机密信息识别方法和信息处理装置与流程
本发明涉及识别机密信息的技术,更详细地,涉及指定在信息处理装置积蓄的记录中包括的机密信息的技术。
背景技术:
近年来,各种信息经由因特网、局域网、LAN等的网络来共享,信息的利用性和访问性提高。为了在因特网等中管理信息,和对信息的利用者提供信息,利用管理应该提供内容等的服务器。服务器从经由网络连接的客户端装置接受访问,进行请求的内容的提供、利用者登记、个人信息的登记/变更等的处理。作为与网络连接的服务器,使用能够通过SMTP接收电子邮件的发送和接收的邮件服务器、HTTP协议进行Web服务,因此,除了安装CGI等的Web服务器、FTP服务器等之外,还可列举出管理各种数据,应答访问请求并提供数据的数据库服务器等。这些服务器,每次实行处理时,积蓄访问的用户的信息、认证结果、为了处理而发送的数据内容、实行结果等。积蓄的信息,根据服务器的类型有不同内容,包括:访问源的IP地址、访问源的域名、被访问的日期和时刻、被访问的文件名、链接源的页的URL、访问者的Web浏览器名和/或OS名、处理花费的时间、接收字节数、发送字节数、服务状态编码等。以下,将通过服务器等的信息处理装置的工作积蓄的、积蓄工作相关的信息的文件仅作为记录来参照。服务器生成的记录,如上述,高密度地包含利用值高的信息,还有,通过记录分析,能适用于服务器的例如分散DoS攻击的所谓恶意攻击的履历、不正当访问的履历、访问内容的统计分析等的市场分析等。还有,记录涉及近年来屡次发生的服务器的不正当访问等,通过横向地分析由多个组织取得的记录,还能够用于正确地掌握网络上的攻击者的时系列的及目标的推移的信息。然而,由于记录包含上述网络的基本信息和/或个人信息,在记录分析取决于外部分析者的情况下,和/或,在记录跨越多个域的情况下,即使是有可靠性的域也可能产生因记录公开导致的泄漏风险。在图10,例示地示出使用Apache2.0安装的Web服务器的访问记录1000及FTP服务器的事务记录1100。再者,图10中,关于网络信息和/或私人信息、端口信息,由于隐藏的目的,用星号“*”置换表示。在如图10所示的记录中,除了服务器的固定IP地址、使用的端口号、所谓目录分层结构的服务器的基础信息之外,还包含用户ID的所谓私人信息和/或密码等机密性的极高的信息。然而,在有登记多种信息的可能性的记录中,在任意位置可包含机密性高的信息,存在根据记录的内容而不同这样的问题。例如,如图10所示的记录原样提供到外部,因为向外部提供企业和组织的网络信息和服务器信息、个人信息等,所以可生成其自身、企业风险。还有,在记录被有恶意的攻击者泄露情况下,企业积蓄的高附加值的信息被破坏,还考虑到由于黑客被盗用的忧虑,以及,被认为是DoS攻击等的目标。因此,对利用服务器的企业和组织来说,将记录按其原样提供给外部分析,作为能得到有用的信息的代价,产生机密泄漏、隐私信息泄漏、由向服务器的不正当访问的信息泄漏等高的风险。根据这样的理由,即使以解析向服务器的访问履历,反映服务器的功能为目的,向记录的第三者的公开时,存在因秘密保持契约而不能提供的高的屏障,成为灵活的记录解析的时候的阻碍的主要原因。还有,即使从记录信息特定了机密性高的信息,若通过访问机密性高的信息来一并置换,存在访问者的相同性和访问的数据的相同性等失去的情况,为了隐藏记录的信息,优选地能识别出原来的数据的属性和相同性等。至此,已知判断记录的机密度的方法,例如,在特开2009-116680号公报(专利文献1)中记载了通过机器学习高精度地判断数据类型的技术,其中,关于向计算机输入输出的数据简便且高精度地检测机密性的有无等的数据类型,以提供有助于数据的适当管理的技术为目的,包括:输入输出数据的读入装置;取得输入输出数据中包括的字符串的数据内容取得装置;将字符串、及其中包含的预定的字符群作为特征而提出的特征提出装置;在外存储器中,设置使用预先数据类型已知的教师数据并参照机器学习的数据类型学习结果来判断特征的数据类型的数据类型判断装置。专利文献1记载的方法也能判断记录内的信息的机密性。然而,由于利用教导数据,对于教导数据不包括的信息则不能进行机密性的判断,存在产生机密信息的泄漏的忧虑。