一种可分级的快速图像GPS位置估计方法与流程
本发明属于多媒体图像处理技术领域,涉及一种图像位置估计方法,尤其是一种可分级的快速图像GPS位置估计方法,特别涉及图像内所包含景物的位置识别。
背景技术:
随着生活水平的提高,人们开始热衷旅游,并在旅游过程中拍摄大量图片上传到图片分享网站与社交网络。知名的图片分享网站如Flickr,上传的图片总数达50亿张。社交网络中的图片上传量更为惊人,光Facebook一家就达到了600亿。在我国,社交网站人人网,开心网成为了主要的上传与分享的途径。与此同时,人们也越来越方便的收集各种景点的各种图片。也许人们会碰到自己非常喜欢的图像,但是却不知道这些图像是在什么地方拍的。因此,对于如此大规模图像多媒体数据,如何有效地利用这些巨大规模的多媒体数据帮助人们自动的识别图像中包含的景物的拍摄地点是很有必要的。目前的图像识别一般都要借助图像所包含的一些标签或者评论信息,根据标签和评论信息对图像进行分类与识别。基于文本的图像检索也已经日渐成熟,像谷歌、百度等,给定输入关键词的前提下,能都搜索出一系列的带有关键词标签的图像。但是由于图像附带的标签与描述存在噪声,另外,这些附带信息本身是人们添加上去的,难免会有一些主观性。所以,利用图像内容进行图像检索以及图像的识别是非常有必要的,另一方面,网络上的大规模图像多媒体资源,也为自动的通过图像内容进行图像的识别提供了有利的条件。随着科技的进步,人们智能手机和部分数码相机拍照时带有时间和GPS记录功能,在上传不自带GPS信息的图片时,Flickr提供用户可以手动拖动上传图像到其相应位置的能。因此,是可以通过网络多媒体手段获取大量的带有地理位置标签的图像的。这就对自动的图像地理位置估计提供了条件。
技术实现要素:
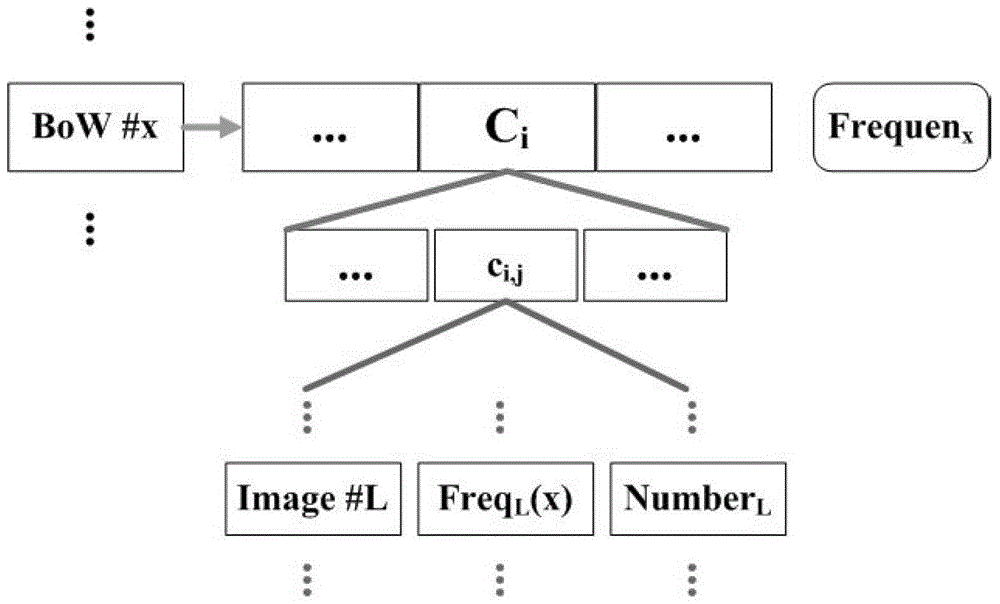
本发明的目的在于提供一种可分级的快速图像GPS位置估计方法,该方法利用两个子系统:离线子系统及在线子系统。其中离线子系统主要对大规模带有地理位置标记图像库的处理。而对于在线子系统,是对查询图像进行特征描述,使用全局特征对所有的离线图库中的图像类进行筛选,之后根据全局特征选取候选图像组并且使用局部特征进行特征量化得到视觉词汇,最后结合每个图像类的代表性图库的倒排索引表,最后根据距离,对结果进行排序,并且使用K-NN方法对图像地理位置进行估计。在这个过程中,使用了倒排索引结构达到了快速图像检索的目的,通过快速的图像检索能够加快图像GPS位置估计的完成。该方法能够提高图像的检索速度,改进检索精度。本发明的目的是通过以下技术方案来解决的:这种可分级的快速图像GPS位置估计方法,包括以下步骤:(1)离线图像库的处理1)图像库预处理计算图像的平均亮度和HWVP纹理能量,按照计算的图像平均亮度,分别去除1%最高和1%最低的图像;按照计算的HWVP纹理能量,分别去除1%最高和1%最低的图像;2)图像特征提取提取图像中的全局特征:45-D颜色矩特征,170-DHWVP特征还有局部的SIFT特征;所述45-D颜色矩特征是指将图像平均分成四份,再重叠提取图像中心区域,然后对五个区域使用九维颜色矩进行描述;3)全局特征聚类按照全局特征,采用K-means聚类方法将图像库中的所有图像聚类成32个第一级聚类;4)根据地理位置细化将上一步得到的32个第一级聚类中的每一类按照地理位置进行细分,得到新的第二级聚类;所述每个第二级聚类中图片都拍摄于相同的地理位置;5)代表性图片选取对每个第二级聚类进行代表性图片选取,得到每