信息处理装置的制作方法
本发明涉及一种可由包含有已重叠在多个字符串的多个标记的原稿图像作成以作了标记的字符串作为解答的填空题的信息处理装置。
背景技术:
已知有如下作成填空题的技术:读取利用手写的标记指定出作为问题的解答的字符串的原稿图像,从所读取的原稿图像数据中抽取标记的图像,在标记的位置抽取字符串,在标记的位置删除字符串,且在字符串的删除部分设定解答栏。作为用于抽取字符串的技术,已知有光学字符识别(opticalcharacterrecognition;ocr)。
技术实现要素:
[发明所要解决的问题]
在可作成填空题的信息处理装置中,希望对于问题制作者及回答者双方可越来越友善(userfriendly)。
鉴于以上情况,本发明的目的在于在能由包含有已重叠在多个字符串的多个标记的原稿图像作成以作了标记的字符串作为解答的填空题的信息处理装置中提高用户的便利性。
[解决问题的手段]
为了达到所述目的,本发明的一实施方式的信息处理装置具备:标记抽取部,从包含有分别已重叠在多个字符串的多个标记的原稿图像抽取所述多个标记;相同字符串识别部,识别已分别重叠着所述标记的所述多个字符串中的相同的字符串;及
符号决定部,对所述相同的字符串分配相同的符号,对不同的字符串分配不同的符号。
为了达到所述目的,本发明的一实施方式的信息处理装置具备:标记抽取部,从具有包含有已重叠着标记的字符串及未重叠标记的字符串的字符串区域的原稿图像抽取所述标记;及图像转换部,将已重叠在所述字符串的标记放大而作成放大字符串,将未重叠所述标记的字符串缩小而作成缩小字符串。
为了达到所述目的,本发明的一实施方式的信息处理装置具备:标记抽取部,从包含有已重叠在字符串的标记的原稿图像抽取所述标记;及字符串比较部,从所述原稿图像抽取与已重叠着所述标记的字符串相同的未重叠标记的字符串。
[发明的效果]
根据本发明,在能由包含有已重叠在多个字符串的多个标记的原稿图像作成以作了标记的字符串作为解答的填空题的信息处理装置中提高用户的便利性。
附图说明
图1是表示第1实施方式中的图像形成装置的硬件结构的框图。
图2是表示图像形成装置的功能性结构的框图。
图3是表示图像形成装置的动作的流程图。
图4是用于说明图像形成装置的动作的图。
图5是表示第2实施方式中的图像形成装置的功能性结构的框图。
图6是表示图像形成装置的动作的流程图。
图7是表示第3实施方式中的图像形成装置的功能性结构的框图。
图8是表示图像形成装置的动作的流程图。
图9是用于说明图像形成装置的动作的图。
图10是用于说明用以算出放大率或缩小率的算式中使用的变量的图。
图11是用于说明实施例1中的放大率或缩小率的计算方法的图。
图12是用于说明实施例2中的放大率或缩小率的计算方法的图。
图13是用于说明实施例3中的放大率或缩小率的计算方法的图。
图14是用于说明实施例4中的放大率或缩小率的计算方法的图。
图15是用于说明实施例5中的放大率或缩小率的计算方法的图。
图16是表示第4实施方式中的图像形成装置的功能性结构的框图。
图17是表示图像形成装置的动作的流程图。
图18是用于说明图像形成装置的动作的图。
具体实施方式
以下,参照附图说明本发明的实施方式。
(i.第1实施方式)
(1.图像形成装置的硬件结构)
图1是表示本发明的第1实施方式中的图像形成装置的硬件结构的框图。
本发明的各实施方式中的信息处理装置是图像形成装置(例如多功能外围设备(multifunctionperipheral;mfp)),以下称为mfp。
mfp1具备控制部11。控制部11由中央处理器(centralprocessingunit;cpu)、随机存储器(randomaccessmemory;ram)、只读存储器(readonlymemory;rom)及专用的硬件电路等所构成,负责mfp1整体的动作控制。使mfp1作为各功能部(下文叙述)发挥功能的计算机程序存储在rom等非暂时性存储媒体中。
控制部11连接于图像读取部12、图像处理部14、图像存储器15、图像形成部16、操作部17、存储部18、网络通信部13等。控制部11对连接着的所述各部进行动作控制、且进行对各部之间的信号或数据的收发。
控制部11根据由用户通过操作部17或连接于网络的个人计算机(未图示)等输入的工作的执行指示,对于执行关于扫描功能、印刷功能及复制功能等各功能的动作控制时所需的机构的驱动及处理进行控制。
图像读取部12从原稿读取图像。
图像处理部14根据需要对图像读取部12所读取的图像的图像数据进行图像处理。例如,图像处理部14进行阴影(shading)校正等图像处理,以提高图像读取部12所读取的图像经过图像形成后的品质。
图像存储器15具有暂时存储经图像读取部12读取而获得的原稿图像的数据、或暂时存储作为图像形成部16的印刷对象的数据的区域。
图像形成部16对图像读取部12所读取的图像数据等进行图像形成。
操作部17具备针对mfp1可执行的各种动作及处理而接受来自用户的指示的触摸面板部及操作按键部。触摸面板部具备设有触摸面板的液晶显示器(liquidcrystaldisplay;lcd)等显示部17a。