此外,根据正则表达式和单词列表检测机密字的技术,在正则表达式的类型的登记和单词列表的登记等、数据结构的工作量很大和在单词遗漏等的方面有限制,因此不能说是十分有效。还有,关于记录,考虑事先定义完全的方案,而且还据此将机密信息匿名化,但是,因为制作的记录的多样性,完全制作多种多样的方案也不现实。还有,有可能补充单词列表和方案,甚至是罕见的名字,此外,需要对应于用户ID、密码的打字错误和输入位置的错误等,登记错误输入的信息的记录。【现有技术文献】【专利文献1】特开2009-116680号公报
技术实现要素:
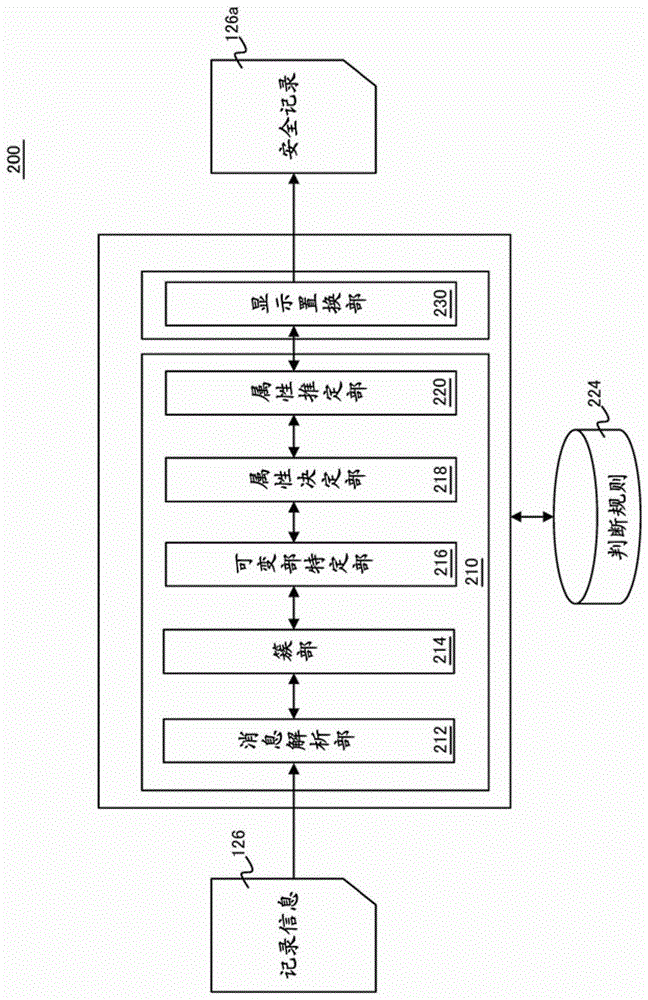
本发明鉴于上述的现有技术的问题而做出,作为课题提出一种机密信息识别方法、信息处理装置、和程序,通过识别记录内包括的机密信息,不损坏记录的有用性,能够扩大记录的利用性。本发明为了解决上述课题,识别记录内的个别信息是否为机密信息。在记录内的个别信息的机密性的判断,根据消息的类似性将记录的消息进行簇划分,比较各簇包括的消息,由此从其差别识别信息的固定部分和可变部分。并且关于可变部分的各个,参照在判断规则中登记的语言、串列或编码信息判断机密度。并且,根据在判断规则中登记的语言、串列或编码信息判断为机密的语言、串列、编码信息出现的位置,作为该簇内的消息中的、应该为机密的部分来判断。也向该簇内的其他消息传播这个判断。即,在该簇内的其他消息中,应该为机密部分所在的字符串,即使根据判断规则没判断为机密的情况,也能判断为机密。并且,在该簇内的其他消息中,通过在判断规则中登记应该为机密部分所在的字符串,在同样的字符串在其他的消息中出现的场合,也能判断为机密。机密区域和被判断的区域,按适合各个的信息的形式用其他显示置换。置换,若完全掩蔽信息,则如图10表示地信息量变少,作为记录的有用性显著地下降,因此尽可能用同等的显示置换与原来的信息相同的类型或具有意义一致的语义。由于用与原来的信息相同的类型或意义一致的显示置换,能判断信息的类型,并且能用可以相同的形式置换。例如,如果是人名,其他的名字,例如,"Alice"→“Cathy","Bob"→“David"所谓别名匹配。还有,例如IP地址等时,留下IP地址的网络结构的特定部分,将其他的部分用具有构成私人IP地址等的正则表达式给予的一定的规则的编码信息等置换,由此能掩蔽包含推定的部分的机密信息。并且,本发明中,关于在判断规则中没登记的信息,使用在消息中的出现位置、机密语的共现关系从判断规则推定机密属性不能决定的区域的机密属性,由此一边记录的机密区域不泄露到外部,一边能够改善记录的利用性。附图说明图1是表示本实施方式的信息处理系统100的实施方式的图。图2是本实施方式中使用的安全记录生成部200的功能块图。图3是表示本实施方式中认为是解析对象的记录300的图。图4是表示本实施方式的判断规则224中登记的语言、串列、或正则表达式等可变部的列表的图。图5是表示本实施方式的记录解析方法的流程图及记录解析的数据形态的图。图6是图5后续的处理的流程图。图7是图6中说明的机密度推定处理的流程图。图8是表示对作为对象的记录810对应附加本实施方式中使用的机密度判断形态800的图。图9是表示本实施方式的显示置换部222实行的置换处理的实施方式的图。图10例示地示出使用Apache2.0安装的Web服务器的访问记录1000及FTP服务器的事务记录1100的图。具体实施方式以下,用实施方式说明本发明,但是,本发明不限于后述的实施方式。图1表示适用本实施方式的机密信息识别方法的信息处理系统100的实施方式。服务器功能部120与网络110连接,应答来自与网络110连接的客户端装置112的请求,对客户端装置112提供Web服务、存储服务、检索服务等。服务器功能部120包含:服务器装置122和数据库124,在所述数据库124中,通过服务器装置122安装的数据库应用等管理数据。除了管理应该提供的内容以外,数据库124还包含利用者登记、利用者信息变更、访问控制信息等的安全性信息。