信息处理装置的制作方法
本发明涉及处理i/o指令的信息处理装置。
背景技术:
近年来,以灵活用于商业为目的,高速解析大量的数据的技术受到瞩目。一般而言,服务器的主处理器(以下称为处理器)从hdd(harddiskdrive:硬盘驱动器)等存储设备读出数据并进行数据的解析和运算。
作为存储设备,正在普及与hdd相比能够高速地进行访问的、以闪存为存储介质的ssd(solidstatedrive:固态驱动器)。进而,reram(resistancerandomaccessmemory:电阻随机存取存储器)或pcm(phasechangememory:相变存储器)等与闪存相比能够高速地访问的半导体存储介质的实用化正在推进。
由于这样的存储设备的出现,高速地读出大量数据成为可能。但是,处理器的处理负荷高、与处理器连接的总线的带宽成为瓶颈而导致数据传送需要花费时间,因此无法有效利用高速的存储设备的性能,作为信息处理装置无法高速化。
现有技术中,已知有通过在信息处理装置中添加具有运算功能的装置(以下称为加速器),使原本处理器执行的处理的一部分分散于该加速器的技术。例如,存在如下所述的技术:在具有处理器的服务器中添加gpu(graphicsprocessingunit:图形处理单元)作为加速器,由gpu对处理器执行的程序处理的一部分进行处理,由此实现处理速度的提高。
该技术是数据传送较多的技术,即,处理器从存储设备将处理对象数据传送到与处理器连接的系统存储器,进而处理器从系统存储器对加速器传送数据,由此gpu能够处理数据。特别是因为数据在与处理器连接的总线往复,所以该总线的带宽成为性能提高的瓶颈。
专利文献1中记载有一种信息处理装置,其目的在于,为了消除该数据传送瓶颈,加速器和存储设备不经由处理器而直接通信,由此进一步提高处理速度。
专利文献1的技术中,在具有处理器和系统存储器的信息处理装置连接基板,gpu与非易失性存储器阵列成一对地搭载于该基板上,在gpu与非易失性存储器阵列间直接进行数据传送。由于非易失性存储器阵列的数据被传送到gpu,仅该gpu的处理结果被传送到与处理器连接的总线,所以能够消除总线的带宽因向系统存储器的访问而被压迫的情况。
现有技术文献
专利文献
专利文献1:美国专利申请公开第2014/129753号说明书
技术实现要素:
发明要解决的课题
专利文献1中关于在信息处理装置的初始化时gpu如何确定成为访问目的地的非易失性存储器阵列则没有记载。存在如下课题:若作为pci-express(以下称为pcle)的末端而连接有存储设备和加速器,则加速器无法确定成为访问目的地的存储设备的指令接口的地址。还存在如下课题:若加速器无法确定存储设备的指令接口的地址,则根本就无法访问存储设备来读出数据并执行处理器的一部分处理。
因此,本发明的目的是提供一种信息处理装置,加速器确定出存储设备后加速器从存储设备读出数据,并且加速器执行处理器的一部分处理。
用于解决课题的手段
本发明是一种信息处理装置,其具有处理器和存储器,并且包括1个以上的加速器和1个以上的存储设备,所述信息处理装置具有将所述处理器与所述加速器和所述存储设备连接的一个网络,所述存储设备具有从所述处理器接受初始化命令的初始设定接口和发行i/o指令的i/o发行接口,所述处理器对所述加速器通知所述初始设定接口的地址或者所述i/o发行接口的地址。
发明效果
根据本发明,能够由加速器确定出存储设备的指令接口的地址,从存储设备读出数据,并执行处理器的一部分处理,从而能够使信息处理装置的处理高速化。
附图说明
图1表示本发明的第一实施例,是表示信息处理装置将数据库的过滤处理卸载到加速器板的概念的图。
图2表示本发明的第一实施例,是表示信息处理装置的构成的一例的框图。
图3表示本发明的第一实施例,是在信息处理装置进行了i/o发行处理的情况的说明图。
图4表示本发明的第一实施例,是表示在信息处理装置进行的初始化处理的一例的时序图。
图5表示本发明的第一实施例,是信息处理装置使fpga执行数据库的过滤处理的例子的时序图。
图6表示本发明的第一实施例,是表示主处理器的i/o和加速器板的i/o同时存在时的处理的一例的时序图。
图7表示本发明的第一实施例的变形例,是表示向1个pcle开关连接了存储设备和加速器板的多个组的构成的一例的框图。
图8表示本发明的第一实施例的变形例,是表示存储设备与加速器板之间的跳数的表格。
图9a表示本发明的第一实施例的变形例,是表示加速器板的处理性能的表格。
图9b表示本发明的第一实施例的变形例,是表示存储设备的性能的表格。
图10表示本发明的第一实施例,表示在存储设备发生了故障时在信息处理装置进行的处理的一例的时序图。
图11表示本发明的第一实施例,是表示在加速器板发生了故障时在信息处理装置进行的处理的一例的时序图。
图12表示本发明的第一实施例,是表示在加速器板发生了故障时在信息处理装置进行的重新分配处理的一例的时序图。
图13表示本发明的第一实施例,表示在初始化完成的状态下新追加存储设备或者加速器板的信息处理装置的一例的框图。
图14表示本发明的第一实施例,是表示在信息处理装置初始化完成后追加了新的存储设备时的处理的一例的时序图。
图15表示本发明的第一实施例,是表示在信息处理装置初始化完成后追加了新的加速器板时的处理的一例的时序图。
图16表示本发明的第一实施例的变形例,是表示信息处理装置的一例的框图。
图17表示本发明的第二实施例,是表示信息处理装置的一例的框图。
图18表示本发明的第二实施例,是表示在信息处理装置进行的数据库处理的一例的时序图。
图19表示本发明的第三实施例,是表示信息处理装置的一例的框图。
图20表示本发明的第三实施例,是表示在信息处理装置进行的初始化处理的一例的时序图。
图21表示本发明的第一实施例,是表示信息处理装置的一例的框图。
具体实施方式
以下使用附图说明本发明的实施方式。
首先,作为本发明的概要,针对进行数据库处理(以下称为db处理)的信息处理装置10进行说明。
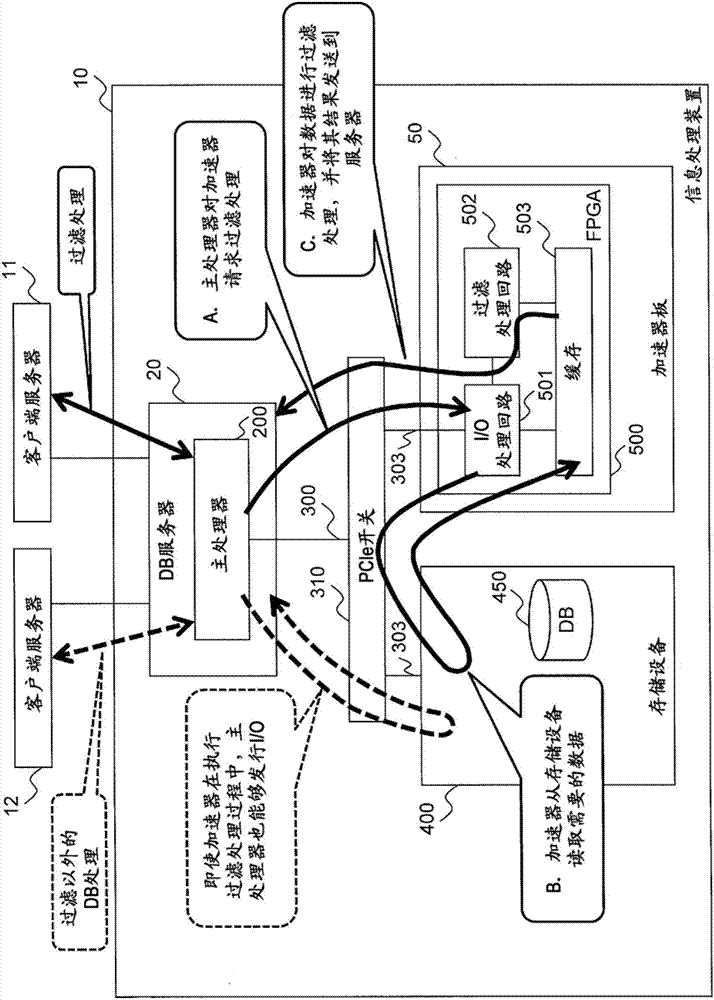
图1是表示本发明的思想的框图。图1是包括信息处理装置10和利用信息处理装置10的客户端服务器11、12的计算机系统,信息处理装置10搭载有以卸载数据库处理的过滤处理为前提的加速器板50。
过滤处理是比较成为对象的数据库(以下称为db)和条件式,仅提取与条件式一致的db的处理,特别是在所述条件式复杂的情况、或成为所述对象的db的数据量多的情况下,会对信息处理装置10的主处理器200施加高的负荷,因此向加速器板50的卸载是有效的处理。
在加速器板50搭载例如fieldprogrammablegatearray(现场可编程门阵列)(以下称为fpga)、graphicsprocessingunit(图形处理单元)(以下称为gpu)、副处理器等。加速器板50通常搭载于带有pcle接口的基板等上,并作为加速器利用于信息处理装置10。