网络通信部13是用于与网络连接的界面。
存储部18是存储由图像读取部12所读取的原稿图像等的硬盘驱动器(harddiskdrive;hdd)等大容量的存储装置。
(2.图像形成装置的功能性结构)
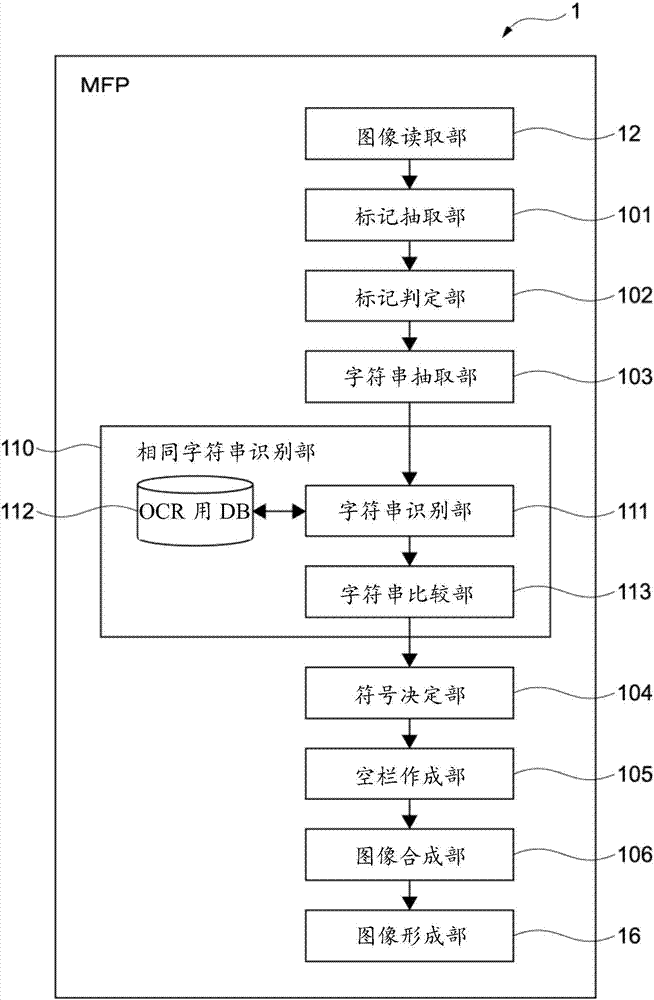
图2是表示图像形成装置的功能性结构的框图。
mfp1通过执行信息处理程序而作为标记抽取部101、标记判定部102、字符串抽取部103、相同字符串识别部110、符号决定部104、空栏作成部105及图像合成部106发挥功能。
标记抽取部101从图像读取部12所读取的原稿图像抽取分别已重叠在多个字符串的多个标记。
标记判定部102对标记抽取部101所抽取的多个标记各自在原稿图像内的位置及形状进行判定。
字符串抽取部103根据标记判定部102所判定的多个标记的位置及形状,抽取已重叠着各个标记的多个字符串。
相同字符串识别部110具有字符串识别部111、ocr用数据库112及字符串比较部113,识别各自已重叠着标记的多个字符串中的相同的字符串。
符号决定部104对字符串比较部113所识别的相同的字符串分配相同的符号,对不同的字符串分配不同的符号。
空栏作成部105作成分别重叠在各自已重叠着标记的多个字符串的空栏图像。
图像合成部106作成将图像读取部12所读取的原稿图像、空栏作成部105所作成的空栏图像、及作为符号决定部104所分配的符号的图像的符号图像予以合成的合成图像。
(3.图像形成装置的动作)
图3是表示图像形成装置的动作的流程图。图4是用于说明图像形成装置的动作的图。
作为前提,在原稿(典型的是纸)上印有作为文本数据的字符串。或者,在原稿上,形成作为图像数据的字符串的图像(复制印有字符串的原稿)。并且,字符串整体中的多个一部分的字符串(复合词、短语、数值等)由作为用户的问题制作者使用荧光标记笔等以手写的方式作标记。作了标记的字符串是填空题中作为解答的字符串。
图像读取部12对原稿进行光学扫描,读取原稿图像(步骤s101,参照图4)。作为“原稿图像”,整体而言是包含有多数字符串的文档原稿的图像数据,包括已重叠在多个字符串的多个标记(图4中所示的阴影部分)。“字符串”是语句(单词、短语、文章等)、数值等,严格而言是其图像。
标记抽取部101从图像读取部12所读取的原稿图像抽取分别已重叠在多个字符串的多个标记(步骤s102)。具体而言,标记抽取部101抽取明度及/或彩度等与背景(白色等)不同且具有特定的形状及尺寸(特定宽度的带状的长方形等)的区域作为标记。
标记判定部102对标记抽取部101所抽取的多个标记各自在原稿图像内的位置及形状进行判定(步骤s103)。具体而言,标记判定部102将原稿图像整体作为坐标系整体,将标记的位置及形状作为坐标算出。
字符串抽取部103根据标记判定部102所判定的多个标记的位置及形状(坐标),抽取已重叠着各个标记的多个字符串(步骤s104)。具体而言,字符串抽取部103通过边缘检测而抽取已重叠着由标记判定部102判定的位置及形状(坐标)所定义的标记的字符串。另外,字符串抽取部103并不抽取字符串所含有的1个1个的字符,而是抽取已重叠着1个标记的字符串整体作为1个字符串。
字符串识别部111对字符串抽取部103所抽取的多个字符串各自进行识别。具体而言,字符串识别部111从字符串抽取部103所抽取的多个字符串的各个字符串抽取多个字符。“字符”是字符串所含有的1个1个的字符(根据语言,也可称为1个1个的单词),严格而言是其图像。字符串识别部111参照ocr用数据库112,对所抽取的多个字符的各个字符进行识别(步骤s105)。具体而言,在ocr用数据库112中,字符的图像图案与字符代码对应且逐个字符地注册。字符串识别部111从ocr用数据库112中检索出表示所抽取的字符的图像图案,获取与经检索而得的图像图案对应的字符代码。字符串识别部111针对字符串所含有的所有字符获取字符代码。字符串识别部111通过将字符串所含有的所有字符各自的字符代码组合来识别字符串(步骤s106)。字符串识别部111针对已重叠着标记的所有字符串抽取字符,获取字符各自表示的字符代码,将字符代码组合,利用该组合的字符代码来识别字符串。
字符串比较部113通过对字符串识别部111所识别的字符串彼此进行比较而对相同的字符串进行识别,从而识别相同的字符串(步骤s107)。具体而言,字符串比较部113针对已重叠着标记的所有字符串,对组合的字符代码彼此进行比较,由此识别相同的字符串。
符号决定部104向字符串比较部113所识别的相同的字符串分配相同的符号(数字、字符、符号等),向不同的字符串分配不同的符号(步骤s108)。
空栏作成部105作成分别重叠在各自已重叠着标记的多个字符串的空栏图像(步骤s109,参照图4)。具体而言,空栏作成部105作成消除了字符串抽取部103通过边缘检测而抽取的字符串(步骤s104)、及从该字符串露出的标记的边缘部分的形状及位置(坐标)的空栏图像。空栏图像可为单纯的空格,也可包含有预先决定的格式(下划线、矩形框、括弧等)。图4所示的例中,空栏图像包含有下划线。