在图1表示的服务器装置122可通过刀片服务器、机架固定件服务器、或大型机等的信息处理装置构成,能通过WINDOWS(注册商标)200X、UNIX(注册商标)、LINUX(注册商标)等的操作系统来控制。还有,服务器装置122处理来自客户端装置112的检索请求,尽可能向客户端装置112返回处理结果,能作为用于分散处理的代理服务器、网关服务器等安装,也能作为Web服务器安装。客户端102能作为包括所谓的单核处理器或双核处理器的微处理器、RAM、硬盘驱动器等的个人计算机、工作站来安装。还有,客户端装置112也能作为PDA、智能手机来安装。客户端装置112能通过WINDOWS(注册商标)、UNIX(注册商标)、LINUX(注册商标)、MACOS(注册商标)、ANDOROID(注册商标)等任何操作系统来控制。在客户端装置112和服务器功能部120之间,经由网络110,能使用TCP/IP等的事务协议连接。还有,在客户端装置112和服务器装置122之间的数据事务能使用RMI(RemoteMethodInvocation:远程方法调用)、RPC(RemoteProcedureCall:远程过程调用)、EJB(EnterpriseJavaBeans)、CORBA(CommonObjectBrokerArchitecture:公共对象代理架构)等的分布式处理环境来构成。其他的实施方式中,也能构成为,在服务器装置122和客户端装置112之间使用HTTP协议,在客户端装置112侧安装Web浏览器,在服务器装置122侧安装CGI(CommonGatewayInterface:公共网关接口)、Servlets、数据库应用等的服务器程序。此外,其他的实施方式中,也能构成为,在服务器装置122侧安装FTP服务器应用,将客户端装置112作为FTP客户端,进行数据事务。服务器装置122在服务器装置122或数据库124的适当的存储空间内保持记录126。在本说明书中,所谓记录126,仅作为记录能参照通过服务器等的信息处理装置的工作积蓄的、关于信息处理装置的工作积蓄的消息的文件,特定的实施方式中,例如记录126,在与客户端装置112之间进行的事务中,逐次记录生成表示服务器装置122的工作的信息。记录126中,虽然信息有高附加值,但是大多情况下,因为用文本基础来记录,能用各种方法从外部访问,但是,高度限定的企业团体的负责者以外的人访问纯粹的记录,从安全性的观点是不利的。因此,本实施方式中,对服务器功能部120,不直接访问记录,生成遮蔽记录含有的重要的基本信息和个人信息的安全记录,在服务器装置122安装访问该安全记录的功能装置。还有,在本说明书中,所谓安全记录是以根据本发明识别记录126包含的机密信息,遮蔽或置换机密信息,不显示机密信息的方式修正的数据文件。图2是为了从记录识别机密性高的区域而在本实施方式使用的安全记录生成部200的功能块图。如图2表示的安全记录生成部200能使用服务器装置122可以实行的程序,例如使用C++,Java(注册商标),Perl,Ruby,PHP等制作,通过与加密等的方式不同的方式,控制向记录的访问,例如能作为过滤器组件等向服务器装置122安装。在图2表示的安全记录生成部200,对于服务器装置122生成的记录126,使用适当的输入接口,从记载记录的存储空间读出,识别隐藏性高的信息,适用各种的处理作为机密信息遮蔽。遮蔽机密信息的数据文件看作是安全记录126a,能经由输出接口等输出。在记录126的读出时,在密码设定记录的场合,能输入准备的密码和解密密钥以调用安全记录生成部200。还有,输出安全记录126a的形式,不做特别限定,但是,包括:向桌面画面的显示、HTML、XML等的结构化文件的作成,文本文件的作成,向制作的文件的硬盘驱动器等的外部存储介质的收置,经过网络的发送等。再者,图2中,为了说明的方便,省略表示输入输出接口。使用图2,进一步说明本实施方式的安全记录生成部200。安全记录生成部200构成为包括:机密信息识别部210和显示置换部230。机密信息识别部210提供识别在记录126中存在的机密信息的功能,显示置换部230提供用其他的文字等置换机密信息识别部210识别的记录126的显示的功能。