个第二级聚类的代表性图像组;6)建立快速的文件索引结构对代表性图像组使用视觉词汇包模型进行描述,并且构建视觉词汇与代表性图像组的倒排索引结构;(2)在线图像地理位置估计1)第一级中心选取首先将输入图像的全局特征与第一级聚类的各个中心进行比对,选择距离最近的M个中心作为候选中心;其中比对是通过计算距离得到的,距离计算方法如下,Di=||LCi-Linput||,(i=1,…,R),其中Linput表示输入图像的45-D颜色矩特征和170-DHWVP特征构成的215维全局特征,Di表示输入图像与第i个类Ci全局特征中心LCi的距离;||X||用来表示X的范数;R=32;按照计算的距离选择M个距离最近的第一级聚类作为候选中心其中M≤R;2)第二级中心选择在选择了M个第一级聚类候选中心之后,进一步进行更精细的第二级聚类候选中心的选择;用s={r1,…,rN}表示所选中的所有的第二级聚类中心,其中ri∈{cj,k},j=1,…,R;k=1,…,Nj;;然后在所有的N个第二级聚类中心中选择前V%作为选择出的第二级候选中心,V为0-100的实数;选择方法与第一级聚类候选中心相同,计算方法如下:di=||Lri-Linput||,i∈{1,…,N}其中N是所有第一级聚类候选中心下面所包含的第二级聚类中心的数目,Lri代表第i个第二级聚类候选中心的全局特征描述;通过该步骤得到的所有的第二级聚类候选中心,记做SC={g1,…,gF},其中gf∈{r1,…,rN},其中f∈{1,…,F},F=V×N/100;3)使用局部特征改进使用BoW直方图或者倒排索引结构对选取的第二级聚类候选中心进行确认;再根据确认得到的结果使用KNN的方法对输入图像的地理位置进行推荐。进一步,以上当使用BoW直方图对选取的第二级聚类候选中心进行确认时,按照以下进行:在离线系统中,用BoW模型描述之后,生成BoW直方图;在此,对输入图像也生成相对应维数的BoW直方图,并表示为h(k),k=1,…,Q;使用四种直方图距离度量方式进行距离度量,包括余弦距离COS、城市距离MAD、欧式距离MSD和直方图相交HIST;其距离计算方法分别如下:其中,NH是代表性图像组的BoW直方图描述。进一步的,以上当使用倒排索引结构对选取的第二级聚类候选中心进行确认时,按照以下进行:使用TF-IDF计算权值的方法,对每个图像组计算其相应的得分,得分计算方法如下,其中FreqL(x)是第x号词汇的频数,NumberL是图像中的所有视觉词汇的数目,Frequenx是词汇在整个图像库中出现的次数,ωx表示的是对于输入图像词汇的权重;权重计算方法如下,其中Freqinput(x)表示BoW#x的频次andNumberinput输入图像所包含的的视觉词汇的总数。与现有技术相比,本发明优点在于:1)本发明的可分级的快速图像GPS位置估计方法使用视觉特征和地理位置信息对大规模的图像库构建了可分层的结构,能够有效提高图像的检索速度;2)本发明提出了分层聚类和局部特征改进的GPS地理位置估计方法,通过结合局部特征,能够有效改进检索精度;3)本发明在局部特征的使用过程中,引用了倒排索引结构来加快检索速度和提高检索准确度。附图说明图1为本发明方法的总体步骤示意框图;图2为本发明方法中采用倒排索引机构的时候的倒排索引表的结构图。具体实施方式下面结合附图对本发明做进一步详细描述:参见图1:本发明的可分级的快速图像GPS位置估计方法包括以下步骤:(1)离线图像库的处理离线子系统的目的主要是对大规模带地理标签的图像库进行离线处理,使其能够更好的应用于在线的图像地理位置估计,以达到快速有效的进行GPS估计的目的。