图像合成部106作成将图像读取部12所读取的原稿图像(步骤s101)、空栏作成部105所作成的空栏图像(步骤s109)、及作为符号决定部104所分配的符号(步骤s108)的图像的符号图像予以合成的合成图像(步骤s110,参照图4)。具体而言,图像合成部106将形状及位置由坐标定义的空栏图像配置在原稿图像的坐标系。并且,图像合成部106通过将预先决定的格式(字体、尺寸等)的符号配置在原稿图像中配置的空栏图像的预先决定的位置(中央、左端等),而作成合成图像。图4所示的例中,合成了原稿图像、包含有下划线的空栏图像、及符号的图像。
图像形成部16将图像合成部106所作成的合成图像形成(打印输出)在纸上(步骤s111)。
(ii.第2实施方式)
以下的说明中,对于与第1实施方式相同的结构及动作等省略说明,而以不同点为中心进行说明。
第1实施方式中,相同字符串识别部110利用光学字符识别(ocr)(步骤s105)对字符串进行识别(步骤s106),识别相同的字符串(步骤s107)。相对于此,第2实施方式中,相同字符串识别部是利用光学字符识别(ocr)以外的方法识别相同的字符串。
(1.图像形成装置的功能性结构)
图5是表示第2实施方式中的图像形成装置的功能性结构的框图。
mfp2通过执行信息处理程序而作为标记抽取部101、标记判定部102、字符串抽取部103、字符串类似度判定部201、符号决定部104、空栏作成部105及图像合成部106发挥功能。mfp2中,作为第1实施方式的相同字符串识别部110,具有字符串类似度判定部201以代替字符串识别部111、ocr用数据库112及字符串比较部113。其他均与第1实施方式的mfp1相同。
字符串类似度判定部201对字符串抽取部103所抽取的多个字符串彼此的类似度进行判定,当类似度为阈值以上时,判定多个字符串为相同的字符串。
(2.图像形成装置的动作)
图6是表示图像形成装置的动作的流程图。
步骤s101至步骤s104与第1实施方式相同。
步骤s104之后,字符串类似度判定部201判定字符串抽取部103所抽取(步骤s104)的多个字符串彼此的类似度,当类似度为阈值以上时,判定多个字符串为相同的字符串(步骤s201)。具体而言,字符串类似度判定部201对字符串的图像图案(像素)彼此进行比较,当图像图案的重复度为阈值以上时,判定为相同的字符串。该阈值只要设为如下的值即可:当字符结构相同但字体不同时,也可判定为相同的字符串。例如,阈值为90%等,用户可作为识别级别而任意设定。
步骤s201之后,步骤s108至步骤s111与第1实施方式相同。
(3.变化例)
各实施方式中,图像读取部12读取原稿图像(步骤s101)。取而代之,mfp1、mfp2也可通过网络通信部13而从连接于网络的信息处理装置(未图示)接收原稿图像。
(4.总结)
当利用原有原稿作成填空题时,1个文章中,作为解答的字符串有时会出现多次。此情况下,由于作为解答的字符串直接显示在文章中会变成提示,所以作为解答的相同的字符串须要全部为空栏。即,应解答为相同的字符串的空栏有多个。然而,若对应解答为相同的字符串的多个空栏分配不同的符号,则回答者可能会误解为应回答不同的语句。为了防止此现象,问题制作者向应解答为相同的字符串的多个空栏利用手动作业分配相同的符号较为麻烦。尤其是,当空栏的总数较多时、或有多组相同的字符串时等,若问题制作者利用手动作业分配符号,则还可能会分配错误的符号。
对此,根据各实施方式,mfp1向相同的字符串分配相同的符号,向不同的字符串分配不同的符号(步骤s108)。由此,可消除由于向应解答为相同的字符串的多个空栏分配不同的符号,回答者会误解为应回答不同的语句的情况。而且,问题制作者不需要花费工夫向应解答为相同的字符串的多个空栏利用手动作业分配相同的符号,而且也不可能分配错误的符号。
第2实施方式中,mfp2对多个字符串彼此的类似度进行判定,当类似度为阈值以上时,判定多个字符串为相同的字符串(步骤s201)。即,字符串实际包含有的字符并不是问题,只要知道字符串相同即可。与第1实施方式中的ocr相比,第2实施方式具有处理量少且无需数据库的优点。
另外,各实施方式中,已对于标记着具有多个字符的字符串时的处理进行了说明,但当标记着由1个字符所构成的字符串时,也能按照图3及图6进行处理。此情况下,在图3所示的步骤s106中,字符串识别部111无需将字符串所含有的所有字符各自的字符代码组合,只要根据已重叠着标记的1个字符的字符代码识别字符即可。而且,在图3所示的步骤s107中,字符串识别部111可针对已重叠着标记的所有的1个字符,通过对字符代码彼此进行比较而识别相同的1个字符。
(iii.第3实施方式)
(1.概要)
第3实施方式中,通过缩小未重叠标记的字符串而作成缩小字符串、放大已重叠在字符串的标记而作成放大字符串,从而使应重叠空栏图像的字符串的尺寸相对扩大。