图1的信息处理装置10中包括:带有进行数据库处理的主处理器200(以下称为处理器)的数据库服务器20(以下称为db服务器);保存有数据库(以下称为db)450的存储设备400;和搭载有能够卸载主处理器200的处理的fpga500的加速器板50。此外,数据库处理是例如dbms(databasemanagementsystem:数据库管理系统)进行的处理。
主处理器200、存储设备400、加速器板50和fpga500利用pcle总线300、303与pcle开关310相互连接。此外,加速器板50和fpga500映射于db服务器20(主处理器200)的存储器空间上,能够使用该存储器映射上的地址相互通信,将其称为一个网络。
fpga500中包括:i/o处理电路501,其具有接受来自主处理器200的访问的功能和进行来自fpga500的i/o发行的功能(具体而言,pcle末端功能和pcle末端的控制功能);能够高速地执行过滤处理的过滤处理电路502;和临时存储db450的数据的缓存503,它们通过内部总线相互连接。
i/o处理电路501和过滤处理电路502两者都可以作为fpga500的硬件电路安装,也可以通过fpga500内部的嵌入式处理器实现一部分或者全部的功能。此外,本实施例中,作为加速器板50使用fpga500进行说明,但是也可以采用gpu和副处理器。
客户端服务器11和12是利用由信息处理装置10管理的db450的应用程序所运行的服务器,向db服务器20请求db处理。
db服务器20从客户端服务器11、12接收使用过滤处理的命令,作为db服务器20将过滤处理卸载到fpga500的顺序,说明a~c。
db服务器20的主处理器200对fpga500发行指示过滤处理的执行的指令(a)。接收到指令的fpga500的i/o处理电路501对存储设备400发行读取命令,获取成为过滤处理的对象的db450的数据,并将其存储在fpga500的缓存503(b)。
接着,过滤处理电路502从缓存503读出i/o处理电路501所读取的db450的数据,进行过滤处理,并将该过滤处理结果作为结果数据发送到db服务器20(c)。
通过以这样的顺序进行过滤处理,在与db服务器20连接的总线300中,db450的数据其本身不流动,仅流动指令和结果数据,所以与所述现有例的顺序相比,能够减少在总线300流动的数据量。
此外,由于能够在信息处理装置10连接多个客户端服务器11、12,所以有可能在例如客户端服务器11请求过滤处理的期间,其他的客户端服务器12请求过滤处理以外的db处理(例如更新处理)。
该情况下,主处理器200需要对存储设备400进行i/o访问,但是在fpga500执行过滤处理中,信息处理装置10的主处理器200也能够对存储设备400发行i/o,并行执行多个处理,能够发送被客户端服务器11、12所请求的处理的结果。
实施例1
接着,使用图2~6,详细说明本发明的实施例1。
图2是表示适用本发明的信息处理装置10的构成的一例的框图。
信息处理装置10包括db服务器20和扩展器30。db服务器20具有处理器200、系统存储器210和芯片组220,它们由内部总线230连接。在芯片组220中pcle根联合体221发挥功能,经由pcle总线2300与pcle开关2310连接。
在芯片组220连接有具有输入装置和输出装置(例如、显示器)的终端180。在系统存储器210中加载os110、pcle驱动器130、dbms120并由主处理器200执行。
pcle驱动器130控制与pcle网络上连接的存储设备或者加速器。其中,pcle驱动器130也可以包括在os110中。dbms120在访问与pcle总线2300连接的装置时经由pcle驱动器130访问各装置。
扩展器30包括2个存储设备400、410、2个加速器板50、51、pcle开关2310、2320、2330,它们分别经由pcle总线2300~2304与db服务器20连接。
存储设备400和加速器板50经由pcle总线2303与pcle开关2320连接。pcle开关2320经由pcle总线2301与pcle开关2310连接。
同样,存储设备410和加速器板51经由pcle总线2304与pcle开关2330连接。pcle开关2330经由pcle总线2302与pcle开关2310连接。
因为加速器板50、51和存储设备400、410映射在db服务器20的存储器空间上,所以图2那样的构成也是一个网络。本实施例中使用pcle总线,所以称为pcle网络。这样,一个网络不限定于如图1的存储设备400和加速器板50那样仅夹着一级pcle开关310的构成。即使如图2的pcle开关2310、2320、2330那样是夹着多级开关的构成,只要映射在db服务器20(主处理器200)的存储器空间上即可。
加速器板50、51分别搭载fpga500、510。在fpga500中具有i/o处理电路501、过滤处理电路502、缓存503,它们相互连接。虽然未图示,但是fpga510也与fpga500同样地构成。
存储设备400是能够使用nvm(nonvolatilememory:非易失性存储器)express协议(以下称为nvme)进行通信的存储设备,具有i/o控制器401和数据库保存区域404。在数据库保存区域404保存db450。数据库保存区域404能够由例如闪存、reram(resistancerandomaccessmemory:电阻随机存取存储器)、pcm(phasechangerandomaccessmemory:相变随机存取存储器)等非易失性存储介质构成。再者,虽然未图示,但是存储设备410也与存储设备400同样地构成。
存储设备400的数据库保存区域404,没有直接映射在db服务器20(主处理器200)的存储器空间上,仅映射指令接口。主处理器200和fpga500无法使用pcle总线2300~2304直接访问数据库保存区域404。因此,主处理器200和加速器板50通过向存储设备400发行i/o指令(读取指令/写入指令),实施向数据库保存区域的读取写入。
即,在系统存储器210中,通过os110对地址空间分配系统存储器210的存储元件来管理访问。与之相对,在nvme和sata中,以区块为单位管理数据库保存区域404,但不将全部的区块分配给系统存储器210的地址空间(逻辑块),通过指令的交换来实现访问。
i/o控制器401接收来自存储设备400、410外部的i/o指令,根据指令进行以下的处理。在读取指令的情况下从数据库保存区域404读出对应的读取地址的数据,并将其写入到读取数据的请求目的地地址。在写入指令的情况下,从写入数据发送源的地址读取写入数据,并将其保存在与写入地址对应的数据库保存区域404。
i/o控制器401包括进行运算处理的处理器402、包括多个队列的指令接口405、和保存用于进行处理的信息的管理信息保存区域403。