离线子系统主要包括以下六个方面:1)图像库的预处理,2)对图像库内图像的全局和局部特征的描述,3)使用全局特征对图像库中图像进行K-means聚类;4)根据地理位置对第一级的聚类得到的类进行细分得到第二级的图像组,5)对第四步得到的图像组进行代表性图像的选择,6)对代表性图像组建立倒排索引表。下面分别对这六个部分进行介绍。1)图像库预处理图像库预处理的目的在于去除一些噪声图像。因为在图像库构建的过程中,是根据关键词在图像库中检索然后进行下载的。这样就导致下载到的图像质量很不均一,可能会有很多图像亮度特别高/低,或者包含特别多的噪声,然后这些图像对于完成GPS估计是没有作用,甚至是有反作用的,于是本发明中就先进行了初步的预处理,旨在去除那些质量比较差的图像。按照计算的图像平均亮度,分别去除Alpha%最高和最低的图像,通过后面实验发现Alpha取1的时候效果最好。对于包含噪声多纹理复杂的图像的去除,本发明中使用的是HWVP特征,计算了纹理能量,然后进行噪声的去除。通过预处理,保证了剩余参与离线图像库使用的图像是一些质量比较好的图。因此,在本发明的最佳方案中,该步骤按照以下进行:计算图像的平均亮度和HWVP纹理能量,按照计算的图像平均亮度,分别去除1%最高和1%最低的图像(即将图像平均亮度排序,去掉两头高部分的和低部分的各1%);按照计算的HWVP纹理能量,分别去除1%最高和1%最低的图像;2)图像特征提取提取图像中的全局特征:45-D颜色矩特征,170-DHWVP特征还有局部的SIFT特征;所述45-D颜色矩特征是指将图像平均分成四份,再重叠提取图像中心区域,然后对五个区域使用九维颜色矩进行描述;3)全局特征聚类考虑到大规模图像库图像检索中对检索速度的要求,本发明中提出使用聚类中心代替图像库中的单幅图像的思想。因为相比图像数,中心数能够减低很多,这样所需要比较的时间也就缩短了。通过全局特征聚类,整个图像库就能够划分成一些相对规模较小的图像类,而每个图像类都有相似的全局特性。之所以聚类,是基于减低复杂度的考虑。另外也希望通过全局特征聚类,能够将拍摄于同一个地方的图像,能够按不同的场景进行划分,如春夏秋冬,白天和黑夜,地标与非地标建筑,古典建筑与现代建筑。按照全局特征,采用K-means聚类方法将图像库中的所有图像聚类成32个第一级聚类;对于全局特征中使用的特征包括颜色特征和纹理特征。颜色特征使用的是45维的颜色矩,而纹理特征则是使用的170维的HWVP特征。本发明中将两个特征融合成一个215维的低级特征,对图像库中所有的图像分别进行描述。通过聚类,得到R个类C1,…,CR,并且每个类都有一个中心LCi。4)根据地理位置细化本步骤中,将上一步得到的32个第一级聚类中的每一类按照地理位置进行细分,得到新的第二级聚类;所述每个第二级聚类中图片都拍摄于相同的地理位置。具体解释如下:得到了第一级的聚类ri∈{cj,k},j=1,…,R;k=1,…,n;之后,根据图像的拍摄地点对这R个聚类进行更精细的划分。假设第i个中心Ci下面包含拍摄于Ni(i=1,…,R)个景点的图像,那么进行按照地理位置的进一步细分,得到了第二级的图像聚类ci,j(i=1,…,R;j=1,...,Ni)。对于每一个第二级的聚类,本文进行了其全局特征中心的计算,并用Lci,j表示。其计算公式如下所示,其中ni,j是ci,j中所包含图像的数目,Li,j,k表示ci,j中第k张图像的215维的全局特征向量。