(2.图像形成装置的功能性结构)
图7是表示第3实施方式中的图像形成装置的功能性结构的框图。
mfp1是通过执行信息处理程序而作为标记抽取部301、标记判定部302、字符串区域判定部303、行区域判定部304、行区域分割部307、转换率计算部308、图像转换部309、空栏作成部305及图像合成部306发挥功能。
标记抽取部301从图像读取部12所读取的原稿图像抽取已重叠在字符串的标记。
标记判定部302对标记抽取部301所抽取的标记在原稿图像内的位置及尺寸进行判定。
字符串区域判定部303对字符串区域在原稿图像内的位置及尺寸进行判定。
行区域判定部304将字符串区域判定部303所判定的字符串区域分割为多个行区域。行区域判定部304对多个行区域在字符串区域内的位置及尺寸进行判定。
行区域分割部307对标记抽取部301所抽取的标记在该标记所属的行区域内的位置及尺寸进行判定。行区域分割部307将标记所属的行区域分割为已重叠在字符串的标记与未重叠标记的字符串。另外,本实施方式中,“字符串”表示由1个字符所构成的单位、或由连续的多个字符所构成的单位。
转换率计算部308计算用于使已重叠在字符串的标记放大的放大率、或用于使未重叠标记的字符串缩小的缩小率。
图像转换部309通过使已重叠在字符串的标记放大而作成放大字符串。图像转换部309通过使未重叠标记的字符串缩小而作成缩小字符串。图像转换部309将所作成的放大字符串及缩小字符串设计配置于作为输出对象的原稿。
空栏作成部305作成已重叠在图像转换部309所作成的放大字符串的空栏图像。
图像合成部306按照设计来配置图像转换部309所作成的缩小字符串的图像、及空栏作成部305所作成的空栏图像,从而作成合成图像。
(3.图像形成装置的动作)
图8是表示图像形成装置的动作的流程图。图9是用于说明图像形成装置的动作的图。
作为前提,在原稿(典型的是纸)上印有作为文本数据的字符串。或者,在原稿上,形成作为图像数据的字符串的图像(复制印有字符串的原稿)。并且,字符串整体中的多个一部分的字符串(复合词、短语、数值等)由作为用户的问题制作者使用荧光标记笔等以手写的方式作标记。作了标记的字符串是填空题中作为解答的字符串。
图像读取部12对原稿进行光学扫描,读取原稿图像(步骤s301)。作为“原稿图像”,整体而言是包含有多数字符串的文档原稿的图像数据,包括已重叠在多个字符串的多个标记。“字符串”是语句(单词、短语、文章等)、数值等,严格而言是其图像。
标记抽取部301从图像读取部12所读取的原稿图像抽取已重叠在字符串的标记(步骤s302)。具体而言,标记抽取部301抽取明度及/或彩度等与背景(白色等)不同且具有特定的形状及尺寸(特定宽度的带状的长方形等)的区域作为标记。
标记判定部302对标记抽取部301所抽取的标记(图9的左下图中所示的阴影部分)在原稿图像内的位置及尺寸进行判定(步骤s303,参照图9)。具体而言,标记判定部302将原稿图像整体(包括空白(页边的空白))作为坐标系整体,将标记的位置及尺寸作为坐标算出。
另一方面,与步骤s302及步骤s303并行地,字符串区域判定部303对字符串区域在原稿图像内的位置及尺寸进行判定(步骤s304,参照图9)。“字符串区域”是在原稿图像中存在包含有已重叠着标记的字符串及未重叠标记的字符串的字符串集合体的区域。具体而言,字符串区域判定部303将原稿图像整体(包括空白(页边的空白))作为坐标系整体,将字符串区域的位置及尺寸作为坐标算出。
行区域判定部304将字符串区域判定部303所判定的字符串区域分割为多个行区域。“行区域”是将字符串区域内存在的字符串集合体逐行地分割而得的区域。换而言之,一般来说,文档原稿中,多个字符沿一个方向连续地排列而成为1行,而将包含有连成1行的字符串且在字符串区域的一端到另一端作为“行区域”。而且,包含有某1行字符串的“行区域”与包含有下1行字符串的“行区域”相邻。换而言之,相邻的2个行区域之间无空间。图9的中央的图所示的例中,被虚线包围的矩形的行区域无间隙地相连。行区域判定部304对将字符串区域分割而得的多个行区域在字符串区域内的位置及尺寸进行判定(步骤s305,参照图9)。具体而言,行区域判定部304将原稿图像整体作为坐标系整体,将字符串区域内的行区域的位置及尺寸作为坐标算出。
行区域分割部307对标记抽取部301所抽取(步骤s302)的标记在该标记所属的行区域内的位置及尺寸进行判定。具体而言,行区域分割部307获取标记判定部302所判定(步骤s303)的标记在原稿图像内的位置及尺寸、及行区域判定部304所判定(步骤s305)的多个行区域在字符串区域内的位置及尺寸。行区域分割部307通过将标记在原稿图像内的位置及尺寸反映为多个行区域在字符串区域内的位置及尺寸,而对该标记在标记所属的行区域内的位置及尺寸进行判定。图9右侧的图所示的例中,判定从上数起第4个与第6个行区域内的标记(阴影部分)在行区域内的位置及尺寸。并且,行区域分割部307将标记所属的行区域分割为已重叠在字符串的标记及未重叠标记的字符串(步骤s306,参照图9)。具体而言,行区域分割部307算出标记的位置及尺寸作为坐标,算出未重叠标记的字符串的位置及尺寸作为坐标。