指令接口405具有:admin队列406,其用于接受主要在初始化(在nvme中生成(或者有效化)i/o发行队列的功能等)或者错误时使用的admin指令;主处理器用i/o发行队列407(以下称为处理器队列),其用于接受来自主处理器200的i/o指令;和fpga用i/o发行队列408(以下称为fpga队列),其用于接受来自fpga500的i/o指令。再者,以下将处理器队列407和fpga队列408总称为i/o发行队列。
这些i/o发行队列作为指令接口405与存储设备400的管理用寄存器等共同映射于pcle网络的地址空间(mmio空间)。
再者,admin队列406、处理器队列407和fpga队列408是分别被分配了不同的地址的独立的队列。这些admin队列406、处理器队列407和fpga队列408的地址在pcle网络的地址空间被分配于存储设备的指令接口405内。pcle网络的地址空间能够由在db服务器20运行的os110或者pcle驱动器130来分配。
db服务器20的主处理器200或者fpga500使用这些i/o发行队列发行i/o指令时,检测到i/o指令的存储设备400的处理器402进行写入或者读取这样的i/o指令处理。
在电源起动时的存储设备400中,i/o发行队列不成为有效,而仅admin队列406为有效。通过主处理器200对该admin队列406发行i/o发行队列的生成(或者有效化)命令(或者初始化的命令),接收到该命令的处理器402使例如处理器队列407有效。
然后,处理器402对db服务器20的主处理器200发送生成了(或者有效化)主处理器队列407的通知,主处理器200能够使用处理器队列407。
此处,将使用了该admin队列406的i/o发行队列407~408的有效化称为生成i/o发行队列。在存储设备400准备有多个i/o发行队列,其有效还是无效的信息保存在i/o控制器401的管理信息保存区域(例如dram等易失性存储介质、或者闪存、reram、pcm等非易失性存储介质)403。
再者,admin队列406接受来自主处理器200的初始化的命令,作为用于生成和管理i/o发行队列407、408的初始设定接口起作用。此外,i/o发行队列407、408作为接受来自主处理器200和fpga500的i/o指令的i/o发行接口起作用。
图2中,存储设备400具有3个i/o发行队列407~409,其中,对主处理器200分配处理器队列407并使其有效,对fpga500分配fpga队列408并使其有效,i/o发行队列409为无效。
成为无效的i/o发行队列409能够分配给其他处理器或者fpga。例如,可以使主处理器200为双核处理器,将其一个核分配给处理器队列407,将另一个核分配给i/o发行队列409,成为不进行核间的排他处理而各核能够进行i/o发行的状态。或者,也可以对fpga500分配fpga队列408,对fpga510分配i/o发行队列409,而成为能够从多个fpga对一个存储设备400发行i/o命令的状态。
图2中,存储设备400具有3个i/o发行队列,但是其个数不限定于3个,几个都可以。
图3是由信息处理装置10进行了i/o发行处理的情况的说明图。此处,使用图3说明使主处理器200用和fpga500用独立地来准备i/o发行队列的必要性。
例如,在nvme的技术中,存储设备400的处理器队列407由供主处理器200进行写入的寄存器构成,主处理器200记录i/o指令发行的累计个数。
主处理器200发行的i/o指令能够保存在i/o控制器401的管理信息保存区域403中。或者,也可以将主处理器200发行的i/o指令保存在系统存储器210的规定区域。对于主处理器200发行的i/o指令的保存目的地,使用周知或者公知的技术即可,因此本实施例中不详述。
另一方面,存储设备400的处理器200(402?)将过去处理的指令数存储在管理信息保存区域403中。例如,如果处理器队列407的值和管理信息保存区域403的值的任一者的值均成为4,则表示过去主处理器200发行了4个指令,存储设备400将该4个指令全部处理完毕。
使用图3的a~c说明从主处理器200对存储设备400新发行1个i/o指令的处理。首先,主处理器200在系统存储器210的规定地址生成i/o指令(a)。
接着,主处理器200在处理器队列407写入对当前值=“4”加上1所得的值=“5”(b)。
与之相对,i/o控制器401的处理器402检测到处理器队列407的值“5”与存储在管理信息保存区域403的、过去处理过的指令数=“4”的值具有差值,判断为有新的指令,从系统存储器210获取指令(c)。
由于主处理器200自身能够存储写入到处理器队列407的值,所以在下次的i/o发行时不用读取处理器队列407,能够容易地写入对过去的值加上1而得的值,能够高速地发行指令。
该情况下,若fpga500共有主处理器200和处理器队列407而要新发行i/o指令,则首先,必需读取一次处理器队列407,才能知道当前的值。
此外,fpga500需要与主处理器200进行排他处理,例如指示主处理器200不更新处理器队列407等。这些与通常的来自主处理器200的i/o发行相比存在不仅花费时间,还产生主处理器200无法发行i/o指令的时间,信息处理装置10整体的性能降低的问题。
另一方面,本实施例1的存储设备400中,对主处理器200用生成处理器队列407,对fpga500用生成fpga队列408。像这样在i/o控制器401具有针对主处理器200和fpga500而独立的i/o发行队列的情况下,在处理器200与fpga500之间,可以不进行排他处理和多余的i/o发行队列的读取,所以主处理器200和fpga500都能够高速地发行i/o指令。
图4是表示在信息处理装置10进行的初始化处理的一例的时序图。
在信息处理装置10的初始化开始时,主处理器200从系统存储器210获取自身所连接的pcle网络的构成信息(1000)。此外,本实施例的初始化处理由加载到系统存储器210的os110和pcle驱动器130执行。以下,将进行os110或者pcle驱动器130的处理的主体作为主处理器200进行说明。
在pcle网络中,具有pcle根联合体221的芯片组220在起动时检测与该芯片组220连接的pcle末端设备的网络构成,将检测结果(pci设备树等)保存在系统存储器210的规定区域中。主处理器200通过访问系统存储器210的规定区域,能够获取所存储的pcle网络(或者总线)的构成信息。
作为pcle网络的构成信息,能够包括网络(或者总线)上的设备的位置、设备的性能、设备的容量等。pcle网络的构成信息在os110或者pcle驱动器130的起动时由主处理器200收集,并保存在系统存储器210的规定区域。
接着,主处理器200使用所获取的pcle网络的构成信息,分配访问存储设备400、410的加速器板50、51(1001)。分配所使用的信息使用例如存储设备400、410与加速器板50、51之间的距离的信息。其中,对加速器板50分配存储设备400、410的处理能够以pcle驱动器130或者os110成为主体的方式进行。以下,将执行pcle驱动器130或者os110的主处理器200作为分配的主体进行说明。