第二级图像数目与第一级图像数目之间的关系如下所示,因此,图像库中图像总数就是所有第一级中心内所有图像数目的加和,表示如下:也就是说,通过聚类和按照GPS位置,对图像库进行了划分,每个图像都被分到了相应的第一级和第二级的中心中,也就有了相应的第一级类别和第二级类别。5)代表性图片选取对每个第二级聚类进行代表性图片选取,得到每个第二级聚类的代表性图像组。得到了第二级聚类ci,j之后,所能够保证的是所有类内的图像都是具有相似的全局特征以及拍摄于相似的地方。由于第二级中心的精细划分是根据图像所附带的标签进行的,而网络上的很多标签都是人工标记包含大量噪声的,因此,ci,j中的图像并不能保证确实是拍摄于所标记的地点中。另外一个方面,由于拍摄于相同景点的图像可能会有不同的拍摄角度,也就导致会有较大的差异。所以仅仅通过全局中心来表示整个ci,j就导致由于取了品均值带来的内部差异的隐藏。考虑到局部特征描述符能够有效的提取图像的局部信息,能够挖掘出图像中所包含的景点,本发明采用SIFT特征匹配的方法对每一个第二级的聚类进行代表性图像的选取。选取的具体算法如下,该算法是参考了Kennedy等人文章中的代表性图像选择的办法改进进行选择的。算法1是本发明提出的代表性图像选择的流程:6)建立快速的文件索引结构对代表性图像组使用视觉词汇包模型进行描述,并且构建视觉词汇与代表性图像组的倒排索引结构。在图像多媒体检索领域,表示局部视觉特征内容的描述符或者局部特征区域的向量就可以看做是一个个的视觉词汇。比如出现在不同图像中的相同的局部特征点/区域应该具有相同的属性,而且描述相同局部特征点临域或者局部特征区域的描述符应该也是一样的,这样就可以说,两个图像的相应两个关键帧都拥有该视觉词汇。那么类比文本倒排索引的定义,图像库中所有图像所提取的局部特征描述符就可以看做是文档中的一个个词汇,而不同的图像就可以看做是不同的文档,那么基于视觉词汇的倒排索引其实就是要为每一个视觉词汇记录它出现的视频名称,出现的帧号甚至在该帧中的坐标位置。所以对于视觉词汇的倒排索引的建立来说,最重要的就是将数量无限的视觉词汇量化到数量有限的可以表示内容的视觉词汇上,我们也形象地称之为量化。量化之后就可以将图像使用BoW模型进行标示。参见图2,对比传统的倒排表不同,本发明中的倒排表是词汇于每个代表性图像组之间的对应关系。倒排表中记录的是每个视觉词汇,以及其所出现的代表性图像组的标号。(2)在线图像地理位置估计本发明的在线图像地理位置估计是于在线子系统中完成的。在线子系统具体的模块可以由图1中的在线部分构成。与离线子系统相似,它的各个模块也可以按照实现功能的不同分为特征提取,第一级中心选取,第二级中心选取以及局部特征确认三大部分:1)第一级中心选取首先将输入图像的全局特征与第一级聚类的各个中心进行比对,选择距离最近的M个中心作为候选中心;其中比对是通过计算距离得到的,距离计算方法如下,Di=||LCi-Linput||,(i=1,…,R),其中Linput表示输入图像的45-D颜色矩特征和170-DHWVP特征构成的215维全局特征,Di表示输入图像与第i个类Ci全局特征中心LCi的距离;||X||用来表示X的范数;R=32;这样就可以计算得到输入图像于所有第一级中心的聚类,然后本发明中对所有的距离按照升序的方式进行排序。由于图像之间的距离可以描述视觉相似性,距离越近,则表明视觉上面相似性越高。然后按照计算的距离选择M个距离最近的第一级聚类作为候选中心其中M≤R;此处的选择方法有一下两个优点,相比计算与图像库中所有图像的距离,仅仅计算中心的距离相比而言就打打降低了计算量。