机密信息识别部210包含:消息解析部212、簇部214、可变部特定部216。消息解析部212构成为包括对记录进行语法解析的解析程序,例如根据模板的比较等将记录126包含的信息的文章相似性量化,考虑以后的处理性,按相似性的顺序将消息归类。簇部214使用相似性对消息进行簇分类。可变部特定部216,通过消息互相的比较,在特定的簇包括的消息的区域中指定作为固定不变化的区域的固定部及作为每个消息变化的区域的可变部,在簇被归属的消息中识别应该作为变量处理的可变部的位置。以下,在消息中的区域中,将每个消息变化的区域作为可变部来参照,代替地将消息不变化的区域作为固定部来参照。此外,机密信息识别部210还包括:属性决定部218和属性推定部220。属性决定部218参照判断规则224判断在信息中作为可变部被识别的字(语)、串列、具有正则表达式给予的一定的规则的编码信息等的机密性相关的属性。例如,检索是否作为可变部识别的区域的存在的语言、串列、正则表达式在判断规则224中登记,现在判断的可变部,在用判断规则机密地登记时,该可变部作为机密信息遮蔽,或作为应该置换的变量来记录。还有,属性推定部220关于判断规则224中未登记的变量进行推定其机密性的判断。推定判断的第1实施方式中,与依据判断规则224判断为机密的可变部在消息中的位置相同的变量,推定具有与根据判断规则224判断为机密的可变部相同的机密水平。还有,推定判断的第2实施方式是,使用判断为机密的可变部和属性不明的可变部的共现关系,根据共现关系的形态推定属性不明的可变部的机密水平的实施方式。本实施方式的属性推定部220,通过不是仅使用判断规则224,还使用消息内的语法解析的结果进行机密水平的推定,不仅根据在判断规则224中登记的语言、串列、正则表达式,还能够根据判断规则224进行机密水平不明的语言、串列、正则表达式(以下,本实施方式中,参照不明部。)的处理。显示置换部230,对判断或推定为机密的可变部,原样保持可变部的语义,用不同的语言、串列、或正规化表示的所谓其他显示置换原来的显示。所谓用语“保持语义”意味着选择与可变部的意义内容或概念内容相同或类似的置换语。根据示例,在人名时,置换为:"Alice"→“Cathy","Bob"→“David"等。还有,在所谓IP地址的正则表达式时,置换为:“192.168.1.1”→“192.1.1.2”,“10.1.5.6”→“167.5.7.8”等的编码信息。还有,关于地名、陆地标志名、端口号、其他的可变部等,也用同样或类似的置换语进行置换的处理。还有,在端口号和邮件地址时,即使使用了假名和不同的数值,也很有可能存在使用该邮件地址的第三者,服务器也有可能使用实际置换后的端口。因此,本实施方式中,在邮件地址和端口号等的信息时,留下邮件地址和端口号已知的程度的痕迹信息,除此之外能将原来的信息用数值以外的字符、星号、#记号、其余适当的符号语言来置换。另外,也能使用加密和其他的置换方法等,到现在为止知道的任何匿名化方法和隐藏方法。还有,在可变部的变换时,在可变部的语言和值相同而得到原来的语言等的出现履历的一致性的情况下,优选地,分配同样的置换语和值。根据显示置换部230判断为机密的可变部被置换之后,能够输出作为以安全记录126a表示的数据文件。显示置换部230制作的安全记录126a,经由适当的输出接口,能作为文件等的传送介质来发送,能容纳于硬盘驱动器、USB存储器、软盘等的可移动性的记录介质中并输出。如以上那样生成的安全记录,在因为暂时进行记录解析而由外部企业访问的情况下,向外部企业提供文件的情况下,因为能最低化企业风险的发生,所以均能够提高记录的利用性,实现网络系统的改善。再者,在访问纯粹的记录时,由于使用其他的安全性高的应用,能确保向记录的访问性和记录解析的隐藏性,但是用于访问纯粹的记录的应用不是本申请的主旨,所以省略详细的说明。图3表示本实施方式中认为是解析对象的记录300。如图3表示的记录300包括:人名310、城市名320、电子邮件地址330。