作为距离的信息,能够使用例如pcle网络的跳数。本实施例中,将通过pcle开关2310、2320、2330的个数(或者次数)作为跳数。
在fpga500与存储设备400的通信中,由于通过一个pcle开关2320,所以跳数=1。另一方面,fpga510与存储设备400之间通过pcle开关2310、2320、2330,跳数=3。因此,图2的构成中,将跳数少的fpga500分配给存储设备400。通过同样的距离的信息的比较,对存储设备410分配fpga510。
再者,存储设备400和加速器板50的分配不限定于一对一。例如,主处理器200能够对存储设备400分配fpga500和fpga510两者,或者也能够将fpga500分配给存储设备400和存储设备410两者。
接着,主处理器200对存储设备400发送生成i/o发行队列的指令(1002)。此处,与pcle根联合体221连接的主处理器200能够获取存储设备400的i/o控制器401具有的、admin队列406的地址。另一方面,如所述课题中也已陈述的那样,作为pcle末端的fpga500无法获取同样作为pcle末端的admin队列406的地址。
因此,主处理器200使用存储设备400的admin队列406,生产用于自身对存储设备400发行i/o指令的处理器队列407和用于fpga500对存储设备400发行i/o指令的fpga队列408这两个队列(1002)。
接着,主处理器200对fpga500通知fpga队列408的队列信息(fpga队列408的地址和最大同时发行指令数(队列的深度))(1003)。
这样,如果有最低限fpga队列408的地址和队列的深度,则fpga500能够对存储设备400发行i/o指令。进而,作为队列信息,还可以包括存储设备400的pcle(或者pci)配置寄存器(省略图示)的地址和能够访问的lba(logicalblockaddress:逻辑块地址)的范围(能够访问的起始lba和容量等)等信息。
例如,若fpga500能够获取存储设备400的pcle配置寄存器的地址,则还能够获取存储设备400的nvme寄存器(省略图示)的地址。fpga500能够根据这些地址计算能够访问的lba的范围。在fpga500使用能够访问的lba的范围对例如一台加速器板50分配了多个存储设备400、410的情况下,fpga500能够判断对哪个存储设备发行i/o指令好。
再者,nvme寄存器是例如在“nvmexpress”(revision1.1bjuly2,2014、nvmexpressworkgroup刊)的第37页~第45页等记载的寄存器。
进而,主处理器200使用admin队列在存储设备410也同样生成处理器队列和fpga队列(1004),并将fpga队列的信息通知给fpga510(1005)。
通过以上图4的处理,fpga500能够向存储设备400发行i/o指令,此外,fpga510能够向存储设备410发行i/o指令。
再者,以主处理器200使用admin队列406生成处理器队列407和fpga队列408的顺序为例进行了说明,但是也可以是,主处理器200对fpga500通知admin队列406的地址,fpga500生成处理器队列407和fpga队列408。
通过以上图3、图4的处理,作为pcle网络的末端而连接的加速器板50的fpga500能够从主处理器200获取fpga队列408的队列信息。由此,能够从pcle末端的fpga500对同样为pcle末端的存储设备400发行i/o指令,加速器板50能够访问保存在存储设备400的db450的数据。
图5是表示在信息处理装置10的初始化完成后主处理器200使fpga500执行数据库450的过滤处理的例子的时序图。
执行dbms120的主处理器200首先对fpga500发行指示过滤处理的过滤处理指令(1101)。该过滤处理指令中至少包括:表示执行过滤处理的数据库450的表格的排头位于存储设备400的db保存区域404的地址的哪里的信息;和执行过滤处理的db450的大小的信息、过滤处理的条件式=a。再者,过滤处理指令中除此之外还可以包括保存过滤处理的结果数据的系统存储器210的地址。
过滤处理指令是包括例如表格的排头为存储设备400的lba=0x1000,并按1m(兆)字节的数据执行过滤条件式=a的过滤处理这样的信息的指令。
此外,过滤处理指令的发行目的地(fpga500或者fpga510)也可以由dbms120或者pcle驱动器130的任一个决定。在pcle驱动器130进行决定的情况下,dbms120发行过滤处理指令时,pcle驱动器130决定发行目的地(fpga500或者fpga510)而发送过滤处理指令。
从执行dbms120的主处理器200接收到过滤处理指令的fpga500的i/o处理电路501,根据过滤处理指令的信息对存储设备400发行读取指令(1102)。该读取指令可以是一次,也可以是多次。图示的例子中,表示fpga500将对1m字节的读取分为4次而按每256k字节发行4个读取指令的例子。
4个读取指令通过例如对于lba=0x1000、0x1200、0x1400、0x1600的4次256k字节读取指令,fpga500读取将lba=0x1000作为排头的1m字节的数据。
从存储设备400的db保存区域404读取到的数据保存在fpga500的缓存503中(1103)。收到4次的读取完成通知的i/o处理电路501对过滤处理电路502进行指示以使得对缓存503的数据执行规定的过滤处理(1104)。
接受了指示的过滤处理电路502执行过滤条件式=a的过滤处理。
接着,过滤处理电路502将过滤处理的结果发送到db服务器20的系统存储器210(1105)。发送目的地的地址可以由过滤处理指令指定,也可以为预先设定的固定地址。
过滤处理完成后,过滤处理电路502将完成通知发送到i/o处理电路501(1106)。接收到完成通知的i/o处理电路501对主处理器200通知过滤处理的完成,并且主处理器200接收到该完成通知,由此一系列的过滤处理完成(1107)。
此外,图5中,说明了作为保存过滤处理的结果数据的地址而使用系统存储器210的地址的例子,但是过滤处理的结果数据的保存目的地地址不限定于此。例如,如果是表示存储设备400的地址的信息,则在存储设备400写入过滤处理的结果数据即可,如果是表示加速器板51的地址的信息,则在加速器板51写入过滤处理的结果数据即可,如果是表示加速器板50的地址的信息,则保存在加速器板50的存储器上即可。
此外,虽然表示了在过滤处理指令之中直接放入过滤条件式=a的例子,但是不限定于此,也可以是用于得到过滤条件式的信息。例如,也可以在系统存储器210上保存过滤条件式,并将该过滤条件式的保存地址放入过滤处理指令之中。