而选择M个中心而非一个中心,是考虑到此步骤仅仅是粗略的选择一些候选图像集,而并非最终的精细选择,因此多选几个聚类有利于寻找到真正的代表输入图像的图像类。通过第一步的选择,得到了M个第一级候选中心,记为2)第二级中心选取在选择了M个第一级聚类候选中心之后,进一步进行更精细的第二级聚类候选中心的选择;用s={r1,…,rN}表示所选中的所有的第二级聚类中心,其中ri∈{cj,k},j=1,…,R;k=1,…,Nj;;然后在所有的N个第二级聚类中心中选择前V%作为选择出的第二级候选中心,V为0-100的实数;选择方法与第一级聚类候选中心相同,计算方法如下:di=||Lri-Linput||,i∈{1,…,N}其中N是所有第一级聚类候选中心下面所包含的第二级聚类中心的数目,Lri代表第i个第二级聚类候选中心的全局特征描述;通过该步骤得到的所有的第二级聚类候选中心,记做SC={g1,…,gF},其中gf∈{r1,…,rN},其中f∈{1,…,F},F=V×N/100;3)使用局部特征改进上述所有步骤都考虑的是图像的全局方面的特征,对于场景区分,建筑物识别等局部特征一直都体现了其有效性。因此,本发明在这一步做了局部特征确认,旨在保证选出来的图像组能够更好地表示输入图像,以达到估计准确的目的。在局部特征的相似性度量中,使用了本发明使用了两种不同的方法,一种是基于BoW直方图的相似性度量,另外一种是基于视觉词汇倒排索引结构的相似性度量。比对的是图像与各个离线系统中选择出来的代表性图像组之间的相似度,期待通过选择相似的图像组,并使用图像组的GPS位置信息来估计图像的拍摄地点位置。基于BoW直方图的相似性度量在离线系统中,生产码数之后,我们对每个代表性图像组用BoW直方图进行描述。在此,对输入图像也生成相对应维数的BoW直方图,并表示为h(k),k=1,…,Q。本发明中使用四种常见的直方图距离度量方式进行距离度量,包括余弦距离(记为COS),城市距离(MAD),欧式距离(MSD)和直方图相交(HIST)。其距离计算方法分别如下,基于倒排索引结构的相似性度量倒排索引结构近些年来经常用于文本检索中,随着图像检索中BoW的不断发展,倒排索引也得到了广泛的应用。本发明中使用了基本的TF-IDF计算权值的方法。对每个图像组计算其相应的得分。得分计算方法如下,其中FreqL(x)是第x号词汇的频数,NumberL是图像中的所有视觉词汇的数目,Frequenx是词汇在整个图像库中出现的次数,ωx表示的是对于输入图像词汇的权重。权重计算方法如下,其中Freqinput(x)表示BoW#x的频次andNumberinput输入图像所包含的的视觉词汇的总数。以上使用BoW直方图或者倒排索引结构对选取的第二级聚类候选中心进行确认后;再根据确认得到的结果使用KNN的方法对输入图像的地理位置进行推荐。实验结果及分析为了验证提出系统的性能,本文对比了IM2GPS,田等人的空间编码的方法(记为SC,包括1-NN和K-NN两种),以及李等人的基于SVM的地标建筑物的分类方法(记为LC)。性能评估包括两个部分,第一部分是GOLD库与GOLDEN库上的交叉检验,第二部分是每个图像库内部的图像GPS位置估计的准确率和时间性能统计。评价准则1)误判率在交叉检验中,如果GOLD库中的图像作为输入图,GOLDEN库作为离线图像库的话,根据本文设定的准则应该是判断为不可估计,但是如果系统误判为图像可以GPS位置估计并且估计出了错误的GPS位置,那么就认为是误判的。