转换率计算部308算出用于使行区域分割部307分割(步骤s306)后所得且已重叠在字符串的标记放大的放大率、或用于使行区域分割部307分割(步骤s306)后所得且未重叠标记的字符串缩小的缩小率(步骤s307)。转换率计算部308根据预先决定的放大率及缩小率中的任一者计算放大率及缩小率中的另一者。所谓预先决定放大率的情况是指例如用户使用操作部17在mfp1中预先设定放大率的情况、或用户使用操作部17在mfp1中预先设定空栏尺寸的情况(根据原有的字符尺寸与空栏尺寸预先决定放大率)。所谓预先决定缩小率的情况是指例如用户使用操作部17在mfp1中预先设定缩小率的情况、或用户使用操作部17在mfp1中预先设定缩小后的字符尺寸的情况(根据原有的(缩小前的)字符尺寸与缩小后的字符尺寸预先决定缩小率)。
优选的是,转换率计算部308以如下方式计算放大率或缩小率:包含有放大字符串的行区域在行区域内的字符排列方向上的长度为放大及缩小前的行区域的同方向上的长度以下。更优选的是,转换率计算部308在包含有放大字符串的行区域在行区域内的字符排列方向上的长度为放大及缩小前的行区域的同方向上的长度以下的范围内,以放大字符串成为最大尺寸的方式计算放大率,或以缩小字符串成为最大尺寸的方式计算缩小率。由此,尽管包含有放大字符串的行区域的长度相对变长,也无需换行等,所以能尽量运用原有的原稿图像的设计,且使空栏图像的尺寸相对变大。
优选的是,转换率计算部308是以如下方式计算放大率或缩小率:包含有放大字符串的字符串区域在多个行区域排列方向上的长度为放大及缩小前的字符串区域的同方向上的长度以下。更优选的是,转换率计算部308在包含有放大字符串的字符串区域在多个行区域排列方向上的长度为放大及缩小前的字符串区域的同方向上的长度以下的范围内,以放大字符串成为最大尺寸的方式计算放大率,或以缩小字符串成为最大尺寸的方式计算缩小率。由此,尽管包含有放大字符串的字符串区域的长度变得比原有的原稿图像长,也无须分页等,所以能尽量运用原有的原稿图像的设计,且使空栏图像的尺寸相对变大。
关于转换率计算部308对放大率及缩小率的计算方法,在下文叙述的各实施例中更具体地进行说明。
图像转换部309使经行区域分割部307分割(步骤s306)后所得且已重叠在字符串的标记以预先决定的或转换率计算部308计算(步骤s307)出的放大率放大,而作成放大字符串(严格而言是放大字符串的图像)。并且,图像转换部309使经行区域分割部307分割(步骤s306)后所得且未重叠标记的字符串以预先决定的或转换率计算部308计算(步骤s307)出的缩小率缩小,而作成缩小字符串(严格而言是缩小字符串的图像)(步骤s308)。图像转换部309将所作成的放大字符串及缩小字符串设计配置于作为输出对象的原稿(步骤s309)。所谓“设计”是指例如使多个行区域分别“居中”、“左对齐”(横向书写时)等。
空栏作成部305作成重叠在图像转换部309所作成(步骤s308)的放大字符串的空栏图像(步骤s310)。空栏图像可为单纯的空格,也可包含有预先决定的格式(下划线、矩形框、括弧、符号等)。
图像合成部306使图像转换部309所作成(步骤s308)的缩小字符串的图像以及空栏作成部305所作成(步骤s310)的空栏图像按照设计(步骤s309)而配置,作成合成图像(步骤s311)。
图像形成部16使图像合成部306所作成的合成图像形成(打印输出)在纸上(步骤s312)。
(4.实施例)
以下的各实施例中,对转换率计算部308的放大率或缩小率的计算方法进行具体说明。
图10是用于说明用以算出放大率或缩小率的算式中使用的变量的图。
各实施例中,字符为“横向书写”。以下,将行区域内的字符排列方向(图10的横向)上的长度定义为“宽度”。将字符串区域内的行区域排列方向(图10的纵向)上的长度定义为“高度”。将用于算出放大率或缩小率的算式中使用的变量定义如下。
以下全部是图像读取部12所读取的原稿图像内的值。
1个字符串区域内所含有的行区域的总数:l。
1个字符串区域内所含有的且包含有标记(图10中所示的阴影部分)的行区域的总数:lm。
字符串区域的宽度:x。
字符串区域的高度:y。
1个行区域内所含有的且已重叠在字符串的标记的合计宽度:xm。
已重叠在字符串的各标记的高度:ym。
包含有标记的行区域内所含有的且未重叠标记的字符串的合计宽度:xn。
未重叠标记的字符串的高度:yn。
用于由已重叠在字符串的标记作成放大字符串的放大率:α(α>1)。
用于由未重叠标记的字符串作成缩小字符串的缩小率:β(0<β<1)。
以下的各实施例中所示的算式都包含有放大率α及缩小率β。放大率α及缩小率β中的任一者都作为变量而预先决定。结果,能算出放大率α及缩小率β中的另一者。
为求方便,图像转换部309的放大/缩小后的尺寸称为如下。它们并非变量。