通过上述图5的处理,从与pcle总线的末端连接的加速器板50直接访问同样为末端的存储设备400,由此能够降低db服务器20的负荷。此外,db450的数据不通过pcle总线2300,而经由pcle开关2320被读入fpga500。因此,pcle总线2300的性能(传送速度等)不成为瓶颈,fpga500能够高速地执行过滤处理。特别是,以如图21那样pcle开关9000~9006构成为树状、且在其前端连接有存储设备9300、9400、9500、9600和加速器9301、9401、9501、9601那样的树状的构成将多个存储设备和加速器组连接时,本发明尤其能发挥效果。此时,加速器9031访问的存储设备全部是跳数为1的存储设备的情况下,从各存储设备9300、9400、9500、9600读取到的数据由pcle开关9003~9006关闭,所以即使增加存储设备和加速器的组也不使用树状的上位的pcle开关(9000、9001、9002)的带宽。由此,能够横向扩展过滤处理性能。
图6是表示主处理器200的i/o和加速器板50的i/o同时存在时的处理的一例的时序图。图6的例子是在fpga500执行过滤处理时,主处理器200在存储设备400进行读取的时序图。
与上述图5的过滤处理的时序图同样,执行dbms120的主处理器200首先对fpga500发行指示过滤处理的过滤处理指令(1111)。
从主处理器200接收到过滤处理指令的fpga500的i/o处理电路501根据过滤处理指令的信息对存储设备400发行读取指令(1112)。该情况下,fpga500使用在上述初始化时从主处理器200通知了地址的fpga队列408。此外,同时,主处理器200也对存储设备400发行了读取指令(1113)。该情况下,主处理器200使用处理器队列407。
图示的例子中,存储设备400执行fpga队列408的第一个读取指令,并将从db保存区域404读入的数据保存在fpga500的缓存503中(1114)。存储设备400将第一个读取指令的读取完成通知发送到fpga500(1115)。
接着,存储设备400执行处理器队列407的读取指令,并将从db保存区域404读入的数据保存在系统存储器210中(1116)。存储设备400将读取指令的读取完成通知发送到主处理器200(1117)。
使主处理器200的i/o处理完成了的存储设备400依次执行fpga队列408的第二个以后的读取指令,并将从db保存区域404读入的数据保存在fpga500的缓存503中(1118)。存储设备400将各读取指令的读取完成通知分别发送到fpga500(1119)。
收到了4次读取完成通知的i/o处理电路501对过滤处理电路502指示对缓存503的数据执行规定的过滤处理(1120)。接受了指示的过滤处理电路502执行规定的过滤处理。
接着,过滤处理电路502将过滤处理的结果发送到db服务器20的系统存储器210(1121)。过滤处理完成后,过滤处理电路502将完成通知发送到i/o处理电路501。接收到完成通知的i/o处理电路501对主处理器200通知过滤处理完成,主处理器200收到该完成通知,由此一系列的过滤处理完成(1122)。
如以上图5的处理那样,存储设备400通过初始化处理(图4)独立地设置处理器队列407和fpga队列408,使用任意队列都能够读取和写入db保存区域404的数据。因此,即使主处理器200和fpga500不进行排他处理,这些读取请求也会被正确地处理。
例如,图6中表示了正从fpga500向存储设备400发行4个读取指令时从主处理器200也发行了读取指令的例子,i/o控制器401中,fpga500和主处理器200写入读取指令的队列分别独立,所以不需要进行fpga500和主处理器200的排他控制。由此,信息处理装置10能够不降低处理性能地从fpga500和主处理器200并行地发行i/o指令。
接着,使用图7~图9说明在本实施例1中多个存储设备400和加速器板50与同一pcle开关连接的情况下的分配方法。
图7是表示将向1个pcle开关3320连接了存储设备和加速器板的多个组的构成的一例的框图。代替图2所示的pcle开关2320,图7的信息处理装置10在pcle开关3320和pcle总线3303添加存储设备410、420和加速器板52,而且在pcle驱动器130添加表格140~160。其他的构成与上述图2相同。
图8是表示存储设备400、410、420与加速器板50~52之间的跳数的跳数表格140。跳数表格140表示图7的存储设备400、410、430与fpga500、510、520之间的跳数的表格。跳数表格140由信息处理装置10的管理者等预先设定,并由pcle驱动器130管理,存储在系统存储器210中。
关于与pcle开关3330连接的存储设备410,跳数最少的加速器板51仅为fpga510,所以能够仅通过跳数对fpga510分配存储设备410。
另一方面,关于存储设备400、420、430,跳数最少的加速器板50、52存在多个。这样的情况下,可以在pcle网络构成中选择距离信息近的加速器板。该情况下,图7的构成中,对fpga500分配存储设备400和存储设备410。此外,对fpga520分配存储设备430。再者,作为pcle网络构成的距离信息,能够定义为pcle开关3320的端口编号越近则距离越近。
此外,os110或者pcle驱动器130也可以使用跳数等距离信息以外的信息来决定存储设备400和加速器板50的分配。该信息能够从存储设备和/或加速器板50获取,例如,具有图9a、图9b所示那样的加速器板50的过滤处理性能、存储设备的容量、存储设备的读取性能等。
图9a是表示fpga的过滤处理性能的fpga性能表格150。fpga性能表格150由fpga的标识符1511和过滤处理性能1512构成。fpga性能表格150可以由信息处理装置10的管理者等预先设定而由pcle驱动器130管理,并保存在系统存储器210中,还可以是pcle驱动器130在加速器识别时进行查询,并将其结果保存在系统存储器210中。
图9b是表示存储设备的性能的存储设备性能表格160。存储设备性能表格160由存储设备的标识符1601、容量1602和读取性能1603构成。存储设备性能表格160可以由信息处理装置10的管理者等预先设定而由pcle驱动器130管理,并保存在系统存储器210中,也可以是pcle驱动器130在存储设备识别时查询存储设备的性能,并将其结果保存在系统存储器210中。
图9a、图9b的例子中,os110或者pcle驱动器130也可以以将容量大的存储设备分配给处理性能高的设备这样的逻辑,对fpga500分配存储设备420,对fpga510分配存储设备400和存储设备430。
或者,os110或者pcle驱动器130还可以以使得加速器板的过滤性能和存储设备的读取性能平衡的方式对fpga500分配存储设备420,对fpga520分配存储设备400和410。