还有,记录300示例的信息,除了登录信息以外,还包括与特定的人名相关,与Tokyo、Osaka等的本地信息和邮件地址的更新相关的信息。还有,也包含一般认为是日本人名的串列的"Sachiko"340。在判断规则224中包含这些个人信息和个人信息不知晓的信息、或与个人信息相关并应该决定为机密信息等全部,要考虑记录的类型的多样性、用于判断规则224作成的程序设计工作量,因此不现实。即使增加若干单词登记,例如根据印度/欧洲语言的人名"Alice"310和"Bob"是否登记的判断规则224,如日本人名的"Sachiko",分类为其机密水平不明的不明部,不能保证充分的隐藏性。本实施方式,由于通过消息结构的解析关于不明部也推定其机密水平,来改善记录300隐藏性。图4表示本实施方式的判断规则224中登记的语言、串列、或正则表达式等可变部的列表。判断规则224,对可变部的每个记录作为字段对应附加属性与语言/串列/正则表达式等的区域显示。属性是与机密部的语义相对应的类别,置换语能从分类为同样的属性的语言选择。还有,IP地址,由正则表达式给予,如果置换IP地址,能置换例如从私有地址中残留本来的IP地址的一部分的形式的显示。此外,在图4,作为属性,也登记邮件地址,在邮件地址的场合,仅随机地置换比@左面的串列不能排除实际的邮件地址的可能性,例如,对于串,在能识别“*”(星号)和“!”(感叹号)等的邮件地址的范围内,能匿名化。另外,在判断规则224中,也能登记非机密信息。非机密信息是判断规则224中不可避免的应该录入的数据,用途在于要求将基于解析器的语法解析效率化,能登记非机密信息。使用图5的流程图及记录解析的数据形态,说明本实施方式的机密信息识别处理及安全记录生成处理。图5的处理,从步骤S500开始,在步骤S501,消息解析部212以消息为单位读入记录数据,对每个消息分割记录,对每个消息计算编辑距离。在步骤S502,使用编辑距离按照类似度对消息进行归类。在步骤S502得到的消息结构510,基于消息的编辑距离生成与类似度相应归类的结构,在图5表示的实施方式中,将用户概况更新的消息和登录消息识别为类似度不同的消息。消息结构510中,例示的表示消息中的可变部512、514。此外,“UserProfilefor”和“isupdated”等的字符串是固定部。若详细地说明,由句子“UseProfilefor”和“isupdated”夹着的语言“Alice”是个人名,“Tokyo”、“alice@foo.com”分别是城市名、电子邮件地址,与表示各值的变量名一起识别为可变部。若参看消息结构510可以理解,类似度高的信息的可变部具有按文章结构中同样的顺序出现的特征。再次,若使用流程图说明,在步骤S503,簇部214使用编辑距离将归类后的消息簇化为类似度高的消息的组。簇化对应于由归类的类似度的排序的程度,不一定是必要的处理,但是由于以簇为单位进行可变部、固定部的识别,能提高可变部的识别性、识别精度。在图5,对通过步骤S503处理生成的消息结构510的簇化的处理,表示簇结构520。说明的实施方式中,识别包含用户概况更新的消息的簇、和包含登录信息的簇。并且,在步骤S503,作为模板结构530登记形成簇的消息的固定部及可变部的结构,对消息生成与各簇的可变部=变量存在的位置相关的模板,在适当的工作用的存储空间中登记。这时,消息的簇,例如,能作为[簇识别值,编辑距离范围,模板识别值]等附加索引,确保判断规则224的适当的存储区域,能预先登记簇的索引。模板结构能对每个处理生成,但是关于同样的服务器功能部120,大多数场合,使用同样的消息。因此,一旦生成簇的索引之后,可如下的方式来组装:关于簇识别值作为信息模板在判断规则224中预先登记,通过读入处理对象的消息识别从编辑距离应该分类簇,立刻评价处理对象的消息中的可变部的机密度。在图5表示的模板结构530中,可变部表示为“<?>",但是,图5的模板结构530的可变部的显示是例示的,不意味着附加结构化文件的标签来识别。在模板中的可变部的识别,由可变部特定部216负责,例如能通过识别从前头开始的词数、空格的数、变量的两个引号之间等,特定的目的的程序来适宜地选择。