网络训练方法、无人机避障方法及装置
本发明涉及无人机控制,尤其涉及一种网络训练方法、无人机避障方法及装置。
背景技术:
1、无人机避障问题可以描述为无人机在一个存在障碍物的空间中导航的任务。任务通常遵循一些优化标准,如工作成本最小、飞行距离最短、飞行时间最短等。常见的传统避障方法包括:动态规划算法、人工势场法、基于采样的方法以及基于图论的方法,但这些方法却需要根据不同的情况建立不同的模型。然而在实际的无人机飞行环境中,工作环境复杂且不可预测,往往需要无人机在未知环境中进行探测并实时决策。
2、随着人工智能技术的进步,强化学习在游戏、机器人、互联网等领域的应用日益广泛,引起了广泛关注。无模型强化学习是一种常用的解决未知环境决策的方法,已经广泛应用于无人机的避障问题中。但是由于无人机与环境的相互交互作用有限,导致无模型强化学习的样本利用率低和自主学习效率低,进而导致无人机避障性能较差。
技术实现思路
1、本发明提供一种网络训练方法、无人机避障方法及装置,用以解决现有技术中无人机与环境的相互交互作用有限,导致无模型强化学习的样本利用率低和自主学习效率低,进而导致无人机避障性能较差的缺陷,实现提高无人机避障中的自主学习效率和样本利用率,以提高无人机避障性能。
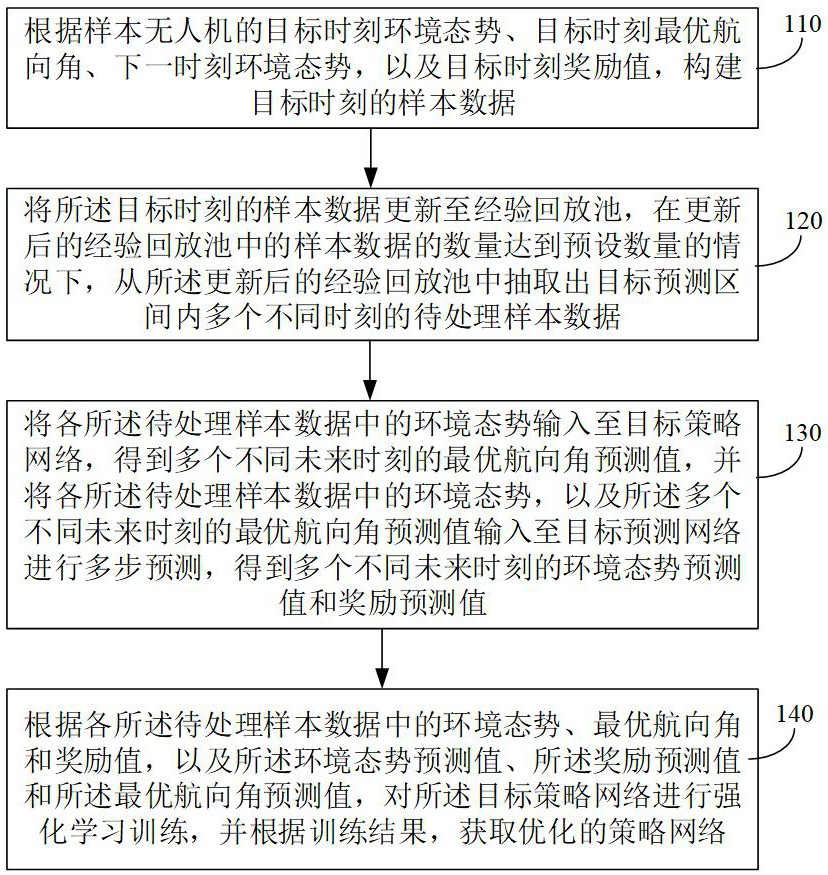
2、本发明提供一种网络训练方法,包括:
3、根据样本无人机的目标时刻环境态势、目标时刻最优航向角、下一时刻环境态势,以及目标时刻奖励值,构建目标时刻的样本数据;
4、将所述目标时刻的样本数据更新至经验回放池,在更新后的经验回放池中的样本数据的数量达到预设数量的情况下,从所述更新后的经验回放池中抽取出目标预测区间内多个不同时刻的待处理样本数据;
5、将各所述待处理样本数据中的环境态势输入至目标策略网络,得到多个不同未来时刻的最优航向角预测值,并将各所述待处理样本数据中的环境态势,以及所述多个不同未来时刻的最优航向角预测值输入至目标预测网络进行多步预测,得到多个不同未来时刻的环境态势预测值和奖励预测值;
6、根据各所述待处理样本数据中的环境态势、最优航向角和奖励值,以及所述环境态势预测值、所述奖励预测值和所述最优航向角预测值,对所述目标策略网络进行强化学习训练,并根据训练结果,获取优化的策略网络;
7、其中,所述优化的策略网络用于基于当前无人机的当前时刻环境态势预测所述当前无人机的当前时刻最优航向角,以供所述当前无人机根据所述当前时刻最优航向角执行避障任务。
8、根据本发明提供的一种网络训练方法,所述目标时刻环境态势和所述目标时刻最优航向角是基于如下步骤获取的:
9、根据所述样本无人机的目标时刻位置、半径和目的地位置,障碍物的目标时刻位置、目标时刻速度和半径,以及所述样本无人机与所述障碍物之间的目标时刻距离,确定所述目标时刻环境态势;
10、将所述目标时刻环境态势输入至所述目标策略网络,得到所述目标时刻最优航向角。
11、根据本发明提供的一种网络训练方法,所述下一时刻环境态势是基于如下步骤获取的:
12、根据无人机动力学约束模型、运动学约束和扰动流场法,计算得到所述样本无人机的下一时刻位置;
13、根据所述样本无人机的下一时刻位置、半径和目的地位置,障碍物的下一时刻位置、下一时刻速度和半径,以及所述样本无人机与所述障碍物之间的下一时刻距离,确定所述下一时刻环境态势。