包含有标记的行区域的宽度:x’。
字符串区域的高度:y’。
(4-1.实施例1)
图11是用于说明实施例1中的放大率或缩小率的计算方法的图。
图11中表示在1个字符串区域所含有的多个行区域中的1个行区域,包含有1个标记、及未重叠1个标记(图11所示的阴影部分)的字符串的情况。此情况下,式1及式2成立即可。
[式1]
y’=αym+β(y1+y3+y4+···+yl)≦y
αym是放大后且包含有标记的行区域的高度的合计值。
β(y1+y3+y4+···+yl)是缩小后且不含标记的多个行区域的高度的合计值。
y’≦y成立。即,能使放大/缩小后的字符串区域的高度y’处于放大/缩小前的字符串区域的高度y以下。
[式2]
x’=αxm+βxn≦x
αxm是放大后的标记的宽度的合计值。
βxn是缩小后且未重叠标记的字符串的宽度的合计值。
x’≦x成立。即,能使放大/缩小后的包含有标记的行区域的宽度x’处于放大/缩小前的字符串区域的宽度x以下。
(4-2.实施例2)
以下,对于与已说明的实施例相同的方面省略说明,而以不同点为中心进行说明。
图12是用以说明实施例2中的放大率或缩小率的计算方法的图。
图12中表示在1个字符串区域所含有的多个行区域中的2个行区域内,包含有1个标记(图12所示的阴影部分)、及1个未重叠标记的字符串的情况。此情况下,式3、式4及式5成立即可。
[式3]
y’=α(ym1+ym2)+β(y1+y3+···+yl)≦y
[式4]
x’1=αxm1+βxn1≦x
[式5]
x’2=αxm2+βxn2≦x
(4-3.实施例3)
图13是用于说明实施例3中的放大率或缩小率的计算方法的图。
图13中表示在1个字符串区域所含有的多个行区域中的1个行区域,包含有1个标记(图13所示的阴影部分)、及2个未重叠标记的字符串的情况。
x=10、y=12、l=6、xm=2、xn=5+3、yn=2、ym=2、α=1.4预先作为变量而决定。
若将这些变量代入式1及式2,则成为式6及式7。
[式6]
y’=1.4×2+β(2+2+2+2+2)≦12
根据式6,β≦0.92。
[式7]
x’=1.4×2+β(5+3)≦10
根据式7,β≦0.9。
在满足β≦0.92及β≦0.9两者的范围内,缩小率β的最小值(即,缩小字符串成为最大尺寸的缩小率β的值)为0.9。为了提高视认性,可采用缩小字符串成为最大尺寸的缩小率,所以此情况下可为β=0.9。
(4-4.实施例4)
图14是用于说明实施例4中的放大率或缩小率的计算方法的图。
图14中表示在1个字符串区域所含有的多个行区域中的2个行区域分别含有标记(图14所示的阴影部分)而且2个行区域的标记的合计宽度xm彼此相等的情况。
x=10、y=12、l=6、从上数起第2行的xm1=3+2、从上数起第4行的xm2=4+1、从上数起第2行的xn1=2+3、从上数起第4行的xn2=1+4、yn=2、ym=2、α=1.2预先作为变量而决定。
若将这些变量代入式3、式4及式5,则成为式8、式9及式10。
[式8]
y’=1.2(2+2)+β(2+2+2+2)≦12
根据式8,β≦0.9。
[式9]
x’1=1.2×(3+2)+β(2+3)≦10
根据式9,β≦0.8。
[式10]
x’2=1.2×(4+1)+β(1+4)≦10
根据式10,β≦0.8。
在完全满足β≦0.9、β≦0.8及β≦0.8的范围内,缩小率β的最小值(即,缩小字符串成为最大尺寸的缩小率β的值)为0.8。为了提高视认性,可采用缩小字符串成为最大尺寸的缩小率,所以此情况下可为β=0.8。
(4-5.实施例5)
图15是用于说明实施例5中的放大率或缩小率的计算方法的图。
图15中表示在1个字符串区域所含有的多个行区域中的2个行区域分别包含有标记(图15的阴影部分)而且2个行区域的标记的合计宽度xm彼此不同的情况。
x=10、y=12、l=6、从上数起第2行的xm1=2、从上数起第4行的xm2=5、从上数起第2行的xn1=3+5、从上数起第4行的xn2=2+3、yn=2、ym=2、α=1.2预先作为变量而决定。
若将这些变量代入式3、式4及式5,则成为式11、式12及式13。
[式11]
y’=1.2(2+2)+β(2+2+2+2)≦12
根据式11,β≦0.9。
[式12]
x’1=1.2×2+β(3+5)≦10
根据式12,β≦0.95。
[式13]
x’2=1.2×5+β(2+3)≦10
根据式13,β≦0.8。
在完全满足β≦0.9、β≦0.95及β≦0.8的范围内,缩小率β的最小值(即,缩小字符串成为最大尺寸的缩小率β的值)为0.8。为了提高视认性,可采用缩小字符串成为最大尺寸的缩小率,所以此情况下可为β=0.8。
以上,已说明实施例1至实施例5,但还包括除此之外的例子,在放大率或缩小率的计算方法中,式14及式15成立即可。
[式14]
式14中,n表示包含有标记的行区域的数量,mn表示包含有标记的行区域内的标记,m表示不含标记的行区域的数量,lm表示不含标记的行区域。
[式15]