步骤S504,作为用于判断规则224的检查的检索钥匙设定识别的可变部,从点A向下面的处理推进处理。图6是图5中后续的处理的流程图。图6的处理,在步骤S601,通过由属性决定部218检索判断规则224,判断可变部的机密度。此后,在步骤S602,将检索的结果得到的机密度,作为当前判断的可变部的位置的可变部的机密度,与模板关联。关联对模板进行语法解析,也能作为语言/串/正则表达式的阶层结构、XML等的结构化文件来关联,更单纯作为[模板识别值,从前头开始的词数,机密,从前头开始的词数,非机密,从前头开始的词数,机密]等的表登记。在图6表示,属性决定部218使用模板判断可变部的机密度的结果。消息结构610中,在判断规则224中登记“UserProfilefor”之后的"Alice"和"Bob",判断其是机密的。另一方面,"Sachiko",在说明的实施方式中,不在判断规则224中登记,属性决定部218作为检索的结果还值"false"。这个状况,对登录消息也同样。若在步骤S602属性决定部218返回值=false,则安全记录生成部200调用属性推定部220。属性推定部220,在步骤S603,判断机密属性不明的可变部的模板上的位置,将对模板分配的该出现位置的机密度设定为属性决定部218应该分配的机密度,用于后述的显示置换部230的处理。关于这个处理说明了模板结构620。在模板结构620,用户概况更新模板中,示出<Red>的可变部的位置已经作为机密属性登记,即使与<Red>的位置相当的不明部出现,也能设定为该不明部的机密属性=机密。此外,关于登录模板例示的<Red>表示的位置的不明部,设定为其机密属性=机密。还有,属性推定部220,关于消息中存在的任意位置的可变部,在步骤S604,使用出现位置以外的信息进行任意的位置的可变部的机密度类推处理。机密度类推处理更详细地后述,但是,使用在消息中的机密部的存在的有无或与机密部的共现关系进行关于消息中任意的位置的不明部推定其机密属性的处理。步骤S604的处理后,在步骤S605,更新在特定的消息内机密水平不明的不明部的机密水平的设定,使处理进行至显示置换部230的处理,在步骤S606,参照判断规则用不同的显示置换可变部,生成安全记录。此后,在步骤S607,经由适当的输出接口以其他的装置中可以利用的方式输出安全记录126a并结束处理。图7是在图6说明的机密度推定处理的流程图。机密度推定处理是用于图2表示的安全记录生成部200推定消息中包括的任意的位置的可变部的机密水平的处理。本实施方式的机密信息识别方法中,机密度的类推在2个实施方式中进行,第1类推方法是仅利用在消息内的机密部的存在的有无的形态(步骤S604→S700→S605),第2类推方法是使用机密部和不明部的共现关系,动态地类推消息内的机密属性的形态(步骤S604→S710→S711→S712→S605)。在本实施方式中,所谓用语“共现关系”意味着消息包含的可变部的值在同一消息内出现2次或以上。还有,用语“共现频度”意味着特定的可变部共同在消息内出现的频度。具体地,例如,考虑个人的姓名、特定的日期为同样消息内不相同的可变部同时出现的情况。姓名是机密度高的机密部,紧接之后出现的日期,有对对应姓名的个人来说特别的意义的日,例如作为生日的可能性高。还有,在那样共现发生时个人的生日被指定和推定,关于不同的个人,这些变量的共现考虑{同姓同名概率*同样生日概率}程度极低的概率,所谓妥当的类推方法。即,机密部和在同样消息内出现的可变部,即使那个机密属性不明,也作为“机密”推定妥当。因此,本实施方式中,使用共现关系类推机密度时,使用以机密部为准的共现频度,关于共现频度设定条件,类推不明部的机密度。作为这个的条件,能关于共现频度设定特定的逻辑条件以下,使用图7说明本实施方式的机密度类推处理。机密度类推处理从步骤S603传递开始处理,在步骤S700,判断消息内是否包含机密部,在包含机密部时,将该消息内存在的可变部一并设定为机密,将处理传递至步骤S605。以下,关于第2实施方式说明。第2实施方式中,在步骤S710,从消息列出该消息包含的可变部。