14、根据本发明提供的一种网络训练方法,所述目标时刻奖励值是基于如下步骤获取的:
15、在所述样本无人机与障碍物之间的目标时刻距离小于第一距离值的情况下,根据所述样本无人机与所述障碍物之间的目标时刻距离、所述样本无人机的半径、所述障碍物的半径,以及第一奖励值,确定所述目标时刻奖励值;
16、在所述样本无人机与所述障碍物之间的目标时刻距离大于或等于所述第一距离值,且所述样本无人机与目的地位置之间的目标时刻距离小于第二距离值的情况下,根据所述样本无人机与所述目的地位置之间的目标时刻距离、所述样本无人机的起点位置与所述目的地位置之间的距离,以及第二奖励值和第三奖励值,确定所述目标时刻奖励值;
17、在所述样本无人机与所述障碍物之间的目标时刻距离大于或等于所述第一距离值,且所述样本无人机与所述目的地位置之间的目标时刻距离大于或等于所述第二距离值的情况下,根据所述样本无人机与所述目的地位置之间的目标时刻距离、所述样本无人机的起点位置与所述目的地位置之间的距离,以及所述第三奖励值,确定所述目标时刻奖励值;
18、其中,所述第一奖励值为常值奖励值;所述第二奖励值为用于限制所述样本无人机远离所述障碍物的威胁奖励;所述第三奖励值为任务完成对应的附加奖励值。
19、根据本发明提供的一种网络训练方法,所述第二奖励值是基于如下步骤确定的:
20、在所述样本无人机与所述障碍物之间的目标时刻距离大于或等于所述第一距离值,且小于第三距离值的情况下,基于所述样本无人机与所述障碍物之间的目标时刻距离、所述样本无人机的半径、所述障碍物的半径、预设威胁半径和第四奖励值,确定所述第二奖励值;
21、在所述样本无人机与所述障碍物之间的目标时刻距离小于所述第一距离值,或者大于或等于所述第三距离值的情况下,基于预设常数值,确定所述第二奖励值。
22、根据本发明提供的一种网络训练方法,所述将各所述待处理样本数据中的环境态势,以及所述多个不同未来时刻的最优航向角预测值输入至目标预测网络进行多步预测,得到多个不同未来时刻的环境态势预测值和奖励预测值,包括:
23、将各所述待处理样本数据中的环境态势和所述最优航向角预测值输入至所述目标预测网络的奖励函数网络,以及将各所述待处理样本数据中的环境态势和所述最优航向角预测值输入至所述目标预测网络的态势转移函数网络,进行多步预测,得到所述奖励函数网络输出的所述奖励预测值和所述态势转移函数网络输出所述环境态势预测值。
24、根据本发明提供的一种网络训练方法,所述根据各所述待处理样本数据中的环境态势、最优航向角和奖励值,以及所述环境态势预测值、所述奖励预测值和所述最优航向角预测值,对所述目标策略网络进行强化学习训练,包括:
25、根据各所述待处理样本数据中的最优航向角,以及所述最优航向角预测值、所述环境态势预测值和所述奖励预测值,获取值函数代价函数;
26、根据所述最优航向角预测值和所述环境态势预测值,获取策略代价函数;
27、根据各所述待处理样本数据中的环境态势和所述环境态势预测值,获取态势转移代价函数;
28、根据各所述待处理样本数据中的奖励值和所述奖励预测值,获取奖励代价函数;
29、根据所述值函数代价函数、所述策略代价函数、所述态势转移代价函数以及所述奖励代价函数,对所述目标策略网络进行强化学习。
30、本发明还提供一种无人机避障方法,包括:
31、获取当前无人机的当前时刻环境态势;
32、将所述当前时刻环境态势输入至优化的策略网络,得到所述当前无人机的当前时刻最优航向角;