式15中,n表示包含有标记的行区域的数量,pn表示包含有标记的行区域,s表示行区域pn内的标记的数量,ms表示行区域pn内的标记,t表示行区域pn内的未重叠标记的字符串的数量,nt表示行区域pn内的未重叠标记的字符串。
(5.总结)
mfp1由包含有已重叠在字符串的标记的原稿图像作成以作了标记的字符串作为解答的填空题(空栏问题)。空栏内,有时会由回答者填写作为回答的字符串或符号,或由问题制作者填写符号等。若空栏小,则可能出现如下等情况:回答者难以填写作为回答的字符串或符号,或难以看见问题制作者所填写的符号等。
对此,根据本实施方式,图像转换部309将已重叠在字符串的标记放大而作成放大字符串,且使未重叠标记的字符串缩小而作成缩小字符串。空栏作成部305作成重叠在放大字符串的空栏图像。图像合成部306作成已将缩小字符串与空栏图像予以合成的合成图像。
这样,通过缩小空栏以外的字符串(未作标记的字符串)、放大空栏的尺寸,能尽量运用原有的原稿图像的设计,且使空栏的尺寸相对放大。
(iv.第4实施方式)
(1.概要)
根据第4实施方式,从原稿图像抽取与已重叠着标记的字符串相同的未重叠标记的字符串,作成分别重叠在已重叠着标记的字符串及所抽取的字符串的多个空栏图像。
(2.图像形成装置的功能性结构)
图16是表示第4实施方式中的图像形成装置的功能性结构的框图。
mfp1通过执行信息处理程序而作为标记抽取部401、标记判定部402、字符抽取部403、字符识别部411、字符串比较部413、空栏作成部405及图像合成部406发挥功能。
标记抽取部401从图像读取部12所读取的原稿图像抽取已重叠在字符串的标记。
标记判定部402对标记抽取部401所抽取的标记在原稿图像内的位置及形状进行判定。
字符抽取部403从图像读取部12所读取的原稿图像抽取多个字符。
字符识别部411参照ocr用数据库112,对字符抽取部403所抽取的多个字符分别进行识别。字符识别部411根据标记判定部402所判定的标记的位置及形状,利用字符代码的组合来识别已重叠着标记的字符串。
字符串比较部413从字符识别部411所识别的多个字符抽取与字符识别部411所识别的已重叠着标记的字符串相同的未重叠标记的字符串。
空栏作成部405作成分别重叠在字符串比较部413所抽取的未重叠标记的字符串、及已重叠着标记的字符串的空栏图像。
图像合成部406作成已将图像读取部12所读取的原稿图像、及空栏作成部405所作成的空栏图像予以合成的合成图像。
(3.图像形成装置的动作)
图17是表示图像形成装置的动作的流程图。图18是用于说明图像形成装置的动作的图。
作为前提,在原稿(典型的是纸)上印有作为文本数据的字符串。或者,在原稿上,形成作为图像数据的字符串的图像(复制印有字符串的原稿)。并且,字符串整体中的多个一部分的字符串(复合词、短语、数值等)由作为用户的问题制作者使用荧光标记笔等以手写的方式作标记。作了标记的字符串是填空题中作为解答的字符串。
图像读取部12对原稿进行光学扫描,读取原稿图像(步骤s401,参照图18)。作为“原稿图像”,整体而言是包含有多数字符串的文档原稿的图像数据,包括已重叠在多个字符串的多个标记(图18中所示的阴影部分)。“字符串”是语句(单词、短语、文章等)、数值等,严格而言是其图像。
标记抽取部401从图像读取部12所读取的原稿图像抽取已重叠在字符串的标记(步骤s402)。具体而言,标记抽取部401抽取明度及/或彩度等与背景(白色等)不同且具有特定的形状及尺寸(特定宽度的带状的长方形等)的区域作为标记。
标记判定部402对标记抽取部401所抽取的标记在原稿图像内的位置及形状进行判定(步骤s403)。具体而言,标记判定部402将原稿图像整体作为坐标系整体,将标记的位置及形状作为坐标算出。
另一方面,与步骤s402及步骤s403并行地,字符抽取部403从图像读取部12所读取的原稿图像抽取多个字符(步骤s404)。具体而言,字符抽取部403通过边缘检测而抽取原稿图像所含有的所有字符。换而言之,字符抽取部403通过边缘检测而将原稿图像分解为1个1个的字符。即,“字符”是原稿图像所含有的1个1个的字符(根据语言,也可为1个1个的单词),严格而言是其图像。
字符识别部411参照ocr用数据库112,对字符抽取部403所抽取的多个字符分别进行识别(步骤s405)。具体而言,在ocr用数据库112中,字符的图像图案与字符代码对应地且逐个字符地注册。字符识别部411从ocr用数据库112中检索出表示字符抽取部403所抽取的字符的图像图案,获取与经检索而得的图像图案对应的字符代码。字符识别部411针对原稿图像所含有的所有字符获取字符代码。
字符识别部411根据标记判定部402所判定的标记的位置及形状,识别已重叠着标记的字符串。字符识别部411针对已重叠着标记的字符串,通过将已重叠着标记的字符串所含有的所有字符各自的字符代码进行组合,从而利用该组合的字符代码来进行识别(步骤s406)。