在步骤S711,列出记录内分类为同样的属性的可变部一起出现的可变部,计算共现频度,向可变部对应附加。在步骤S712,在机密部的机密部字符串(A)和不明部的可变部字符串(B)的共现频度在阈值TH1以上,并且同时其可变字符串(B)和该机密部的字符串以外(附加栏A)同时出现的频度在阈值TH2以下的情况下,将当前判断的不明部推定为机密。采用这个逻辑条件的处理理由在于,在例如可变部的值是作为机密信息的姓名的情况下,与这个姓名高的频度共现的字符串(例如∶生日,电子邮件地址,这个人物的密码等),应该考虑为机密。在图7,表示用于基于共现频度的机密度类推的例示的条件。条件730,使用与机密部共现的可变部作为机密部处理的第1实施方式。条件730中,与人名“Alice”共现的字符串“Tokyo”和电子邮件地址“alice@foo.com”都推定为机密性高的可变部。按照推定的结果如上述使用文字的置换,保护机密信息。还有,条件740是在第2实施方式的步骤S712使用的条件。另一方面,条件740产生进行多次共现判断的必要性,更精密地可以根据与不明部的机密部的关系进行机密推定。这些的各个判断条件按照记录的类型、目的,安装于信息处理装置。条件740的判断成为必要,如以下的情况。即,在与机密的可变部同时出现的字符串中,一般地,在其他的消息内也可能出现。例如,某人物住的国家的名字,可能与那个人物的名字同时高的频度出现,但是其他许多人也住在一样的国家,那个国名其他的许多人名也可能同时出现。这个场合,国名本身的机密度低,不必置换国名。(总之,如果假定国家的人口充分地大,由于从国名指定个人认为是不容易的,认为仅从国名几乎不会泄露个人的隐私)。这个情况有的国名,与特定的人名A同时不出现,A以外的人名(附加栏A)大量地同时出现,由于不断用条件740能判断为非机密。还有,关于其他的实施方式,对上述阈值,在特定用途恰当地给予机密度,通过适宜地设定,通过期望的安全性。以下,关于本发明其他的实施方式,沿着图7的上下文说明。这个实施方式中,机密度推定处理从步骤S604传递处理开始。步骤S700,属性部220从下列的2个模式按以下的那样选择一个。第1模式是最单纯的方法,属性推定部220,在判定是机密的消息内的全部的可变部,消息内的任意1以上的可变部被判定为机密时,向步骤S605推进处理。这个,即使可变部不是机密的情况,将可变部机密过多分类,但是,为简略化的判断方法。还有,如果选择第2模式,属性推定部220在步骤S710列出消息包括的可变部。在步骤S711,属性推定部220,列出在各消息中出现的可变部的组,此后计算各可变部各自的共现频度。在步骤S712,不明部及特定的机密部的共现频度在预定的阈值TH1以上,并且除去作为不明部的可变部的特定机密部之外,与机密部的共现频度低于阈值TH2的情况下,属性推定220决定该可变部分为机密。采用这个处理,根据以下的理由。例如可变部,作为机密信息的个人名,与这个姓名高的频度共现的字符串(例如∶生日,电子邮件地址,这个人物的密码等),应该考虑为机密。在本实施方式的第1模式对应于,机密部和可变部间的共现关系的、不明部作为“机密”判断的出现频度的阈值设定为0。换句话说,与机密部分一起出现1次以上的全部的可变部分判断为机密,如第1实施方式,在消息内机密和不明部存在时,把该不明部作为机密代替的处理。第1模式是与第1的实施方式同样地将几个可变部,在作为机密过分类的可能性的方面简略化的判断方法。然而,这个方法不必要共现频度的检查。这个实施方式,能作为减轻信息处理装置的组/头属性时由推定部220选择的处理。步骤S712之后,属性推定部220进入步骤S605,结束图7机密度推定处理。随同地,按照用于共现判断的对象的可变部的属性,作为共现频度的阈值也能使用不同的值。还有,根据消息,关于消息内的可变部,有可能发生其机密属性通过判断规则224不能进行完全判断。这个情况下,机密信息识别部210使用不明部的出现位置进行机密属性的推定,此后,使用共现关系进行不明部的机密属性的推定及决定,能防止机密信息原样在安全记录中显示。