33、根据所述当前时刻最优航向角,控制所述当前无人机执行避障任务;
34、其中,所述优化的策略网络是基于如上述任一项所述网络训练方法训练得到。
35、本发明还提供一种网络训练装置,包括:
36、构建单元,用于根据样本无人机的目标时刻环境态势、目标时刻最优航向角、下一时刻环境态势,以及目标时刻奖励值,构建目标时刻的样本数据;
37、抽取单元,用于将所述目标时刻的样本数据更新至经验回放池,在更新后的经验回放池中的样本数据的数量达到预设数量的情况下,从所述更新后的经验回放池中抽取出目标预测区间内多个不同时刻的待处理样本数据;
38、预测单元,用于将各所述待处理样本数据中的环境态势输入至目标策略网络,得到多个不同未来时刻的最优航向角预测值,并将各所述待处理样本数据中的环境态势,以及所述多个不同未来时刻的最优航向角预测值输入至目标预测网络进行多步预测,得到多个不同未来时刻的环境态势预测值和奖励预测值;
39、优化单元,用于根据各所述待处理样本数据中的环境态势、最优航向角和奖励值,以及所述环境态势预测值、所述奖励预测值和所述最优航向角预测值,对所述目标策略网络进行强化学习训练,并根据训练结果,获取优化的策略网络;
40、其中,所述优化的策略网络用于基于当前无人机的当前时刻环境态势预测所述当前无人机的当前时刻最优航向角,以供所述当前无人机根据所述当前时刻最优航向角执行避障任务。
41、本发明还提供一种无人机避障装置,包括:
42、获取单元,用于获取当前无人机的当前时刻环境态势;
43、决策单元,用于将所述当前时刻环境态势输入至优化的策略网络,得到所述当前无人机的当前时刻最优航向角;
44、避障控制单元,用于根据所述当前时刻最优航向角,控制所述当前无人机执行避障任务;
45、其中,所述优化的策略网络是基于如上述任一项所述网络训练方法训练得到。
46、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述网络训练方法,或者如上述任一种所述无人机避障方法。
47、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述网络训练方法,或者如上述任一种所述无人机避障方法。
48、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述网络训练方法,或者如上述任一种所述无人机避障方法。
49、本发明提供的网络训练方法、无人机避障方法及装置,通过从经验回放池中抽取出多个不同时刻的待处理样本数据,并且基于目标策略网络以及目标预测网络对各待处理样本数据进行预测,得到多个不同未来时刻的最优航向角预测值、环境态势预测值和奖励预测值,以基于各待处理样本数据中的环境态势、最优航向角和奖励值,以及未来时刻的环境态势预测值、奖励预测值和最优航向角预测值,对目标策略网络进行滚动优化,不仅可以实现通过目标预测网络的虚拟环境数据生成来扩充样本数据的数量,以减少与真实环境的交互次数,提高样本利用率,加快训练速度,提高学习效率,进而使得无人机在与环境交互次数更少的情况下目标策略网络可以快速收敛到最优;还可以使得优化的决策模型既具备当前决策经验,又具备未来决策经验,以便做出更加优化的无人机避障决策,由此提高无人机避障性能。
- 还没有人留言评论。精彩留言会获得点赞!