i,a′i;θ′);
29、其中a′i为下一个状态s′i时q′值最大的下一个行动;
30、vi.使用q网络计算每个转换预测q值的qi:
31、qi=q(si,ai;θ),i=1...m;
32、vii.使用预测和目标q值之间的均方作为损失函数:
33、
34、并使用损失函数l来更新q网络权重为:其中α为学习率,为损失函数l对θ的梯度;
35、viii.每s步,更新目标网络权重以匹配q’网络权重:θ′=θ;
36、ix.将当前状态设置为下一个状态:s=s′;
37、c.随着时间的推移将ε减小为:ε*μ,0<μ<1。
38、本发明步骤三的训练过程中,在t时船的坐标为(xt,yt),而目标轨迹上离船最近一点为(x′s(t),y′s(t));奖惩函数r由轨迹偏离惩罚函数roff、过度操作惩罚函数rod和到达目标时间奖励函数rgtime的加权合:
39、r=aroff+brod+crgtime,a、b、c为权重。
40、本发明轨迹偏离惩罚函数p为超参数。
41、本发明过度操作惩罚函数rod为:
42、
43、本发明到达目标轨迹的耗时奖励函数rgtime为:
44、
45、其中ttotal为船实际到达目标轨迹终点的时间,t为目标轨迹长度除以船的途径速度。
46、本发明步骤三的训练过程中,单轮训练过程中只考虑一个目标轨迹的分段,即将各分段视为不同的训练场景,当前场景的终点同时也是先一个场景的起点,并假设分段内环境因素与船舶的推进速度不变。
47、本发明步骤b-i中,1-ε概率选择的a为最优动作,ε概率选择的a为随机动作。
48、本发明与现有技术相比,具有以下优点和效果:可操作船舶在不同的风、浪、洋流的干扰条件下,高精度循迹航行,并尽量保障操作的平滑性以提升舵机设备机械寿命,实现在不同的干扰条件下高精度循迹航行与平滑的船舵操作,可以提高船舶自动循迹航行的精度、减少能源消耗和排放,并降低舵机老化,具有广泛的应用前景。
技术特征:
1.一种基于强化学习的船舶循迹航行的方法,其特征在于:包括如下步骤:
2.根据权利要求1所述的基于强化学习的船舶循迹航行的方法,其特征在于:步骤一中,分割点(x′i,y′i)的选择标准如下:
3.根据权利要求1所述的基于强化学习的船舶循迹航行的方法,其特征在于:所述的船舵操作指令集为:{“向左”,“向右”,“不变”}。
4.根据权利要求1所述的基于强化学习的船舶循迹航行的方法,其特征在于:步骤三具体步骤如下:
5.根据权利要求1所述的基于强化学习的船舶循迹航行的方法,其特征在于:步骤三的训练过程中,在t时船的坐标为(xt,yt),而目标轨迹上离船最近一点为(x′s(t),y′s(t));奖惩函数r由轨迹偏离惩罚函数roff、过度操作惩罚函数rod和到达目标时间奖励函数rgtime的加权合:
6.根据权利要求5所述的基于强化学习的船舶循迹航行的方法,其特征在于:
7.根据权利要求5所述的基于强化学习的船舶循迹航行的方法,其特征在于:过度操作惩罚函数rod为:
8.根据权利要求5所述的基于强化学习的船舶循迹航行的方法,其特征在于:到达目标轨迹的耗时奖励函数rgtime为:
9.根据权利要求5所述的基于强化学习的船舶循迹航行的方法,其特征在于:步骤三的训练过程中,单轮训练过程中只考虑一个目标轨迹的分段,即将各分段视为不同的训练场景,当前场景的终点同时也是先一个场景的起点,并假设分段内环境因素与船舶的推进速度不变。
10.根据权利要求4所述的基于强化学习的船舶循迹航行的方法,其特征在于:步骤b-i中,1-ε概率选择的a为最优动作,ε概率选择的a为随机动作。
技术总结
本发明提出了一种基于强化学习的船舶循迹航行的方法,旨在解决传统自动舵在海上风、浪、洋流干扰下精度不高、降低效率,以及船舵过度操作导致的设备老化问题。本发明包括如下步骤:一、构建坐标序列;二、构建船舵操作模型;三、模型强化学习训练;四、循迹航行。
技术研发人员:沈敏行,梁鑫,常涛,刘志豪
受保护的技术使用者:浙江省智能船舶研究院有限公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!