或者,也可以对fpga500分配存储设备400、存储设备420和存储设备430,对fpga510也分配存储设备400、存储设备420和存储设备430。该情况下,存储设备400、420、430的i/o控制器401,除了生成各个主处理器200用的处理器队列407以外,还能生成加上fpga500用的fpga队列408和fpga510用的fpga队列409这两个而得到的数量的i/o发行队列。主处理器200能够在使用了存储设备400、410、420、430的数据库450的过滤处理中并行使用fpga500和fpga510两者。
信息处理装置10中,通过进行这样的fpga和存储设备的分配,例如能够以存储设备的读取性能的合计与加速器板的过滤性能平衡的方式进行分配,能够采用在高负荷时存储设备和加速器板都能够发挥最大性能的构成等,实现信息处理装置10整体的性能的最优化。
接着,说明在本实施例1中在存储设备400产生了故障的情况下的处理的一例。图10是表示在存储设备400产生了故障时在信息处理装置10进行的处理的一例的时序图。
当存储设备400被分配给fpga500时,执行dbms120的主处理器200对fpga500发行过滤处理指令,对存储设备400的db450执行过滤处理(1201)。
fpga500接收过滤处理指令,为了读取成为处理对象的db450,对存储设备400发行读取指令(1202)。
但是,在该时刻存储设备400产生了故障的情况下(1203),例如存储设备400检测到自身的故障,经由pcle根联合体221对主处理器200通知故障(1204)。
接受了故障通知的主处理器200检测存储设备400的故障,并将该故障通知给fpga500(1205)。接收到故障的通知的fpga500,因为过滤处理尚未完成,所以将因故障而过滤处理失败了的情况通知给主处理器200。
上述图10的例子中,说明了存储设备400自身检测到故障并通知给主处理器200的例子,但是也可以是主处理器200监视存储设备400的状态,检测故障,对fpga500通知存储设备400的故障。
此外,也可以是fpga500通过轮询(polling)等检测在存储设备400产生了故障的情况。例如,也可以通过从fpga500对存储设备400发行的读取的超时等来进行检测。检测到故障的fpga500对主处理器200通知该故障和过滤处理失败了的情况。
通过这种方式检测到存储设备400的故障的主处理器200能够对db服务器20通知在存储设备400发生了故障的情况,并催促更换。例如,存在在db服务器20的管理画面显示告知产生故障的消息等的方法。此外,当具有通过镜像等方法而被保护的、存储设备400的备份设备时,能够代替存储设备400而使用该设备。
接着,对在本实施例1中在加速器板50产生了故障的情况下的处理的一例进行说明。图11是表示在加速器板50产生了故障时由信息处理装置10进行的处理的一例的时序图。
在存储设备400被分配给fpga500的情况下,执行dbms120的主处理器200指示fpga500进行对存储设备400的db450的过滤处理(1211)。
但是,在该时刻,在fpga500产生了故障的情况下(1212),fpga500经由pcle根联合体221对主处理器200通知故障(1213)。接受了故障的通知的主处理器200检测fpga500的故障。另外,也可以由主处理器200监视fpga500,来检测故障。
主处理器200从存储设备400读取过滤处理中所需的db450(1214),并将其保存在系统存储器210(1215)。读取完成后(1216),执行dbms120的主处理器200不使用fpga500,而由自身执行db450的过滤处理(1217)。
此外,主处理器200也可以将分配给fpga500的存储设备400再次分配给fpga510等其他加速器板51。关于该处理,用以下的图12进行说明。
图12是表示在加速器板50产生了故障时由信息处理装置10进行的重新分配处理的一例的时序图。
在存储设备400被分配给fpga500的情况下,执行dbms120的主处理器200对fpga500指示对存储设备400的db450执行过滤处理(1221)。
但是,在该时刻,在fpga500产生了故障的情况下(1222),fpga500经由pcle根联合体221对主处理器200通知故障(1223)。接受了故障的通知的主处理器200检测fpga500的故障。此外,也可以由主处理器200监视fpga500来检测故障。
主处理器200决定对新的加速器板51分配存储设备400。主处理器200指示存储设备400生成fpga510用的fpga队列408(1224)。主处理器200对fpga510通知包括存储设备400的fpga510用的fpga队列408的地址在内的信息(1225)。
接着,执行dbms120的主处理器200对新的fpga510重新发行指示进行使用保存在存储设备400的db450的过滤处理的过滤处理指令(1226)。
从主处理器200接收到过滤处理指令的fpga510根据过滤处理指令的信息对存储设备400发行读取指令(1227)。从存储设备400的db保存区域404读取的数据保存在fpga510的缓存中(1228)。
存储设备400在所请求的数据的读出完成时将读取完成通知发送到fpga510(1229)。接收到读取完成通知的fpga510基于过滤处理指令执行过滤处理(1230)。
接着,fpga510将过滤处理的结果发送到db服务器20的系统存储器210(1231)。过滤处理完成后,fpga500将过滤处理的完成通知发送到主处理器200(1232),结束一系列的过滤处理。
另外,虽然说明了在存储设备400生成新的fpga510用的fpga队列408的例子,但是也可以是fpga510援用fpga500所使用的fpga队列408。在该情况下,主处理器200对fpga510通知fpga500所使用的fpga队列408的地址和fpga队列408的值等、用于援用fpga队列408的交接信息。
如以上图12那样,在fpga500产生了故障的情况下,对存储设备400分配其他fpga510,由此,即使在fpga500发生故障时也能够保持处理能力,能够继续信息处理装置10的运用。
图13是表示对1个pcle开关4320追加了存储设备和加速器板的构成的一例的框图。图13的信息处理装置10,代替图2所示的pcle开关2320,在经由pcle总线4300与db服务器20连接的pcle开关4310上,经由pcle总线4303连接有加速器板50和存储设备400。而且,在该pcle开关4310热插拔存储设备440和加速器板53。对于其他构成,与所述图2相同。
图14是表示在信息处理装置10的初始化完成后,追加了新的存储设备440时的处理的一例的时序图。
在向将fpga500分配给存储设备400的信息处理装置10新插入了存储设备440时(1301),从存储设备440对主处理器200发行中断(1302)。
检测通过热插拔进行的中断,检测到存储设备440的追加的主处理器200进行存储设备440和fpga500的重新分配。例如,示出将存储设备440追加分配给fpga500的例子。
主处理器200指示存储设备440生成主处理器200用的处理器队列407和fpga500用的fpga队列408(1303)。