字符串比较部413从字符识别部411所识别的多个字符抽取与字符识别部411所识别的已重叠着标记的字符串相同的未重叠标记的字符串(步骤s407,参照图18)。具体而言,字符串比较部413对于已重叠着标记的字符串的字符代码的组合与未重叠标记的字符的字符代码进行比较。并且,字符串比较部413抽取与已重叠着标记的字符串的字符代码的组合相同且原稿图像所含有的所有未重叠标记的字符中的连续的字符代码的组合。图18所示的例中,抽取字符串“def”及“yz”。
若字符串比较部413抽取与已重叠着标记的字符串相同的未重叠标记的字符串(步骤s408中为是),则空栏作成部405作成已分别重叠着字符串比较部413所抽取的未重叠标记的字符串(步骤s409)及已重叠着标记的字符串的空栏图像(步骤s410,参照图18)。另一方面,若字符串比较部413未抽取与重叠着标记的字符串相同的未重叠标记的字符串(步骤s408中为否),则空栏作成部405作成已重叠在重叠着标记的字符串的空栏图像(步骤s410)。具体而言,空栏作成部405作成消除了字符抽取部403通过边缘检测所抽取的字符(步骤s404)、及已重叠着标记时的从该字符露出的标记的边缘部分的形状及位置(坐标)的空栏图像。空栏图像可为单纯的空格,也可包含有预先决定的格式(下划线、矩形框、括弧等)。图18所示的例中,空栏图像包含有下划线。
图像合成部406作成已将图像读取部12所读取的原稿图像(步骤s401)、空栏作成部405所作成的空栏图像(步骤s409、s410)予以合成的合成图像(步骤s411,参照图18)。具体而言,图像合成部406将形状及位置由坐标定义的空栏图像配置在原稿图像的坐标系。图18所示的例中,合成了原稿图像、及包含有下划线的空栏图像。
图像形成部16将图像合成部406所作成的合成图像形成在(打印输出)纸上(步骤s412)。
(4.变化例)
实施方式中,空栏图像为单纯的空格等,但亦可对空栏图像分配符号(数字、字符、符号等)。
即,一变化例中,字符串比较部413对已重叠着标记的字符串、及与其相同的未重叠标记的字符串分配相同的符号(数字、字符、符号等)。
图像合成部406作成将图像读取部12所读取的原稿图像、空栏作成部405所作成的空栏图像、及作为字符串比较部413所分配的符号的图像的符号图像予以合成的合成图像。具体而言,图像合成部406通过将预先决定的格式(字体、尺寸等)的符号配置在原稿图像中配置的空栏图像的预先决定的位置(中央、左端等),而作成合成图像。
实施方式中,图像读取部12读取原稿图像(步骤s401)。取而代之,mfp1也可通过网络通信部13而从连接于网络的信息处理装置(未图示)接收原稿图像。
(5.总结)
当利用原有原稿作成填空题时,1个文章中,作为解答的字符串有时会出现多次。此情况下,由于作为解答的字符串直接显示在文章中会成为提示,所以作为解答的相同的字符串须要全部为空栏。然而,问题制作者利用手动作业抽取作为解答的所有相同的字符串不仅费事,而且确实难以抽取所有相同的字符串。
对此,根据实施方式,mfp1从原稿图像抽取与已重叠着标记的字符串相同的未重叠标记的字符串(步骤s407),作成分别重叠在已重叠着标记的字符串及所抽取的字符串的多个空栏图像(步骤s409、步骤s410)。由此,能确实使作为解答的相同字符串全部成为空栏。因此,不会出现作为解答的字符串直接显示在文章中而成为提示的现象,而且问题制作者无需花费工夫利用手动作业抽取作为解答的所有相同的字符串。
而且,若对应解答为相同的字符串的多个空栏分配不同的符号,则回答者可能会误解为应回答不同的语句。为了防止此现象,问题制作者利用手动作业对应解答为相同的字符串的多个空栏分配相同的符号较为麻烦。尤其是,当空栏的总数较多时、或有多组相同字符串时等,若问题制作者利用手动作业分配符号,则还可能会分配错误的符号。
对此,根据变化例,mfp1对已重叠着标记的字符串、及与其相同的未重叠标记的字符串分配相同的符号。由此,可消除由于向应解答为相同的字符串的多个空栏分配不同的符号,回答者会误解为应回答不同的语句的情况。而且,问题制作者不需要花费工夫向应解答为相同的字符串的多个空栏利用手动作业分配相同的符号,而且,也不会分配错误的符号。
另外,各实施方式中,已对于标记着具有多个字符的字符串时的处理进行了说明,但在标记着由1个字符所构成的字符串时,也可按照图17进行处理。此情况下,在图17所示的步骤s406中,字符串识别部411无需将字符串中所含有的所有字符各自的字符代码组合,只要根据已重叠着标记的1个字符的字符代码识别字符即可。而且,在图17所示的步骤s407中,字符串识别部411可针对已重叠着标记的1个字符的字符代码与未重叠标记的字符的字符代码进行比较,抽取与已重叠着标记的1个字符的字符代码相同且原稿图像所含有的所有未重叠标记的字符。
而且,当标记着1个字符(根据语言,可为1个单词)时,可不执行图17所示的处理。一般而言,相同的原稿中,相同的1个字符有时会采用分别不同的使用方法。此时,能防止非用户预期的1个字符成为空栏。
- 还没有人留言评论。精彩留言会获得点赞!