并且,其他的实施方式中,一旦关于作为不明部识别的位置出现的语言、串列、字符列、数字列,编码信息等推定机密属性之后,通过追加在登记判断规则224推定的语言、串、字符列、编码信息等的数据,学习判断规则224,能使机密信息的判断处理效率化。图8是表示向作为对象的记录810对应附加本实施方式中使用的机密度判断形态800的图。白色矩形框是固定部,云形框内的可变部是机密的区域,阴影的矩形框内是推定的机密区域,下划线的可变部是使用模板内的出现位置判断的机密属性的区域。如图8所示,固定消息(非机密)及云形框内的可变部的组820使用判断规则224直接判断机密属性。另一方面,关于组830是按判断规则224作为不明部分类的可变部。本实施方式中,关于作为不明部分类的可变部,使用可变部的共现关系及消息内的出现位置判断机密属性。使用共现关系类推或推定机密属性的可变部是对姓名的日期及城市名。还有,使用可变部的出现位置判断,是可变部=password。这个可变部成为输入用户ID那样错误地输入密码,此外,在密码上重叠打字错误的不明部。本实施方式中,使用同样的簇内的消息的可变部的出现位置,利用例如记录810的第1行的可变部"UserID"的紧接之后机密属性的区域出现,关于不明部=password判断为机密。通过以上内容,本实施方式中,关于不在判断规则224登记的可变部也能设定机密水平,降低企业团体风险,由此提高记录的利用性。图9表示本实施方式的显示置换部230实行的置换处理的实施方式。在原来的记录900,包含人名、城市名、电子邮件地址等多个机密区域。本实施方式的显示置换部230依据设定的协议置换作为机密登记的信息的可变部。具体地,关于人名、城市名,选择判断规则224内同样的属性以外的值,进行置换。再者,此时,在原来的可变部相同的情况下,分配同样的其他显示值。还有,关于电子邮件地址,通过识别电子邮件地址的程度的其他显示,将拉丁字母变更为其他的字符和数字。具体地,关于人名,记录900的"Alice"、"Bob"、"Sachiko",在安全记录910中,分别置换为"Mary"、"Nic"、"John"。还有,关于城市名,"Tokyo"、"Osaka"、"Naha"分别置换为"NewYork"、“Washington”、"Toront"。此外,关于电子邮件地址,具有依据SMTP协议的显示以能识别的方式保留****@***.***的显示,用字符置换。再者,关于指定个人的以外的域名的区域,也可从信息量的观点非置换的原样残留。还有,在图9没有表示,但是,关于IP地址等,一边沿用原来的数字的一部分,一边用适当的私人IP地址置换全球IP地址等来置换机密信息。再者,用于置换的规则,在安全记录生成部200管理的适当的存储空间作为表和列表预先保存,按照服务器管理者等的高水平的管理者的请求,进行逆变换,用于再现原来的记录。还有,关于本发明,为了便于发明的理解,对各功能装置及各功能装置的处理记述了具体的功能装置,但是,除了实行上述的特定的功能装置特定的处理以外,本发明还考虑处理效率和实现上的程序设计等的效率,能分配用于在任何功能装置均能实行上述的处理的功能。本发明的上述功能能通过C++、Java(注册商标)、Java(注册商标)Beans、Java(注册商标)Applet、Java(注册商标)Script、Perl、Ruby、PYTHON等面向对象程序设计语言、SQL等的检索专用语言等记述的装置能够实行的程序来实现,能在装置可读的记录介质中容纳并分发或传送。至此,用特定的实施方式说明了本发明,但是,本发明不限于实施方式,其他的实施方式、追加、变更、删除等,在本领域技术人员想到的范围内能进行变更,只要在其形态也上能实现本发明的作用、效果,均包含于本发明的范围。【符号的说明】100信息处理系统102客户端110网络112客户端装置120服务器功能部122服务器装置124数据库126记录126a安全记录200安全记录生成部210机密信息识别部212消息解析部214簇部216可变部特定部218属性决定部220属性推定部224判断规则230显示置换部
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1