主处理器200对fpga510通知包括fpga510用的fpga队列408的地址在内的队列信息(1304)。
通过进行这样的重新分配,即使在信息处理装置10的初始化完成后,也能够在存储设备440的追加后赋予fpga500处理新的存储设备的信息的功能。
图15是表示在信息处理装置10的初始化完成后追加了新的加速器板53时的处理的一例的时序图。
图13中,在向将fpga500分配给存储设备400的信息处理装置10新追加了加速器板53(fpga530)时(1311),从fpga530对主处理器200发行中断(1312)。
检测通过热插拔进行的中断,检测到追加了fpga530的主处理器200对存储设备400、440、fpga500、530再次进行分配。例如,在存储设备400仍然被分配给fpga500、且存储设备440被分配给新追加的fpga530的情况下,主处理器200对fpga500通知存储设备440的分配解除(1313)。
接着,主处理器200指示存储设备440生成fpga530用的fpga队列408(1314)。之后,主处理器200对fpga530通知包括存储设备440的fpga530用的fpga队列408的地址在内的队列信息(1315)。之后,执行dbms120的主处理器200指示由fpga530执行使用存储设备440的db的过滤处理。
此外,说明了在存储设备440生成新的fpga530用的fpga队列408的例子,但也可以是fpga530援用fpga500所使用的fpga队列408。该情况下,主处理器200对fpga530通知fpga500所使用的fpga队列408的地址和fpga队列408的值等、用于援用fpga队列408的交接信息。
通过进行这样的重新分配,即使在信息处理装置10的初始化完成后,也能够在追加加速器板53后使用加速器板53来提高信息处理装置10的性能。
以上,根据本实施例1,db服务器20的主处理器200对同样作为末端的加速器的fpga500通知与pcle总线2300~2304的末端连接的存储设备400的队列的信息。由此,pcle总线2300~2304的末端的fpga500同样能够访问末端的存储设备400。而且,fpga500能够直接从存储设备400读出数据并执行主处理器200的处理的一部分,能够使信息处理装置10高速化。
此外,本实施例1使用数据库450的过滤处理进行了说明,但是适用本发明的处理不限定于数据库450的过滤处理,只要是能够将主处理器200的负荷卸载到加速器板50的处理即可。例如可以是数据的压缩处理等。
此外,在本实施例1中,说明了主处理器200对加速器板50通知nvme的admin队列406的地址和i/o发行队列407~409的地址的例子,但是本发明不限定于nvme和队列接口。只要是处理器对加速器板50通知用于能够进行i/o指令发行的初始设定接口的地址和从其他设备向存储设备的i/o发行接口的地址的构成即可。
此外,在本实施例1中,如图2所示,说明了利用在db服务器20的外部连接存储设备400和加速器板50的构成,执行db450的过滤处理的例子。但是,本发明不限定于该构成,只要是主处理器200、存储设备400和加速器板50通过网络连接的构成即可。
例如也可以是在db服务器20的内部的pcle插槽搭载有存储设备400或者加速器板50的构成,或者图16的信息处理装置10那样的构成。
图16表示实施例1的变形例,是表示信息处理装置10a的一例的框图。信息处理装置10a具有通过服务器-存储装置间网络700(例如、光纤通道、infiniband(无线带宽技术)等)连接于db服务器20的存储装置60。在存储装置60的内部包括具有存储处理器600、高速缓存610、存储芯片组620的存储控制器61。
存储控制器61的存储芯片组620包括pcle根联合体621。pcle根联合体621经由pcle总线5301连接pcle开关5310。
包括fpga500、510的加速器板50、51和存储设备400、410、420、430经由pcle总线5303与pcle开关5310连接。
此外,在本实施例1中,说明了使用pcle总线作为将主处理器200、存储设备400和加速器板50连接的总线,但是本发明中使用的总线不限定于的pcle。例如代替pcle总线可以使用sas(serialattachedscsi:串列scsi)。
实施例2
图17表示本发明的第二实施例,是表示信息处理装置10的一例的框图。本实施例2中,代替加速器板50,采用加速器板54,仅使用pcle开关2310,其他的构成与所述实施例1相同。
所述实施例1中,说明了不具有存储元件的加速器板50对存储设备400发行i/o指令的例子,但是本发明中,搭载有加速器板50的设备也可以具有存储元件。
例如,图17的信息处理装置10是具有加速器板54和存储设备400的构成,加速器板54搭载有作为加速器的fpga540和作为非易失性存储器的db保存区域545双方。
db服务器20与所述实施例1同样,主处理器200在存储设备400的i/o控制器401生成fpga用i/o发行队列409,并将所生成的队列信息通知给fpga540。由此,fpga540能够使用队列信息对存储设备400发行i/o指令。
以下说明在该加速器板54发行了过滤处理指令时的处理。
图18是表示由信息处理装置10进行的数据库处理的一例的时序图。
与所述实施例1的图5同样,执行dbms120的主处理器200对fpga540发行过滤处理指令(1401)。过滤处理指令中至少包括:表示执行过滤处理的数据库450的表格的排头位于存储设备400的db保存区域404的地址的哪里的信息;和执行过滤处理的db450的大小信息、过滤处理的条件式=a。收到过滤处理指令的i/o处理电路541针对自身的db保存区域545中没有的lba区域的数据向存储设备400发行读取指令(1402)。存储设备400读出所请求的数据并将其写入缓存543(1404、1408),向i/o处理电路541发行读取完成通知(1406、1410)。
另一方面,对于保存在fpga540自身的db保存区域545的lba区域的数据,对非易失性存储器控制电路544发行读取指令(1403)。db保存区域545读出所请求的数据并将其写入缓存543(1405、1409),对i/o处理电路541发行读取完成通知(1407、1411)。
i/o处理电路541,在过滤处理中所需的全部数据被写入缓存543时,基于接收到的条件式=a对过滤处理电路542发出执行过滤处理的指令(1412)。过滤处理电路542使用缓存543的数据执行过滤处理,在db服务器20的系统存储器210写入过滤处理结果(1413)。而且,过滤处理电路542对i/o处理电路541发行过滤处理的完成通知(1414)。i/o处理电路541对db服务器20的主处理器200通知过滤处理的完成通知(1415),结束处理。