反之,GOLDEN库中的图像做输入图像,GOLD做离线库的时候,原理也是相同的。本文中,ER表示误判率,用FN代表发生误判的图像数目,TN表示所有用于交叉检验的图像总数。误判率的计算公式如下:2)GPS估计的准确率与时间性能对比系统的准确率是通过从离线图像库中选取图像作为输入,利用系统进行GPS位置估计,然后判断与真实的位置是否一致进行准确率度量的。计算公式如下:式中:AR——整个图像库的图像GPS估计准确率;Ai——第i个景点的估计准确率;G——所有测试的地理位置个数。针对每个景点分布计算准确的公式如下:式中:NCi——正确估计的图像个数;NAi——该地理位置出所有测试图像的总数。与其他方法的对比为了公平起见,所有的对比方法中,使用的都只有图像内容。对于方法SC,1-NN和K-NN都进行了对比,其中K选取了是其性能达到最佳的值:120。LC方法中视觉词汇的规模为6万,对比中,提出的系统的基本设置参数为R=32,M=10,K=50,V=100,同时,视觉词汇的规模为6万。基于直方图的相似性度量以及基于倒排索引结构的方法都参与了对比。实验结果如下表3-1和表3-2所示。表3-1SC(1-NN),SC(K-NN),IM2GPS,LC以及本文方法在图像库COREL5000,OxBuild5000和GOLD上的GPS估计准确度(%)结果表明,本文提出的系统性能明显优于其他方法,不仅在GOLD库上,同时也表现在其他两个测试库OxBuild5000和COREL5000上。三个测试数据集上IM2GPS的平均精度为45.98%,39.67%,53.06%。LC的平均精度为49.43%,53.94%,54.25%。SC(K-NN)在三个测试集的性能分别为76.01%,60.87%和71.84%,比其相应的SC(1-NN)性能有所提升。我们的方法根据COS进行举例度量方法在三个数据集上的结果分别为97%,91%和84.64%。MAD,MSD,HIST,和IFS下我们的方法比IM2GPS,LC和SC更好。表3-2.SC(1-NN),SC(K-NN),IM2GPS,LC以及本文方法在图像库COREL5000,OxBuild5000和GOLD上的GPS估计时间消耗(ms)通过实验发现,有效的结合全局特征和局部特征有利于图像GPS位置估计。因为IM2GPS仅仅利用了全局特征,其AR是比较低的。虽然SC利用局部特征,确忽略了全局特征所能够提供的有效信息。因此,我们的方法体现出了更好地性能。LC的估计准确率较低的原因有两个。其中之一是,他们使用的BoW直方图的时候,局部特征的空间信息是完全被忽略的。另外一方面,是SVM分类受到训练集的影响是很大的,而一般情况下,不能保证训练集中的图像不包含噪声图像。在三个测试集上,IM2GPS平均计算成本是60.46ms,33.74ms,64927ms,而SC(K-NN)是7.30ms,5.51ms,39.60ms,LC则分别是1.04ms,1.34ms,2.89ms。COS,MAD,MSD,HIST,和IFS计算成本都要低于SC,LC,和IM2GPS。对于大规模数据集,IFS的有效性体现的非常明显,平均计算成本是0.117ms,这只是IM2GPS消耗时间的1.8×10-6%,0.25%的SC(K-NN),12.19%的COS,12.58%的MAD,11.36%的MSD,以及11.82%的HIST计算成本。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1