通过这样的处理,db服务器20能够对加速器板54将在存储设备400的db保存区域404和加速器板54的db保存区域545中保存的db的过滤处理卸载到作为加速器的fpga540。
实施例3
图19表示本发明的第三实施例,是表示信息处理装置10的一例的框图。本实施例3中,代替加速器板50和存储设备400,将多个加速器搭载存储设备800、810连接在pcle开关310上,其他构成与所述实施例1相同。
所述实施例1中,说明了不具有存储元件的加速器板50对存储设备发行i/o指令的例子,但是本发明中,能够采用包括加速器的功能和存储设备的功能的加速器搭载存储设备800、810。
例如,如图19的信息处理装置10那样,存在将作为加速器而搭载有fpga900的加速器搭载存储设备800和搭载有fpga910的加速器搭载存储设备810经由pcle开关310与db服务器20连接的构成等。db服务器20和pcle开关310是与所述实施例1相同的构成。
加速器搭载存储设备800中,i/o控制器801和fpga900具有芯片间通信电路901,能够对fpga900的缓存903传送db保存区域804的数据。由此,能够利用过滤处理电路902对db保存区域804的db进行过滤处理。
再者,i/o控制器801与所述实施例1的图2所示的i/o控制器401同样,具有处理器802、管理信息保存区域803和指令接口805。指令接口805具有admin队列806、处理器队列807和fpga队列808、809。
加速器搭载存储设备810也是同样的构成,i/o控制器811和fpga910具有芯片间通信电路,能够对fpga910的缓存913传送db保存区域814的数据。由此,能够利用过滤处理电路912对db保存区域814的db进行过滤处理。
再者,i/o控制器811与所述实施例1的图2所示的i/o控制器401同样,具有处理器812、管理信息保存区域813和指令接口815。指令接口815具有admin队列816、处理器队列817和fpga队列818、819。
图20是表示由信息处理装置10进行的初始化处理的一例的时序图。
主处理器200在信息处理装置10的初始化开始时从系统存储器210取得自身连接的pcle网络的构成信息(1501)。
接着,主处理器200使用所取得的pcle网络的构成信息分配访问数据库保存区域804、814的fpga900、910(1502)。该分配能够与所述实施例1的图4同样地进行。
主处理器200使用加速器搭载存储设备800的admin队列806,生成主处理器200用的i/o发行队列807和加速器搭载存储设备810的fpga910用的i/o发行队列808(1503)。
此外,同样地,主处理器200使用加速器搭载存储设备810的admin队列816,生成主处理器200用的i/o发行队列817和加速器搭载存储设备800的fpga900用的i/o发行队列818(1504)。
之后,主处理器200对加速器搭载存储设备800通知加速器搭载存储设备810的i/o发行队列818的信息(1505)。此外,主处理器200对加速器搭载存储设备810通知加速器搭载存储设备800的i/o发行队列808的信息(1506)。通过上述图20的处理,加速器搭载存储设备800和加速器搭载存储设备810能够相互发行i/o指令来执行过滤处理。
再者,上述实施例3中介绍了i/o控制器801、811和fpga900、910作为独立的芯片而被安装的例子,但是也可以将过滤处理电路902、912搭载于i/o控制器801、811等一体化为具有加速器的功能的i/o控制器。
再者,将所述实施例1的图5的处理适用于本实施例3时,主处理器200对加速器搭载存储设备810发行过滤处理指令,加速器搭载存储设备810从加速器存储设备800读入数据。然后,加速器搭载存储设备810的fpga910执行过滤处理,并将处理结果保存在主处理器200的系统存储器210。
此外,将所述实施例1的图7、图8、图9a、图9b的内容适用于本实施例3时,首先,在主处理器200起动等时多个加速器收集存储设备800、810的信息,并作为pcle网络的构成信息保存在系统存储器210中。然后,主处理器200基于pcle网络的构成信息,使满足规定条件的加速器决定存储设备800、810和fpga900、910的分配。主处理器200基于该决定了的分配,通过加速器对加速器搭载存储设备810通知存储设备800的admin队列806的地址或者i/o发行队列807、808的地址,来进行分配并执行。
再者,将所述实施例1的图10的处理适用于本实施例3时,在加速器搭载存储设备800产生了故障时,基于来自加速器搭载存储设备800的通知,主处理器200检测故障。主处理器200对执行过滤处理的加速器搭载存储设备810通知加速器搭载存储设备800的故障。
再者,将所述实施例1的图11的处理适用于本实施例3时,在加速器搭载存储设备810的fpga910产生了故障时,加速器搭载存储设备810对读入了数据的加速器搭载存储设备800通知fpga910的故障。
或者,也可以是,加速器搭载存储设备810对主处理器200通知fpga910的故障,主处理器200对加速器搭载存储设备800通知fpga910的故障。
再者,将所述实施例1的图14或者图15的处理适用于本实施例3时,主处理器200检测到新的加速器搭载存储设备的追加时,参照系统存储器210的pcle网络的构成信息,决定新的加速器搭载存储设备和fpga的分配。然后,主处理器200基于新的分配,将admin队列和i/o发行队列的地址通知给新的加速器搭载存储设备或已有的加速器搭载存储设备800来改变分配。
再者,本发明不限定于上述的实施例,包括各种变形例。例如,为了容易理解地说明本发明,上述的实施例是详细记载的例子,不必限定于具有所说明的全部构成。此外,能够将某实施例的构成的一部分置换为其他实施例的构成,此外,还能够在某实施例的构成中添加其他实施例的构成。此外,对于各实施例的构成的一部分,均能够单独地或者组合地应用其他构成的任何追加、删除或者置换。
此外,上述的各构成、功能、处理部和处理单元等,它们的一部分或者全部可以通过例如集成电路进行设计等由硬件实现。此外,上述的各构成和功能等,也可以通过解释、执行处理器实现各个功能的程序而由软件实现。实现各功能的程序、表格、文件等信息能够放在存储器、硬盘、ssd(solidstatedrive)等记录装置、或者ic卡、sd卡、dvd等记录介质中。
此外,控制线和信息线示出了说明上认为必要的部分,不限定于产品上必须示出全部的控制线和信息线。实际上也可以认为几乎所有的构成相互连接。
<补充>
一种信息处理装置,是存储数据的存储设备,
所述存储设备具有接受所述初始化的命令的初始设定接口和发行i/o指令的i/o发行接口,
所述i/o发行接口包括接受来自所述第一装置的i/o指令的第一i/o发行接口和接受来自所述第二装置的i/o指令的第二i/o发行接口,
所述存储设备能够从所述第一装置和第二装置分别独立地接受所述i/o指令。
- 还没有人留言评论。精彩留言会获得点赞!